


Привет codeforces,
хотелось бы обсудить здесь задачи вступительной работы практической части ЛКШ.
Сами задачи: link
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |







Как решается задача J?
Разобьем строки по символам '?', к нас получится некоторое количество кусков. Их немного, так как вопросов максимум 10. Для каждого из кусков сохраним позицию начала, а также массив значений префикс-функции. Потом пробежимся по тексту и проверим совпадение начиная с этого символа: пробежимся по всем кускам и посмотрим на соответствующие значения префикс-функции. В итоге алгоритм за O(m + (n + m) * k), где k — количество вопросов
Кстати, а у нее есть решение побыстрее, без разбития по вопросам?
В книге Гасфилда говорится, что нету.
UPD. Вру, все-таки есть. За асимптотику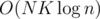 (K — размер алфавита), с помощью быстрого преобразования Фурье. В статье про оное на е-максе можете найти идею (скалярное произведение массива A и всевозможных циклических сдвигов массива B).
(K — размер алфавита), с помощью быстрого преобразования Фурье. В статье про оное на е-максе можете найти идею (скалярное произведение массива A и всевозможных циклических сдвигов массива B).
Можно и без размера алфавита, надо считать суммы вида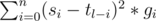 где gi это индикатор того, что символ i не равен "?". Это можно посчитать используя пару свёрток.
где gi это индикатор того, что символ i не равен "?". Это можно посчитать используя пару свёрток.
Интересная идея, спасибо!
А разве нельзя через видоизменённую префикс функцию (Когда проверяем, равны ли буквы, говорим, что либо равны либо одна из них — знак вопроса. По-моему, это работает быстрее.
Можно вместо k КМП сделать один Ахо-Корасик.
Такое чувство, что немного должно улучшить, но не сильно, будет O(N + M + T), где T -- сумма количеств вхождений каждого куска в строку.
Ничего не должно. Строка
aaaaaaaaa....aaaaaaaи образецa?a?a?a?a?a?a?a?a?a?a.Может быть я непонятно выразился.
Имелось в виду, что мне кажется, что в среднем будет меньше лишних действий. Естественно, что на таких крайних случаях выигрыша не будет.
Можно разбить на блоки, и проверять хешами.
Я тоже так делал) ИМХО, это очень просто и мало кода.
Делал через хеши. Считаем хеш шаблона. Надо быть внимательным при подсчете хеша шаблона если символ — ?, то не нужно прибавлять ничего. После заводим вектор, и проходя по шаблону, кидаем позиции вопросиков в вектор, а их не больше 10. Далее заводим вектор, и проходясь по строке, считаем хеши всех префиксов строки за линию. Теперь просто проходим по строке, на i-ом шаге заводим переменную и в нее записываем разность хеша префикса с концом в (i + длина шаблона) элементе — хеш префикса с концом в i-ом элементе, получаем хеш подстроки длины шаблона, далее удаляем из хеша слагаемые с позициями, равными позициям вопросиков в шаблоне и сравниваем хеш подстроки с хешем шаблона, если они равны, то кидаем позицию в вектор ответа. Далее что делать, я думаю, понятно. Решение не сложное и не медленное.
ABCDEF — тупо делаем, что написано G — комбинаторика за квадрат, используя тр. Паскаля H — тупой BFS I — реализация
Кстати, в задаче J зайдут регулярки ?
Говорят там КМП? нет?
H можно код
BFS пройдет, если работать не со строками, а только с числами. Сразу получается значительное ускорение
Понятно
У меня в Н со строками зашло
Можете поподробнее объяснить решение с тр. Паскаля
Давайте рассмотрим все варианты распределения N на r,g,b — красных, зеленых и синих. Переберем r,g в цикле (b=n-r-g). Для каждого варианта: пусть мы определили r,g,b, тогда количество вариантов такого распределения полоски равно C(r, n) * C(g, n - r) * C(b, n - r - g), но b = n - r - g, т.е. С(b, n - r - g) = 1.
Чтобы не вычислять каждый раз число перестановок через факториалы, используйте треугольник Паскаля. Псевдокод:
Итоговая сложность: N^2
Заходила еще такая вещь: переберем r, g, b так, как Вы сказали, только будем к ответу прибавлять так:
Разумеется, нужно с модулями работать. В связи с этим все усложняется. Алгоритмом Евклида нужно обратные элементы в кольце по модулю предпосчитать для всех факториалов от 1 до 5000.
А можно как-нибудь делать I без структурок типа СНМа?
Вроде тупо перебор за квадрат заходил
Если просто после каждого запроса поставить крестик проверять по горизонтали, по вертикали, и по двум диагоналям максимальный ряд из крестиков, все тесты не пройдет, на нескольких будет TL. Но, можно поставить пару примочек(условий) на проверку, надо ли дальше проверять, хватит ли вообще клеток на дополнение ряда, и собственно не проверять, когда этот ряд обречен на провал, тогда решение заметно ускорится и пройдет все тесты.
Я решал ее бинпоиском по ответу. Сначала делал массив, в него записывал ход, на котором был поставлен этот крестик. Теперь можно для каждого крестика узнать, стоял ли от после i-го хода. Проверял ответ так: завезем массив, будем в ячейке хранить максимальную по длине последовательность крестиков, заканчивающихся в этой клетке. Считаем отдельно через ДП для последовательностей по вертикали, горизонтали и диагоналям.
Я писал фенвика. У меня было четыре фенвика: 1)для вертикалей 2)для горизонталей 3)для диагоналей двух типов, которые идут вниз и вверх. Когда мы ставим крестик, то нам имеет смысл проверять только лишь ту горизонталь, вертикаль и диагональ, куда мы его поставили, да так, чтобы наш крестик был среди нужной длины последовательности. Итого получаем сложность O(M*K*logN) и небольшая константа. Прошу заметить, если делать без фенвика, то сложность получится O(M*K^2). Однако мое решение получило на двух тестах TLE. :(
У задачи K подозрительная буква :).
Решение: построить дерево компонент двусвязности, далее решать как задачу K с NEERC 2011 (разбор там есть, на английском).
Если я правильно понимаю, достаточно вывести ceil(leaves/2), т.к. ответ восстанавливать не просят
K. Убираем мосты, компоненты сжимаем в вершины, вернем мосты. Получится дерево, ответ
(leaves + 1) / 2округленный вниз.