


Привет, Codeforces!
Рад представить вам PyPy на Codeforces. Прошу любить и жаловать.
Хорошие новости состоят в том, что JIT в самом деле работает — PyPy зачастую оказывается существенно быстрее классического Python. Похоже, что обычно PyPy быстрее в 2-60 раз. Например, PyPy 2 показывает 60 кратный прирост производительности на binary-heap-benchmark, а PyPy 3 — 85-ти кратный.
Кроме того у PyPy хорошая совместимость с Python, то есть в большинстве случаев вы можете просто отправить программу на PyPy.
Не уходите далеко — скоро вас ждут еще хорошие новости :)







ЧЯДНТ? :(
код -- абсолютно одинаковый :(
UPD: благодаря комментарию hellman_, я, поменяв input() на sys.stdin.readline() и print() на sys.stdout.write(), добился едва ли не такой же скорости, как и у питона
теперь обе задачи по 108-109 мс, что уже "погрешность"
А что тут удивительного?
Выбери более насосную задачу — там поглядим... На миллисекундах статическая погрешность большая, например на разогрев jit должно время уйти... %)
так-то оно так, просто я python использую как раз для таких задач див2 А-С из-за скорости тайпинга
хотелось его использовать без какой-либо боязни получить ТЛ на таких задачах, а получается, что выигрыш получается "наоборот" на сложных и долгих задачах
а так, я не мастер питона и знаю его как пару клевых фич/немного синтаксического сахара, чтобы писать на нем более сложные задачи. Наверняка кто-нибудь напишет что-то существенное и там будет значительный прирост в скорости
ну да, я его для того же юзал помнится — по сравнению с толстой джавой это выглядело оч экономно :)
которые вообще м.б. уже можно и не на питоне писать :)
Я всецело согласен — мне вообще сомнительно что от PyPy будет много проку для спортивных задач с ограничением в 1-2 секунды. В общем кажется в этот раз команда CF проделала хорошую, но вероятно, невостребованную работу... :(
Или даже так
pypy -- это же JIT (динамический компилятор), поэтому так и должно быть. Опережать он должен на более длительных временах выполнения.
Pypy иногда работает медленней сpython, мы наблюдали случаи, когда pypy был в два раза медленнее, чем cpython. Но это редкие случаи, как правило, все-таки pypy быстрее.
По-видимому, трудно предсказать, в какому случае будет быстрее pypy, а в каком — сpython. Для этого нужно как минимум очень хорошо понимать, как устроен каждый из них.
Три сабмита, второй и третий с ручными оптимизациями.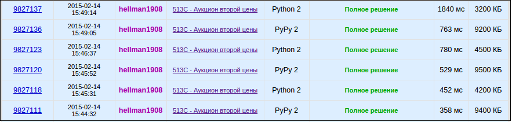
По поводу pypy3 — разработка ведется не так давно, у разрабов основной задачей была совместимость с py3 и я думаю они пока не сильно работали над производительностью.
А вот здесь >2с (не проходит) vs 0.404с:
Ещё пример, алгоритм ~2.5kk операций:
PS. Почему то в попытках в моем профиле неверная ссылка на задачу.
Хм у pypy почему то raw_input() / print медленные. Нужно sys.stdin/stdout юзать..
потому что в PyPy эти функции — просто обертки над sys.stdin/stdout с кучей рефлекшна и обработки исключений. В обычном CPython такой проблемы нет, потому что они написаны на C.
добавьте JIT для C++ :-) в MSVC он уже есть
Что?
хапчо. /clr:pure http://mirror.codeforces.com/blog/entry/14083
Это имхо не для "вообще C++" это для CLR от .NET — не важно на каком языке ты под неё пишешь.
В чём смысл (для спортивных задач) писать на C++ под .NET, чтобы получилось нарочно медленнее а потом кое-как оптимизировалось JIT-ом — я не представляю.
Какая хрен разница, достаточно большое подмножество (если не всё) Си++ там работает, а через что оно уже работает, уже отдельная тема. Ты хотя бы прочитал ссылку? Я привёл пример, в котором JIT быстрее едва ли не в полтора раза. И ты, похоже, не понимаешь причины того, почему C#/Java медленее С++. Дело не столько в JIT, а другой семантике языка (там нет UB и вс ё выполняется строго слева направо) и неотключаемых проверках индексов при обращении к массиву (а если это массив ссылок, то требуется еще проверка типа объекта)
И вовсе он не быстрее. Мне лень перезагружаться в Windows на своей машине, поэтому я прогнал (несколько раз! один раз ничего не говорит) на соседней XP с VS2010, и нативная версия работает за 7000 тиков, а CLI — за 10000 тиков. И совершенно нет причин, по которым JIT был бы быстрее на таком коде.
Вообще я согласен, но хочу заметить, что JIT на это наплевать и он всех оптимизирует одинаково, а проверки индексов, бывает, наоборот, помогают сделать циклы быстрее (когда они выносятся за цикл, а внутри производится оптимизация с учётом того, что индекс точно находится внутри границ — в частности, что индекс неотрицателен и не переполняется при прибавлении шага цикла).
Совсем даже не требуется. Массивы разных типов — это разные типы; и в CLI, и в JVM. И для generic collections в CLI тоже не требуется; а вот в Джаве — да, вот там требуется. Не говоря уже о том, что не важно, C# это или C++/CLI, а массивы ссылок работают абсолютно одинаково.
[Edit для читателя: Нет, всё-таки требуется при записи в массив, см. ниже.]
Ненуок, я нашёл то сравнение C# с C++, которое упомянуто в твоём блоге без ссылки: http://stackoverflow.com/questions/2285864/why-is-net-faster-than-c-in-this-case
(Вроде датировано 2010 г. и версия MSVC даже меньше, чем я использовал, так что не знаю, почему у меня этого не произошло. Или, может быть, произошло, но CLI-версия всё равно медленнее?)
Ну ок. Да. JIT может так сделать. С такой же лёгкостью AOT может так сделать! MSVC этого не делает по умолчанию. Зря. Но это же не повод кричать, что JIT лучше в общем случае. Не говоря уже о том, что помогает это не шибко-то часто. Вон, как я говорю, проверка индексов тоже бывает, что ускоряет, — это же не повод кричать, что с проверкой индексов всё получается быстрее, чем без неё.
Если писать на C++/CLI pure и C#/unsafe то результаты будут похожие, но, простите, когда речь заходит о скорости нормального с# кода, а не unsafe.
Требуется. Допустим есть класс "фрукт" и класс "яблоко" и есть метод, принимающий массив фруктов и что-то с ним делающий. Так вот, Java позволяет передать в этот метод массив яблок (потому что каждое яблоко является фруктом) -- но там поэтому стоят рантайм проверки, чтобы никто в массив, аллоцированный как массив яблок, и имеющий формальный тип массив фруктов, не положил грушу. В общем, иди почитай про трансляторы, а не неси чушь с апломбом.
И что? Разницы никакой. Unsafe только просит компилятор не ругаться на использование указателей. Генерация кода, который и так компилируется, от этого не меняется. Ни промежуточного, ни машинного.
Touché, про это я забыл. Но даже они только при записи в массив, а JIT’у ничто не мешает их соптимизировать при возможности.
И не надо грубить.
совершенно правильное и совершенно неуместное замечание
только что у вас JIT был медленее, а тут "не мешает". Ну может соптимизировать. Иногда. В общем случае нет.
А потом ты скажешь что твой пример не работает на CF потому что здесь компиляторы юзают Mono...
на CF есть как MS так и Mono.
При всём вышесказанном я лично не имею ничего против добавления нового пункта в список компиляторов, MSVC /clr:pure; а лучше даже просто /clr, а не /clr:pure. Помешать это никому не должно, ну так и фиг с ним. У C++/CLI как у языка программирования даже есть свои плюсы, в первую очередь доступ одновременно к библиотекам C++ и .NET. Но подаваться он должен именно как C++/CLI, а не как C++ JIT.
Команде разработчиков CF наверняка любопытно для начала определить сколько человек (кроме beatoriche) собираются этим пунктом воспользоваться. Это ж все же не две строчки в конфиг вписать (хотя учитывая наличие C# и F# м.б. не оч сложно).
Да, совершенно верно. Я забыл это сказать.
Так вот как раз именно -- две строчки в конфиг вписать. C# и F# тут не при чём вообще, в новом MSVC это есть и так без дополнительных пакетов. Сложность только тут может быть, как .NET работает -- через обычный сандбокс или особый. А вот для всяких хаскелей, которыми один фиг никто не пользуется, надо сами трансляторы устанавливать.
суки умрите я вас ненавижу
Сходил потестить новую фичу в "Запуск на сервере", и с ужасом (случайно) обнаружил, что тут в питоне установлена numpy. Что за страшная несправедливость? Эта библиотека не входит в стандартную поставку Python'а, и, между прочим, может дать огромное приемущество пишушим на питоне в некоторых задачах (например, если нужно умножать большие матрицы).
Например, следующий код:
работает на питоне меньше секунды, а straight-forward (без built-in магии и ассемблерных вставок) перемножение таких матриц на C++ не укладывается в 10 секунд.
Я считаю, для восстановления мирового баланса надо добавить аналогичные библиотеки для C++ и Java (cblas/jblas, или хотя бы numpy4j).
Видимо, numpy входит в стандартный дистрибутив PyPy. Я подумаю как быть, но маловероятно, что будут установлены cblas/jblas/numpy4. Скорее либо удалю numpy из PyPy, либо оставлю как есть, следуя принципу установки дистрибутива по-умолчанию. Ведь не режем же мы Policy Based Data Structures (ext/pb_ds/assoc_container.hpp) из g++, хотя это тоже явный specific от GCC, лежащий за пределами стандарта С++.
А можно тогда добавить "-march=native -mavx -mavx2" для GCC? Чтобы можно было получить сопоставимую производительность без адского ассемблера (кстати, а зачем -fno-asm для C в параметрах? только чтобы участникам пришлось писать __asm__ вместо asm?).
Приведи пример кода, где -mavx -mavx2 там сильно помогут. Чтобы и потестить на нем и лучше понять.
Ок, вот код (на codeforces не компилируется из-за выключенного avx). Я максимально соптимизил "наивную" версию, чтобы не было вопросов про "сильную" помощь (это ускорило совсем наивную версию раза в 3, но до numpy всё равно далеко).
Моя реализация с avx явно не очень оптимальная, она всё ещё немного проигрывает numpy; однако она выигрывает в 2 раза у заоптимиженной "наивной" реализации. Думаю, если использовать _mm256_dp_ps() вместо того что у меня — должно догнать numpy.
(код в правке)
А что,
-march=nativeне включает AVX?А вообще у меня где-то был список, чего бы надо поправить во флагах и замере времени на Кодфорсах… Выкопать бы его. Но это ж надо вспоминать, куда я его сунул!
numpy в python 2.7 тоже работает.
Да вроде не входит… Ни в PyPy, ни в CPython. Под PyPy стандартный numpy даже и не идёт-то, надо их собственный форк использовать. Вот я сейчас зашёл на сайт проверить, не вкладывают ли они его в виндовые бинарники — там отдельный раздел Installing NumPy (optional). Видать, всё-таки не вкладывают.
Зато NumPy входит во многие сторонние дистрибутивы Питона «всё в одном»: Canopy, Anaconda… Может, на Кодфорсах установлен именно один из таких дистрибутивов, а не официальный?
(Это я не агитирую против NumPy. Это мне просто интересно, как он вообще здесь оказался.)
А какая, собственно, разница? Никто же не запрещает пользоваться ей, все участники в равных условиях. Таким образом можно запретить BigInteger в Java, потому что в плюсах его нет, или например, std::set в C++, хотя в паскале его тоже нет.
BigInteger в Java и set в плюсах — часть стандартной библиотеки, в отличие от numpy. В плюсах же нет, например, boost. Я и предложил разумный вариант — добавить аналоги numpy в других языках.
"Все в равных условиях" — сомнительный аргумент. Можно, например, взять какой-нибудь не очень популярный язык (скажем, haskell) и добавить туда все мыслимые и немыслимые библиотеки. Тогда половина задач будет решаться на этом языке в одну строчку вызовом какого-нибудь убойного алгоритма из библиотеки, и участникам, которым не пофиг на результат, придётся волей-неволей использовать эзотерический язык вместо родного и привычного. Не думаю, что так делать правильно.
есть ли где нибудь статистика, какие языки и компиляторы выбираюсь участники codeforces?