I happened to be proctoring ECNA 2025, and here are a few random afterthoughts after the contest…
You can find the full contest on Kattis: https://naeast25.kattis.com/contests.
Problem C — AROD
Link: https://open.kattis.com/contests/naeast25open/problems/arod
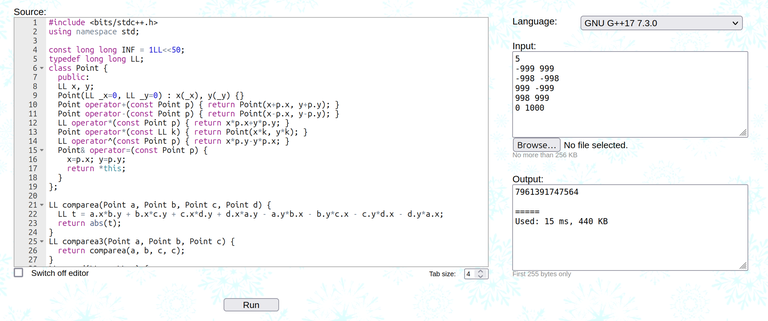
I am slightly surprised that my $$$O(n^4)$$$ solution passes the problem with $$$n=300$$$.
#include <bits/stdc++.h>
#define upd(mul) \
int s = x1 * y2 - x2 * y1; \
if (s == 0) { \
D += tot * mul; \
continue; \
} \
int c1 = x1 * x2 + y1 * y2; \
int c2 = (x2 - x1) * (-x1) + (y2 - y1) * (-y1); \
int c3 = (x1 - x2) * (-x2) + (y1 - y2) * (-y2); \
if (c1 > 0 && c2 > 0 && c3 > 0) { \
A += tot * mul; \
} \
if (c1 == 0 || c2 == 0 || c3 == 0) { \
R += tot * mul; \
}
int dp[601][601][4];
int main() {
int MX, MY;
scanf("%d%d", &MX, &MY);
long long A = 0, R = 0, O = 0, D = 0;
for (int i = 0; i <= MX; ++i) {
for (int j = 0; j <= MY; ++j) {
if ((i + 1) * (j + 1) <= 2) continue;
{
long long tot = (MX - i + 1ll) * (MY - j + 1ll);
if (i == 0) {
D += tot * (j - 1);
continue;
}
if (j == 0) {
D += tot * (i - 1);
continue;
}
// 3 vertices
R += tot * 4;
// 2 vertices
for (int k = 1; k < j; ++k) {
int x1 = 0, y1 = j;
int x2 = i, y2 = k;
upd(2);
}
for (int k = 1; k < i; ++k) {
int x1 = i, y1 = 0;
int x2 = k, y2 = j;
upd(2);
}
int g = std::__gcd(i, j);
D += tot * (g - 1ll) * 2;
// 1 vertex
for (int k = 1; k < i; ++k) {
for (int l = 1; l < j; ++l) {
int x1 = k, y1 = j;
int x2 = i, y2 = l;
upd(4);
}
}
}
}
}
long long tot = (MX + 1ll) * (MY + 1ll);
O = tot * (tot - 1) * (tot - 2) / 6 - A - R - D;
printf("%lld\n%lld\n%lld\n%lld\n", A, R, O, D);
}
I verified that the inner loop indeed ran around $$$2 * 10^9$$$ times for the test case, so maybe you just have to be brave and code a slightly complexity-wise-worse solution at times…
Problem D — But I Want to Win
Link: https://open.kattis.com/contests/naeast25open/problems/butiwanttowin
Let me just present you my accepted solution and see if you can figure out what is wrong:
#include <bits/stdc++.h>
long long A[50];
long long sum;
int main() {
int N;
scanf("%d", &N);
for (int i = 0; i < N; ++i) {
scanf("%lld", &A[i]);
sum += A[i];
}
std::sort(A, A + N, std::greater<long long>());
if (A[0] * 2 >= sum) {
puts("IMPOSSIBLE TO WIN");
return 0;
}
long long tot = A[1];
int round = 0;
for (int i = N - 1; i >= 0; --i) {
tot += A[i];
++round;
if (tot * 2 > sum) {
printf("%d\n", round);
return 0;
}
}
}
I will quote the clarification question to showcase the issue:
question for judges: we want to know the answer to the following test case from judge solutions
6 3 7 8 9 80 100the answer is 2:
round 1: the candidate with 3 votes can have 2 votes diverted to the candidate with 7, and 1 vote diverted to the candidate with 8
round 2: there are three candidates with 9 votes each, so all of them are knocked out and divert their votes to us, giving us 107 votes, a strict majority
we think that the judges might print an incorrect solution to this test case
By the time I read the problem, it was pretty clear that the problem was not correct, based on the fact that the two top MIT teams died horrendously on it and other teams passed in one go:

I was able to intuit what went wrong pretty easily, given the relatively straightforward (and wrong) greedy, and was contemplating an interesting philosophical question: if I know that problem is wrong and I know why it is wrong, should I submit a wrong solution that would get accepted?
Eventually I believe the problem was rejudged after the contest, and almost every solution was accepted. The current scoreboard should reflect the fact.
I think it is generally difficult to make a contest that is absolutely correct. Still, given the relative frequency of issues in problem setting (e.g. https://zhtluo.com/cp/rant-on-incorrect-ecna-2023-c-computational-geometry.html), I wonder if we can employ a more rigorous problem testing procedure somehow.