


I hope you enjoyed the contest!
Editorials of all problems have been added. Also if you can explain your solution in the comments, please do so! That would be still very helpful for other participants.
2202A - Дизайн паркура
2202B - Построение ABAB
2201A1 - Потерянная цивилизация (простая версия)
2201A2 - Потерянная цивилизация (сложная версия)
Thanks to Proof_by_QED for suggesting this subtask!
2201B - Соберите числа
2201C - Нечестная скобочная последовательность
Thanks to reirugan for writing the model solution without bugs!
2201D - Бинарный не-поиск и запросы
2201E - Счетчик ABBA
Thanks to satyam343 which suggested a modification of an easier problem, which later turned into this problem!
2202G1 - Монотонные монохромные матрицы (простая версия)
2201F1 - Монотонные монохромные матрицы (средняя версия)
2201F2 - Монотонные монохромные матрицы (сложная версия)
2201G - Эвристический контест Codeforces 1001
Special thanks to sammyuri for finding the intended solution!
We are not providing you with the editorial for Div1G, this is a deliberate decision. The main crux of the problem lies in your creativity, and I don't want to limit your creativity by showing you the solution! Instead, we will try to give you some hints to guide you on what the problem actually "tries" to do. (So it will pretty much "look" like an editorial, we'll just not give you the final construction!)






Fast editorial, also very few people gave the contest, maybe because of mid-sems ;)
I think today less people gave the contest
yes the participation count was much lesser too
midsem time in india, lol!
Loved the problem Div2D / Div1B
This problem is quite similar to a certain poker game that we sometimes play. :D
because of c2 missed the problem, regretting after solving Div2D
I dont really have a thing to complain about this contest LMAO XD
orz
I think problem B in this contest is more difficult than other div2 contests
How do you guys solve the questions so fast? Every question from every contest seems so different from each other. How Do i improve?? :(
just constantly solve, like endlessly. improvement comes with experience , pattern recognition, dedication, burnout prevention.
Am I the only one who found the DP approach for C2 way easier than the stack one? I saw a ton of people doing stack solutions, but DP just felt so much lighter and more intuitive to me. I just let dp[i] store the total sum of f(a[j...i]) for all points j (where 1 <= j <= i).
If you need x minimum numbers to satisfy the condition upto [1...i], you just look back at the previous state. If the prefix up to i-1 also needed those exact same x minimum numbers, your current state just smoothly extends from it having dp[i]+i-p basically where p is the first index where you could get a[i] as a[i]-1 basically, and if you need x+1 numbers than the previous one then its just dp[i] + i+1 as you would need +1 for all of the subarrays computed previously and including the current value as a[i] can be an independent value too. You basically just carry over the state from dp[i-1] without having to overcomplicate things. The transition is extremely clean.
[submission:https://mirror.codeforces.com/contest/2202/submission/364102671]
Real nice!
I also used DP approach for C2. I think it depends on how people do C1
Ahh I see
Nice Div2B. I just love those problems that make me again and again realize all of my time and efforts put into CP is just completely meaningless and useless as well as the whole existence of myself as long as I am dong this. Really, really looking forward to the end of my miserable and painful and tragic CP life when I will finally become a normal and happy and healthy human being.
give me a hug bro so same TwT
B was crazy.
-152 :) so sorry for you
when a problem just doesn't click, it can feel like all the effort you've put in is meaningless. But: your worth as a person is not tied to solving a Div2B, or any problem. CP is just one activity among many. it doesn't define you maybe we should take a break; if it is no longer bringing you joy or fulfillment, it's absolutely fine to shift your focus to other things that make you feel happy and healthy. your well-being matters far more than any rating or problem solved. all the best
one failure means nothing. if failure were enough to kill a person, then my life is filled with failures— I would have died countless times now. we fall, we get back up. that's the reason why we live in the world.
DIV 2B was tricky
for me difficulty of problems are: C1<C2<B<A (div2)
Yes, it seems that the first few questions of this competition were quite unconventional.
I have an easier approach for Div2 B, who knows DP. since string T is fixed we can compute dp[i][char at begin][char at last]=can we generate the string up till i by making firstchar and lastchar at i here is the submission link. Submission
My solution for Div2 C1 and C2 / Div1 A1 and A2. I didn't use a stack for implementation, so I thought this might be an alternate solution.
Solution for C1
We maintain two variables l and r. Let v denote the input vector Initially set l and r both to INT_MAX. Let the variable ans=0. Then we can run the following algorithm:-
Start Loop
For i=0,1,2, ... N-1
If v[i]-1 does not lie between l and r, update l to v[i]
Update r to v[i]
End loop
Return ans
Proof of correctness:- Let us try to understand in a layman sense what l and r actually represent. For any given 0<=i<n, for v[i] not to be an original element, v[i]-1 must have appeared before. This is a necessary condition, but it's not sufficient. Consider the test case, n=5, v=[1,2,3,2,4]. In this case, although 3 has appeared before 4, the presence of the 2 in between forces 4 to be an original element. So now, we can understand the significance of l and r. We will define an element x, to be usable if and only if it can be used to generate x+1. So all elements from l to r(both inclusive) represent the usable elements. If v[i]-1 does not belong to the set of usable elements i.e between l and r, then v[i] is an an original element. In that case, we have to increment the answer, and set l to v[i]. r will be set to v[i] regardless. This clearly solves our earlier problem( when 3 was not actually an usable element), and is also sufficient.
Solution for C2
Initialize variable ans=0 Let us make an observation. Consider each element v[i] for i=0,1,..n-1. Consider all subarrays v[l,l+1,..r], such that l<=i<=r. We want to count the number of subarrays for which v[i] has to be an original element in the subarray. Summing over all i will give us the desired answer.
Now we will try to reuse the original algorithm we had for C1. Notice that whether v[i] is an original element or not depends on only the elements before it. This means that contribution of v[i] as an original element will be the same for every subarray a[i,...m], where i<=m<=n.
Suppose we are in the if block of the algorithm, it means that v[i] is an original element of the subarray a[0,..i]. In that case, v[i] will contribute 1 to the ans for every subarray a[k,..i] for 0<=k<=i. Therefore we have i+1 contributions for every subarray a[i,...m] for i<=m<=n. So total contribution be be (i+1)*(n-i). We add this to the ans.
Otherwise, there exists an usable element for v[i], which is v[i]-1. We find the nearest occurrence of v[i]-1 to v[i]. Let it be j. We can easily find j if we story the last location of all elements using a map. Therefore, for every 1<=k<=j, v[i] is not an original element for v[k,..i]. So it will contribute 0 for all such subarrays. But for each j+1<=k<=i, v[i] does not have an usable element, so it will contribute 1 to the ans for each such subarray. So we have i-j contributions for every subarray a[i,..m]. So total contribution would be (i-j)*(n-i). We add this to the ans.
We return the final ans.
Proof of correctness is apparent from the explanation.
Hope this helps!
Me: just let me die. Problem B: solve me then.
HINT : you just have to check alternate pairs if they are equal then ans is definately wrong
I also see this soln from some users....
Hope it helps //////
a simpler approach to div1B / div2D
I thought so at the very beginning. Unfortunately, I didn't figure out that the maximum value of the answer is 2n — 1. TT
Another explanation for div1B/div2D follows:
For integer
n, there are two extreme patterns:1, 1, 2, 2, ..., n-1, n-1, n, nn1, 2, 3, 1, 4, 2, 5, 3, ..., n-1, n2n-1We can split the
ncounts into combinations of these two patterns. Let:adistinct numbersbdistinct numbersFor example:
1, 1, 2, 2, ..., a, ahas2atotal numbersa+1, a+2, a+3, a+1, a+4, a+2, ..., n-1, nhas2btotal numbersThen:
k = a +2b-1Note:
bmust be greater than0.Since
a + b = n, we can solve foraandb.CODE
Thank you for this very nice contest!
For problem A, my solution did not use the observation from the editorial. Call the amount of moves of the first kind a, the amount of the second kind b, and for the third kind c. Then, it is possible to go from (0,0) to (x,y) iff there exists a solution in which a, b, c are non-negative integers for the following:
a * (2,1) + b*(3,0) + c*(4,-1) = (x,y)
Solving this system proves the exercise left for the reader.
PS: does anyone know when is the next rollback? I can't shake off the felling that there is a lot of cheating in the recent DIV2s.
Bruh, i got to this system after my recursion approach segfaulted, but I just could not solve it, I only knew how to solve square systems. Noob looking for basic linalg skills
I suggest that you take a look at gaussian elimination: link
For this case, as the system is small, it is easy to do it by hand. Just isolate one variable at a time and substitute.
2a +3b + 4c = x, a — c = y
The second equation is simpler and we can isolate: a = c + y Then, in the first equation:
b = (x — 4c — 2a) / 3 = (x — 6c -2y) / 3 = -2c + (x-2y)/3
Notice that we need a, b, c to be non-negative integers. Hence:
c + y >= 0, c >= 0, 3 |(x — 2y) and -2c + (x — 2y) /3 >= 0
Then compare the constraints on the remaining variable c and check if it produces a valid interval.
in div2D/div1B, can someone explain why does a pair flips in at most 2 ops, like there can be a case where say first 1 was seen (ops=1), then next 1 is seen when 3, 1 happens(ops=2), now finally in the 3rd op, we flip the 2 1s,
You are correct — the editorial is not disagreeing with you.
Given your comment, maybe it is easier to see it this way: each number (from 1 to n) may appear at most 4 times. The worst case is exactly your example. There are n elements and each operation increases the appearances in 2. Hence: 2 * #ops <= 4 * n -> #ops <= 2*n
In order to prove that #ops == 2*n is not achievable, I proceeded by contradiction, considering the last element to appear for the first time.
for div2: Easy C1 but to hard B.
Can someone explain me the editorial for div 2 A. its written that all are ending on same spot (6,0). but how. like
(0,0)→(2,1) -> (4,2)→(6,3)
(0,0)→(4,-1) -> (8,-2)→(12,-3).
Or i misunderstood the question or the editorial.
The paths in the editorial are different. In simple terms, consider the effect of a move (2,1) and a move (4,-1). We go from (0,0) to (2,1) + (4,-1)= (6,0).
Hence, we can trade those 2 for 2 moves of the (3,0) type. Because of this, if there exists a solution, then there exists a solution with only 2 types of moves: (3,0) and (2,1) or (3,0) and (2,-1). Use (2,1) or (2,-1), depending on y signal, to solve the second coordinate. Then check if the remaining x coordinate is a non-negative multiple of 3.
My solution of Div2 A (that's essentially equivalent to the second solution in the editorial).
Proposition. Let $$$S_i$$$ be the set of coordinates where Steve can reach after $$$i$$$ moves. Then,
It's not too hard to find this, if you enumerate first 2 or 3 steps by hand. Proof is easy (by induction, starting from $$$S_0 = \left\{ (0, 0) \right\}$$$).
Then, it's very clear that $$$x + y$$$ must be a positive multiple of $$$3$$$ for $$$(x, y)$$$ to be a member of $$$S_i$$$, because $$$(2i + t) + (i - t) = 3i$$$. Then you have $$$i = (x + y) / 3$$$. The answer is YES if $$$2i \le x \le 4i$$$ (if $$$x$$$ is within this range, you have a valid $$$t$$$).
I still don't understand the editorial for Div2B.
What do you mean by "you can't use the same letter twice in a row because the first and last letters of T will be the same on the next iteration"?
If we assume T is even, we already can't use the same letter twice, no? What's the point of re-stating it with additional reason? I feel like I'm missing something here... It's like as if we had a choice of picking same letter twice.
Ok I understand we can only pick different letters from T per the condition on every other operation, but like that one sentence is really confusing me.
Edit: ok I'm gonna presumably say you meant "you can't use the same letter twice in a row because the first and last letters of T will be the same [different one] the next iteration."
Am I the only one who solved Div2/B with DP ?
I think the user Mitpro also uses DP for Div2/B, see his submission 364057440
Explanation about his DP: https://mirror.codeforces.com/blog/entry/151441?#comment-1349271
---
Beside that, I think I'm the only one who solved Div2/B using bitmask x) see my submission 364071388
Explanation about my approach: https://mirror.codeforces.com/blog/entry/151441?#comment-1349318
Not the only maybe, I used it too, in VP:) But yours is far more elegant.
Can anyone tell me for the Question C why code 1 got WA but code2 passed?
code 1: ~~~~~~ void Puzzle_Out() { int n; cin >> n; std::vector a(n); for(int &i : a) cin >> i;
multiset<int> ml; int ans = 0; for(int i =0; i < n;i++){ int val = a[i] - 1; if(ml.find(val) == ml.end()){ ans++; ml.clear(); } ml.insert(a[i]); } cout << ans; cout << nl;} ~~~~~~
code 2: ~~~~~~~~~ void Puzzle_Out() { int n; cin >> n; std::vector a(n); for(int &i : a) cin >> i; vector s;
} ~~~~~~~~~~
Consider a case like:
1 2 3 4 2 4.Your code will say 1, but the correct answer is 2, because there is no way to generate the final 4 from the preceding 3 if you include the intervening 2.
I did the B in a brute-force manner. I basically went through each letter and checked if it's possible to have and used recursion when encountered '?', and we can put both a and b...
Here's my code...
So sad that there was no graph/tree problem in div 2=((((( Stuck on A and B last night, somehow still managed to solve 5 problems(solve C1 before B and D before C2 lol), and still got negative delta. Can someone give me some advice on how to become CM?
I'm sure there are many uncaught cheaters, that's why it's hard to increase the rating.
I'm sure you will come candidate master sooner or later :3 wanna compete who will reach that rank first? ;)
If it helps I think Div 2 — C1 can be solved with a graph-like interpretation. You can take a look at my (practice) submission
Did you cheat? I see failing at pretest 1 during contest, and your first fail on Div2 D was basically exactly what claude returned.
for a, x = 2a+3b+4c, y = a-c, x+y = 3a+3b+3c, so x+y≡0(mod3),
x>=2a,a<=x/2,y<=x/2,x>=4c,c<=x/4,-c>=-x/4,so y>=-x/4
so cant A2 use prefix solution?
any alternate ways of thinking about the ')' dp in Div2E/Div1C
I was thinking the opposite, instead of counting how many regular bracket, I count how many sub-sequence that made the bracket irregular, and to make the bracket irregular you need to select sub-sequence that "starting with "vulnerable
(" *, and end the sub-sequence with)" and count number of such sub-sequence equal topow(2,index(start of sub-sequence with symbol '(')-index(end of sub-sequence with symbol ')')).. complexity isO(n^2)if counting start and end of sub-sequence naively, we can optimize it toO(n)by storing start of sub-sequence with symbol(using DP, note that iterating to the right is multiplying this DP value by 2, and if the current index is valid start sub-sequence with "vulnerable(" * you can add DP value by 1, and the formula (when the valid end sub-sequence)is found) become addcurrent DP valuetoans.Note:
'(': is the start bracket that if flipped will make the entire bracket sequence irregular. I assume you already know how to identify this ;)After iterating
ntimes,answill become number of sub-sequence that makes the bracket irregular. The actual answer to print ispow(2,n)-ans.Maybe my approach is too complicated, but I think this should be counted as "alternate ways" x)
for b , odd: aab or aba, both x[2] != x[3],expand on it, odd: x[2i] != x[2i+1]
even: ab or ba , expand on it, x[2i-1] != x[2i]
For (Div2C1==Div1A1) conclusion that element $$$a_i$$$ can be merged if $$$x \le a_i \le y+1$$$ isn't correct. $$$a_i$$$ must be bigger than $$$x$$$. In example: $$$1,2,5,6,5$$$ this solution would give $$$2$$$, but the answer is $$$3$$$ because of the last element.
oh sheesh I meant $$$x+1 \le a_i \le y+1$$$, I guess I need some sleep
WHY IS MY MAP CODE NOT WORKING??
For (Div2C1==Div1A1) I wrote a stress test using Solution 2 to verify Solution 1, but I haven’t been able to find any failing test cases. Could someone help me check what’s wrong with my greedy approach? :)
364147493
Try this input to your program:
Expected answer:
2Your answer:
1You can't make sequence
[1, 2, 3, 4, 2, 4]with just[1]!I see, thank you so much! I need to take a break as well. Actually, the correct code should be segs.back().second = ai;, but I mistakenly wrote segs.back().second = max(y, ai); instead. :)
Give me some hint for Div2A i am unable to think and intute about A , how do i came up from (x,y) ----> (0,0) ??
You can check my notes from the previous page, which use mathematical knowledge of setting unknowns and inequality scaling. I hope this will be helpful to you.
It's a clever observation that you don't need any other moves. If y is negative do the sufficient y moves (third move) and then the 2nd move only if the remaining x is a multiple of 3, or else terminate. Similarly if y is positive do the first move y amount of times and then 2nd move as long as the remaining x is a non negative multiple of 3. Because if you really check the id you do one positive y move and one negative y move. It's equivalent to do 2 constant y move. As x+2,y+1 and x+4,y-1. If you sum it it's x+6,y which is two times of x+3,y. I hope it helps
loved the contest , thanks alot chromate chromate00
My solution for div1E :364151963
For conflict/overlap over all shifts: for small d: brute shifts, for sparse forced residues: count shifts via (r-s mod d),for dense: bitset rotation + popcount
Can anyone please explain to me the dp solution for C2? My approach was to store sum of f(i...j), i <= j <= n in dp[i] my submission — https://mirror.codeforces.com/contest/2202/submission/364103957
I completely neglected the fact that when I increase l then there will be some changes in the elements needed in the shortest sequence. Is there some way to account for that in the dp?
I’m a Div.2 user, but I became interested in the last problem of Div.1, so during the contest I focused only on Div.1G and solved it. Therefore, I’d like to present my approach, which I believe is more intuitive than the editorial’s method. Also, while the official solution has efficiency $$$0.4 - o(1)$$$, my method achieves efficiency $$$0.444\cdots - o(1)$$$, so it is more efficient.
I did not use any heuristic, and instead simplified the problem with a small trick. First, let’s think of the coordinate plane after rotating it by $$$45^\circ$$$. In this case, it is scaled by a factor of $$$\sqrt{2}$$$, and a move of the form $$$(2,3)$$$ becomes a move of the form $$$(1,5)$$$. Since this form contains $$$1$$$, it becomes much more intuitive to visualize and reason about things such as parity.
This makes it easy to come up with the following pattern, and by simply stitching such patterns together, you can fill the space quite easily. The fact that movement is possible using only $$$(1,5)$$$ is nice, because if you arrange the pattern so that it leaves a 2-cell gap in the middle, there is no risk of edges going off in strange directions.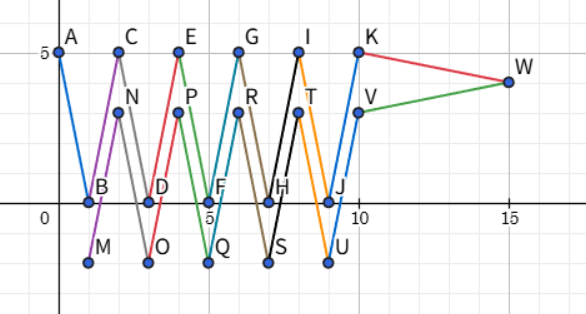
By extending this, you can connect the patterns further, and with a careful implementation, you can fill one quarter of a diamond-shaped region. Reflecting it gives one half, and reflecting it again fills the entire shape. Then, simply rotate it back by $$$45^\circ$$$.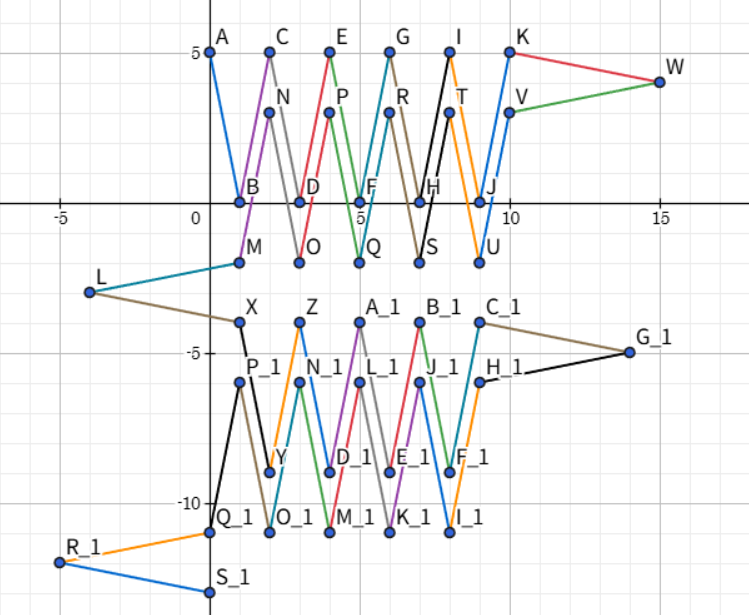
Using this method, I used about $$$410,000+$$$ vertices, and my implementation is here: 364106211
I also discovered a diagonal pattern that approaces 4/9 − o(1). It is a bit less wasteful in space and achieves 432978 tiles. It is also very likely that it can be improved further to reach something closer to 4/9 of the tiles.
This image shows the general pattern for my method. Only for the top right corner, you may have to manually finish it.
Here is my implementation: 367931807
i think the first solution of div2C1/ div1A1 has some problems or maybe i just misunderstood it, going by the explantion of C1,the answer of example 1 2 4 5 3 7 8 should be 3 , not 4. but the answer is 4
oh, its my fault
For Div2 C2, it is essentially an optimization of brute-force traversal of all substrings and summing up the results, using the monotonic stack data structure. As for how to optimize, it depends on what we are actually trying to calculate — we aim to find the number of all subsegments covering the i-th position. For example:
1 2 3 6 5 6
1 2 3 4 5 6
When processing 3 (the 3rd element, 0-based), how to calculate its contribution? We just need to compute the number of all subsegments covering the i-th position within the range from the valid left interval to the valid right interval. This can be easily derived using the inclusion-exclusion principle:save = total number of subsegments — number of left subsegments — number of right subsegmentsHere, left part: [1,2], right part: [6,5,6]This is equivalent to save = (3-2)(6-3), which generalizes to (i-pre)(n-i). Here, pre stores the end of the previous mergeable subsegment. As for why pre is set to -1 when the stack (st) is empty — this is a virtual node based on 0-based indexing, which is straightforward. I have written this kind of monotonic stack optimization before, but unfortunately, I lacked this intuition during the contest. Below is my implementation:
364164769
A similar problem is Codeforces 1072 Div3 Problem E, my implementation:
364169560
for the Div2B prob , i keep 2 pointers, le and re. i have a move variable which keeps the count of latest consecutive '?'. if i encounter 'a' i see if le or le+ move or re or re — move can help to put 'a' into og array. then update the pointers accoridngly. this approach is failing idk y can someone help https://mirror.codeforces.com/contest/2202/submission/364169367
thank u :)
I highly discourage you from implementing this with simulation, bro. Because I used simulation myself during the contest — the O(n) solution you came up with will miss some edge cases. That’s why you need to keep track of the previous step. I only managed to reduce the time complexity by using state compression. Below is my implementation:364081839 Hope this helps you!
thank you for the advice, could u tell the edge case or maybe the flaw in the logic, i felt this was quite robust, wud help immensely if u can point out a void
I wrote a checker with the correct reference code and identified a faulty test case:
The expected output is YES, but the tested program outputs NO — you can verify this yourself.
thanks, btw another testcase is ??b?? the issue is i leave spaces for the buffer X and check if le + total buffer or re — totalbuffer satisfy it, if not , i say its a no. this was the extra rigidity. u just need to check for all positions, of buffer from le, le+1..to le+X (actually if X is >=2 i should check for either 1 or 2 it has to satisfy as least once.) that did get accepted after contest. but man i wasnt to think more simply
Newbie here. Trying to solve 2202A — Parkour Design and figured out this is plain old maths.
The possible steps to reach (x,y) are some usages of (2,1),(3,0) and (4,-1).
Let's assume we use a,b,c times of the steps respectiely. I can write this as:
Comparing each coordinate individually, we get:
If you add equation 1 and 2, you can prove that x + y is a multiple of 3. (First deduction)
Now, using equation 3, I can get
We also know from eq 2, that y + c = a and a >= 0
So, there are two constraints on c:
Leaving this deduction for your practice. Figure it out from here onwards
Div2B Was muchh harder than Div2C
The exam setter is taking revenge on society
Don't cry, baby. You'll do better next time.
caseforses
F2 has more successful solutions right now in upsolving than F1...
It's surprisingly easy and clean when you look back from a nice solution, although the time limit for F2 is somewhat tight. Just consider a Young diagram given by the counts of black cells in each row, another diagram given by columns and check if they're the same but transposed. In other words store the difference of actual column-diagram and the one that would be expected by transposing the row-diagram, check if this difference is nothing. Since a query is adding 1 block to a "corner" in each, it just needs computing the size of a diagram's column (in each of the 2 diagrams from the difference) on which this block is added and updating 4 values (in a map in my implementation). One size is known directly, the other is found as the number of larger rows in a diagram = segment tree.
《The proof is left as a practice for the reader.》
My solution to Div2C1:
Let $$$nxt[i]$$$ be the next index that hasn't been removed. Inititally, $$$nxt[i]=i+1$$$. And while $$$nxt[i] \leq n$$$ and $$$a[i] = a[nxt[i]]$$$, remove the element at index $$$nxt[i]$$$ and update $$$nxt[i] = nxt[nxt[i]]$$$.
I tried to use something like a DSU, but I simplified it to this. I don't think this is a great way to solve the problem because it makes me struggle a lot with C2 later.
Div2A of this contest is harder than normal Div2 As
If you can observe the steps taken by y
then it is simple math problem
main point was to observer and make steps through y
I might not be the first one to see this, but this is blog 151515
I can't really understand the problem statement for C1. I really don't want to look at the editorial yet.
After 24 hours I finally got the problem statement! The implementation doesn't seem that difficult. I don't know why it was so hard for me to parse. I loved div2A+B though. I wish I hadn't missed the contest.
Not as easy as I thought, but still a really cool problem! 364117836
Dynamic programming approach to Div2 B: https://mirror.codeforces.com/contest/2202/submission/364212034
I really don't understand 2201D, how to find the $$$f(a)$$$.
What I understood so far:
Also I undestand how to find $$$k_\text{max}$$$ for each query, I need for each unique $$$x$$$ maintain the set $$$\text{set}[x] = (i \mid b[i] = x)$$$. The largest spread of such set will give me $$$k_\text{max}$$$. I also understand that maintaining the $$$\text{set}[\cdot]$$$ and the maximum spread can be done in $$$\log(n)$$$ as each time at most one set is updated.
What I don't understand, how do I recompute the set of intervals. Changing one value can change the $$$k_\text{max}$$$, so I would need to rebuild the set of intervals from beginning, potentially each operation changes $$$k_\max$$$. Could anyone elaborate please.
You don't rebuild the set at any moment. You simply maintain all of them at the same time, for every known candidate of $$$k_\max$$$. As there are only $$$\mathcal{O}(n)$$$ distinct values at any moment, there are only $$$\mathcal{O}(n)$$$ intervals over all candidates too.
Thank you! This does not look trivial though...
There might be $$$O(n)$$$ different values of $$$k_\max$$$ if I gradually modify the array from $$$[1, 1, 2, 2, ..., n/2, n/2]$$$ to $$$[1, 2, 3, ..., n/2, 1,2, 3, ..., n/2]$$$.
Moreover processing one $$$i\ x$$$ can affect many sets for $$$k_\max$$$, for instance if I change $$$[0, 1, 1, \dots, 1]$$$ into $$$[1, 1, 1, \dots, 1]$$$ it affects all $$$k_\max$$$
So how do I see the update procedure: for a query
i xI iterate over all segments sets for all $$$k_\max$$$, ifx == s[i + k_\max]orx == s[i - k_\max], I merge/split the segment in the corresponding set"I merge/split the segment in the corresponding set" is correct; for precise implementation examples refer to https://github.com/kth-competitive-programming/kactl/blob/main/content/various/IntervalContainer.h
Hi chromate00. In 1G, are there any examples of using "rules" to construct gadgets? I literally have no idea how to set up a "rule". And according to the editorial, I should write something like a brute force(obeying "rules") to generate a gadget, right?
Surely I believe there are multiple ways to do this, but in (integer) linear programming, a good start to experimenting with this would be "restricting" the degrees to at most $$$2$$$. This is because if all degrees are $$$2$$$, then the graph is a union of cycles; if all degrees are $$$1$$$ or $$$2$$$ then the graph is a union of paths and cycles. Forcing a vertex degree to be $$$2$$$ makes it an "internal" vertex, while forcing it to be $$$1$$$ makes it a leaf vertex.
Then you can have constraints that deal with connectivity — there are several rules historically designed for TSP, that force a TSP integer linear program to not have smaller subtours. Searching up keywords "Subtour elimination constraint", "Miller-Tucker-Zemlin" would be a good start to learning these. Or maybe you can ditch that altogether and add some extra variables to try modeling "maximize shortest distance between vertex $$$v$$$ and vertex $$$w$$$" instead of the total number of edges used.
Other than that, everything lies in your creativity. It's certainly hard, but I think it's an equally rewarding experience. Good luck, and have fun!
how to delete this comment of mine?
I have a question: why does the greedy approach in solution C fail at the third step?
Although I didn't participate in the contest, I took some time afterward to tackle the problems. I thought about Problem B for a long time, and I finally cracked it. Here's my solution:
Consider the example where T="ababa". In this case, possible strings S include: "ababa" "aabab" "aabba" "abaab"
These can be segmented as follows: "a|ba|ba" "a|ab|ab" "a|ab|ba" "a|ba|ab" From this pattern, a clear regularity emerges.
am i the only one who felt div2 C2 (the hard version) easier than the easy version? it is just straightforward 1D DP 364802836
Why is my map code not working for C1?
Are Div2 C2s (Div1 A2s) like D? If I'm trying to practice C, should I just avoid C2s for now? (If they somehow appear again). I'm basing this info off of CFTracker: https://cftracker.netlify.app/contests`
Does anyone have an alternate solution to Div2E/Div1C?
I have initially approached the problem by counting the subsequences that when shifted causes the sequence S to become irregular but it's difficult to come up with ideas to optimize this approach.
If anyone can explain the author's solution better and go in depth, I'd be grateful.
I am a bit confused about the editorial for F1. It states the following:
But I believe this is incorrect. As an example, it is possible to have a large "L" shape of 1's, which would result in both O(q) active rows and columns. Or have I misunderstood something?
I am curious about the other intended solutions (that use the other two facts listed). The hard version solution makes a lot of sense though, and is a really cool idea!
Oh, yeah, it's correct if "distinct" is in the sentence, but I missed that out...... I'll try to explain another approach and rewrite the editorial for F1.
can someone explain me why the ans is 3 for c1(lost civilization) 4th case: 9 8 9 2 3 4 4 5 3
A convenient editor for the G task.
366609493
Just copy the code and paste it into the file *.html and open it in any browser.
in E I found this approach:
Try to find the answer for the subseqs ending with '(' first, it's easier.
It is sum of 2^(i — 1) for each i that s[i] = '(', because a subseq ending with '(' is always valid.
Use dp to find the answer for the subseqs ending with ')'.
Let dp[i][0] show how many subseqs are there in range [1, i] ending with '(', and same of it with ')' for dp[i][1].
If s[i] == '(', then dp[i][0] = dp[i — 1][0] * 2 + dp[i — 1][1] and similar for s[i] == ')'.
If there already is a subseq ending with '(', you can just leave it how it is or just add s[i], and if there already is a subseq ending with ')', you can just add s[i], similar for ')'.
Try to observe when we cant use a subseq ending with ')'.
It's when the prefix balance of [1, i] range is <= 1.
Try to find the difference of delta for each index in the subseq, you will see that it is smth like that:
(s[i_k] - s[i_1]) + (s[i_1] - s[i_2]) ...You would see that the change of prefix balance of any index in range[i_x, i_(x+1) - 1]would bes[i_k] - s[i_m]where s[i_k] is ')' because we are calculating subseqs that end with ')', so it will be — 1 — (s[i] == '(' ? 1 : -1). If s[i] == '(', no problem there, prefix bal wont change, but if s[i] == ')' we need prefix balance to be >= 2 as this shift would decrease the balance by 2.You can just do dp[i][0] = 0 when prefix balance of [1, i] range is <= 1
Actually, 2202G2 Monotone Monochrome Matrices (Hard Version) can be solved in O(n+q) with this code
Can some explain more clearly this line in Div1C?
"Let's maintain a DP defined as DPi=(number of non-trivial subsequences in prefix containing index i), where non-trivial means that the subsequence ends with a ')'. Then, DPj affects DPi (j<i) if either: + Sj was ')'; + or the prefix sums between j and i never dropped below 2."
why we got 2 conditions above and how to implement it?
2201C — Rigged Bracket Sequence
Can someone help in understanding the solution? Didn't get proper understanding of the solution.
The TL for div1-F2 was too low for my $$$O((n + q) \log{n})$$$ implementation, and I had to resort to some stupid optimizations to get my code to AC.
By the way, is there a better hash for a sparse binary grid $$$g$$$ than $$$(\sum_{g(i, j) = 1} a^i \cdot b^j) \bmod M$$$ (where $$$a$$$, $$$b$$$, and $$$M$$$ are suitable primes)?
DIV 1 A1. Can someone explain what is wrong with my code?