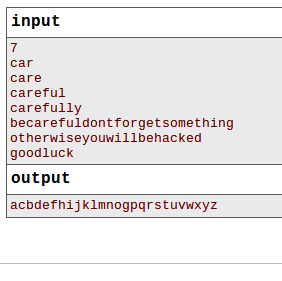
My code gives the answer right on my linux(ubuntu) computer but it fails at system testing. I believe it's something about vectors I use in the code (ans,tem) but I could not find the exact reason. Any ideas? (Also it could be nice if someone tests the code. Maybe it will fail on other computers as well. Who knows?)
EDT: Problem solved