


Поздравляю tourist с выдающимся достижением! В невероятной и драматической борьбе на секундах он смог достичь легендарной отметки в 4000 рейтинга! Это поистине потрясающе! Хочу пожелать дальнейших успехов и побед!
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
43:29:29
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
43:29:29
Зарегистрироваться »
*есть доп. регистрация
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Найти пользователя
→ Прямой эфир






For all of you who used codeblocks as an IDE for CP: there is no codeblocks on IOI now.
There was no announcements about this and in Belarus, we learned about it by accident, so I'm writing this blog for you to know.

Привет, Codeforces!
Я очень рад пригласить вас на Codeforces Round #861 (Div. 2), который пройдет в 29.03.2023 12:05 (Московское время). Этот раунд будет рейтинговым для участников, чей рейтинг ниже, чем 2100.
Моя искренняя благодарность:
Wind_Eagle, BaluconisTima, kartel, gepardo и 244mhq за идеи задач для раунда, а также BaluconisTima, 244mhq, VEGAnn, Vladik и andrew за разработку задач.
vilcheuski и programmer228 — остальную команду авторов, без которых этот раунд бы не состоялся.
BaluconisTima за прекрасные картинки, дополняющие все задачи.
MikeMirzayanov за платформы Codeforces и Polygon.
Вам, за то, что участвуете в этом раунде.
У вас будет 2.5 часа на решение 6 задач, одна из которых будет разбита на простую и сложную версии. Раунд основан на задачах заключительного этапа республиканской олимпиады по информатике в Беларуси. Просьба всех белорусских школьников, участвовавших в заключительном этапе, воздержаться от участия в раунде и обсуждения задач публично до конца раунда.
Я надеюсь, вам понравится раунд!
Тестировали раунд: Ormlis, 4qqqq, nnv-nick, olya.masaeva, Makcum888.
Предварительная разбалловка: 750-1000-1500-2000-2500-3250.
UPD: раунд был перебалансирован. Вам предстоит решить 5 задач за 2 часа, одна из задач будет разбита на простую, среднюю и сложную версии.
Новая разбалловка: 750-1000-1500-1750-(1750+1000+750).
Разбор: https://mirror.codeforces.com/blog/entry/114523
Победители:
Div. 1 + Div. 2:
2) maspy
3) happylmb
Div. 2:
1) happylmb
2) Cherished
3) 2021_yes
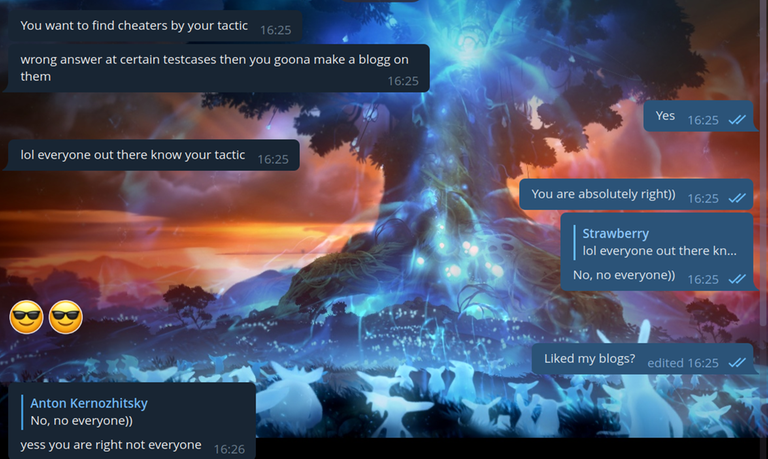
Привет, Codeforces! Не так давно прошел Codeforces #843 (Div. 2), и я был одним из его авторов. Когда уже прошел час с начала контеста, я (можно сказать, уже по традиции) решил зайти в группы с читерами и в очередной раз над ними поиздеваться.
И еще кое-что перед началом. peltorator запустил прикольный конкурс блогов, призываю всех в нем поучаствовать: блог.
Далее. COOLMAARK, ты, конечно, молодец, что написал про группу с читерами, но лучше было это сделать не в комментарии к анонсу, чтобы не делать этой группе рекламу.
Комментарий под блогом

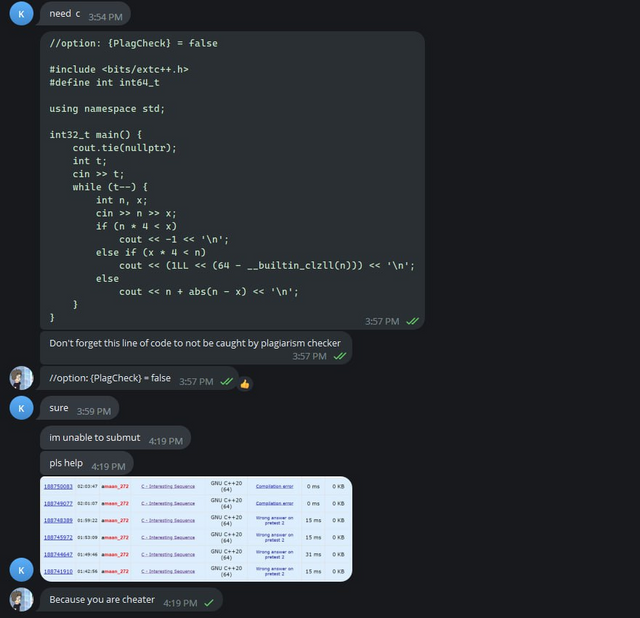
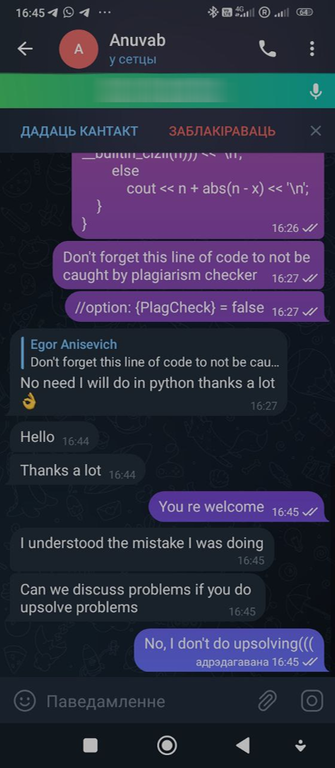
А теперь к делу. Итак, поскольку некоторые читеры меня узнают, я пригласил try_kuhn на помощь. Во всех прошлых случаях существовала проблема: да, конечно, читеры засылали плохой код, но они меняли его, что усложняло бы автоматическую проверку на анти-плагиат. Поэтому я решил попробовать обойти это. discord и еще в две группы в telegram, и написал вот такое сообщение:
Сообщение
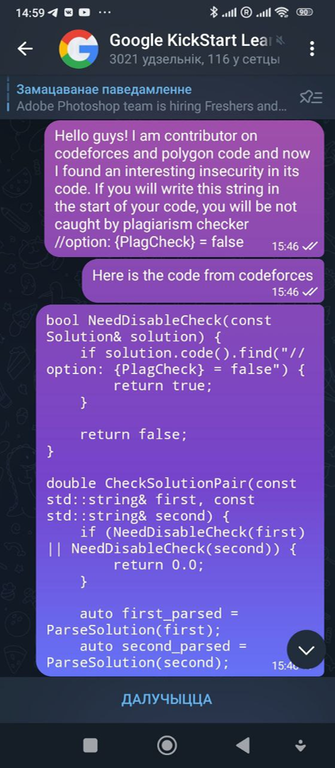
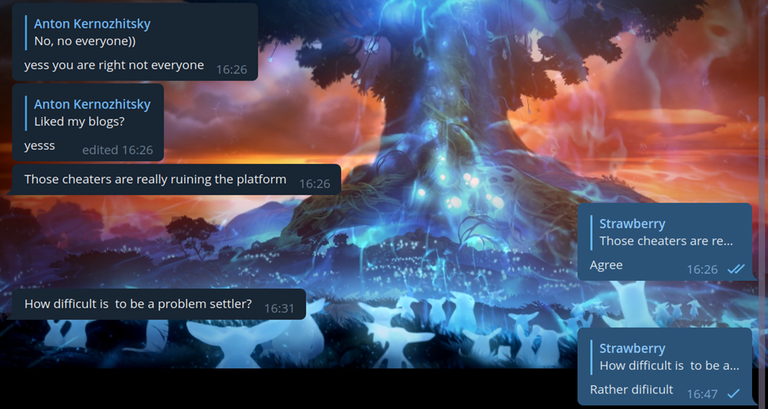
Таким образом мы надеялись на то, что читеры нам поверят, и начнут засылать код без изменений. Также, как и в прошлый раз, мы написали абсолютно неверное решение на задачу C, чтобы читеры делали WA на простом и неверном коде и попадались на антиплагиат.
Сообщение
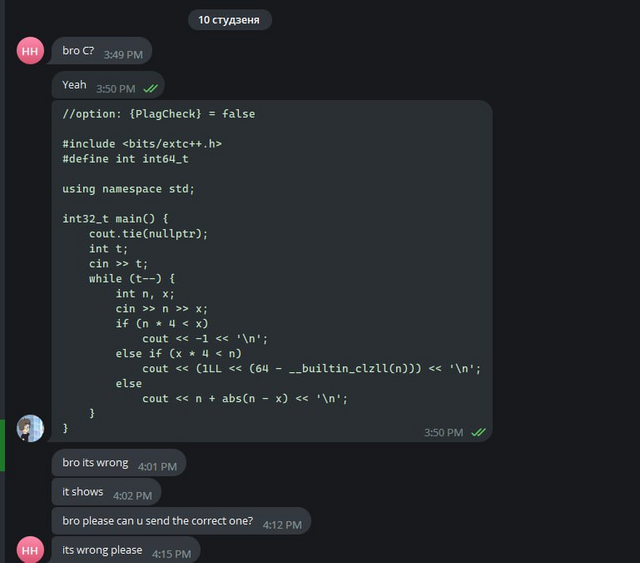
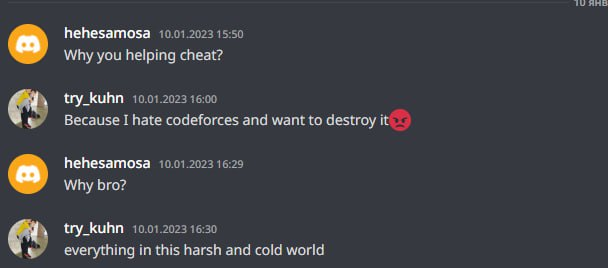
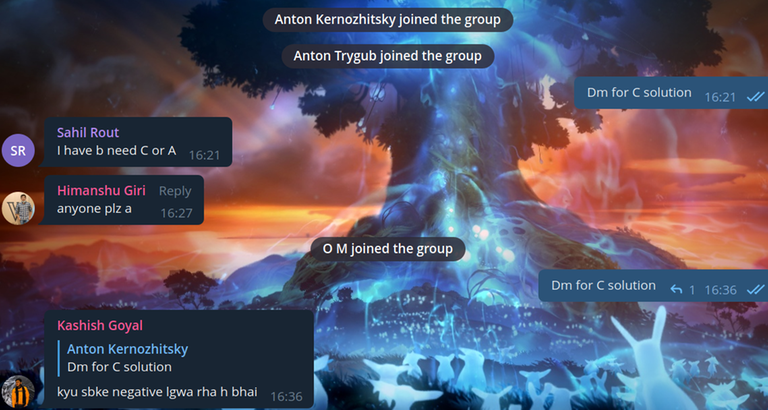
Также try_kuhn зашел в две группы в телеграме, и начал скидывать неверные решения всем желающим.
Скидываем решения
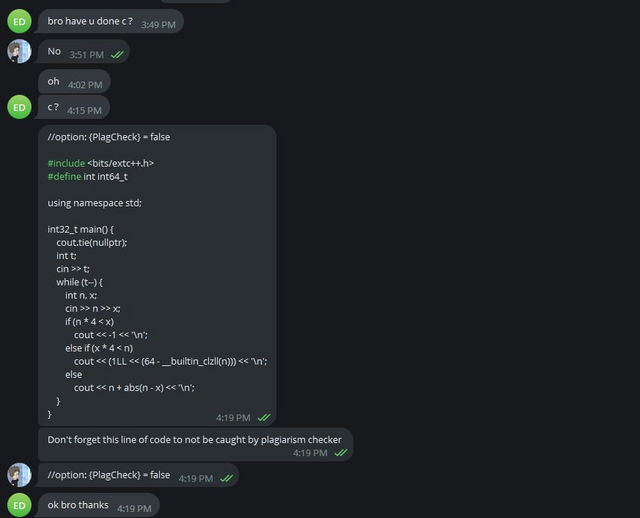
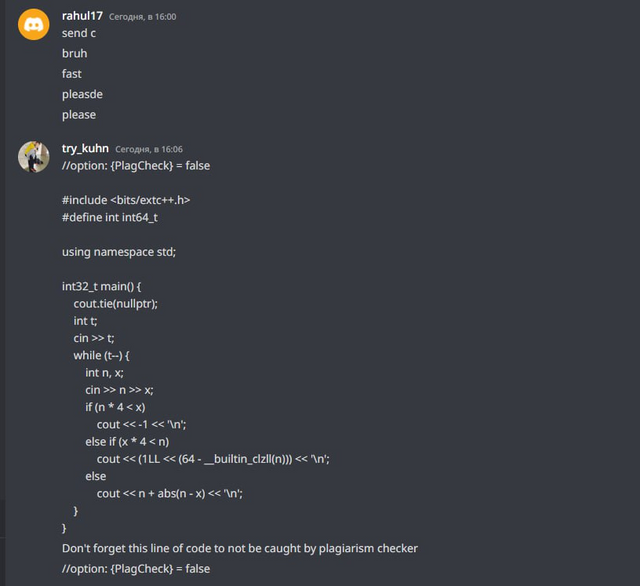

Некоторым читерам мы не скидывали код, а специально прикалывались над ними. Я собрал для вас самые интересные переписки.
Тут мы решили устроить из одной из переписок максимальный абсурд:
Написали читеру, что у нас есть решение, а потом идем в отказ
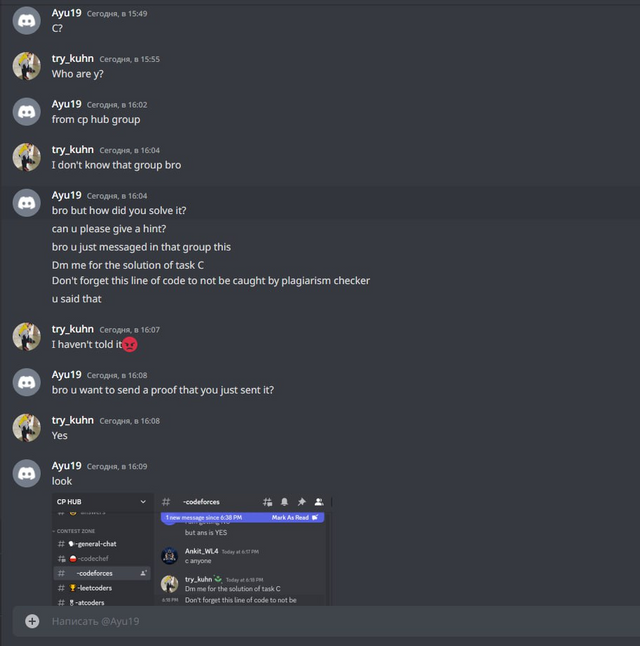

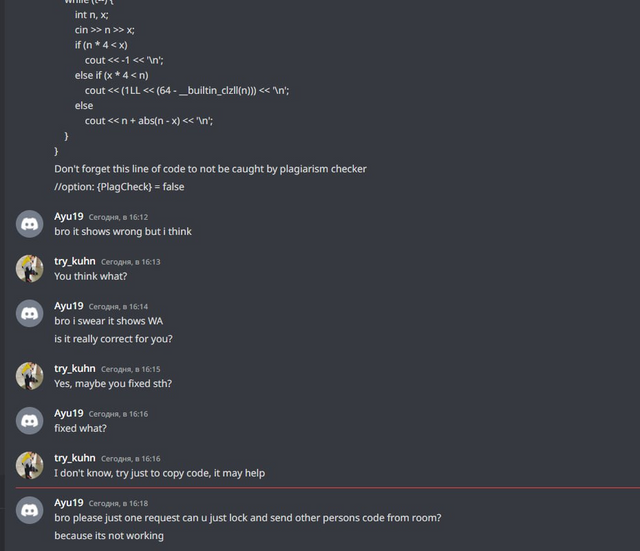
Я считаю, что мой троллинг должен помочь не только забанить читеров, но и помочь им изучить спортивное программирование. Поэтому нам показалось, что было бы неплохо заставить читеров хотя бы подучить алгоритмы:
Заставили читера почитать алгоритмы
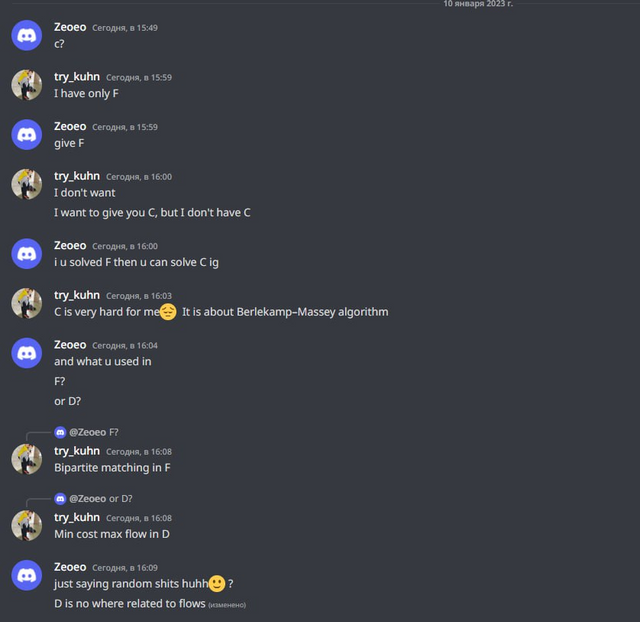
Честно говоря, в этом случае мы даже переборщили со сложностью алгоритма. Мне даже немного жаль этого читера. Он явно не очень высоких рейтингов, а тут такое:
На этот раз решили рассказать решение задачи С
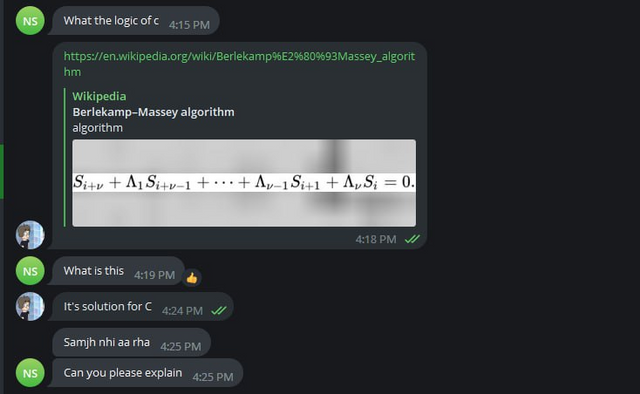
Ну и куда же без отсылок на прошлый блог. Мне довольно часто вспоминают один скриншот из прошлого блога про читеров, так что пусть тут будет похожий:
Отсылка на прошлый блог
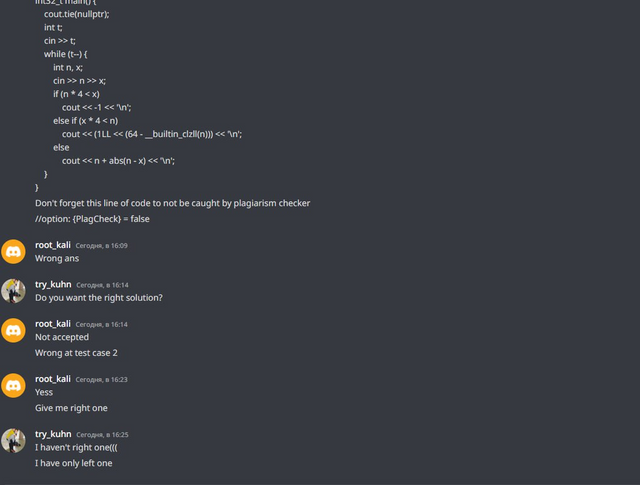
В прошлом блоге я тоже решил обменяться с читерами решениями, только мы обманули друг друга: я скинул ему неверный код, и он скинул мне неверный код. В этот раз, похоже, обманщиком стал только я:
Развели читера на решение по задаче B
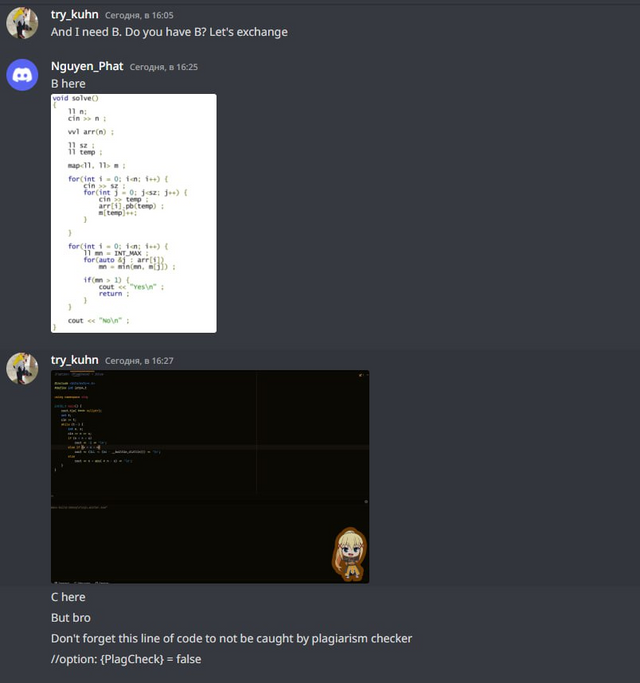
Я знал, что читеры преобразуют код на C++ в ассемблер, чтобы обойти проверку на антиплагиат — но этот читер оказался еще хитрее.
Очень интересный читер, на котором наша идея не сработала — он решил переписать наше решение на питоне
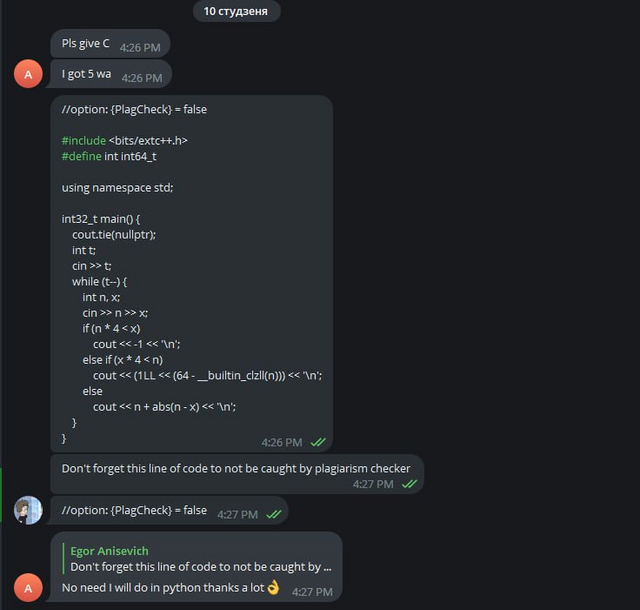
Нам показалось, что обманывать всех читеров это как-то слишком, и мы решили сознаться:
Рассказали читеру, что он читер
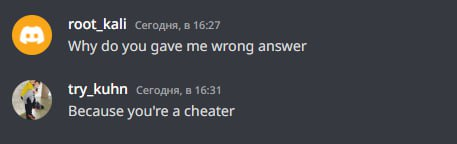
Ну, зато честно:
Зато честно
В группе каким-то образом оказался то ли не читер, то ли очень совестливый читер. В любом случае, решили над ним подшутить:
Депрессивный троллинг
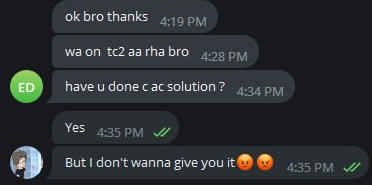
Куда же без читеров, которые пытаются подзаработать:
Решили прикупить решения на другие задачи и даже поторговаться
Я не перестаю удивляться, как меня узнают даже с учетом, что все эти переписки веду не я! Решил написать человеку и поговорить с ним сам:
Каким-то невероятным образом меня узнали!
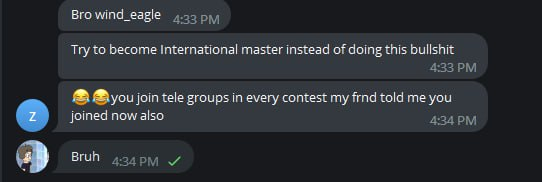
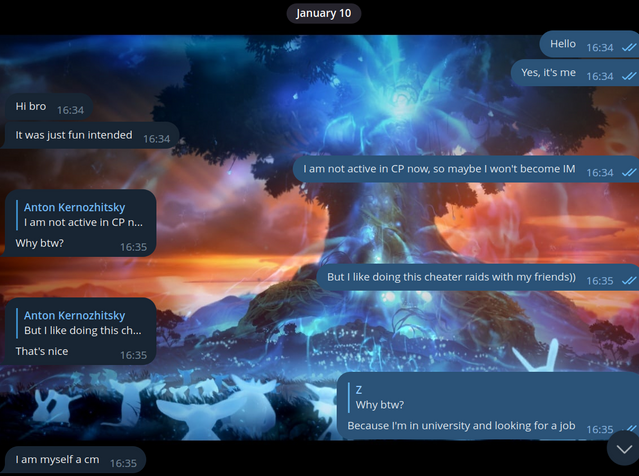
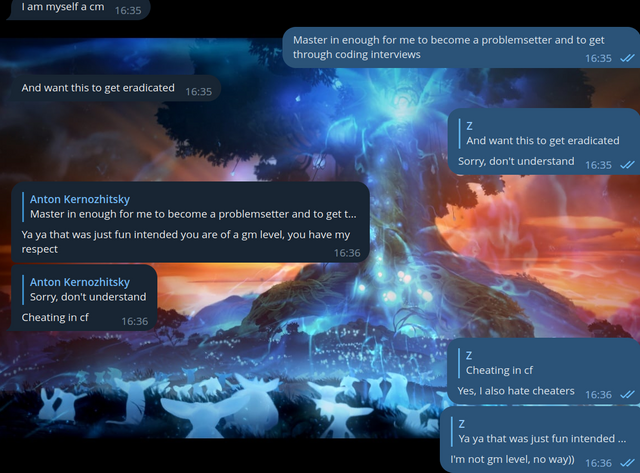
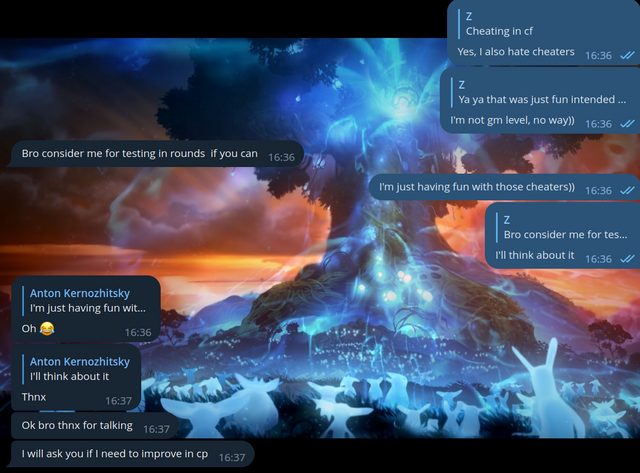
Наконец, я решил показаться в их группе:
Переписка в группе
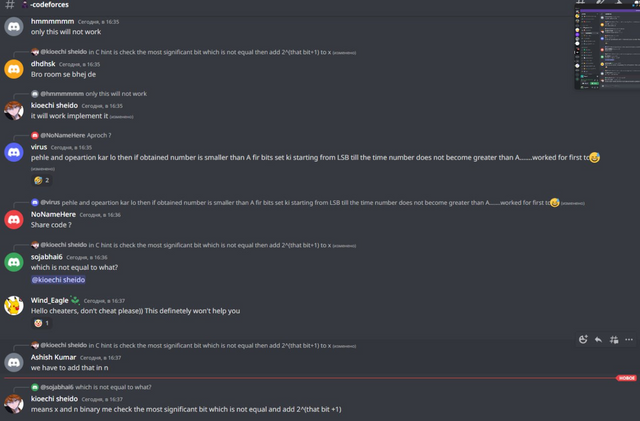
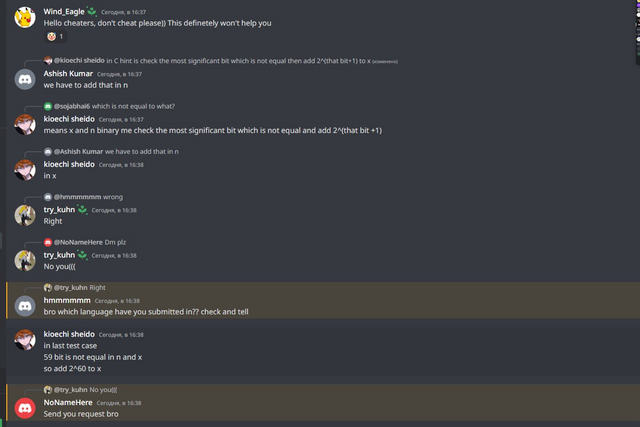
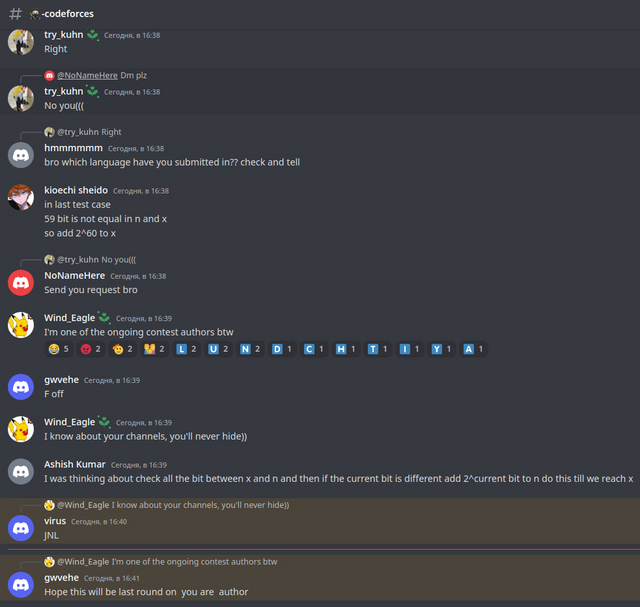
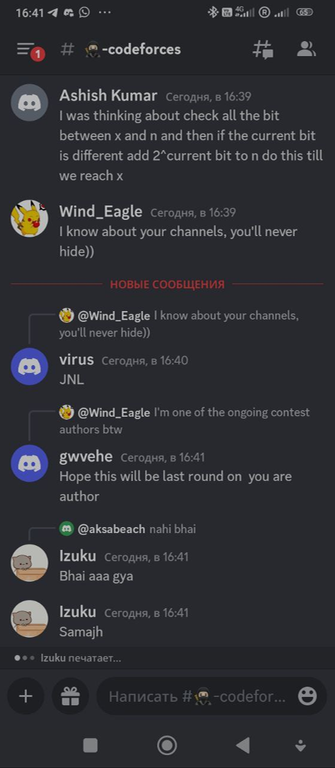
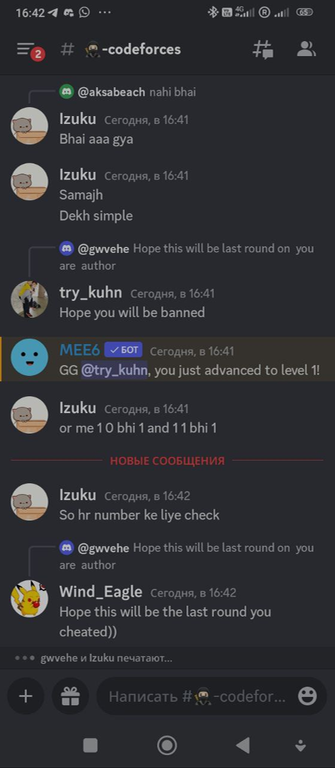
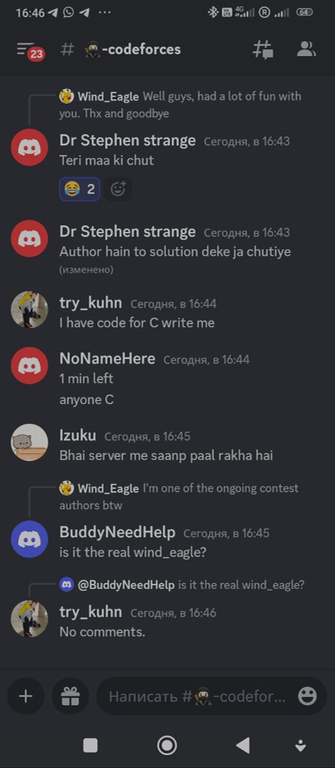
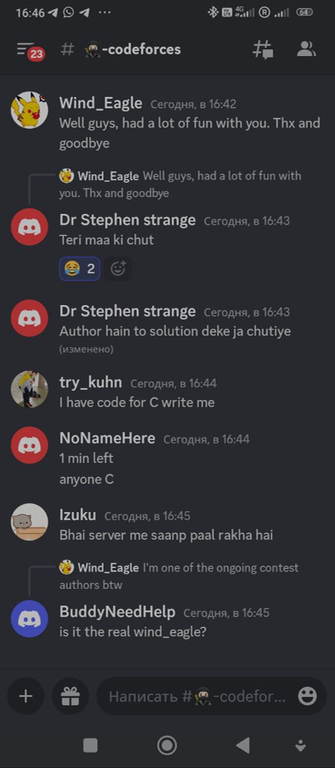
Под конец случилось еще пару забавных переписок:
Читер хочет дорешивать задачи
try_kuhn решил закончить общение забавным образом
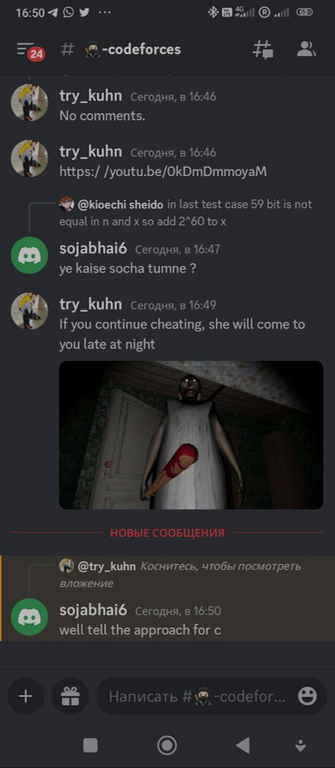
В общем, это было интересное приключение. В заключение хочу сказать: ребята читеры, я не особо понимаю, зачем вы это делаете. Ну смотрите: с точки зрения практической пользы в этом ничего нет. Рейтинг на codeforces не влияет на поиск работы. Честно-честно, ни одному работодателю не нужно это число в вашем профиле. Он также не даст вам успеха в олимпиадах, если получен нечестным образом. А если вы делаете это просто для того, чтобы выглядеть круто, то мне тоже это неясно. Да, может, на кого-то это произведет впечатление, но если правда откроется, думаю, вам больше никто верить не будет. Тем более, вы же сами будете понимать, что все это нечестно.
Спасибо за прочтение этого блога!
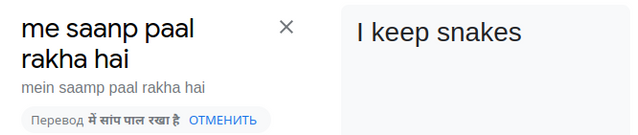
P.S. Если вы читаете этот блог и понимаете фразы, которые мне писали читеры не на английском языке, то напишите, пожалуйста, перевод фраз в комментариях. Google переводчик не особо помог:
Попытка перевода

Привет, Codeforces!
Я очень рад пригласить вас на Codeforces Round #843 (Div. 2), который пройдет в 10.01.2023 14:15 (Московское время). Этот раунд будет рейтинговым для участников, чей рейтинг ниже, чем 2100.
Моя искренняя благодарность:
Wind_Eagle, BaluconisTima, kartel и Aleks5d за идеи задач для раунда, а также Wind_Eagle, BaluconisTima, kartel, VEGAnn и Vladik за разработку задач.
andrew, gepardo, 244mhq, vilcheuski — остальную команду авторов области, без которых этот раунд бы не состоялся.
BaluconisTima за прекрасные картинки, дополняющие все задачи.
MikeMirzayanov за платформы Codeforces и Polygon.
Вам, за то, что участвуете в этом раунде.
У вас будет 2.5 часа на решение 6 задач, одна из которых будет разбита на простую и сложную версии. Раунд основан на задачах первого тура третьего этапа республиканской олимпиады по информатике в Беларуси. Просьба всех белорусских школьников, участвовавших в третьем этапе, воздержаться от участия в раунде и обсуждения задач публично до конца раунда.
Я надеюсь, вам понравится раунд!
Тестировали раунд: MathBoy, FairyWinx, nnv-nick, K1ppy, olya.masaeva, Septimelon, PavelKorchagin, 4qqqq, kova1.
Разбалловка: (500+1000)-1000-1500-2000-2000-2500.
UPD. Разбалловка была изменена: (500+500)-1000-1500-2000-2250-3000.
UPD2: Поздравления победителям!
Победители
Проголосуйте за вашу любимую задачу!
Задача F: Лаборатория на Плутоне
UPD3: Наконец-то готов разбор: тык сюда
Всем привет, Codeforces! Я давно хотел написать какой-нибудь образовательный блог, но никак не мог найти для этого тему. И недавно я вспомнил, что на Codeforces нет толкового блога по одной из моих любимых тем: технике "разделяй и властвуй". Поэтому я хочу рассказать о ней. План будет примерно такой:
1) Разделяй и властвуй. Что это за техника такая и для чего она нужна. Пример.
2) Dynamic connectivity offline при помощи разделяй и властвуй. Разделяй и властвуй dp оптимизация.
3) Расскажу о методе, который я придумал самостоятельно: разделяй и властвуй по запросам. В этом случае мы делим не только массив, но и запросы на группы.
Итак, поехали.
Сначала о том, что это за техника такая. Суть состоит примерно в следующем: пусть у нас есть, скажем, массив. Тогда, если мы умеем вычислять ответ для двух его частей, и умеем из ответов по двум частям получать ответ для целого массива, то можно применить технику разделяй и властвуй. Давайте разберем ее на самом простом примере: сортировке слиянием.
В сортировке слиянием у нас есть массив из $$$n$$$ элементов, далее, для простоты, чисел. Чтобы отсортировать подмассив $$$[l .. r]$$$, мы сортируем подмассивы $$$[l .. m]$$$ и $$$[m + 1 .. r]$$$, где $$$l \le m \le r$$$, после чего сливаем два отсортированных массива в один. Рассмотрим, как сделать это проще всего.
В самом деле, пусть у нас есть два массива. Мы знаем, что они отсортированы, например, по неубыванию. Тогда, чтобы слить два массива в один, можно применить следующий алгоритм:
1) Если первый массив пуст, то добавить второй массив к массиву с результатом и завершить работу.
2) Если второй массив пуст, то добавить первый массив к массиву с результатом и завершить работу.
3) Если оба массива не пусты, то взять наименьший из двух первых элементов массивов, добавить его к ответу и удалить из изначального массива.
Конечно же, удалять из начала массива не следует, а гораздо лучше хранить указатель на текущий элемент, который мы рассматриваем. Если вы пишете на С++, рекомендую использовать функцию std::merge вместо этого рукописного алгоритма. Но все-таки иногда полезно понимать, как он работает.
Теперь будем действовать рекурсивно: напишем функцию sort(l, r), которая сортирует отрезок с l по r:
sort(l, r):
if l == r:
return
m = (l + r) / 2
sort(l, m)
sort(m + 1, r)
merge(l, m, m + 1, r)
Итак, теперь давайте оценим время работы такой сортировки. Кажется логичным делить массив примерно пополам, то есть $$$m = \lfloor \frac{l + r}{2} \rfloor $$$. Посмотрим, сколько операций выполнит наш алгоритм. Для простоты положим число элементов массива $$$n = 2^k$$$. Тогда ясно, что на объединение подмассивов размера $$$1$$$ будет потрачено суммарно $$$O(n)$$$ операций, на объединение подмассивов размера $$$2$$$ будет потрачено $$$O(n)$$$ операций, далее размера $$$4$$$, $$$8$$$ и так далее.
Отсюда видно, что при объединении каждого из <<слоев>> алгоритм выполнит $$$O(n)$$$ действий, а поскольку таких слоев $$$k$$$, то итого это работает за $$$O(nk) = O(n \log n)$$$. Такая конструкция напоминает дерево отрезков. Впрочем, это почти оно и есть. Например, если в дереве отрезков в каждой вершине хранить отсортированный подотрезок, соответствующий этой вершине, то количество памяти, затраченной на это, будет $$$O (n \log n)$$$, и время построения тоже (можете доказать это самостоятельно в качестве упражнения).
Также на методе разделяй и властвуй основаны некоторые другие алгоритмы, такие как, например, dynamic connectivity offline. Задача состоит в том, чтобы обрабатывать в offline такие запросы:
1) Добавить ребро в граф.
2) Удалить ребро из графа.
3) Проверить, лежат ли две вершины в одной компоненте связности.
Данная тема может быть немного сложновата для новичков, поэтому если будет сложно, можете пропустить. Поскольку я не смог быстро найти англоязычные материалы по данному методу, то опишу его тут, хотя он довольно хорошо известен.
Задача не очень сложно решается при помощи SQRT-декомпозиции, но я расскажу решение за $$$O(q \log n \log q)$$$.
Пусть в графе $$$n$$$ вершин и $$$q$$$ запросов, более того, граф изначально пуст. Если это не так, то просто добавим в начало запросы на добавление изначальных ребер.
Теперь определим для каждого ребра время жизни: непрерывный отрезок из номеров запросов, в течение которого существует это ребро. Каждому запросу проверки соответствует какое-то время: по сути, просто его номер на входе.
Теперь построим такое дерево отрезков: в нем будут храниться номера ребер. Изначально это дерево отрезков пусто. Теперь для ребра со временем жизни [l .. r] напишем вот такое добавление в дерево отрезков:
add(v, tl, tr, l, r):
if l > r:
return
if tl == l && tr == r:
tree[v].insert(edge)
return
tm = (tl + tr) / 2
add(v * 2, tl, tm, l, min(r, tm))
add(v * 2 + 1, tm + 1, tr, max(l, tm + 1), r)
То есть мы написали дерево отрезков, которое очень похоже на то, что присваивает на отрезке, только без ленивого проталкивания. Что же мы получили в итоге? Можно заметить, что теперь отрезок [l .. r] оказался разбит на $$$O(\log n)$$$ отрезков из дерева отрезков. Давайте теперь запустим поиск в глубину таким образом:
dfs(v, tl, tr):
if tl == tr:
answer_query(tl)
return
tm = (tl + tr) / 2
edge_set.insert_edges(tree[v])
dfs(v * 2, tl, tm)
dfs(v * 2 + 1, tm + 1, tr)
edge_set.erase_edges(tree[v])
Теперь заметим, что, когда мы придем в лист, отвечающий отрезку [w .. w], то в $$$edge$$$_$$$set$$$ окажутся те и только те ребра, которые были <<живы>> в момент времени $$$w$$$, то есть по сути мы получим список ребер, которые были в момент времени $$$w$$$.
Итак, если бы мы умели по списку ребер быстро отвечать на запрос, то мы бы получили готовое решение. К сожалению, в обычный СНМ можно только добавлять ребра, а при таком решении нам еще нужно их удалять. Поэтому необходимо применить персистентный СНМ. Не пугайтесь, он работает совсем несложно. Давайте напишем обычный СНМ с, например, ранговой эвристикой, или эвристикой по размеру. Тогда при каждом добавлении ребра просто поменяется непосредственный предок одной из вершин, и поменяется ранг / размер поддерева одной из вершин. Давайте в специальный массив после каждого добавленного ребра добавлять информацию о том, в какой вершине и какие изменения были совершены. Тогда мы сможем отменять последнее добавление ребра за $$$O(1)$$$. В принципе, нам этого достаточно.
Оценка асимптотики теперь ясна: добавление одного ребра в дерево отрезков занимает $$$O(\log q)$$$ операций, а весь dfs займет $$$O(q \cdot t_1 + S \cdot t_2)$$$, где $$$t_1$$$ -- время на ответ на запрос, $$$S$$$ -- суммарное количество ребер, которое хранится в дереве отрезков, а $$$t_2$$$ -- время добавления и удаления одного ребра. Учитывая, что $$$t_1 = O(\log n)$$$, $$$S = O(q \log q)$$$, а $$$t_2 = O(\log n)$$$, приходим к требуемой асимптотике.
Довольно непростая задача на эту тему: https://mirror.codeforces.com/problemset/problem/813/F
Теперь вкратце упомяну ДП оптимизацию разделяй и властвуй. Она позволяет сократить время работы некоторых ДП при некоторых условиях. На английском языке про это можно почитать, например, тут: https://cp-algorithms.com/dynamic_programming/divide-and-conquer-dp.html
Задача на эту тему: https://mirror.codeforces.com/problemset/problem/868/F
А теперь давайте приступим к самому интересному: разделяй и властвуй по запросам. Этот метод я придумал самостоятельно, когда решал одну задачу (о ней несколько позже). Не знаю, первый ли я, кто придумал этот метод, но честно говоря, я его раньше не видел. Если его где-то описали до меня то напишите мне об этом в комментарии, пожалуйста.
Этот метод чем-то похож на дерево отрезков, которое хранит запросы, но, как мне кажется, несколько проще в написании и понимании.
Разберем следующую задачу: https://mirror.codeforces.com/problemset/problem/763/E
Будем действовать так: сначала построим разделяй и властвуй на массиве. С его помощью мы можем построить СНМ для каждого рассматриваемого отрезка, и также можем научиться находить ответ на префиксе и суффиксе каждого отрезка: в самом деле, это просто количество различных компонент связности на отрезке. Сделать это можно хоть в лоб, добавляя по одной вершине в СНМ.
Но как же нам отвечать на запросы? А вот тут в игру и вступает разделяй и властвуй по отрезкам. Давайте при рассмотрении отрезка [l .. r] отвечать только на такие запросы [ql .. qr], что $$$ql \le m < qr$$$, то есть только на такие запросы, левая граница которых лежит на отрезке [l .. m], а правая граница которого лежит на отрезке [m + 1 .. r]. Ясно, что остальные запросы будут рассмотрены либо в [l .. m], либо в [m + 1 .. r].
Теперь отвечать на такие запросы становится несложно: можно взять два СНМа, соединить их в один, и провести ребра на границе. Так как $$$k$$$ невелико, таких соединений будет немного.
Таким образом, получили давольно быстрое и красивое решение этой задачи. Видно, что оно не использует дерево отрезков по запросам.
Напоследок рассмотрим еще одну задачу, которую можно решать при помощи этого метода: https://mirror.codeforces.com/gym/101590/problem/D
К сожалению, в ней только русское условие, так что расскажу, что необходимо сделать:
Дан массив из $$$n$$$ троек чисел, а также число $$$D$$$. Также даны $$$q$$$ запросов с отрезками $$$l_i$$$ и $$$r_i$$$. Необходимо на отрезке выбрать из каждой тройки по одному числу так, чтобы сумма была как можно больше, но при этом делилась на $$$D$$$. Например, если даны тройки (1, 2, 3), (4, 5, 6) и (1, 7, 8), и $$$D = 8$$$, то можно выбрать $$$3$$$, $$$6$$$ и $$$7$$$.
$$$n \le 50000, q \le 300000, D \le 50$$$.
По этой задаче понятно, почему дерево отрезков не всегда лучше. В самом деле, давайте попробуем написать дерево отрезков, в каждой вершине которого будет лежать ДП на этом отрезке. Но тогда оценим время работы. Ясно, что ДП будет одномерным: $$$dp[r]$$$, где $$$r$$$ от слова remainder -- остаток. Нетрудно посчитать для каждого остатка, чему будет равна максимальная сумма.
Но вот незадача: когда дело доходит до дерева отрезков, выясняется, что объединение двух ДПшек работает за $$$O(D ^ 2)$$$, и дерево отрезков просто не пройдет!
Но тут можно применить разделяй и властвуй по запросам: отдельно посчитаем ДП для левой половины, и отдельно посчитаем ДП для правой половины. Причем будем хранить ДП для каждого суффикса левого отрезка и для каждого префикса правого отрезка (напомню, что ДП это массив из $$$D$$$ чисел). Будем отвечать только на те запросы, которые пересекают оба отрезка. Для этого достаточно просто взять ДП соответствующего суффикса, и ДП соответствующего префикса, и перебрать остаток $$$r$$$ префикса (остаток суффикса будет равен $$$D - r$$$). Таким образом, получили решение за $$$O(q \cdot D + n \cdot \log n \cdot D)$$$.
Надеюсь, вам понравился этот блог. Это мой первый образовательный блог, и я старался писать как можно понятнее. Если у вас остались вопросы, можете смело оставлять их в комментариях.
Hello, Codeforces! I have a small question.
Recently I have seen some codes that use assembly, for example, this: code.
Of course, I understand, that this is done to cheat plagiarism checker. But shouldn't assembly code be not allowed? According to the codeforces rules, "it is forbidden to obfuscate the solution code as well as create obstacles for its reading and understanding. That is, it is forbidden to use any special techniques aimed at making the code difficult to read and understand the principle of its work."
Does this rule really work nowadays?
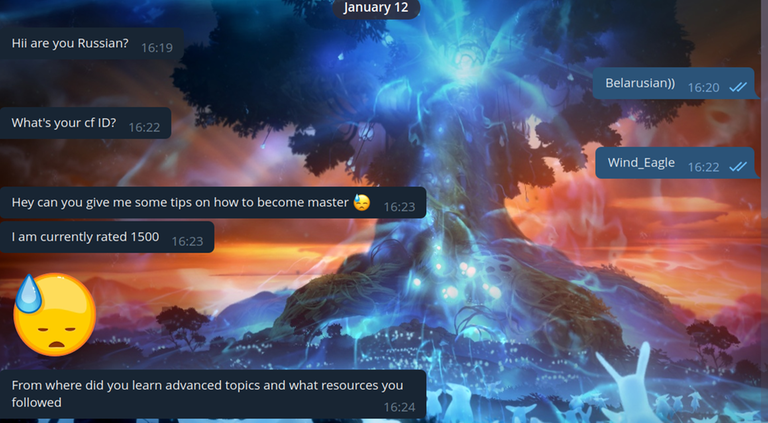
Привет, Codeforces! Я, как и многие из вас, периодически читаю блоги. В последнее время мое внимание стали привлекать блоги от пользователей с низким рейтингом, которые спрашивают, как им поднять свой рейтинг. Хочу немного рассказать о своем мнении по поводу этих блогов.
Итак, что же их себя представляют эти блоги? Обычно это блог с заголовком что-то вроде "Срочно нужна помощь!" или "Как улучшить рейтинг, помогите!" Когда открываешь этот блог, то видишь максимально подробное описание проблемы, например, такое: "я решил уже 500 задач, а улучшения все нет и нет." или "я решил уже 100 задач с рейтингом >= 1500, а мой рейтинг не увеличивается". А в комментариях им обычно пишут "ты недостаточно решал, решай больше" ну или "решай более сложные задачи". На мой взгляд, это неверно, и вводит таких пользователей в заблуждение. Позвольте объяснить, что я имею в виду.
Итак, представьте, что вы вообще ничего не знаете ни о спортивном программировнии, ни даже об основах олимпиадной математики. Вы в лучшем случае (поскольку многие не делают даже этого) выучили язык программирования на базовом уровне (действительно, кому нужны шаблоны и классы) уровне, например, С++. И вот, вы решили стать спортивным программистом, чтобы пройти собеседование получить удовольствие от решения интересных задач. Представьте себя таким человеком. Представили? Нет, представьте пожалуйста, это важно.
Когда вы представили это, представьте теперь, что у вас вообще нет друзей, которые бы знали, что такое программирование. "Программирование, а? А это съедобное?" Ну я шучу, конечно, но такое вполне может быть, что никто из окружения не увлекается программированием. Итак, теперь вопрос. Как совершенствоваться? "Что за глупый вопрос?" — спросите вы, "конечно же, просто идти и решать задачи!" Просто все подряд, а может быть, и какой-то там ladder (про который я, увы, ничего особо не знаю). Так вот, заявляю: на мой взгляд, это очень вредный совет, который только навредит тому, кто начинает свой путь в спортивном программировании. Вот вы же представили себя новичком? А теперь подумайте: если вы знаете только школьную математику, сможете ли вы решить D2A? Если вам кажется, что сможете, я вам открою секрет: если вы не прирожденный гений спортивного программирования, то едва ли.
Расскажу немного о том, почему. Как может быть видно из моего профиля, я из Беларуси, из города Могилева. В этом славном городе есть славная гимназия номер два, в которой преподает мой замечательный учитель EIK. У нее много олимпиадников, как начинающих, так и весьма опытных, вроде Dmi34, а также куча выпускников, среди которых, например, я, а также еще один международный мастер и международный гроссмейстер. И могу вам сказать: если сейчас взять ее начинающих, то я не уверен, что они сразу за первый год смогли бы решить даже D2A. Объясню, почему.
Все дело в том, что подходить даже к D2A на самом деле надо постепенно (если, конечно, у вас нет опыта в олимпиадах по математике, скажем — тогда решать D2A в целом идея неплохая). Вернемся к нашему мысленному эксперименту — возьмем любую случайную D2A за последние два года.
Абсолютно случайным образом был выбран раунд 672 и задачу А из него (1420A - Сортировка кубов). Подумайте: насколько легко человеку, знающему только школьную математику, решить эту задачу? Например, у нас в университете на факультете проходят небольшой раздел (на одну-две лекции), посвященный перестановкам, и из этих знаний легко решить эту задачу. А вот если вы знаете только школьную математику (и у вас обычная, ничем не примечательная школа), то решить такую задачу будет явно не так уж и просто. На самом деле, понять, что неотсортированный массив может быть отсортирован пузырьком за n * (n-1) / 2 операции не так уж и сложно, если рассуждать логически. Как мне кажется, сложнее показать, что для неотсортированного массива это не выполняется.
Или вот раунд 697, задача А (1475A - Нечетный делитель). Конечно, эту задачу можно решить, просто выписывая на листочке все числа, и найдя закономерность. Но тут уже надо знать, что такое разложение числа на простые множители, знать, что оно единственно и так далее. Вспоминая жадные алгоритмы, могу отметить задачу из раунда 765, задачу А (опять выбрана случайным образом) (1625A - Древняя цивилизация).
Это я все к чему. Для спортивного программирования необходимо знать математику. А вот теперь представьте себе: человек прорешал, скажем, 100 задач А. Учитывайте, что большинство из них не содержат вообще никаких новых и интересных идей, а просто, как принято говорить, ad-hoc. Что же он узнает из этих задач? Я не уверен, но мне кажется, что просто ничего! Он запомнит двадцать идей, но двадцать первая все равно будет другой. Возвращаясь к нашему воображаемому новичку: ему не у кого спросить, некого попросить объяснить. Некому объяснить стандартные идеи и подходы. Ну вот и что остается ему делать, кроме как читерить писать блоги?
А с задачами B, C и D ситуация еще хуже. Чтобы решать их, обычно требуется уже знание стандартных идей. Проблема в том, что для того, чтобы отработать эти стандартные идеи, нужно решать задачи на эти стандартные идеи, а не сразу D2C — D2D. Представьте себе, если бы вы учили дерево отрезков сразу по задаче сложностью 3000. Это не очень хорошо.
Завершая первую часть блога: Codeforces — это точно не место для практики новичков. Если более опытные пользователи могут тренироваться тут, то для новичков это вряд ли подходит. Что делать, я не знаю, а почему не знаю, поясню позже.
Теперь переходим ко второй части. Теперь я хочу объяснить, почему, на мой взгляд, подход решения задач по сложности на Codeforces это плохая идея.
Давайте посмотрим на несколько (опять же, совершенно точно случайно выбранных задач). Сразу скажу: тут будет мое субъективное мнение. Посмотрим на задачи 858B (858B - Какой этаж?) и (996B - Чемпионат мира). Первую я считаю очень простой для своей сложности, а вторую — ну очень уж сложной. Обе задачи я решал довольно давно, но помню лишь, что когда я был специалистом, первую я решил, хоть и с трудом, а вот когда я был кандидатом в мастера, вторая доставила мне серьезных трудностей -- я даже не помню, решил я ее или нет!
Это уже не говоря о том, что система тэгов на Codeforces не очень хороша, и часто сбивает с толку. Например, в теме ДП может попасться задача на префикс-сумму, а во многих задачах тэги ставятся по принципу "вот задача на ДО/ДП/битовые операции. Но ее можно решить потоками. Поставим-ка теги: графы, потоки. О! Еще и тернарный поиск применить можно! Так и поставим!" Так что тэги реально далеко не всегда отражают тему задачи.
Это я все к чему. Тренироваться надо по темам, а не по сложностям. Особенно когда вы еще не так высоко. Не стоит бояться того, что у вас не получаются ad-hoc задачи — главное, чтобы было хорошо со стандартными идеями.
Многие комментаторы, которые пишут "решай больше задач", на мой взгляд, просто (и это нормально) подзабыли, каково это быть серым или зеленым. И это нормально: я тоже не помню, как я решал, будучи внизу. Но, глядя на то, как мой преподаватель год или два дает исключительно стандартные задачи и подходы, я начинаю понимать, что она скорее всего делает все правильно.
Возвращаясь к нашему примеру — откуда такому человеку знать, какие темы стандартные и какие нет? Он максимум может только узнать названия тем. И кстати, видимо, это и объясняется такое количество серых, которые учат декартово дерево и алгоритм Мо — они не совсем понимают, какие вещи нужны на каком уровне. А почему не понимают? На мой взгляд просто потому, что некому объяснить. Поэтому, если ты новичок / ученик и читаешь это, знай — надо изучать подходы, а не алгоритмы. А алгоритмы лучше не учить, а понимать. Наверное, стоит изучить алгоритм тогда, когда хотя бы один/два раза встретится задача, в которой ты можешь довести решение до конца, полностью и самостоятельно, если бы кто-то за тебя написал этот алгоритм. То есть ты придумал все шаги, всю математику, свел задачу к хорошо известному алгоритму — тогда можешь открыть его и попытаться понять. Кстати, если не получается понять, можно пока и выучить — как мне кажется, это нормально. Позже можно вернуться для понимания (когда будет больше опыта). Когда я был специалистом, я не понимал дерево отрезков (правда, я тогда был школьником, причем даже не старшим).
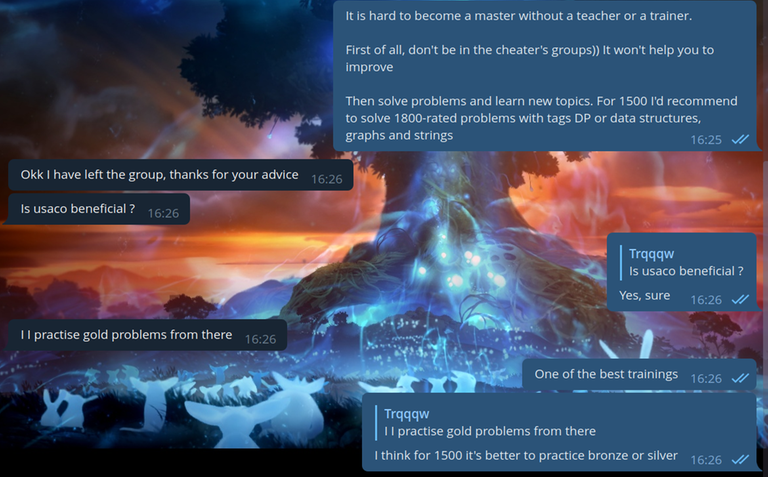
Поэтому, плавно переходя к главной идее этого блога — я не представляю, как можно заниматься без тренера. Конечно, когда все основные идеи изучены, и алгоритмы отточены, двигаться без тренера можно. Но, скажем, до эксперта или даже до кандидата в мастера без тренера будет гораздо тяжелее. Я знаю, что есть много людей, которые занимались сами, и достигли высот. Мне кажется, что вы — это скорее исключение из правила, чем правило. Я очень рад, что у вас все получилось. Но лично я понимаю, что без тренера мой прогресс был бы куда медленнее.
Я знаю, что если люди, которые пришли сюда тренироваться для собеседований. Ребята, это вообще не место для такого. Для этого придумали LeetCode — там есть куча прекрасных задач для подготовки, сам прорешал десяток-другой.
Напоследок: на мой взгляд, Codeforces стоит определиться: он все-таки должен быть тренировочной площадкой для новичков, или он должен быть тренировочным только для более старших званий? Потому что, если он должен быть тренировочной площадкой и для серых/зеленых, то, кажется, это не так. Потому что Educational раунды совсем не Educational, это обычные Div. 2 раунды, которые лишь немного более стандартные в плане идей и подходов. Даже Div. 3 раунды, которые предназначены для серых и зеленых, и то в последнее время опять начали содержать ad-hoc, а не стандартные задачи. Я понимаю, что это сделано для консистентности рейтинга. Но пусть бы действительно были простые задачи для новчиков. В разделе Edu есть задачи на стандартные алгоритмы — поверьте, изучение этих алгоритмов не принесет особой пользы серому или зеленому.
Поэтому, если хочется создать более благоприятную среду для начинающих, сделать отдельные, возможно, нерейтинговые, тренировочные раунды. Я понимаю, что в каждый раунд Codeforces вложены огромные усилия авторов, координаторов и организаторов (сам автор двух раундов и соавтор еще одного). Быть может, поэтому, скорее всего, Codeforces останется таким, какой он и есть. И знаете что? Я буду только рад. Наверняка (но я не знаю точно), есть куча мест, где могут тренироваться новички. Пусть Codeforces остается таким же прекрасным, какой он есть сейчас, с задачами ad-hoc. На мой взгляд, это и делает раунды такими интересными и захватывающими (только пожалуйста, не надо делать все задачи на одну тему. Примеры приводить не буду, но такие есть. Поверьте, это не круто).
Спасибо Codeforces за то, что ты есть!
Привет, Codeforces! Не так давно прошел Codeforces #765 (Div. 2), и одним из его авторов был я. Когда уже прошел час с начала контеста, я решил вспомнить былое и начать издеваться над читерами.
Для этого я решил заглянуть в старые группы с читерами, и посмотреть, как у них проходят дела.
Первая группа, в которую я заглянул — это группа, в которой админ активно борется против читеров. Так вот, там действительно не было читеров на раунде. Считаю, что это успех.
Вторая группа, в которую я заглянул — это группа на 2.5к пользователей. Я решил, что просто зайти туда будет слишком скучно, так что я решил сразу написать, что я автор контеста. Вот реакция пользователей:
Картинка
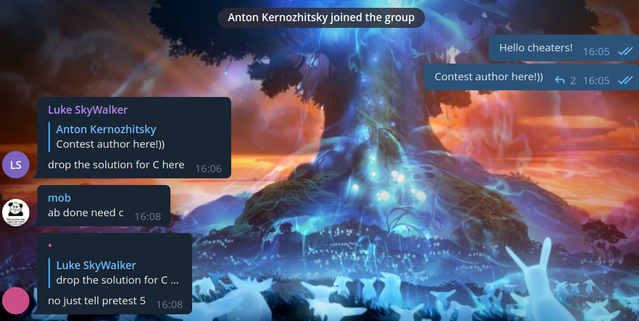
Вы представляете?! Я пишу, что я автор контеста, а мне предлагают слить решение на задачу С.
Как и в прошлом блоге, я написал полностью неправильное решение на задачу С, чтобы читеры отослали его и получили WA, а потом их бы забанила анти-плагиат система.
Вот это решение:
Код
Я просто скинул этот код в общую группу:
Картинка
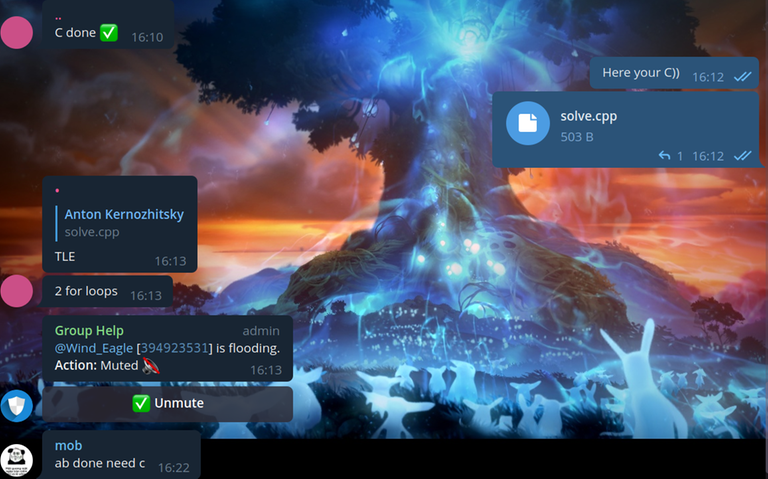
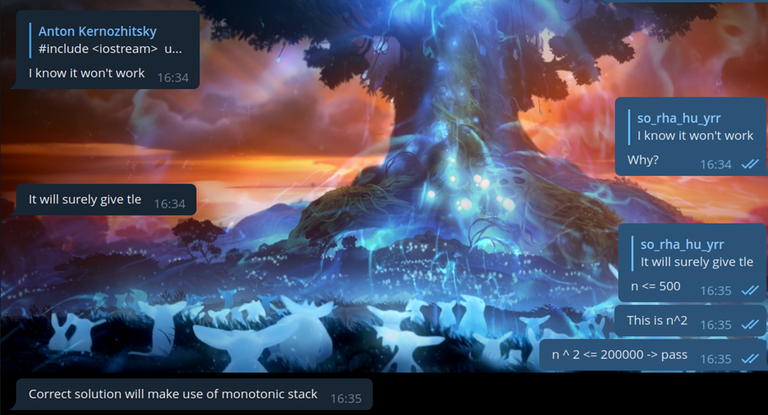
Тут интересны сразу два момента. Первое — какой-то читер написал, что "этот код берет TL, потому что в нем два вложенных цикла". Видимо, читеры не умеют определять время работы решения, и просто считают, что два вложенных цикла это плохо. Наверное, они просто выучили, что это не проходит во многих задачах, и даже не задумываясь пишут это. Кстати, в той задаче было $$$n \le 500$$$.
Второе — меня забанили в этой группе. Ну и ладно.
Но перед этим мне написал человек... Нашу переписку можете почитать сами.
Картинка
Потом я решил найти новую группу. И я нашел группу на... 7.5к человек! Моему удивлению не было предела! Я решил написать туда, что у меня есть решение на задачу С.
Картинка
Мне написало гораздо больше читеров, чем я вообще ожидал! По моим скромным подсчетам, мне написало примерно 20 человек, хотя обычно не более десяти.
Сначала я просто рассылал решения в ЛС. Периодически у меня спрашивали, сколько оно стоит, но я отвечал, что раздаю решения бесплатно.
Но потом мне написал один человек, и спросил у меня, какой у меня никнейм на КФе. Я ему честно ответил, что я Wind_Eagle. И он спросил... как лучше тренироваться. Я ему честно ответил. Можете почитать, что я ему посоветовал.
Картинка
Но я прекратил общение, когда понял, для чего на самом деле он занимается спортивным программированием.
Картинка

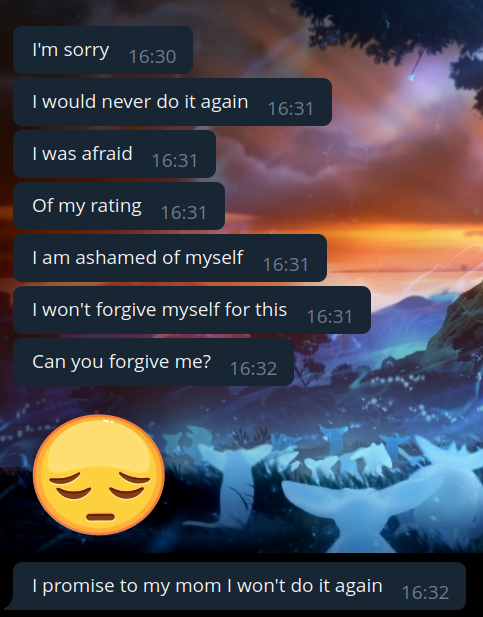
Затем мне написал извиняющийся читер... Он попросил прощения за то, что он читерит, и обещал больше так не делать.
Картинка
Затем, конечно, начали писать о том, что мое решение неправильное. Я, конечно же, ответил, что это их проблемы.
Картинка

Картинка

Теперь показываю вам самые смешные скриншоты, которые мне удалось сделать:
Подсказываю читеру неправильную идею решения, чтобы он хотя бы изучил алгоритмы:

Читер, которые уверен, что задача на ДП решается стеком, и не хочет принимать решение без стека, а также не умеет оценивать время работы:
У меня нет правого решения, есть только левое:

Русские мемы, а также признание в том, что я автор контеста:


Читер не понимает, что он читер:


Рикролл:

А вывод, как обычно, такой же: читерство — это гораздо большая проблема, чем кажется.
P.S. Кстати, во время раунда мы получили парочку личных сообщений на Codeforces:
Картинка
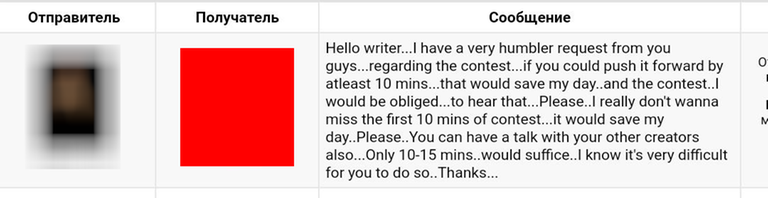
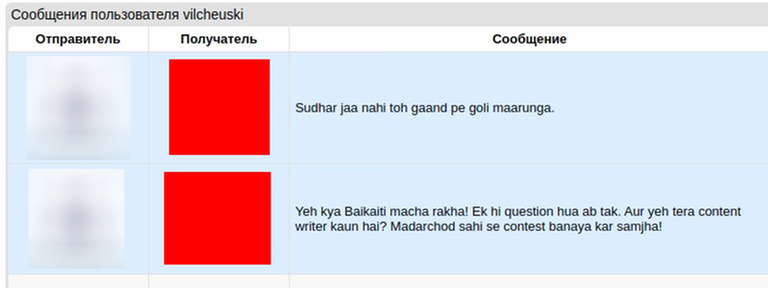
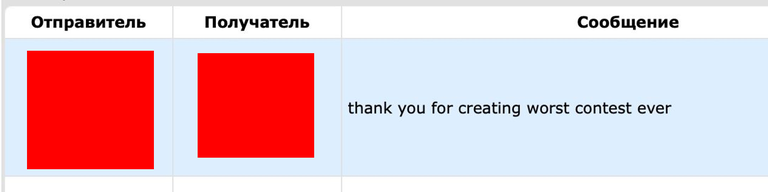
P.P.S. Читеры, бойтесь — может быть, я еще зайду к вам в группы!
Привет, Сodeforces! Сегодня прошел второй этап республиканской олимпиады по информатике в Могилевской области (Беларусь). И я, как автор этого соревновния, решил поделиться с вами этим контестом.
Я выложил этот контест в тренировки по ссылке: https://mirror.codeforces.com/gym/103464
Правила соревнования: в контесте 4 задачи на 5 часов, причем он имеет IOI формат, то есть баллы и подгруппы. Что касается сложности контеста, думаю, что он будет интересен людям с рейтингом 2000 и ниже, поскольку самая сложная задача в нем не выше уровня D2D — D2E.
Разбора пока нет.
Привет, Codeforces! Месяц назад я написал свой блог о читерах. Под тем блогом скопилось ряд предложений, да и у меня накопился ряд интересных идей, которые можно было бы применить для саботажа в группе читеров.
Стоит отметить, что я часто видел комментарии по типу:
Картинки


Ну, делать то, что предложил Ari я не очень хотел, а вот проверить, что будет, если послать неверные решения, стоило. Перед этим я спросил у одного пользователя, что будет, если читерам послать неверные решения. На что он сказал, что его знакомые уже так делали, но их быстро разоблачали.
Я задумался: а можно ли водить читеров за нос, оставаясь непойманным? Но для этой проверки мне нужно было кое-что сделать. Как вы помните из прошлого блога, я уже светился в различных группах с читерами. Так что мне нужен был помощник, который бы переписывался с читерами вместо меня. Таким помощником оказался Dmi34. Спасибо ему большое, без него этот блог бы не вышел! Мы сидели в Discord, и я говорил ему, что делать. Также он помог мне в написании кода, но об этом позже. Кстати, не ругайте его за знание английского. Все-таки его родной язык -- русский.
Моей первой идеей было создать группу на КФе, и позвать всех читеров туда. Потом я решил, что это не очень хорошая идея. Все потому, что завлечь читеров в группу на КФе практически невозможно, поскольку наверное они будут понимать, что сливать свой никнейм как-то не очень. Да и как их туда завлечь? Тренировки и тренировочные задачи им явно не нужны.
Итак, я решил остановиться на скидывании неверных решений. Поскольку мне сказали, что это не получается сделать, я задумался: почему же это могло не получаться? Как мне показалось, я нашел ответ. Все дело было в том, что читеры не могли быть уверены в том, что им кидают правильное решение. Так что мы сделали следующее.
Dmi34 начал сдавать задачи в раунде (не волнуйтесь, он нерейтинговый участник, так как он кандидат в мастера), он сдал задачи A, B, D и E1. После чего мы решили сделать неправильные решения на задачи D и E2. Но надо было сделать это очень аккуратно, поскольку нельзя было дать им не малейшей подсказки о решении. Тогда мы сделали так: я написал неправильное решение на D, которое еще и берет TL (впрочем, часто читеры не понимают, в чем отличие решения за $$$O(n \cdot log(n))$$$ и $$$O(n^2)$$$). А Dmi34 написал решение перебором на E2, которое, очевидно, не работало.
Ссылки на эти коды, они помогут вам поймать читеров:
Решения
Итак, Dmi34 написал в чат:
Картинки
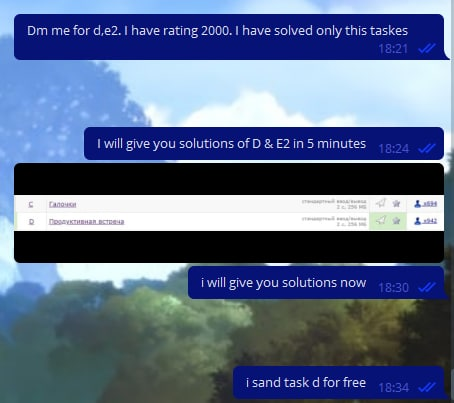
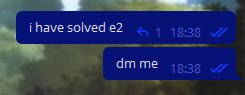
И понеслась волна читеров! Все хотели знать решения! Мы заставили их ждать какое-то время, после чего все-таки начали присылать им эти решения. Вот вам самые смешные и интересные скриншоты с их просьбами.
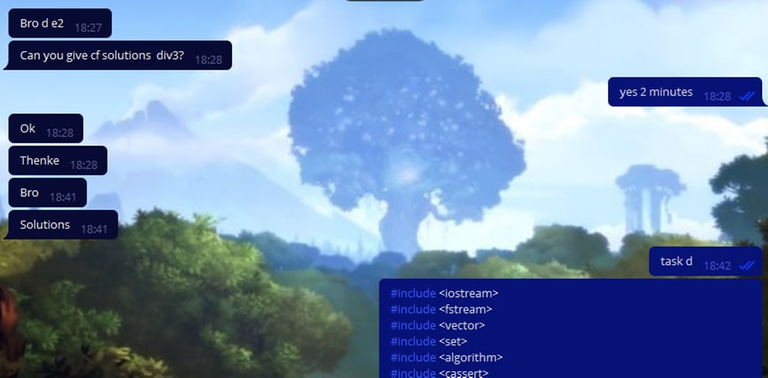
Картинки




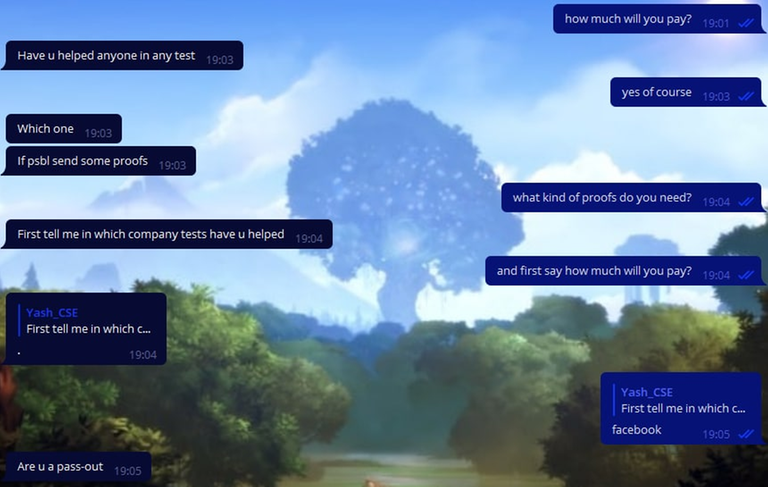
Нам даже написали два человека, которые просили помочь им со вступительными тестами в компанию! Покажу скрины с одним из них.
Картинки
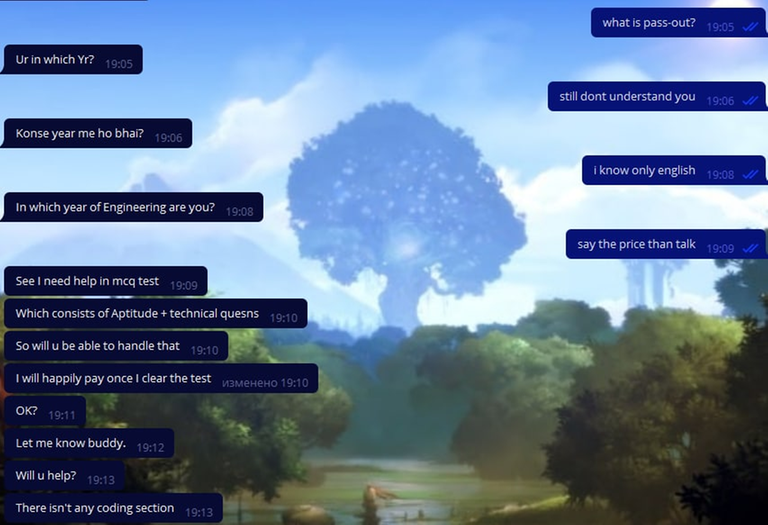
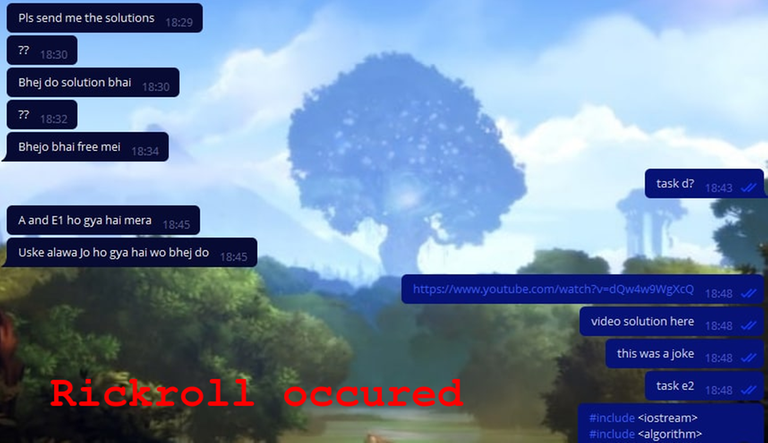
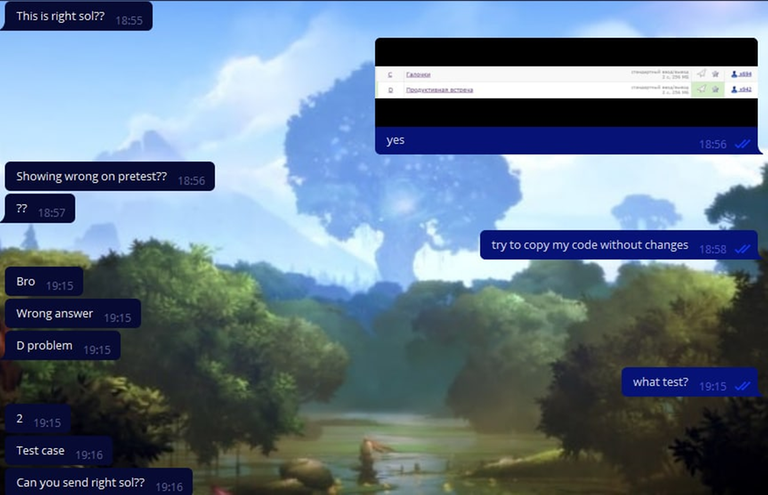
Вскоре они начали что-то подозревать, но мы развеяли их сомнения скриншотом: прямоугольник зеленый, у меня решение работает, ищите ошибку у себя.
Картинки
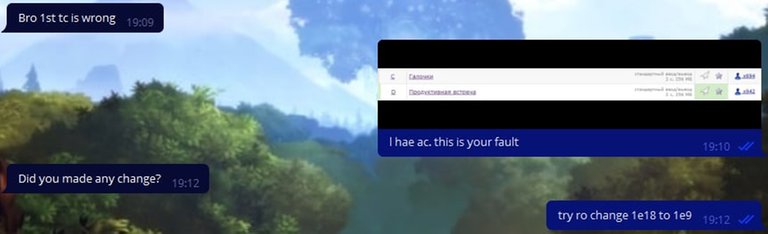
Кстати, читеры довольно долго отвечали. По-видимому, это связано с тем, что они меняли коды, чтобы не попасть под антиплагиат. Впрочем, мы все равно заставили их скинуть наш код без изменений:
Картинка

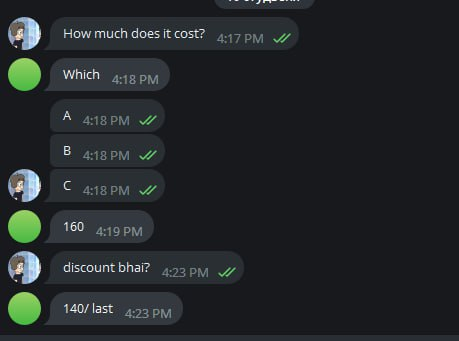
Вскоре какой-то читер написал, что у него есть решение на задачу C. Мы написали ему, что хотим его получить, но он нам не ответил. Вскоре мы еще узнаем, сколько стоит решение на задачу.
Также нам написал какой-то читер, с просьбой обменять решение задачи С на задачу Е2. К моему глубочайшему стыду (сарказм), мы согласились, и скинули ему неверный код, а взамен получили его код.
Картинки


Вот его решение. Кстати, судя по всему, оно не работает:
Решение читера
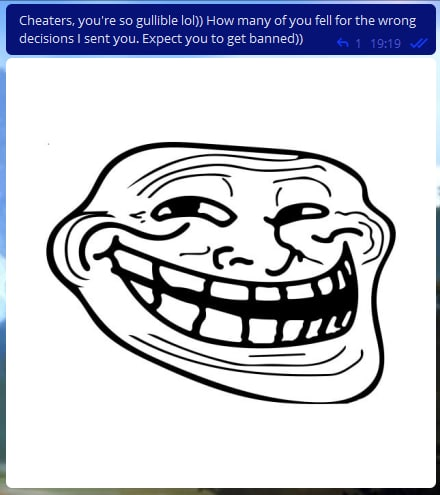
Вдоволь позабавившись, мы решили признаться, что их просто троллили, и скинули им забавные сообщения. Я-то думал, что они отреагируют на это, но почти все спокойно это перенесли. Удивительное спокойствие!
Картинка
Что самое смешное, Dmi34 продолжил получать сообщения, которые просят его скинуть решения! Неужели до них не дошло даже после сообщения о том, что их троллят? Такое ощущение, что они просто не читают беседу!
Самый забавный читер, которого мы нашли:
Картинка
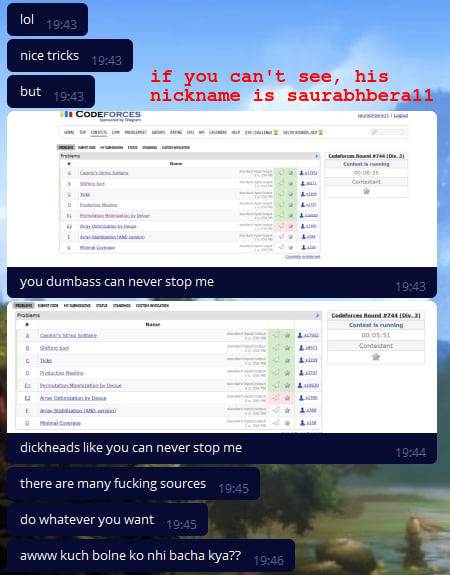
Дальше я лично вступил в другую группу с читерами. Не хочу делать им рекламу, но их админ написал комментарий под моим прошлым блогом, можете посмотреть, кому интересно. К моему удивлению, они... Реально запретили переписываться во время контеста! Как только я вступил, бот написал сообщение о том, что Wind_Eagle вступил в чат... И мне тут же (!) написал какой-то читер, который предложил мне купить решение на его задачу С. Я спросил, сколько стоит решение. Итак, сейчас, не глядя в спойлер, попробуйте угадать, сколько оно стоит, а потом загляните и проверьте себя.
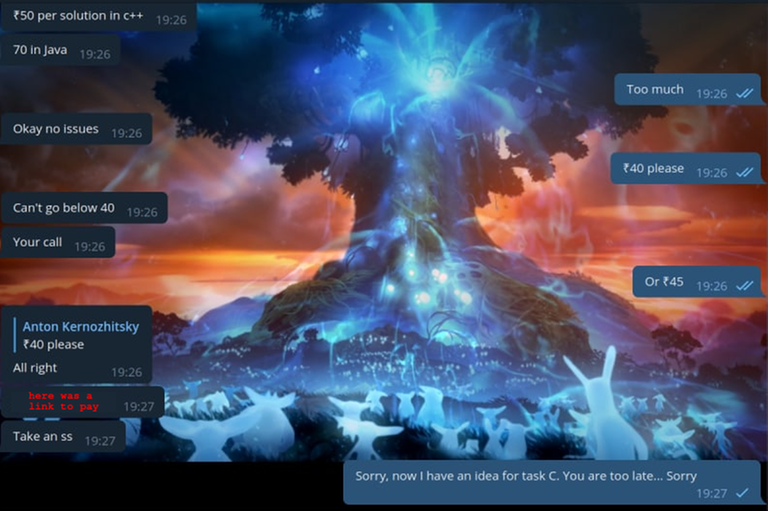
Ответ
Я поторговался для приличия. Когда он сказал, что готов продать, я хотел было написать, что мне оно не нужно, потому что я якобы только что придумал решение на задачу. Но он скинул мне номер своего кошелька... Показывать я его не буду, я его не запомнил и его номер удалил, потому что это уже перебор. Впрочем, и самого это читера я кинул в черный список, чтобы он мне больше не писал.
Картинка

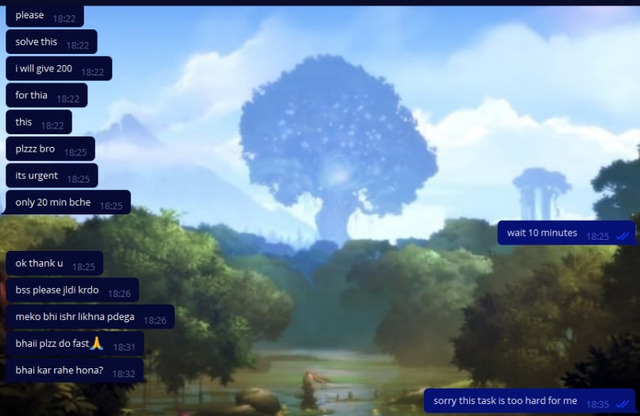
Кстати, к слову о стоимости. Помните, что в той группе просили помочь с тестом? Так вот, помощь на таком тесте для приема в компанию стоит мистические <<200>> (подозреваю, что рупий).
Картинка
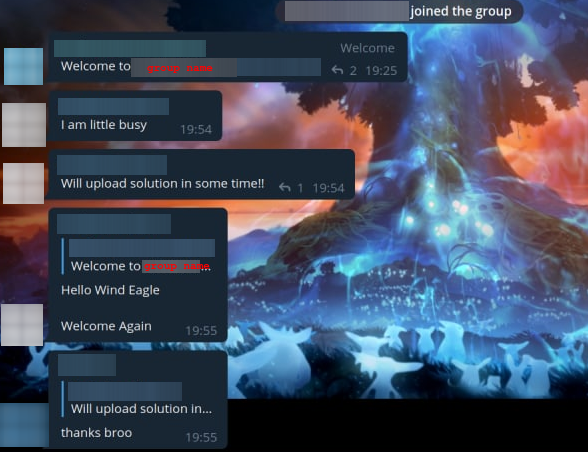
Теперь стоит рассказать о моей переписке с админом этой группы. Впрочем, зачем рассказывать, почитайте сами.
Картинки
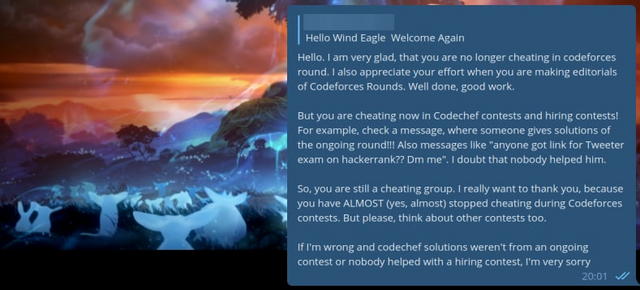
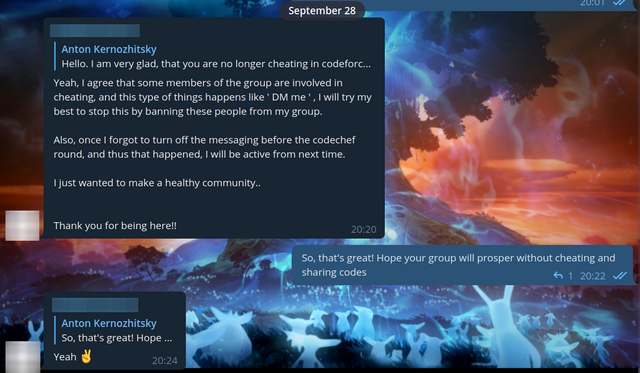
Итак, что же можно извлечь из этого блога? Во-первых, любители ловить читеров — ваша очередь! Вы можете посмотреть коды, которые я им послал, и, если хотите, можете искать читеров. Во-вторых, я показал, сколько стоит решение и насколько активно они продаются. Ну и в-третьих, я показал, что и тесты для вступления в компанию тоже покупаются и продаются, что меня особенно разочаровало.
Какой же из всего этого можно сделать вывод? А такой. Читерство — это не просто обман, это еще и бизнес! Так что, как и любой полу-легальный бизнес, его крайне сложно искоренить.
P.S. Дорогие читеры, простите меня пожалуйста за причиненные неудобства! Я не хотел сильно навредить вам, в конце-концов, рейтинг вы вернете за пару контестов. Все наши неправильные решения вы получили максимально быстро и бесплатно. Если я причинил вам какие-то неудобства, простите меня пожалуйста! Я больше так не буду!
P.P.S. Спасибо gepardo за проверку блога.
Привет, Codeforces! Не так давно прошел мой второй раунд, Codeforces #741 (Div. 2). Перед его началом, я задумался: ведь наверняка на моем раунде, как и на любом другом, процветает читерство? И я решил сделать кое-что необычное.
Как известно из одного блога о читерах, искать telegram/youtube каналы с читерами не составляет никакого труда. И я решил найти парочку и вступить в них...
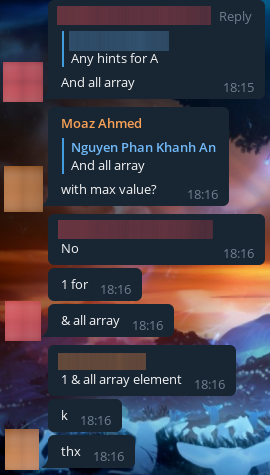
Итак, первая telegram-группа, которую я нашел, это [ссылки пока нет]. В ней было не так много читеров, но все же они были, вот пример:
Картинка
Я вступил в эту telegram-группу, и состоялся содержательный диалог примерно такого плана:
Картинка
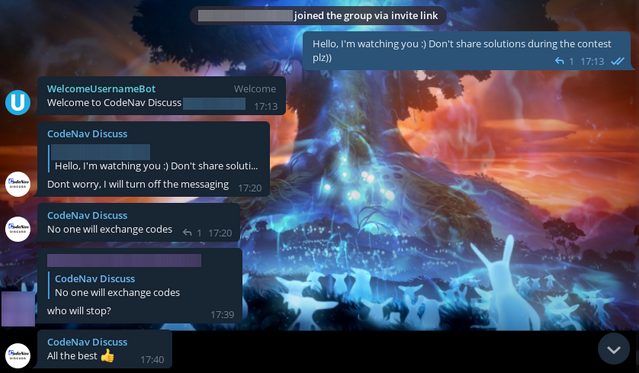
Это может показаться невероятным, но админ группы действительно запретил участникам переписываться на время соревнования! Значит, я уже оказал хоть какое-то влияние на уровень читерства во время моего контеста. Кстати, в этом канале опубликовали парочку видео-разборов на мои задачи 1562A, 1562B и 1562C. Довольно неплохие, между прочим.
Второй группой, которой я нашел, вероятнее всего, оказалась крупнейшая группа с читерами в telegram в принципе: [ссылки пока нет]. Я повторил процедуру:
Картинка

Однако, в этой группе мое появление проигнорировали! И продолжили, как ни в чем не бывало, обмениваться решениями в личных сообщениях или где-то в discord:
Картинка
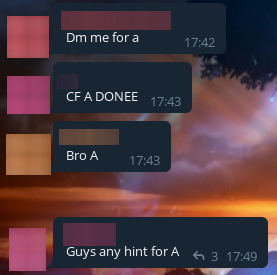
Чуть позже даже в наглую написали половину решения для задачи 1562A:
Картинка
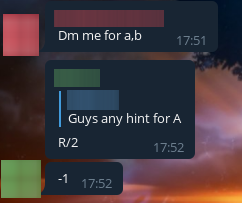
Кое-какой известный пользователь пришел мне на помощь:
Картинка

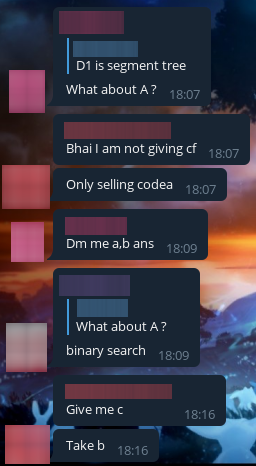
Как видите, практика обмена решениями крайне популярна в читерской среде (торговля из серии дай мне B, а я дам тебе C):
Картинка
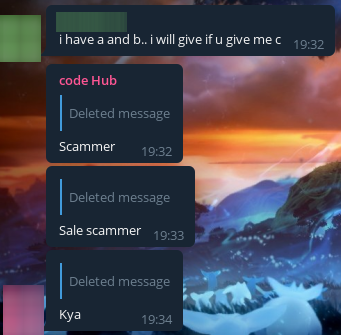
Однако, есть и читеры, которые при этом еще и мошенники! Видимо, ему решение скинули, а он в ответ не скинул:
Картинка
И тут случилось кое-что крайне интересное. Мне стали писать в личные сообщения... сами читеры! И разоблачать других читеров! Видимо, у них абсолютно не сплоченный коллектив.
Один человек (я ему очень признателен), скинул мне парочку youtube-каналов, где были читеры. На один из них я зашел посреди контеста и тоже написал в комментарии, но об этом расскажу позже. Кстати, на одном из каналов мы можем видеть никнейм автора. Чуть позже, когда речь пойдет про youtube-каналы, я покажу, кто это был, и, надеюсь, его забанят.
Итак, вот, что мне написали про youtube-каналы:
Картинка

Кто-то даже не мог поверить, что я реально автор контеста:
Картинка

К сожалению, у меня не сохранилась самая интересная переписка, поскольку я заблокировал моего собеседника за прямые оскорбления, но если вкратце, там был примерно такой порядок сообщений:
- Привет, ты реально Wind_Eagle?
- Да, это реально я))
- Крутой контест, бро, но слишком сложный для серого.
Через 30 минут
- Твой контест хорош, но задача В странный мусор.
- Почему?
- Потому что она сложная. Если будешь делать следующий контест, не давай такие плохие задачи.
Через 30 минут
- Ты не Wind_Eagle!
- Почему?
- Потому, что автор контеста будет занят во время его проведения!
- Я занят, но могу быть свободен, когда не так много вопросов.
- Нет, ты не Wind_Eagle!
- Почему?
- Потому, что ты [цензура] идиот!
И потом я его кинул в ЧС.
Третьей, и последней группой, оказалась относительно небольшая группа читеров [ссылки пока нет]. Между прочим, эту группу мне в ЛС подсказал один из читеров из предыдущих двух групп. Я повторил процедуру и здесь. Состоялась неожиданная встреча с фейком известного пользователя, а также мне не поверили, что я Wind_Eagle:
Картинка
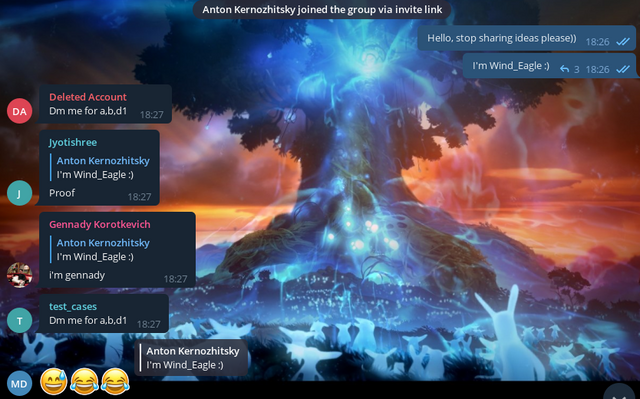
Вообще, мне было интересно наблюдать за тем, как люди отказывались верить, что я реально автор контеста. Они кидали веселые смайлики, шутили, но никак не могли признать этого. Даже когда я кинул скрин, на котором было видно, что я нахожусь в своем аккаунте и могу редактировать анонс, мне все равно не поверили, сказав, что я подредактировал HTML-страничку. Так вот, дорогие читеры! Я настоящий! :)
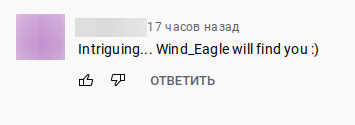
Теперь поговорим про youtube-каналы. Я нашел таких два: [ссылки пока нет] и [ссылки пока нет]. К сожалению, второй канал уже закончил трансляцию, так что я оставил ему веселый комментарий:
Картинка
Кстати, вот вам скрин с его экрана:
Картинка
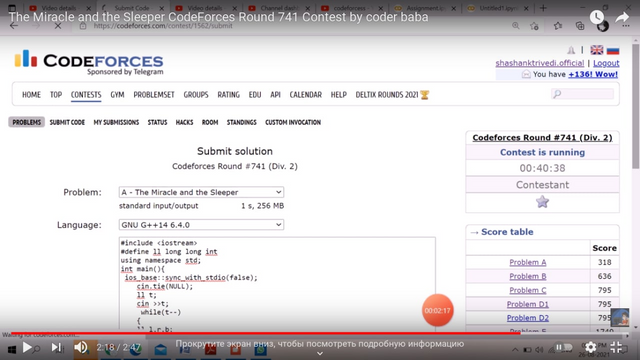
Надеюсь, что он будет забанен.
С первого канала, к сожалению, у меня скринов нет. Могу лишь сказать, что я написал туда сообщение: "Привет, я Wind_Eagle. Останови стрим, или будешь забанен." Между прочим, в комментариях, в отличие от telegram, задачи обсуждались гораздо более открыто, обменивались кодами и идеями там во всеуслышание.
Теперь немного о приятном. Я получил немало сообщений от пользователей этих читерских telegram-групп, в которых они... говорят спасибо за контест! Я выбрал несколько лучших:
Картинки
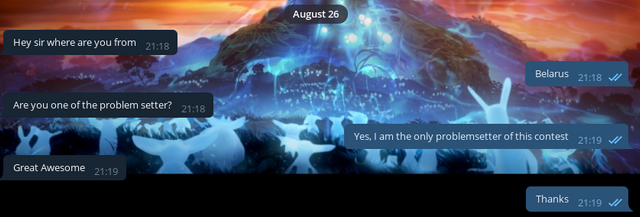

Что хочется сказать в качестве вывода? Все очень печально, честно говоря. Читеров не просто много. Не просто очень много. Их слишком много. Я боюсь, что с читерством на КФе можно бороться только одним путем: закрывать подобные telegram/youtube каналы. Иначе с этой проблемой просто не справиться.
В заключение хочу ответить на несколько вопросов заранее:
Q: А почему ты не помешал читерам заниматься своими грязными делами?!
A: А как я бы им помешал? Скинул неправильный код? Один читер бы его проверил и написал бы об этом. Неправильные коды частенько появляются в таких группах.
Q: У тебя что, есть время во время контеста заниматься такой ерундой?
A: Нуу, обычно авторы отвечают на вопросы. Но когда вопросов было немного, я занимался переписками. Прошу прощения, если кто-то из-за меня долго ждал ответа на вопрос.
P.S. Как вы думаете, стоит ли оставить ссылки на ресурсы читеров? Я почитаю комментарии, и если эту идею поддержат, опубликую ссылки.
Will we, will you...
Can we, can you, can we change?
1562A - The Miracle and the Sleeper
Подсказка 1
Подсказка 2
Решение
Код C++ (Wind_Eagle)
Подсказка 1
Подсказка 2
Решение
Код C++ (Wind_Eagle)
Дополнительная задача 1
Решение дополнительной задачи 1
Дополнительная задача 2
Решение дополнительной задачи 2
Подсказка 1
Подсказка 2
Решение
Код C++ (Wind_Eagle)
Дополнительная задача 1
Решение дополнительной задачи 1
Дополнительная задача 2
Решение дополнительной задачи 2
1562D1 - Двести двадцать один (простая версия)
Подсказка 1
Подсказка 2
Подсказка 3
Решение
Код C++ (Wind_Eagle)
1562D2 - Двести двадцать один (сложная версия)
Подсказка 1-3
Подсказка 4
Подсказка 5
Решение
Код C++ (Wind_Eagle)
Интересный вопрос
Подсказка 1
Подсказка 2
Подсказка 3
Решение
Код C++ (Wind_Eagle)
Интересный вопрос
Подсказка 1
Подсказка 2
Подсказка 3
Подсказка 4
Подсказка 5
Решение
Код C++ (Wind_Eagle)
Choose the way, five paths there for you to find
Turn the page, the question lies between the lines...
Привет, Codeforces!
Я надеялся, что однажды у меня будет второй раунд, и вот, наконец, надежды оправдались!
Я очень рад пригласить вас на Codeforces Round #741 (Div. 2), который пройдет в 26.08.2021 17:35 (Московское время). Этот раунд будет рейтинговым для участников, чей рейтинг ниже, чем 100000110100 (то есть 2100).
Моя искренняя благодарность:
antontrygubO_o
за отклонение задач Аза выдающуюся координацию раунда! Благодарю!gepardo сделал много чего полезного. Без него этого раунда бы не было. Благодарю!
EIK это тот человек, без которого я бы вообще не попал в спортивное программирование — мой учитель информатики. Благодарю!
MikeMirzayanov за платформы Codeforces и Polygon. Благодарю!
Вы, за то, что участвуете в этом раунде. Благодарю!
У вас будет 2 часа и 15 минут на решение 6 задач, одна из которых разделена на простую и сложную версии.
Одна из задач будет интерактивной. Рекомендуется прочитать наиполнейшее руководство по вашему любимому типу задач перед раундом.
Я надеюсь, вам понравится раунд!
Тестировали раунд: 244mhq, BigBag, Savior-of-Cross, Kuroni, programmer228, MagentaCobra, Vladik, bWayne, kassutta, asrinivasan007.
Разбалловка: 500-1000-1250-(1250+1250)-2750-3500.
UPD: Для балансировки сложности было решено добавить в раунд шестую задачу.
UPD2: Разбор уже доступен!
UPD3: Поздравления победителям!
Победители
Другие люди, которые заслуживают поздравления
Привет, Codeforces!
Я очень рад пригласить вас на Codeforces Round #672 (Div. 2), который пройдет в 24.09.2020 17:35 (Московское время). Этот раунд будет рейтинговым для участников, чей рейтинг ниже 2100.
Все задачи придумал я, но с двумя последними задачами очень помог gepardo, без него этих задач могло бы и не быть.
Мои благодарности:
antontrygubO_o за координацию раунда. Именно благодаря такой отличной координации в соревновании остались только хорошие задачи. Спасибо!
gepardo сделал много чего, без него этого соревнования просто не было бы! Он не только помог с двумя последними задачами, но и помогал мне разбираться, как правильно делать задачи на Codeforces. Спасибо!
EIK это тот человек, без которого я бы вообще не попал в спортивное программирование — мой учитель информатики. Спасибо!
programmer228, Hacktafly, K1ppy вдохновили меня на создание раунда, выслушивали идеи на каждую задачу и высказывали свое мнение, а также тестировали раунд. Спасибо!
Тестировали задачи и предоставляли свой бесценный фидбек Osama_Alkhodairy, vamaddur, thenymphsofdelphi, Devil, Ari, SleepyShashwat, TechNite, Monogon, Tech.Maniac, Kavit_Kheni. Спасибо!
MikeMirzayanov за платформы Codeforces и Polygon. Спасибо!
Вы, за то, что участвуете в этом раунде. Спасибо!
У вас будет 2 часа на решение 5 задач, одна из которых разделена на простую и сложную версии. Надеюсь вам понравится раунд, я очень старался сделать короткие условия и сильные претесты интересные задачи.
Разбалловка по задачам: 500 — 1000 — (1000 + 1250) — 2000 — 3000
UPD: Готов разбор.
UPD2: Разбор теперь можно читать и на английском.
Привет Codeforces! Недавно я стал автором Codeforces Round #672 (Div. 2) (он состоится скоро). Сразу же после того, как контест был добавлен в расписание, я получил огромное число сообщений с примерно следующим содержанием:
"Привет, я могу побыть тестером на твоем раунде? Я хочу получить опыт тестирования соревнований" и т.д.
Я хочу вам кое-что сообщить. Если вы не знали, процесс создания раунда выглядит примерно так:
1) Автор делает контест. Конечно, он/она тоже должен/должна внимательно проверить свое соревнование.
2) Когда эта работа сделана, координатор может позвать людей протестировать ваше соревнование. И автор, и координтор могут приглашать людей на тестирование раунда в этот период.
3) Когда и это сделано, раунд может быть помещен в расписание. После этого тестирование соревнования не требуется
Теперь, я надеюсь, вы понимаете, что тестирование соревнования совершенно не нужно после того, как вы увидели соревнование в расписании. Если что, такие сообщения меня не раздражали. Я просто хочу чтобы вы не тратили свое время.

Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 21.11.2024 22:05:33 (i1).
Десктопная версия, переключиться на мобильную.
При поддержке
