


I wanted to write super-harsh blog but then I decided to split it into educational part and whining part. This is whining part. To read some cool stuff go here. This one will also be educational on a slightly different topic. And there will be A LOT of harsh stuff.
I'm not saying that I'm perfect. That round had some really bad problemsetting issues. Problem E was googleable, problem D had very weak tests against very stupid solution (so stupid that none of the authors and testers come up with it, moreover, it is so counter-intuitive that I don't know how so many people independently did it). In two constructive problems participants could look at jury's output, the feature of which I didn't know. And I'm sorry for these issues. BUT. This comment has very negative rating despite being so true. And no one are here to back me up. So I want to speak my truth as I always do.
Let me accompany you to the world of supposedly BAD STATEMENTS. aka statements written by Um_nik.
Problem C from 2nd division of CF Round #518 gets a lot of praise for having very bad statement. Let us look at clarification requests we get on this problem. My answers here are not answers to clarifications from real contest, they are my emotions.
I think that you should be ashamed for your clarifications so I will include handles. This is probably not ethical as a problemsetter to do it. But I don't care anymore. Maybe I will be banned from setting rounds on CF. That looks like a good thing for all of us. You don't want to solve my problems, I don't want to do anything good for you.
"Is it also necessary that if 2 colors harmonize each other they should be connected?" and similar
by sam29, arif.ozturk, aman28rwt, -rs-, Vshining, tgritsaev, L0rdV0ldemort000006, Huvok, seo, shinbay, Apptica, yurics, Distructed_Cat, Adoki, dalbaeb69, chrome, ASUS, cjc, its_ulure, GhostDrag, GhostDrag
Answer: Yes. That's what "if and only if" means. Literally. That is the meaning of these words.
"Excuse me, what is number k in prob C?"
by tgritsaev, fooish, dalbaeb69
Answer: That's a good question, number k is not important for the problem, but I decided to introduce it to ensure that you'll understand that you should place only colored rooks on a chessboard.
"A,B harmonize; B,C harmonize; do A,C Harmonize?"
by harshit601, Fighter.human, Gudleyd, atrophy98, tshr
Answer: No. I have no idea where did you get it from. There is nothing resembling in the statement. Probably it's an attempt to explain some samples, but it is wrong on first sample.
"are there many solutions for sample tests or it's one solution only?"
by Bakry, _QWOiNYUIVMPFSBKLiGSMAP_, bhowmik, mahdi.hasnat
Answer: Another good question, we made global clarification about this later. This was obvious from the samples, I think, but it was a mistake not to write it. I'm sorry.
"In the first sample, we can't go from the blue rook to every green rook!!" and similar
by cfalas, OmarBazaraa, MonsterInMe, DesiChamp, cjc, aman_shahi2, DesiChamp, MonsterInMe, S.Jindal
Answer: Samples are correct. Statement is correct.
"Reply fast please"
by ck98
"The statement looks like it was done with google translate, i don't understand anything"
by AlexArdelean
Answer: That's important information.
"if there is a harmonized pair (a,b). do the ans must contain a set of union of a and b? or i can arrange without any union set."
by Distructed_Cat
"if there is a harmonized pair (a,b). is it a must to make the both set of color a and b connected?" by Distructed_Cat
"And any rook of one color is connected with any other rook of another color that means all rook of 1st color is connected with all other rook of 2nd color if both color harmonise with each other?"
by Fighter.human
"Is it necessary for two rooks of different colors to be in one set?" by bktl1love
"What is harmonize of color??"
by _Muhammad
"can i connect colors other than the described in the input"
by KyRillos_BoshRa
"Specail Judge?"
by C20192413
Answer: Do you fucking read your questions? I like that "I can't solve the problem with operations in statement, can you provide better operations for me?"
Many questions just asking to clarify what the hell is happening in this hellish statement. There are a lot more stupid questions, I just tired.
CF has a large number of participants in each round. If 5% of participants think that his/her time is more important than ours then we will have to answer 5-10 questions every minute. In this round we had 30-40 unanswered questions during an hour, waiting time to get answer to your question is 5-10 minutes. And if we can't understand your question, we spend several minutes on answering. Please. Please. PLEASE. Spend 2-3 minutes trying to answer your question yourself. Use samples. Reread the statement. This is a skill, you have to improve it. Read my blog.
Don't ask "please explain the problem, I don't understand it". We already did explain the problem. The thing called "statement". Read it. Carefully. Why do you think that we will come up with better explanation right now? We prepared this statement several days, we asked testers to read it and say if something is unclear.
Don't say that statement is bad because you can't understand it. The statement can be hard to understand because it requires some knowledge, not because it is badly written. And some statements require to know mathematical notation like "if and only if" in this particular case. I can't come up with better explanation of why there are so many people asking the same question. basically "what if and only if means".
Please assume that authors spend some time on your contest. Much more time than yours 2 hours. Because it is true.
You can remember that once I made round unrated because I found the mistake in authors solution. I didn't wrote a clarification "I think your problem suck" without explanation. I continued my attempts to solve the problem and waited for the end of the contest, then asked what is authors answer for my test. Because I expected that authors did their job well and too busy answering stupid questions during the round.
One more time I spend ~15 minutes trying to prove that my answer for sample is incorrect. When I did it, I send this clarification: "Are you sure that answer for third sample is 34? For me it seems that there are 3 valid trees, in each of them there are 6 possible ways to choose pair of vertices, and for each path there are two possible winning moves for Ember, so the answer should be 36." Compare this to what you do.
I also think that CF should abandon the practice of answering every clarification if possible. It will decrease the number of clarifications and decrease the time to answer one clarification. If I can answer "Read the problem statement", that should be the answer. If I can answer "No comments", that should be the answer.
I think I'm finished with whining about my statements. Now about this doomed community of supposedly smart people.
The thing you did called bullying. There are people who downvote everything I write independent of content. Next there are people who disliked the consequences of my words, even my comment is correct. And there are also people who don't like that I'm saying my thoughts and don't respect their idols.
I liked first comment about "should stop creating problems", and first comment about this after the round. All others don't have own thoughts and have to repeat one thing over and over again. Now it is not a joke, it is being animals.
The same goes for "mind is weak". Yeah, guys, you are so original, it was not me who said it first.
To adequate people in this community: I'm tired of speaking truth. This not your truth? Explain me why am I not right, change my point of view. You think that I'm right in some cases? Speak it up. These animals can attack lone people, but if they will see that I'm not alone, they could think for once. You think that I have no right to insult people, but the idea is correct? Downvote me, say that wording is bad, but express that you agree with meaning.
MikeMirzayanov, I understand that for you quantity is more important than quality. I'm happy that you have your army of stupid fanatics who will write "You forget to hail Mike" under each post. This army has defeated me. Congrats.





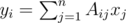 (maybe
(maybe 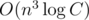 (intersect
(intersect 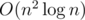 is standard and
is standard and  is possible, probably only with library code :)
is possible, probably only with library code :) . So now we play not for components, but for edges. Better, but still not obvious.
. So now we play not for components, but for edges. Better, but still not obvious.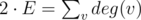 . But for calculating
. But for calculating 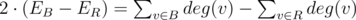 . Turns out this is true, because all RB-edges cancel out.
. Turns out this is true, because all RB-edges cancel out.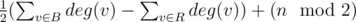

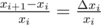 . Worst case for us is when relative error is maximal. It is logical to make them equal — exactly what we do by binary search with absolute errors.
. Worst case for us is when relative error is maximal. It is logical to make them equal — exactly what we do by binary search with absolute errors. 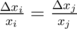 . We can assume that
. We can assume that 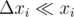 so
so 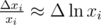 . Now we have
. Now we have 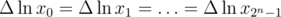 , but
, but  , so
, so 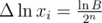 . How large should be
. How large should be 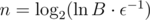 . Much smaller than
. Much smaller than 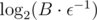 .
.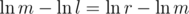 or simply
or simply 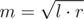 .
.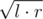 (it is basically the same as dividing the segment in binary search).
(it is basically the same as dividing the segment in binary search).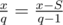 . Отсюда
. Отсюда 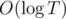
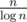 .
.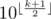 . Это
. Это  .
.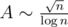 . В нашем случае
. В нашем случае 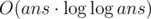 .
.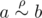 . Если такие есть, то действительно
. Если такие есть, то действительно 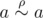 . А если их нет? Если для
. А если их нет? Если для  .
.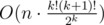 . Если написать аккуратно, это может зайти.
. Если написать аккуратно, это может зайти.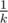 , поэтому если попробовать
, поэтому если попробовать 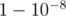 такая точка найдется, и мы сможем уменьшить
такая точка найдется, и мы сможем уменьшить 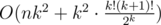 .
.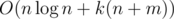 времени,
времени, 