



Hello, Codeforces!
UPD: Challenge is over. You can find result by this link
We are happy to invite you to the great event the 45th ICPC World Finals Challenge powered by Huawei,which will start on November 17, 2022, 00:00 UTC (UTC+0).
In this Challenge, You will have a unique chance:
- to compete during 14 days online challenge;
- to solve 1 or 2 problems prepared by different business domains of HUAWEI;
- to win amazing prizes from HUAWEI!
As a special prize, HUAWEI together with ICPC Foundation will provide the travel trip to the 46th Annual ICPC World Finals in a guest role to the 2 winners (1 winner for each problem)!
Everybody is welcome to participate. It is an individual competition.
45th ICPC World Finals Challenge powered by Huawei (open to public):
Start: November 17, 2022 00:00 UTC (UTC+0)
Finish: November 30, 2022 23:59 UTC (UTC+0)
This time HUAWEI has prepared 2 challenging tasks for you from different business domains – Central Software Institute and HiSilicon. You are free to choose which problem you would like to solve, and you are also welcome to solve both problems, but please remember the total runtime of both rounds, which start simultaneously, is 14 days only. We hope you'll enjoy this complex yet very exciting Challenge!
Each problem will have own scoreboard and own prize fund, so this is a unique chance for you to win double prize for two solved problems!
Problem No 1: Parameterized Branch Instruction Stream Generation
Benchmarks are popular for estimating and comparing the performance of computer systems which has always been a challenging task faced by computer architects and researchers. However, it is known that as emerging applications evolve, benchmark characteristics drift with time and an optimal design using benchmarks of today may not be optimal for applications of tomorrow. This problem has been aptly described as: “Designing tomorrow’s microprocessors using today’s benchmarks built from yesterday’s programs”. One of the approaches for addressing these challenges is to complement application benchmark suites with synthetic benchmarks.
Program control flow generation algorithm is one of the most difficult questions for synthetic benchmarks. Hence, this problem focuses on generating program control flow for synthetic benchmarks based on MIC related to behavior of conditional branch instructions. In this question, program control flow generation is abstracted to draw a route on a directed graph. The route and the graph with MIC closest to the input will be the winner.
Problem No 2: Task Scheduling and Data Assignment
This is a problem about job scheduling and data assignment. Consider a scenario, where we want to run a complicated software project, on a computing cluster or on a multi-core heterogeneous computing chip. The computing cluster has multiple computing units of various computing power, as well as multiple memory disks with various reading and writing speed. The software project consists of many small computing tasks with inter-dependence among them. During the execution, these tasks will also produce data that need to be stores onto some memory disks. Our goal is to design an efficient task scheduling algorithm, that is able to assign the tasks to different computing units, and to store the data to different memory disks, such that the overall makespan, which is the time the finish the last task, is minimized. As you can imagine, usually when a task starts its execution, it needs to first read the necessary data from the memory disks, and when the computation completes, it will then write its own data to some memory disk for other tasks to read. This means, the schedule of tasks to computing units, and the assignment of data to memory disks are tightly connected to each other, and they will together decide the overall running time of the whole software project.
Prizes
| Rank | Problem 1 | Problem 2 |
| Grand Prize (Rank 1) | €15,000 EUR + the travel trip to the 46th Annual ICPC World Finals in a guest role | €15,000 EUR + the travel trip to the 46th Annual ICPC World Finals in a guest role |
| First Prize (Rank 2- 6) | €8,000 EUR | €8,000 EUR |
| Second Prize (Rank 7- 16) | €3,000 EUR | €3,000 EUR |
| Third Prize (Rank 17 – 46) | HUAWEI FreeBuds | HUAWEI FreeBuds |
| * If the allocated HUAWEI Challenge prize cannot be delivered to your region for any reason it may be replaced by another prize of the same value (if no legal restrictions), at the discretion of the sponsor. | ||
Challenge Rules and Conditions
By participating in this Challenge, you agree to the Challenge Rules and Conditions of Participation
Good luck, we hope this will be fun!






Wow, that's awesome! I didn't expect another round so short after the ICPC online challenge.
In the last challenge there was some elephant in the room, which I'd like to address early on (discard my comment, if both problems will have a 2nd set of testcases after the contest ends): are we allowed to tweak our code specifically for each testcase like this?
Could you elaborate for what exactly is the purpose of this? Or is the randomSeed just placeholder? If so, for what you might use this in real-case scenario?
I'm not sure if you (or other readers) followed the previous round. The winner commented that he tested 200 different seeds and detected the testcase to pick the best one among these 200 (read the last 2 paragraphs for more details). Obviously I don't know what to expect from the upcoming contest, but this being the winning strategy left a bit of a sour taste to me. The code snippet is some pseudo-code to explain the idea.
Makes sense, interesting approach tho, but not certainly sure why it's allowed as well, lol;
But I guess they can do the same in production and get the most suitable seeds for different cases, so I guess it's fair, ty.
Well, in reality you can't just assume the data will be very similar to the training set. That is exactly the reason we use a validation test after training in ML, because overfitting is an undesirable phenomenon.
Sadly, I'm quite unfamiliar with development side of any type of programming, since I have never developed or learned how to develop anything, yet at least, so I can't really speak on that. I'm basically blindsided in development and have just some ideas/opinions how things might work there, lol
But when will the rewards for the last contest be distributed?
I have not received any message about the reward in the past ten days.
Hi Macesuted-Moe, thank you for your active participation and inputs! We were waiting for the ICPC account verification and will contact you very soon! Please let us know if there’s ever anything you need!
Hi Huawei, I have yet to receive any messages too. Are you still waiting for the ICPC account verification? Let me know if I can assist, e.g. by providing screenshots.
hi,huawei.how will the rewards be distributed?I looked through the Announcement but find nothing
After the ICPC Challenge, there was a competition held by HUAWEI again. That really surprised me, and I am looking forward to the problems of this contest, hoping to surprise me.
About the last round.....
Random algorithm can get high points.
Actually that's OK for this kind of problems
Not to mention that important metaheuristic algorithms like simulated annealing rely on randomization too. (It needs a way to determine the next state to search, and it is based on randomized "Monte-Carlo" methods.)
Thank you,and I am very sad to get -17 contribution.
Don't be obsessed with contribution. You got your doubt resolved — that's the most important.
Once again, the woman in the video urgently needs to improve her English
it's rated ?
No
No.
It would be nice to finally fix language selector issue and remove incorrect use of flags.
Sources with supporting arguments:
Codeforces Language Picker -- chrome extension to see how fixed codeforces language picker would look like.
Please support the initiative and stop reinforcing poor UX practices (including downvoting).
It would be nice to finally delete your account and not bother us with your bullshit.
It's really sad when you only need to have 10 more score to be rank 46
GG everyone !
Does someone know how we are supposed to "associate" our contest account with our ICPC account, as written in the rules ?
Maybe the organizer will send you an email later and let you fill in the information
Last time winners received the following private message from "System":
Hello!
Congratulations on your successful performance in the ICPC 2022 Online Challenge powered by HUAWEI. You can read the details in the post by the link https://mirror.codeforces.com/blog/entry/107690.
We remind all winners that you must have an account at https://icpc.global/ in order to receive a prize. The email for this account must EXACTLY match the one used in your Codeforces account. Please verify that this is indeed the case. The deadline is October 14th.
What was your approach to problem 2?
Can someone, who solved problem 1 with a 10500 score, tell the solution?
Can everyone downvote this comment pls? I am trying to get less contribution
Any good ideas on how to tackle problem 2? Are others solutions visible?
Given a schedule satisfying the constraints, I scanned it to identify tasks on a critical path. (tasks are critical if they end at the final time, or end immediately before another critical task begins).
I sorted the tasks into an order based on satisfying the constraints and giving some priority to tasks what were on the critical path for a previous schedule. Then greedily allocate tasks to machines, aiming to complete each task as soon as possible. Similarly, allocate disks to tasks based on quantity of data to be processed, with rough priority to give faster disks to tasks on critical path. Finally iterate and try again, mixing and matching disk allocations and task queues.
After much tweaking of random weights I came out at 18th, with no hope of making any more progress without some new ideas.
Also, anyone else have problems with 65536 character code limit? After several days of hacking generating code I had to start deleting debug code before submitting.
At the beginning of my algorithm, I greedily schedule tasks to disks to minimise total read/write work, and I randomise afterwards to see if I can improve the solution further. Then, I compute a rough lower bound on the time needed to complete the descendents of a task. To do this, I compute something like the maximum between the longest path, and the sum of the works of all the descendents divided by the number of processors. I sort the tasks by this value, then I schedule then in this order, each task taking the machine that allows it to finish the earliest.
I'll try a scheduling, then I will update the priorities using some rules, then I'll try an other scheduling, ... until time is ~14.8s. The rules are basically to compute the "slack" time each task have and decrease the priorities accordingly, and randomly switch a few priorities and disks.
I also have some parameters which are used : - A constant which adds priority to tasks with a lot of children. - A constant which decrease the score of a machine with a lot of tasks that want to be scheduled on it. - A constant that tells what is the "weight" of waiting.
When I start the program, I start by testing a lot of values for every constant, and continue with the bests.
As the No.32 of problem 1, I have no idea about how to solve problem 2 with even a solution that just satisfy the limitations. Maybe I'm just weak on graph theory. :(
A fun fact: I got 1k more score by just changing the precision when doing scoring.
For problem 2, just to satisfy the limitations....
There must be at least one task which does not depend on any others. Find it, or one of them, and schedule it on a machine.
Now there must be at least one task that does not depend on any unscheduled tasks. Find it, or one of them, and schedule it on a machine late enough to satisfy any dependencies. Repeat until you run out of tasks to schedule, which will happen when all tasks are scheduled.
Um... Thanks! Just like a toposort maybe
Happy to describe the approaches, but a quick question first: Are we allowed to post solutions (i.e. source codes)?
Edit: I saw that in the previous contest, eulerscheZahl posted his solution and no one complained, so I'll assume it's ok.
I received the prize money without any issues. But back then I was wondering the same and checked the rules for any such paragraph. I can't give you a definite answer whether or not it's ok. Maybe share one of your codes and wait for a reaction to only lose one of your prizes? Joking aside, I'd also like to have an official statement.
I spent like 10 minutes fighting with CF markdown (can't get lists to work properly) and I gave up. I'm linking to github instead.
Problem 1:
Approach
Code
I'll add problem 2 later today
Approach for the 2nd problem:
Github version
Links
Final Solution — I have removed a lot of nearly useless (~0.4 gain) code to make it a little bit more readable.
Problem
This problem is a fairly standard task scheduling problem. The biggest issue here is that the best solving method highly depends on the input. Large tests, small tests, unbalanced allowed machines, very strict disk capacities, narrow critical path are some of the potential properties that can drastically affect the preferred solving method. You could either randomly try a bunch of methods or do some heavy work with the test case extraction to make more educated guesses.
Approach
Out of 51 tests, only two were maximal (n=10000) and every other test was n<=800. Because of that, I wanted to find a decent approach based on the local search. I tried a weird mix of SA (Simulated Annealing) and greedy. My state is:
task_order+task_machine+task_disk_preference, where each variable is a vector of length t (number of tasks). In order to evaluate the state I use a greedy method:Use
task_disk_preferenceto pre-assign a disk to each task, earlier in the list gets a faster disk.In each step, take the first (based on
task_order) available (= all dependencies fulfilled) task and place it on the designated machine (based ontask_machine) using the pre-assigned disk.It's allowed to set machine to "unknown" for a task. This version tries all machines and chooses one that has the fastest finish time.
This state representation is fairly stable, but the state evaluation is incredibly inefficient (since it restarts the whole process from scratch). For n=800 I got around 50K state evals (which is rather low, but not terrible), but for n=10000 I got only around 2K which is pretty much nothing and thus SA has no chance of improving it.
The main improvement came from initializing the
task_orderbased on the "critical path". For each task, I calculate the longest possible chain of tasks that have to follow it. The tasks with the longest chains are given the highest priority. For some reason using "longest_chain_starting_from_this_task — longest_chain_ending_with_task" gave even better results so I kept it. Initializingtask_disk_preferencewas simpler and I just used data*number_of_times_this_data_is_used. This + some minor tweaks gave around 2827 points. The remaining 10 points came from running the same solution many times and choosing the best set of parameters for each test case.My greedy initialization is far from good and my SA does nothing for the 2 largest test cases, so I'd imagine that's where the remaining 10 points mostly come from.
Additional Comments
If someone started early, it was possible to extract some of smaller tests (all n<=300 and maybe even some/all of the n=800). You get a total of 8064 (24 per hour * 24 hours * 14 days) submits throughout the 2 weeks of the competition. With each submit you can extract 24-32 bits of information. I'd guess that should be achievable with a decent compression (removing redundant input + LZ compression). This would leave only the last 2 cases for online solving.
Messy code on github.
I started with an initial greedy solution: estimate the time it takes for each state to complete it and all the following tasks. Then put the tasks with no prior dependencies in a priority queue, sorted by the expected time to finish (those with higher expected will get dequeued first). Assign the machine and disk that can get the task completed the fastest (on ties use the weakest hardware, you don't need a speed 10 disk to store 3 units of data). Update the dependency count for each of the following tasks and add them to the queue if they have no further dependencies. This gives an initial solution. From there you can compute the time it takes to complete the task-tree and run the same greedy again with more accurate numbers.
For the following part I have a bruteforce for smaller testcases (greedy still helps to set an upper bound when to stop early) and a hill-climber for the others. Two hill climbers actually, one takes 2 random tasks and assigns random disks and machines to it, keeping the changes if they don't score worse. The other hill climber modifies 5 consecutive tasks instead. When the HC is stuck for 10000 turns, I allow one bad move that makes the score worse. For a test with 1600 tasks I generated I can test about 40k mutations until I run out of time — on a computer that was cutting edge 10 years ago when I bought it.
This should score around 2825 points. Similar to Psyho I gain about 10 points by tweaking for specific testcases.
I'm curious about the score distribution on the tests if you are agreeable to provide, since there's no official 'full score'.
I edited the gist from my link above to include the scores. If you combine mine and Psyho's, you get 2839 — which is still far from the top.
Thanks for the solution @Psyho. How can we extract the 24-32 bits testcase information?? I remember I didn't see any output from the judge. Did I miss something? Thanks !!
If you go to "My Submissions" and click the "Partial Results" link, you'll get score, time & memory usage per test case.
Extracting information:
Memory is 1024MB max where the resolution is 1MB — this gives theoretical max of 10 bits (8 bits is very easy though).
Time is 15 seconds max, but the resolution is 16ms and it's tricky to get the exact timing. In theory it's another ~10 bits, but getting 7-8 bits should be easy.
Extracting through score is a little bit trickier. The resolution of the score is 0.001 point, but various test cases have different "baseline" scores. It's easy to decrease your score by pushing full solution by X units of time. If you extract the scaling factor first, you can calculate an exact expected score. It's easy to extract 10 bits for every test case. Probably 12-13 is doable for most tests.
Results of my final submit: link
If someone wants to practice problems like this, I'd highly recommend Topcoder's Marathons (nice visualizers, usually very approachable problems especially recently) and AtCoder's Heuristic contests (better platform, weirder problems and you have to use google translate to read about approaches).
Navigation on topcoder can be a bit of a challenge. I still have no idea how to get there, but marathon matches will show up here.
For a list of upcoming challenges I recommend clist, it shows that the next marathon will start on Dec. 7th 6pm UTC.
Is it sufficient if my Codeforces e-mail matches only the secondary e-mail from ICPC system?
I think that many participants abused test system, as eulerscheZahl described in this comment ("...This should score around 2825 points. Similar to Psyho I gain about 10 points by tweaking for specific testcases..."). Psyho used similar techniques — you may find their solutions above.
Obviously, solutions were expected to be general, not for special cases (otherwise organizers would have done open tests, e.g. as it was on Pinely Treasure Hunt Contest). I think that such special solutions must be rejected. Moreover, during contest I asked jury about legality of this method and got following reply: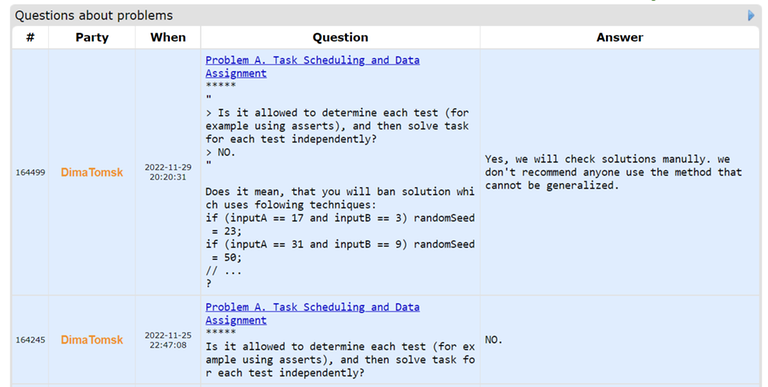
Lol.
First of all, such solutions were accepted in the previous one that happened few months ago.
If you make your tests fixed with no system phase, everyone will overfit. Either indirectly (by applying random changes and keeping those that scored better) or directly (by adjusting parameters per testcase). It may "feel wrong" but that's how the contest was designed. There's no such thing as a "general solution" here, as the complexity is hidden within handmade testcases. You can reorder the scoreboard however you like by constructing a different set of tests that adhere to the problem statement.
Could someone please explain to me what is wrong with this response? Why are people disliking this? Because of the 'lol'? Cause I don't really see any problems with the reasoning.
Also, it seems rather weird to not change the official rules at all (between contests), but change what is OK to do and what is not. Furthermore, eulerscheZahl's question of where to draw the line is really apt. DimaTomsk made 600+ submissions during 9 days of the contest. How sure can we be that nothing in there 'abused the test system'? (this is a rhetorical question, not trying to start any beef plz)
Furthermore, checking just the presence of 'if testcase A' is not enough to guarantee anything — if rules explicitly forbid this type of structure, people would just obfuscate the fact that they are doing the same thing anyways.
I can totally understand your point of view, I don't like that strategy either. At the same time it felt too powerful not to use it. Especially after the last contest was won that way (without resulting in any reaction by contest organizers, in a contest where it mattered even more due to incomplete information), I assume that many resorted to this strategy. There is a reason, why I asked this question a whole month before the contest started — and I got absolutely no reaction while another question was answered. They did not even make your clarification request public.
Furthermore I would consider completely rejecting a submission because of that extremely harsh, given that it's "only" 10 points and would still be around top10 without hardcoding. And where exactly do you draw the line? Is it allowed to submit the same code 100 times and hope for a lucky submit (not seeding your RNG)?
Let's wait for organizer's decisions. From my point of view I did everything to clarify the legality of my actions beforehand and had reason to believe that it's allowed. If codeforces doesn't want us to extract information, they have ways to do so (or at least make it harder), see Huawei's communication routing challenge:
Wanna get higher prize by rejecting top participants? Maybe it is better for you to shut up?
DimaTomsk then you got a response about that famous question, and you didn't even bother sharing it with participants, or even reply to the comment you copied your example from.. looks a really well-intentioned behavior..
Let's read the first announcement from the contest:
"Your score for the contest is equal to the sum of the scores among all tests. The best submission will be chosen to show standings. The problem do not have any system testing (i.e. the current testset is final). Your score at the end of the contest is your result."
So, if organizers ban any solution after the end of the contest, they will break their own rules. It will lead to disaffection among the top contestants of organizers' decisions (Huawei). I guess the purposes of Huawei sponsoring such contests are popularization/developing competitive programming, propagation of the Huawei brand among programmers, and searching for people for internships and jobs. Disaffection among the top contestants basically means reputation losses for the Huawei brand among targeted participants. I believe banning solutions after the contest is not in Huawei's interest.
By the way, this test-seed overfitting is not healthy. It would be cool if organizers designed the contest in such a way that prevents overfitting (or, at least, makes it highly difficult to overfit).
If you want general solution then create an additional set of system tests. If you don't do that and the goal is to get max score on fixed set of tests then it's a COMPLETELY different contest. Disallowing that at this point would be ridiculous
Yes, I agree, but now DimaTomsk had to participate in that completely different contest, based on the information only he had! It is not fair for him.
@DimaTomsk Thank you for participating in this contest and for the valuable suggestions you provided!
We view fairness as the most important criterion when evaluating the participants' performances in this contest. Therefore, the grading rules will strictly follow the problem statement. We have not ban solutions that are tailored to the tests. All the scores and the ranking shown on Codeforces remain unchanged.
With that being said, we are grateful for all the feedback from the participants. We have read all comments carefully and will incorporate them into our future problem designs. We will continue to optimize our problems and hope to bring you a better experience in future Huawei competitions.
But why when I asked you during contest, you strictly forbade it. You said you will not accept such kind of solutions, but you did it. It means, you changed rules after contest. Because of it I lost many points.
@DimaTomsk
Dear Dima, we very apologize for disinformation delivered to you by answering so, we had internal miscommunication about it, we did not change the rules of the contest after its completion, standing results fully meet original problem statement rules. We sincerely hope to contact you personally and deliver apologizes about situation occurred!
Here is an actual suggestion about how to handle this situation.
Consider all submissions of DimaTomsk and for each individual test case find the best scoring submission. Sum up the individual best test case scores to obtain an "upper bound" of what the total score of DimaTomsk could have been.
For comparison, this "upper bound" is 2835.886 for me. My final score is 2835.545, so it is possible to get very close to the "upper bound" (for instance, I never had any problems with source code size limit).
If the "upper bound" results in a different prize category for DimaTomsk, then I think there is an actual problem. Otherwise, the claims like "I would get 10-15 scores more" are just empty words.
After conversation with Huawei all miscommunications were resolved. Thank you.