


Thank you all for participation! We hope, you enjoyed the problems.
2176A - Operations with Inversions
Which element of the array cannot be removed using the described operations?
Under what condition the element $$$a_j$$$ cannot be removed?
Note that the element $$$a_1$$$ cannot be removed using the described operations.
In general, the $$$j$$$-th element cannot be removed if $$$a_j$$$ is not less than all elements $$$a_1 \ldots a_{j - 1}$$$.
Otherwise, among the elements $$$a_1 \ldots a_{j - 1}$$$, there will always be an element $$$a_i \gt a_j$$$, which means that $$$a_j$$$ can be removed.
The constraints are small enough, so for each element, this statement can be checked in $$$O(n)$$$ for one check — resulting in a total of $$$O(n^2)$$$ for the test.
The idea for solving it in $$$O(n)$$$ is as follows:
- We will process the elements starting from $$$a_2$$$ to $$$a_n$$$.
- Let $$$M$$$ denote the largest among the already processed elements, initially $$$M = a_1$$$.
- If $$$M \gt a_j$$$, then $$$a_j$$$ is removed; otherwise, we set $$$M$$$ equal to $$$a_j$$$.
#include <iostream>
#include <vector>
#include <algorithm>
#include <map>
#include <ctime>
#include <queue>
#include <iomanip>
#include "assert.h"
#include <math.h>
#include <set>
#include <deque>
using namespace std;
#define vi vector<int>
#define vii vector<pair<int, int>>
#define pii pair<int, int>
#define ll long long
#define pll pair<ll, ll>
const ll INF = 2e18;
void solve() {
int n;
cin >> n;
vi a(n);
for (int i = 0; i < n; i++) cin >> a[i];
int cmx = 0;
int mx = 0;
for (int i = 0; i < n; i++) {
mx = max(mx, a[i]);
if (a[i] == mx) cmx++;
}
int res = n - cmx;
cout << res << "\n";
}
int main() {
srand(time(0));
ios::sync_with_stdio(0);
cout.tie(0), cin.tie(0);
int T = 1;
cin >> T;
while (T--) {
solve();
}
}
2176B - Optimal Shifts
What is the answer for the strings "101", "1010", "10101", "101010", and so on?
Is the optimal set of operations different for the strings "100", "010", and "001"?
What is the answer for the strings "100", "0100", "00100", "001000", and so on?
Is the answer different for the strings "0100100", "100011", "001110110"?
Consider all groups of consecutive zeros in the cyclic string $$$S$$$.
Let the number of zeros in these groups be $$$z_1, z_2, \ldots, z_k$$$, where $$$k$$$ is the number of groups.
In this case, the answer is $$$MZ = \max(z_j)$$$.
We will show that the answer $$$MZ$$$ is always achievable as a result:
- We can perform the operation with $$$d = 1$$$ exactly $$$MZ$$$ times.
- After each operation, all $$$z_j \gt 0$$$ will decrease by $$$1$$$, as the leftmost zero in each block will turn into a one.
- Since $$$MZ = \max(z_j)$$$, after exactly $$$MZ$$$ operations, all $$$z_j$$$ will be equal to zero.
We will show that it is impossible to obtain an answer better than $$$MZ$$$:
- Suppose there exists an answer with the sum of cyclic shifts $$$S = d_1 + d_2 + \dots + d_m$$$, where $$$S \lt MZ$$$.
- Consider the largest block of zeros (its size is $$$MZ$$$) and the one to the left of this block.
- When applying the first operation with shift $$$d_1$$$, we could not have created ones in positions to the right of $$$d_1$$$ in this block.
- When applying the subsequent cyclic shifts, this one can also only move to the right by the value of the shifts.
- In total, this one can only move $$$S$$$ positions to the right from its original position, which is strictly less than $$$MZ$$$ — thus the last zero of the block will remain a zero, contradicting the initial assumption.
#include <iostream>
#include <vector>
using namespace std;
#define vi vector<int>
#define ll long long
void solve() {
int n;
cin >> n;
string s;
cin >> s;
s += s;
n *= 2;
int cur = 0;
int res = 0;
for (int i = 0; i < n; i++) {
if (s[i] == '1') cur = 0;
else cur++;
res = max(res, cur);
}
cout << res << "\n";
}
int main() {
int T;
cin >> T;
while (T--) {
solve();
}
}
2176C - Odd Process
You have $$$n$$$ coins, and all of them are even. What will the answers be for all $$$k$$$?
You have two coins: one even and one odd. What will the answers be for $$$k = 1$$$ and $$$k = 2$$$?
You have $$$n$$$ coins, and exactly one of them is odd. What will the answers be for all $$$k$$$?
You have $$$n$$$ coins, and all of them are odd. What will the answers be for all $$$k$$$?
You have $$$n$$$ coins, and exactly three of them are odd. What will the answers be for $$$k = (n - 2)$$$, $$$(n - 1)$$$, and $$$n$$$, respectively?
You have $$$n$$$ coins, and exactly four of them are odd. What will the answers be for $$$k$$$ from $$$(n - 3)$$$ to $$$n$$$?
If all the coins you have are even, then regardless of your actions, the bag will be empty every time.
Let's say we have one odd coin $$$oc$$$ and several even coins $$$ec_1, ec_2, \dots, ec_m$$$.
We will sort the even coins in descending order: $$$ec_1 \ge ec_2 \ge \dots ec_m$$$.
In this case, for $$$k = 1 \dots (m + 1)$$$, we can construct the following answers:
- $$$oc$$$
- $$$oc + ec_1$$$
- $$$oc + ec_1 + ec_2$$$
- $$$\dots$$$
- $$$oc + ec_1 + ec_2 + \dots + ec_m$$$.
But what to do if there are several odd coins?
Let $$$oc$$$ be the largest of the odd coins.
We will perform the above actions for all $$$k$$$ from $$$1$$$ to $$$(m + 1)$$$.
For $$$k = (m + 2)$$$, we will use the following construction:
- First, we will put any two odd coins that are not the coin $$$oc$$$ into the bag.
- Next, we will put the coin $$$oc$$$ and all even coins except the smallest one $$$ec_m$$$.
For $$$k = (m + 3)$$$, we will add the smallest even coin $$$ec_m$$$ to the already constructed answer.
For $$$k = (m + 4)$$$, we will add two more "unnecessary" odd coins at the beginning and again remove $$$ec_m$$$.
For $$$k = (m + 5)$$$, we will add $$$ec_m$$$ again, and so on.
Note for $$$k = n$$$: if you have an even number of odd coins in total, then regardless of the order of addition, the bag will be emptied in the end.
#include <iostream>
#include <vector>
#include <algorithm>
#include <map>
#include <ctime>
#include <queue>
#include <iomanip>
#include "assert.h"
#include <math.h>
#include <set>
#include <deque>
using namespace std;
#define vi vector<int>
#define vii vector<pair<int, int>>
#define pii pair<int, int>
#define ll long long
#define pll pair<ll, ll>
const ll INF = 2e18;
void solve() {
int n;
cin >> n;
vi a(n);
for (int i = 0; i < n; i++) cin >> a[i];
vi odd, even;
for (int i = 0; i < n; i++) {
if (a[i] & 1) odd.push_back(a[i]);
else even.push_back(a[i]);
}
sort(odd.begin(), odd.end());
sort(even.begin(), even.end());
reverse(even.begin(), even.end());
vector<ll> prefeven((int)even.size() + 1);
if (even.size() > 0) {
prefeven[0] = 0;
for (int i = 0; i < even.size(); i++) prefeven[i + 1] = prefeven[i] + even[i];
}
ll ans = -INF;
int cntodd = (int)odd.size();
int cnteven = 0;
for (int i = 0; i < n; i++) {
if (a[i] % 2 == 0) cnteven++;
}
int odd1 = 1, even1 = 0;
if (odd.size() == 0) odd1 = 0, even1 = 1;
for (int k = 1; k <= n; k++) {
if (k > 1) {
if (even1 < even.size()) even1++;
else {
if (odd1 + 2 <= odd.size() && even1 > 0) {
odd1 += 2;
even1--;
}
else {
odd1++;
}
}
}
if (odd1 & 1) {
cout << odd.back() + prefeven[even1] << " ";
}
else {
cout << 0 << " ";
}
}
cout << '\n';
}
int main() {
srand(time(0));
ios::sync_with_stdio(0);
cout.tie(0), cin.tie(0);
int T = 1;
cin >> T;
while (T--) {
solve();
}
}
2176D - Fibonacci Paths
In this Editorial, we will refer to simple paths in the graph, where the sequence of numbers forms a generalized Fibonacci sequence, as Fibonacci paths.
Think about what the simplest Fibonacci paths look like.
The simplest Fibonacci paths are paths of two vertices ($$$u,v$$$) connected by an edge. Moreover, any edge in the graph is a Fibonacci path, as the corresponding sequence of numbers (the ends of the edge) consists of only two numbers.
Now think about what longer Fibonacci paths look like.
Longer Fibonacci paths consist of a sequence of edges such that the numbers at the ends of the first edge are arbitrary. But the number at the end of any other edge is the sum of the numbers at the ends of the previous edge and the beginning of the current edge.
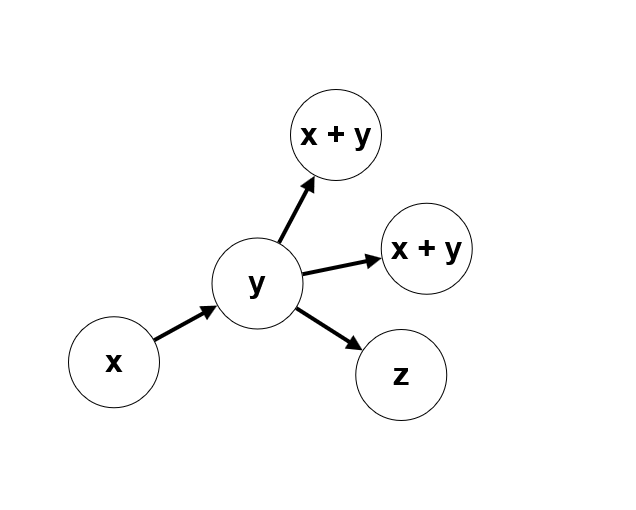
Think about dynamic programming on edges.
Let's count $$$dp[uv]$$$ — the number of Fibonacci paths that start with the edge ($$$u,v$$$). The transitions in such dynamics will look like $$$dp[uv]=\sum dp[vw]$$$, for such edges ($$$v,w$$$) for which $$$cost[w]=cost[u]+cost[v]$$$.
How to compute such dynamics if it depends on the order of processing edges? We could introduce a parameter $$$k$$$ — fix the length of the Fibonacci path, and then the dynamics would look like $$$dp[uv][k]=\sum dp[vw][k-1]$$$. But there is a simpler way.
Notice that in a Fibonacci path, for each subsequent edge, the sum of the numbers at its ends is strictly greater than the sum of the numbers at the ends of the previous edge. This means that edges with a greater sum of numbers should be processed strictly before edges with a smaller sum of numbers, and the order of processing edges with the same sum can be arbitrary, as they cannot be part of the same Fibonacci path.
Then we will sort the edges, and it will remain only to quickly recalculate the sum $$$dp[uv]=\sum dp[vw]$$$ from the dynamics. Naively searching for edges ($$$v, w$$$) where $$$cost[w]=cost[u]+cost[v]$$$ will not work, as the asymptotic complexity of such a solution will easily be $$$O(E^2)$$$ or worse.
Therefore, we will compress edges with the same value at the end and coming from the same vertex together. For each vertex $$$u$$$, we will maintain a dictionary $$$dp[u][cost]$$$ — the number of Fibonacci paths from vertex $$$u$$$ that go to some vertex $$$v$$$ with value $$$cost$$$.
The recalculation of this dynamics is such that $$$dp[u][cost[v]] = dp[u][cost[v]] + (1 + dp[v][cost[u] + cost[v]])$$$ — the value of the dynamics $$$dp[u][cost[v]]$$$ is incremented by the number of paths from vertex $$$v$$$ with cost $$$cost[u]+cost[v]$$$, plus one for the path from a single edge ($$$u,v$$$).
The asymptotic complexity of the solution is $$$O(E\cdot\operatorname{log}(E))$$$.
#include <bits/stdc++.h>
using namespace std;
#define vi vector<int>
#define vii vector<pair<int, int>>
#define pii pair<int, int>
#define ll long long
#define pll pair<ll, ll>
const ll INF = 2e18;
const int MOD = 998244353;
struct Edge {
int u, v;
ll s;
Edge(){}
Edge(int u, int v, ll s) : u(u), v(v), s(s){}
bool operator < (const Edge &other) const {
return s < other.s;
}
};
void add(int &a, int b) {
a += b;
if (a >= MOD) a -= MOD;
}
void solve() {
int n, m;
cin >> n >> m;
vector <ll> a(n);
for (int i = 0; i < n; i++) cin >> a[i];
vector <vi> g(n);
vector <Edge> edges;
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
u--;
v--;
g[u].push_back(v);
edges.push_back(Edge(u, v, a[u] + a[v]));
}
sort(edges.begin(), edges.end());
reverse(edges.begin(), edges.end());
vector<map <ll, int>> sumdp(n);
int ans = 0;
for (auto e : edges) {
int u = e.u;
int v = e.v;
ll s = e.s;
//cout << u << " " << v << " " << s << endl;
int curdp = sumdp[v][s];
add(curdp, 1);
add(sumdp[u][a[v]], curdp);
add(ans, curdp);
}
cout << ans << "\n";
}
int main() {
srand(time(0));
ios::sync_with_stdio(0);
cout.tie(0), cin.tie(0);
int T = 1;
cin >> T;
while (T--) {
solve();
}
}
2176E - Remove at the lowest cost
Come up with a solution to the problem without queries.
Let's look at the maximum elements. What can you say about the segments between them?
Let's first provide a theoretical estimate for the answer, followed by an algorithm that achieves this estimate.
Let's introduce $$$\operatorname{f}(l, r, x)$$$, which means the following: suppose we only consider the elements $$$a_l, a_{l + 1}, \ldots, a_{r - 1}$$$, and we can eliminate each of them using an element with a removal cost of $$$x$$$. What is the minimum removal cost for the entire range? Let's assume that we pass the best possible value to $$$x$$$.
Then let $$$p_1, p_2, \ldots, p_m$$$ be the positions of all the maxima on the interval. Note the following facts:
For any $$$i, j$$$ for which there exists $$$k$$$ such that $$$l \leq i \lt p_k \lt j \lt r$$$, there is no sequence of operations in which one of these elements removes the other
At least one of the elements $$$p$$$ must be removed by an element outside this interval
The elements $$$p_1, p_2, \ldots, p_m$$$ can be removed either for the cost of $$$x$$$ or for the cost of another maximum element
Define $$$x' = min(x, c_{p_1}, c_{p_2}, \ldots, c_{_m})$$$. Then from these three remarks, we can conclude that, with the optimal choice of $$$x$$$ earlier, $$$\operatorname{f}(l, r, x) = x' \cdot m + \operatorname{f}(l, p_1, x') + \operatorname{f}(p_1 + 1, p_2, x') + \ldots + \operatorname{f}(p_m + 1, r, x')$$$.
This is true because, according to point 2, there must be at least one element that is removed by an element outside the interval. According to point 3, we can remove the remaining $$$m - 1$$$ maxima only using $$$x$$$ and other elements $$$p_i$$$, and the remaining maximum is $$$x'$$$(according to the condition). And according to point 1, all the segments are independent of each other, if we do not consider the maxima.
In this case, the answer to the problem is $$$\operatorname{f}(0, n, inf) - inf$$$.
Now, we will show that this sequence of deletions is valid.
We will also recursively remove segments, but with the condition that this minimum element outside the segment will lie strictly to the left or to the right of the segment $$$l, r$$$. Then, when we have selected $$$x'$$$, we can perform the following process:
We have a set of segments $$$(l_1, r_1), \ldots, (l_{m + 1}, r_{m + 1})$$$. We will find a segment that is a neighbor of the element $$$x'$$$, and we will recursively remove it. After that, this optimal neighbor will have one of the maximum elements as a neighbor (or we will have removed the entire segment). We remove it for $$$x'$$$.
This process will end when there is exactly one element that can be removed for $$$x'$$$. It is easy to see that we have reached our estimate, which means that the recursive algorithm above actually returns the answer to the problem.
What is the structure of the recursive calls to the function $$$\operatorname{f}$$$? Can we remember it and then use it to efficiently process requests? For which elements will the cost of deleting them change when we set it to zero?
Note that the structure of the function calls $$$\operatorname{f}$$$ is a tree. Let's save it and remember the price we paid for removing each element, let's call it $$$r_i$$$.
Then, when the request to zero $$$c_{p_i}$$$ comes, we take the node for which $$$p_i$$$ is one of the maximums and perform a depth-first search on the subtree of this node, avoiding the nodes that have already been zeroed. Thus, we change the corresponding values of $$$r_i$$$ to $$$0$$$ and recalculate the global answer.
The complexity of the solution is $$$O(n \log{n})$$$, as we need to calculate the maximum on a segment to implement the function $$$\operatorname{f}$$$, which may require a segment tree or a sparse table.
There may be other approaches to the problem.
#include <iostream>
#include <vector>
#include <set>
#include <map>
#include <algorithm>
#include <deque>
#include <queue>
#include <iomanip>
using namespace std;
#define ll long long
#define vi vector<int>
#define pii pair<int, int>
#define vii vector<pii>
const int N = 505010;
const int MOD = 1e9 + 7;
vi g[3 * N];
int cost1[3 * N], cost2[3 * N];
int tree[4 * N], pos[4 * N], a[N], c[N];
int nxtL[N], nxtR[N];
int num[N];
int n, q;
void build(int v, int tl, int tr) {
if (tl == tr) {
tree[v] = a[tl];
pos[v] = tl;
return;
}
int tm = (tl + tr) / 2;
build(v * 2, tl, tm);
build(v * 2 + 1, tm + 1, tr);
if (tree[v * 2] > tree[v * 2 + 1]) {
tree[v] = tree[v * 2];
pos[v] = pos[v * 2];
}
else {
tree[v] = tree[v * 2 + 1];
pos[v] = pos[v * 2 + 1];
}
}
pii getmax(int v, int tl, int tr, int l, int r) {
if (l > r) return { -1, -1 };
if (l == tl && r == tr) {
return { tree[v], pos[v] };
}
int tm = (tl + tr) / 2;
pii tmp = max(getmax(v * 2, tl, tm, l, min(r, tm)), getmax(v * 2 + 1, tm + 1, tr, max(l, tm + 1), r));
return tmp;
}
int state = -1;
ll ans;
void addEdge(int v, int u) {
if (v == -1 || u == -1) return;
g[v].push_back(u);
}
int it = 0;
int precalc(int l, int r, int minc) {
int xx = minc;
state++;
int vres = state;
if (l > r) return vres;
pii p = getmax(1, 0, n - 1, l, r);
vi t;
int pos = p.second;
while (pos >= l) {
t.push_back(pos);
pos = nxtL[pos];
}
reverse(t.begin(), t.end());
pos = nxtR[p.second];
while (pos <= r) {
t.push_back(pos);
pos = nxtR[pos];
}
for (int x : t) minc = min(minc, c[x]);
for (int x : t) num[x] = vres;
if (xx <= (int)1e9) ans += minc;
cost1[vres] = minc;
ans += 1ll * minc * ((int)t.size() - 1);
addEdge(vres, precalc(l, t[0] - 1, minc));
for (int i = 1; i < t.size(); i++) {
addEdge(vres, precalc(t[i - 1] + 1, t[i] - 1, minc));
}
addEdge(vres, precalc(t.back() + 1, r, minc));
for (int v : t) num[v] = vres;
return vres;
}
void go(int v) {
if (!cost1[v]) return;
if (!g[v].size()) return;
if (v == 1) ans -= 1ll * ((int)g[v].size() - 2) * cost1[v];
else ans -= 1ll * ((int)g[v].size() - 1) * cost1[v];
cost1[v] = 0;
for (int u : g[v]) {
go(u);
}
}
void solve() {
cin >> n;
for (int i = 0; i < n; i++) cin >> a[i];
for (int i = 0; i < n; i++) cin >> c[i];
vi p(n);
for (int i = 0; i < n; i++) cin >> p[i], p[i]--;
map <int, int> lst;
for (int i = 0; i < n; i++) {
if (lst.find(a[i]) == lst.end()) nxtL[i] = -1;
else nxtL[i] = lst[a[i]];
lst[a[i]] = i;
}
lst.clear();
for (int i = n - 1; i >= 0; i--) {
if (lst.find(a[i]) == lst.end()) nxtR[i] = n;
else nxtR[i] = lst[a[i]];
lst[a[i]] = i;
}
build(1, 0, n - 1);
for (int i = 0; i <= 3 * n; i++) g[i].clear();
ans = 0;
state = 0;
int root = precalc(0, n - 1, (int)1e9 + 1);
cout << ans << " ";
for (int i = 0; i < n; i++) {
int j = num[p[i]];
go(j);
cout << ans << " ";
}
cout << "\n";
}
int main()
{
int T = 1;
cin >> T;
while (T--) {
solve();
}
return 0;
}
2176F - Omega Numbers
Try to express $$$\omega(x \cdot y)$$$ in terms of $$$\omega(x)$$$ and $$$\omega(y)$$$.
$$$\omega(x \cdot y) = \omega(x) + \omega(y) - \omega(\operatorname{gcd}(x,y))$$$. How large can $$$\omega(x)$$$ and $$$\omega(x \cdot y)$$$ be?
$$$\omega(x) \leq 6$$$, $$$\omega(x \cdot y) \leq 12$$$. How can we count the number of pairs ($$$x,y$$$) with a fixed sum $$$\omega(x)+\omega(y)=const$$$ and a fixed $$$\operatorname{gcd}(x,y)=const$$$?
Let $$$K$$$ denote the maximum number of unique primes in the factorization of any number under the given constraints. In this problem, $$$K \leq 6$$$, and asymptotically $$$K=O(\operatorname{log}(maxA))$$$.
Let's try to compute $$$dp[g][sum_{len}]$$$ — the number of ordered pairs ($$$i,j$$$) such that $$$\operatorname{gcd}(a_i,a_j)=g$$$, and $$$\omega(a_i)+\omega(a_j)=sum_{len}$$$. If we can compute this dynamic programming, then the answer to the problem is: $$$\sum_{g=1}^{g=n}\sum_{len=1}^{len=2 \cdot K}dp[g][sum_{len}] \cdot (sum_{len}-\omega(g))^k$$$.
A well-known method can be used to count the number of pairs of numbers in the array ($$$i,j$$$) for which $$$\operatorname{gcd}(a_i,a_j)=g$$$ for any number $$$g$$$ from $$$1$$$ to $$$maxA$$$. Let's modify this method for our problem.
Let $$$cnt[x][len]$$$ be the number of numbers in the original array that are divisible by $$$x$$$, and for which $$$\omega(x)$$$ equals $$$len$$$.
To compute this auxiliary dynamic programming, we can iterate over each $$$x$$$ from $$$1$$$ to $$$maxA$$$, and for each $$$x$$$, iterate over its multiples and add to $$$cnt[x][\omega(i \cdot x)]$$$ the count of multiples $$$i \cdot x$$$ from the array. The asymptotic complexity of this counting is $$$O(n \cdot \operatorname{log}(n))$$$ (partial sums of the harmonic series).
Now we are ready to compute the dynamic programming $$$dp[g][sum_{len}]$$$. Let's iterate over the greatest common divisor $$$g$$$ from $$$maxA$$$ down to $$$1$$$. If we simply wanted to count the number of pairs with $$$\operatorname{gcd}=g$$$, we would subtract the already counted pairs with larger multiples of $$$\operatorname{gcd}$$$.
But now we also have a fixed total length $$$\omega(x)$$$ of both numbers in the pair. Therefore, for a fixed $$$g$$$, we will also iterate over 2 parameters — $$$len_a$$$ and $$$len_b$$$, that is, $$$\omega(a)$$$ and $$$\omega(b)$$$ for both numbers.
Then $$$dp[g][sum_{len}]=dp[g][\omega(a) + \omega(b)]=dp[g][i+j]=cnt[g][i] \cdot cnt[g][j]$$$, where $$$i,j$$$ are iterated from $$$1$$$ to $$$K$$$. Here we also need to be careful and account for the case when $$$i=j$$$, in which case we add $$$\frac{cnt[g][i] \cdot (cnt[g][i] - 1)}{2}$$$ to $$$dp[g][i+j]$$$.
Next, we simply iterate over the multiples of $$$g$$$: $$$2 \cdot g, 3 \cdot g, \ldots$$$, to subtract the intersections $$$dp[g][sum_{len}] = dp[g][sum_{len}] - dp[i \cdot g][sum_{len}]$$$.
The asymptotic complexity of the solution is $$$O(maxA \cdot (K^2 + K \cdot \operatorname{log}(maxA)))$$$.
#include <bits/stdc++.h>
using std::cin;
using std::cout;
using vi = std::vector<int>;
using vvi = std::vector<vi>;
using ll = long long;
const auto ready = []()
{
cin.tie(0);
std::ios_base::sync_with_stdio(false);
return true;
}();
ll binpow(ll a, ll p, ll mod)
{
ll res = 1;
ll mult = a;
while (p) {
if (p & 1) res = res * mult % mod;
mult = mult * mult % mod;
p >>= 1;
}
return res;
}
const ll mod = 998244353;
const int max_a = 2e5 + 10;
const int max_len = 6;
vi fi_div(max_a);
vi num_len(max_a);
void precalc() {
// Here we precompute the number of unique primes in each number, i.e. w(n)
for (int i = 2; i < max_a; ++i) {
if (fi_div[i] == 0) {
for (int j = i; j < max_a; j += i) {
if (fi_div[j] == 0) fi_div[j] = i;
}
}
}
for (int i = 2; i < max_a; ++i) {
int x = i;
int len = 0;
while (x > 1) {
++len;
int tmp = fi_div[x];
while (fi_div[x] == tmp) x /= tmp;
}
num_len[i] = len;
}
}
void solve() {
int n, k;
cin >> n >> k;
vi vec(n);
for(int i = 0; i < n; ++i) cin >> vec[i];
vvi cnt(n + 1, vi(max_len + 1));
for(int i = 0; i < n; ++i) {
int x = vec[i];
cnt[vec[i]][num_len[x]] += 1;
}
// Here we calcualte auxilary dp - cnt[x][len] - how many numbers with w(n) = len are divisible by x
for (int i = 1; i < n + 1; ++i) {
vi dp(max_len + 1);
for (int j = i; j < n + 1; j += i) {
for(int s =0 ; s < max_len + 1; ++s) dp[s] += cnt[j][s];
}
cnt[i] = dp;
}
vvi dp(n + 1, vi(2 * max_len + 1));
ll ans = 0LL;
// Here we calcualte dp[g][len]
for (int g = n; g >= 1; --g) {
// Account for cases len_a != len_b
for (int len1 = 0; len1 <= max_len; ++len1) {
for (int len2 = len1 + 1; len2 <= max_len; ++len2) {
dp[g][len1 + len2] += 1LL * cnt[g][len1] * cnt[g][len2] % mod;
dp[g][len1 + len2] %= mod;
}
}
// Account for cases len_a = len_b
for (int len = 0; len <= max_len; ++len) {
dp[g][len + len] += 1LL * cnt[g][len] * (cnt[g][len] - 1) / 2 % mod;
dp[g][len + len] %= mod;
}
// Subtruct states with where gcd is multiple of current g
for (int j = 2 * g; j < n + 1; j += g) {
for(int s = 0; s < 2 * max_len + 1; ++s) {
dp[g][s] -= dp[j][s];
dp[g][s] %= mod;
}
}
for(int s = 0; s < 2 * max_len + 1; ++s) {
dp[g][s] %= mod;
dp[g][s] += mod;
dp[g][s] %= mod;
}
// Add k-th powers to the answer
int gcd_len = num_len[g];
for (int len = 0; len < 2 * max_len + 1; ++len) {
int rad = len - gcd_len;
ans += dp[g][len] % mod * binpow(rad, k, mod) % mod;
ans %= mod;
}
}
cout << ans << "\n";
}
int main()
{
precalc();
int t;
cin >> t;
while (t--) solve();
return 0;
}
Tutorial of Codeforces Round 1070 (Div. 2)






Auto comment: topic has been updated by ABalobanov (previous revision, new revision, compare).
Writing first so 123gjweq2 can't say first
I couldn't understand the tutorial code, so here's a (maybe) simpler top-down DP implementation with a very similar idea (compressing edge state into (end node index, start node value) pairs) for those like me. 353122473
Nice,,this code matches my idea
I thought of a different solution for problem D that barely passed in time.
Observe that the value written at a certain vertex is at most $$$10^{18}$$$. Therefore, no generalized Fibonacci path is longer than $$$86$$$ nodes, as the $$$87$$$-th non-generalized Fibonacci number is greater than $$$10^{18}$$$ (and this should hold for any other larger starting numbers than both being $$$1$$$). This can easily be checked with a program that calculates the first $$$n$$$ Fibonacci numbers.
Thus, we can store for each node the amount of paths that require the next node in a path to have a certain value, which is given by the sum of the value at the node and each adjacent node entering it, calculated in the previous iteration. Initially, accounting for paths of length 2, we can store at the destination of each edge all the sums between the value of that node and any node entering it, counting possibly repeated sums.
For convenience I used the reversed graph, as that way I could just check for a each node in an iteration if its value is present at the
mapof sums computed in the previous iteration for each of the outgoing nodes. Though that was just a decision I made while implementing during the contest.Due to the initial observation, there would be at most $$$87$$$ iterations over all the nodes and edges. Also, by using a map to lookup and update values present at a certain destination, I have a $$$\log$$$ factor in my solution to account for.
Hence, the complexity of this solution should be around $$$O(87 \cdot (n+m) \log m)$$$, considering in each iteration at most $$$m$$$ distinct sums would be computed (one for each edge), amounting to around $$$6.5 \cdot 10^8$$$ operations (explaining why my solution barely passed the TL). Also, I may be off in the exact numbers, but the general idea is that "Fibonnaci paths are short".
Here's my submission: 353082932
I tried to make use of the same idea (paths have length at most $$$87$$$) in some of my initial submissions but got TLE. After that, I realised I can just sort the vertices by $$$a_i$$$ and compute the DP in that order, so I very quickly modified the code to make it pass. Even the for-loop over the lengths is still in there!
Yup, after reading the editorial I got the idea of sorting edges by value in their destination, and I modified the submission I posted above. It passed in just 0.2s. The code is identical apart from that: 353380486
While in contest I also got a TLE, so I changed to a newer compiler, optimized access to maps a bit to avoid sometimes accessing two times unnecessarily, and crossed my fingers haha. Glad I got a bit lucky.
Nevertheless, I thought the idea was neat and worth mentioning.
Here is my two pass greedy linkedlist solution for E:
https://mirror.codeforces.com/contest/2176/submission/353120120
O(Nlog(N)) because of an initial sort, otherwise O(N).
I used the linked list to solve E too. Each time, choose the element that has the smallest removal cost and delete the elements on both sides whose natural values are not greater than the chosen element.
Here's my c++ implementation:
https://mirror.codeforces.com/contest/2176/submission/353133414
Sorry,what is the meaning of the natural values.
Oh... In the problem, $$$a_i$$$ is defined as the natural value.
can anyone help me with problem D?
https://mirror.codeforces.com/contest/2176/submission/353126337
whats wrong here?intuitively seems perfect but getting wa on test 1 itself
Why my code fail on C.
what if we do not have enough evens :)
If even is used up, we gonna used $$$2$$$, $$$3$$$, $$$4$$$, …… odd numbers. But we don't want to use even times of odd numbers, let number of even number is $$$m$$$, when $$$k = m + 2$$$,i use three odd number and remove a minimum even number, when $$$k = m + c$$$ which $$$c$$$ is an odd number, the answer equals to $$$res_{m + 1}$$$. Why my code fail?
I get it. When I was modifying the code, I forgot to put this for loop outside the if statement.
I have a slightly different approach to D. I simply used DFS and memoization to find the answer. Since using map would give MLE (353062066), I used unordered map with custom hash function (353064160), which reduced the memory by a lot.
Can u help me memoise my code ? i think i was doing what u are thinking about ig. Anyway , see if you can help, thanks!
353249392
Use the dfs as a non-void function and memoise the answer to [idx, par], since the answer to [idx, par] doesn't change
Will do and get back to you. Thanks!
Can you tell me why am I getting TLE even with O(m) solution? 353299803
think like i have a graph like a star graph a middle node and left side has roughly m/2 nodes and right side also has m/2 nodes so your code will compute this type of graph answer in O(M/2 * M/2) which is O(M^2) that is the reason you are getting tle to avoid that you have to take them as a group and then propogate everyone value in the middle first and then propogate it to the next right half so it will reduce your time complexity to O(M/2 + M/2 ) which is O(M)
What is the complexity of your code though?
I think O(n + m)
Here is my solution to Problem D: Due to the rapid growth rate of Fibonacci, we can use DFS to calculate each Fibonacci number brute-force, and incorporate memoization to solve this problem. 353130807
having hints before main solution is really helpful, thanks
Convolution solution to F:
As mentioned, there are a number of solutions for F that simply use a standard method to AC the problem. One such method is the GCD convolution. This blog here has a very clean and nice description of the general ideas behind the zeta and mobius transforms used in the GCD convolution.
Generally speaking, the idea is very straightforward:
Here is my implementation: 353129856. Notice that although the code is a bit long, it's mostly just from boilerplate to determine the omega for each value and the code for the GCD convolution and the associated transforms (as an optimization, I didn't use the provided GCD convolution method but I'm still executing, well, a GCD convolution). The logical part in and of itself is relatively succinct.
In problem C, what is m?
m (in the editorial) is the number of even numbers in the array
Ah okay. Thank you!
Can someone tell why my code is giving wrong answer on test case 2 or give a test case where my code fails
I have found your bug!
Its because you had this line:
if(even.size()==1) val[k]=0The counterexample is this case
n=5a = {1, 1, 1, 1, 2}The AC code outputs:
1 3 1 3 0But your code outputs:1 3 0 3 0Thank you
E can be solved using segment tree beats.
For each
ifindl,rwhich is the widest range (includingi) that have values<=a[i](using stack). Then update the cost for removing each element in rangeltorby assigning it tomin(cost[j],c[i])for which we use segtree beats. Initial answer would besum of cost for all minus cost for last remaining element(which is minimum ofc[j]wherea[j]==max(a)). For zeroing operations, you usel,rof that element and updatecost[j]tomin(cost[j],0)and again find the sum of all costs. Once you have zeroed any index such thata[i]==max(a)all further costs will be0.This solution can be used to solve for a type of updation query where you reduce
cfor any element.can anyone tell me, what is the error in this code ~~~~~ // this is code
include<bits/stdc++.h>
using namespace std; typedef long long ll; int main() { ll t,n,i,odd,even,sum,k,check; cin>>t; while(t--) { cin>>n; ll array[n]; odd=0,even=0; vectorodds,evens; for(i=0;i<n;i++) { cin>>array[i]; if(array[i]%2==1) { odd++; odds.push_back(array[i]); } else { even++; evens.push_back(array[i]); } } sort(odds.begin(),odds.end(),greater()); sort(evens.begin(),evens.end(),greater()); vectorpresum; sum=0; for(i=0;i<evens.size();i++) { sum+=evens[i]; presum.push_back(sum); } if(odd==0) { for(i=1;i<=n;i++) cout<<0<<" "; cout<<endl; } else if(even==0) { for(i=1;i<=n;i++) { if(i%2==1) cout<<odds[0]<<" "; else cout<<0<<" "; } cout<<endl; } else { if(odd==1) { cout<<odds[0]<<" "; for(i=0;i<presum.size();i++) cout<<odds[0]+presum[i]<<" "; cout<<endl; } else if(odd==2) { cout<<odds[0]<<" "; for(i=0;i<presum.size();i++) cout<<odds[0]+presum[i]<<" "; cout<<0<<" "<<endl; } else {// odds>=3 cout<<odds[0]<<" "; for(i=0;i<presum.size();i++) cout<<odds[0]+presum[i]<<" "; k=1+presum.size(); check=(k%2); for(i=k+1;i<=n;i++) { if((i%2)==check) cout<<odds[0]+presum[presum.size()-1]<<" "; else cout<<odds[0]+presum[presum.size()-2]<<" "; } cout<<endl; } } } return 0; } ~~~~~
fails for test case t=1,n=7,a=
6 4 2 1 3 5 7where k=n.And the answer for s_tapan099's tc is
7 13 17 19 17 19 0A nice observation can make code for C easier. Here is my submission 353059457 Following the nomenclature in tutorial since for k=m+2 we are using oc and all even except mth therefore it is same for k=m and again for k=m+3 it is same as k=m+1 and so on. All edge cases considered separately — All odd, no odd and even no.of odds.
The hints of problem c are very good.
I like it how he explain all the cases in problem c.
I saw 998345353 at F when I was using a translate plugin. Who proposed the idea? Great!
For E there is a O(n) solution, you do cartesian tree and color the subtree of a node each time, with ascending
c[i]'s. The only caveat is ifa[node] == a[par[node]]you should start coloring frompar[node]so for that I hold alinkarray which gets us to the highest node with the same value as the current one. Here is my solution : https://mirror.codeforces.com/contest/2176/submission/353155958note : I did the sorting with
std::sortfor convenience but you can do that with counting sort to get true O(n)In Problem D, why we should sort the edges by $$$a_u+a_v$$$?
if you have a simple path and it follows the definition of fibonacci sequence, and without loss of generality lets assume if edge (u1,v1) comes before edge (u2, v2) then its sum should also be in the same order.
I spent quite a bit of time on Problem B, only to see a three-line solution in the editorial…
For reference, this is the method I used:
Here’s my submission:B — Optimal Shifts
Can anyone confirm if this actually minimizes the number of operations (not the cost)? Would feel better knowing I wasn’t overcomplicating things.
It turns out there is no need for 87 or 90 bound needed in problem $$$D$$$. The problem doesn't guarantees that the given graph is DAG , but we can still make it a DAG. Note that the sequence is increasing except for the first two elements. Hence make a second graph , which has an edge from $$$u$$$ to $$$v$$$ iff $$$a[v] \gt a[u]$$$. You can look at my submission 353070891
why is my solution failing in problem D
my code : 353225582
I met the same problem with you, just Wrong Answer On test 3 the 251st case. But I don't know why.
For C I think you it doesn't matter which odd number it is, except for the maximum. If at least one odd exists, you could first print the maximum odd number and then m more numbers where the ith number will be maxOdd+ith even number (in descending order) and then for the remaining numbers: m+2 to n, for jth number if (j-m) is odd print the (sum of all even+maxOdd) else print 0, and add check that if there are even number of odd numbers then nth number will be 0 regardless of the parity of j-m.
353291565
I am getting TLE , please help in problem D
Nice editorial for F.
In problem C, cnteven is for what??
What is the "A well-known method can be used to count the number of pairs of numbers in the array (i,j) for which gcd(ai,aj)=g for any number g from 1 to maxA" in F. Can someone say how I can google it or provide a link to editorial of this method?
Well, I think I understood what method was mentioned here. In short, this is a regular dp, where we count the number of pairs that x divides, and then subtract all the other gcds that x divides. This can be done as in sieve of Eratosthenes, and it will work for O(nlogn)
Easy solution for D: Let's replace each edge v->u with an edge between two FAKE vertices: (v << 64 | Y) -> (u << 64 | X + Y), where X is the value associated with vertex v, and Y with u. This way, we obtain a new graph in which ANY path corresponds to a Fibonacci path! Simply count the number of paths in this graph using DFS and caching. https://mirror.codeforces.com/contest/2176/submission/353494951
Can you guys tell me why my D is TLEing?
PROBLEM D: I am getting TLE on test case 11 353509271. What can I do better?
For F, a slightly better bound on K can be given. The primorial function is bigger than n! so it's inverse is less. By Stirling, n! is $$$O\left(e^{n \ln(n)}\right)$$$ and the inverse of this is $$$O\left(\log(n)/\log(\log(n))\right)$$$
I've found, I guess, very simple linear solution to problem E.
Let's see that an element can be killed only by first not-less element on the right|left, or first not-less than first not-less on the right|left, or ...
We will denote the set of elements, which are able to kill element at position $$$i$$$, as $$$killers(i)$$$.
Let's assign for each $$$i$$$ the cheapest element from $$$killers(i)$$$ to kill $$$i$$$.
The observation: there is a sequence of deletions which satisfies our assignments.
The proof's sketch: Let's draw an arrow from each position i to his killer. It suffices to show that there are no crossing arrows. We can see that if two arrows are crossing, then we can reassign one of them and obtain cheaper solution.
It is known that we can compute "first not-less on right|left" in linear time. With a simple DP we can also compute those assignments in $$$O(n)$$$. The answer is just a sum of costs of killing each element. So we solved E without queries.
We can now observe that any changes in elements that doesn't belong to $$$killers(i)$$$ don't have any impact on the cost of killing $$$i$$$. Hence it suffices to compute, for each element, the first time that some member of $$$killers(i)$$$ is changed to zero. We can solve it in $$$O(n)$$$ with very similar DP.
I thought of a different solution for problem C .
The approach is to separate the numbers into even and odd and sort even numbers in descending order and odd numbers in descending order. If there are no odd numbers then the answer would be zero for all k. If there are no even numbers then the answer would be zero for even k and the largest odd number for odd k. We need the sum of even numbers to reduce the O(n) complexity to calculate again, so prefix sums of even numbers are used. For each k, first start by placing the largest odd number. If the number of evens available are enough then just add the number of even numbers required in descending order. If the number of even numbers available are less than required, then if the number of odd numbers to be used are even, simply place them before the largest odd number as their sum would give 0, so the answer should be the largest odd number plus the sum of all even numbers. If the number of odd numbers to be used are odd, then simply remove the smallest even number and place all odd numbers available before the largest odd number, and if k equals n (that is all numbers are to be used) then the sum would be 0.
Here is my submission :
https://mirror.codeforces.com/contest/2176/submission/356942161
Problem C. Odd Process
Can anybody explain sample cases 3 and 4?
Input:
Output:
In sample 3, for example, on $$$k=4$$$, doesn't the bag contain $$$[3, 4, 2, 1]$$$, with the even sum $$$10$$$, therefore being emptied and giving a score of $$$0$$$? How is the score $$$7$$$ instead? Same confusion with sample 4.
For $$$k=4$$$ we can take $$$[1, 1, 3, 4]$$$ in this order. Maybe you miss that we can solve problem independently from previous $$$k$$$
You are right. I missed the point that for each $$$k$$$ we begin with an empty bag. Thanks for the clarification.
4
A Better Approach for Problem C 2176C - ODD PROCESS - Odd Process LYC_666 ~~~~~ #include<bits/stdc++.h> using namespace std;
define int long long
bool cmp(int t1,int t2) { return t1 > t2; }
signed main() { ios::sync_with_stdio(0), cin.tie(0); int t; cin >> t; while (t--) { int n; cin >> n; vectorodd, even; for (int i = 0; i < n; i++) { int v; cin >> v; if (v % 2 == 0) { even.push_back(v); } else { odd.push_back(v); } } if (odd.empty()) { for (int i = 0; i < n; i++) { cout << "0 "; } cout << "\n"; continue; } sort(even.begin(), even.end(),cmp), sort(odd.begin(), odd.end(), cmp); int size = even.size() + 1; vectorpre(size + 1); pre[1] = odd[0]; for (int i = 0; i < even.size(); i++) { pre[i + 2] = pre[i + 1] + even[i]; } for (int i = 1; i < n; i++) { if (i <= size) { cout << pre[i]<<" "; } else { if ((i — size) % 2 == 1) { cout << pre[size — 1] << " "; } else { cout << pre[size] << " "; } } } if (odd.size() % 2 == 0) { cout << "0"; } else { cout << pre[size]; } cout << "\n"; } return 0; } ~~~~~
359184091