


В свете происходящих сейчас законодательных мракобесий возникло настойчивое желание перевезти всё своё "хозяйство" на зарубежное доменное имя и хостинг.
Давайте попробуем поголосовать, какое название вам бы больше всего понравилось:
https://polldaddy.com/poll/7857563/
(С фантазией у меня туго, так что не стесняйтесь предлагать свои варианты — конечно, предварительно проверяя их на свободность, например, тут)
UPD Всем спасибо, голосование завершено. Результаты: победил вариант e-maxx.io (25%), вторым по популярности оказался e-maxx.us (16%).







 Привет, кодефорсчане!
Привет, кодефорсчане! можно было собрать вообще из одних хешей: ища максимальные палиндромы с помощью бинпоиска, и ища
можно было собрать вообще из одних хешей: ища максимальные палиндромы с помощью бинпоиска, и ища 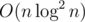 , хотя её можно уменьшить до
, хотя её можно уменьшить до 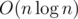 , заменив дерево отрезков sparse-table (это когда для каждой позиции
, заменив дерево отрезков sparse-table (это когда для каждой позиции 