


Meta Hacker Cup is upon us again. Along with it comes the unique format where we have to run our code on large test cases ourselves. Unfortunately, past experience shows that not everyone knows how to do this reliably. Usually, after the first round, many people lose points as a result of an unreliable workflow. This time, let's try to prevent that from happening. Sorry for the somewhat self-important title, but I really do wish that everyone understood this and that no one will fail the contest because of this.
Don't EVER copy-paste huge files
A lot of people's workflow to run a solution is the following:
- Click some green button in the IDE
- A box comes up, copy-paste the input into that box
- The output shows up somewhere
This may work well for running your solution on small sample test cases. It is terrible for running your solution on the huge test cases in Meta Hacker Cup. In last year's Round 1, the full test case for problem C was 37.5 megabytes in size and 6 million lines long. A 20 year old computer is very much capable of handling a file that large, but most graphical tools are not built with such files in mind.
I did an experiment. I opened my code for that problem in VS Code, compiled it and ran the program in VS Code's terminal. Then, I copy-pasted that 6 million line input file into that terminal. VS Code froze and I had to kill it. I'm fairly certain that this will happen on pretty much every consumer laptop. If you do this and your computer crashes, it's not because your laptop is old and slow, it's because you used a tool for something it wasn't designed for. Even if it doesn't crash, the clipboard itself has an upper limit on some systems. You shouldn't even need to open these files. Many text editors aren't designed for large files either and might crash; again, this is not because your computer is slow, it's because the tools aren't designed for large files.
Here's how you should be working with these files.
Option 1. Use pipes to read the input from a file and write the output to a file. For example, ./program < input.txt > output.txt reads the input from input.txt and writes it to output.txt. Read my blog on command line to learn more.
Option 2. Read the input from files directly. In your program, you can write
#include <fstream>
// ...
int main () {
ifstream fin ("input.txt");
ofstream fout ("output.txt");
}
Now, you can read from fin (e.g. fin >> n >> m) and write to fout (e.g. fout << "Case #" << i << ": " << ans << '\n').
Option 3. If you like Option 2, but cin and cout are burnt deeply into your muscle memory, you can do
#include <cstdio>
// ...
int main () {
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
}
Now cin reads from input.txt and cout writes to output.txt.
Set a higher stack size
I've written a simple C++ program. It generates a random tree by selecting the parent of vertex $$$u$$$ to be in $$$[u - 6, u - 1]$$$. Then, it prints the depth of the last vertex. Here is the program.
Try running this on your computer; it doesn't take any input. With high probability, you'll see this message:
Segmentation fault (core dumped)
What is going on? Have I perhaps made some implementation mistake? No: the reason this code segfaults is that the recursion goes too deep. A slightly simplified explanation is that when you are calling a recursive function, the compiled program needs to remember all recursive calls that led to the current call, and it runs out of memory to write this information into. This issue commonly comes up if there is, for example, a graph problem where you need to write DFS.
Option 1. (Linux and probably Mac OS, only if running command line) Type ulimit -s unlimited into the terminal before running your solution in the same terminal.
Option 2. (All platforms) Follow the instructions here.
Compile with -O2
-O2 is a flag given to the compiler that enables certain optimizations. You might not be aware of it, but every submission you submit to Codeforces or any other online judge is compiled with that flag. If the input files are large, you probably want to compile with this as well, otherwise your solution will run rather slowly.
If you compile from the command line, you can just do g++ -O2 solution.cpp -o solution. If you compile using some button in your IDE, it depends on your IDE, but you should be able to add this flag from some menu. Here's how to do it on some common tools. Please note that there are all kinds of setups and if you are doing something different, you probably need to do these things differently as well. If you use some tools, you should in general be well-versed in how to use and configure these tools.
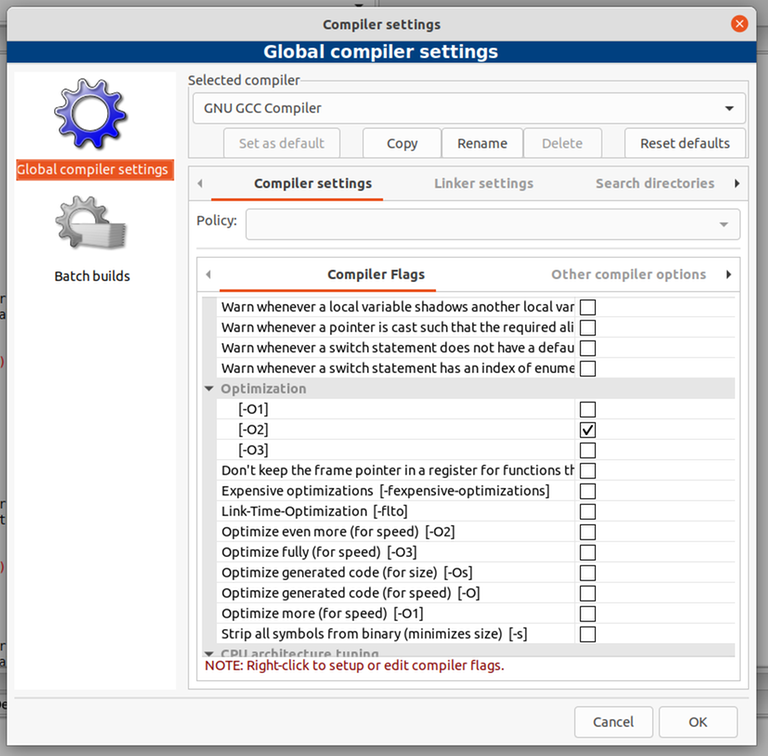
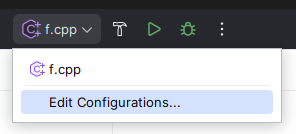
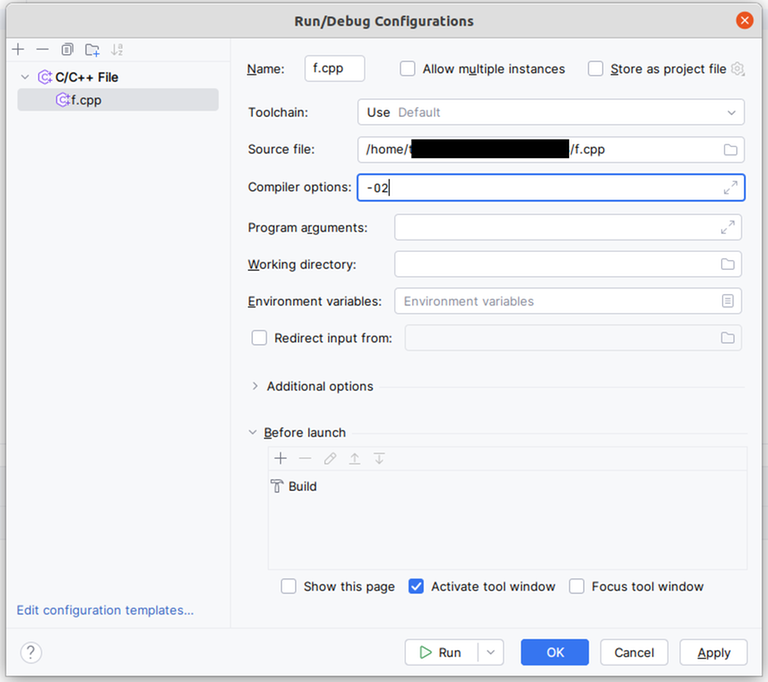
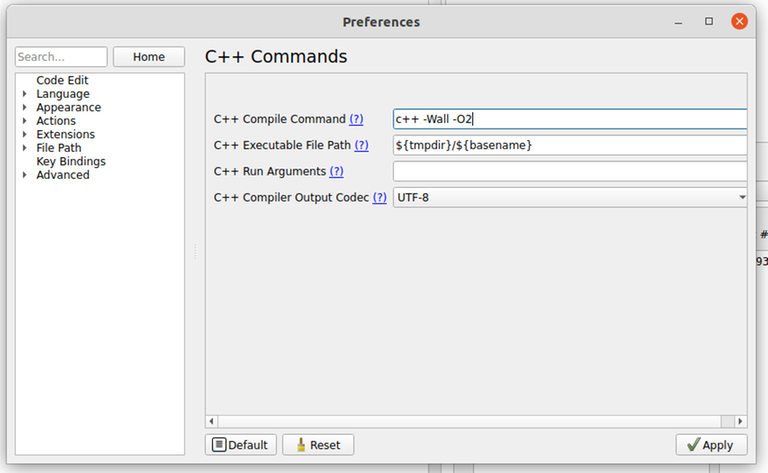
If you disregard any of the rules above and lose points as a result, it is your own fault! It's not the fault of Hacker Cup organizers and it's not because you have an old and slow computer!






Also very important: if you are using windows subsystem for linux,
ulimit -s unlimitedmay not work. Use a compiler on native Windows.This works for gcc in WSL:
Copied from here.
on MacOS
ulimit -s unlimitedgave mebash: ulimit: stack size: cannot modify limit: Operation not permitted, not using root, appending-Wl,-stack_size,20000000to gcc/clang seems working for meuse sudo
I know sudo but don't think it's a good idea to use it all the time. (as far as I know
ulimitjust changes current session and will not be in effect later or when exiting sudo)There's a soft and a hard limit. You cannot set the soft limit to anything higher than the hard limit, and you can't increase the hard limit (unless you are root). On Linux the hard limit is usually unlimited, but that might not be the case on MacOS. You can use
ulimit -Hsto see the hard limit, or useulimit -s hardto set the soft limit to the hard limit, i.e. as high as possible.The hard limit on my machine is around 64MB and I was able to change it to that without root. Also via the linker method the max stack can be specified is 512MB, since declaring a large array of 511MB was fine and a 512MB resulted stack overflow, looks that way is able to bypass the system limit.
To increase stack size in OSX I do g++-9 -Wl,-stack_size -Wl,100000000 test.cpp && ./a.out
Have it in my library since I can never remember it.
For newer linkers (on Linux/Mac), the command to set stack size has changed so the common recommendation of
-Wl,--stack=268435456throws a linker error like the following:On modern systems, pass
-Wl,-z,stack-size=268435456to your C(++) compiler instead. This is tested with GNU ld (GNU binutils) 2.43.1, LLD 18.1.8, and mold 2.33.0.I created separate input and output files as mentioned in Option 2, but VS Code still crashed(on the same C question mentioned in the blog). Are there better choices available?
At what point did it crash?
I populated the input file, and then ran the code. The first 13 or so test cases ran(there wasn't any output in the output file but I had added a "Hello" line to be printed in the terminal, and there were around 13 "Hello"). After that I left it idle for around 10 minutes but nothing happened(the output file remained empty).
Can you show your code? Maybe it was just slow?
$$$N$$$ in this problem is up to 4 million, your code is $$$O(N^2)$$$, it would probably take a day or two to finish. So it's expected that it would not finish in 10 minutes.
Nothing shows up in the output file because you used
"\n"to print line breaks instead ofendl. If you use"\n", they might be actually written only when the program finishes working.But did anything actually crash (i.e. did VS Code become unusable or similar)?
Aaah! My bad. The second double for loop's inner one should have update condition j+=i. Also even my logic was wrong. Since I am working with strings it should have been if(s[i-1]=='1') and not just if(s[i-1]). It now got Accepted. Thanks a lot -is-this-fft-
The O(n^2) solution was making VS code unresponsive. I even had to restart my computer once.
How do you run your solution in VS Code? Do you press some "run" button or do you write something in the terminal? If the first, does it take you to some debug mode?
There is a triangle(with its base vertical) on the top right corner. On clicking it, the terminal opens. In CF rounds, I just copy paste the input, click enter and the output comes, all in the terminal itself. I don't run any commands in the terminal.
Activities for poor competitive programmers
> be me
> competitive programmer
> decide to participate in a competition with a unique format to compete with other competitive programmers
> genuinely been having fun taking part every year for like 10 years
> be called poor because of this
Why are people like this
> be you
> competitive programmer
> see troll comment
> care enough to respond with greentext on website which is not image board
> manually make text green, add \ before every >, add <br> after every line
> complain about being called poor
this way of having fun feels poor-ish
hacker cup is actually for the richest competitive programmers, it's one of the only two cp contests i know that you can win by running a parallelized solution on your supercomputer cluster
:/
Has anyone actually done anything like this and gotten a meaningful advantage?
Who's gonna confess to this?
It's actually less about confessions and more about whether this is actually feasible. Writing programs that can actually be efficiently parallelized is nontrivial (if you actually do some MPI or whatever). The other option is to just take a computer that's really fast but I'm not sure that's an actual thing either.
well...
for this problem many people had multithread solutions and/or solutions that ran close to the 6 minute limit. not a case with some insane computer but it shows that money really does matter
What's the difference between -O2 and -O3?
Different optimizations, -O3 is a higher level. Historically -O3 could have done some incorrect transformations (and I think there is some recent example of this), so I always use -O2 unless I am trying to cheese something through (and it has never made enough of a difference). So probably just using -O2 is fine.
o3 is sometimes slower than o2 as well
Are templates allowed in the contest like on codeforces?
Quote from the FAQ https://www.facebook.com/codingcompetitions/hacker-cup/2024/round-1/faq
" Human Track — Can I work with other people / AIs, or use pre-existing code?
You may use any code or online information that had been written before the start of the contest. However, you may not communicate with anybody else about the contest, including non-competitors, while it is running. You may not use any AI system for assistance during the contest. "
From this I understand that it is allowed to use a template. And if you watch Neal Wu's stream, he is using a template in Meta Hackercup 2023: https://youtu.be/uIPIcpizjvg?feature=shared&t=55
Thanks for this post
i get the segmentation fault on it. Now i have increased the stack size and now its working fine
Is there a way to create a facebook account fast? Verification (why?) takes one day apparently
The scoreboard does not load. I think it always worked before the contest in previous years.
Disabling Adblock solved this for me.
I didn't qualify to the next round because of this blog. I used the template you provided to increase the stack size and when I wanted to run my solution on A , the code kept running for more than 6 minutes and the timer ran out. I tried the code on my regular template and it took less than a minute.
I think you owe me a T-shirt.
Hey -is-this-fft-, thanks for the blog! Option 2 link from blog doesn't work, I think you mean link: https://nor-blog.pages.dev/posts/2023-09-25-increase-stack-size/ which helped me.
I secured under 200 rank in round 1 still it shows I am not registered for round 2 , anyone else also facing the same issue ?
same here.