


→ Pay attention
Before contest
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
28:11:38
Register now »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
28:11:38
Register now »
*has extra registration
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Nov/22/2024 13:23:23 (j3).
Desktop version, switch to mobile version.
Supported by

"japanese" tag, what's the relation?
because "Kon'nichiwa" in japanese means hello :P
No one passed 250, rank 38 with only 50 points? What's happening in the world???
They are going to redo the system tests for 250 XD
God save topcoder
My arena kept hanging in the middle? I couldn't see the problem statements for 500 and 1000 for some time and had to restart the arena 3 times :/
This was my 2nd SRM and a very bad experience
How do you solve 500?
I wrote a dp[k][n] — shortest path from vertex n while Bob still have k tokens. You can calculate this dp layer by layer in order of increasing values of k. When you fixed a layer, it turns out to be almost shortest path algorithm (Dijkstra's, for example), with only difference — if k>0, then there are lower limitations on values of DP, determined by values of DP from next layer — because Bob can use token if Alice chooses edge which leads to something better than those values.
I think I got the solution in the end of coding time. let's count d[k][v] (k>0)! d[k][v] >= max(d[k-1][u] + c[v][u] : v->u) d[k][v] >= min(d[k][u] + c[v][u] : v->u) d[k][n-1]=0.
These were our conditions. Let's write dijkstra's algorithm for every k. But, when we update something we should update with max((q[k][u] = max(d[k-1][u] + c[v][u])), d[k][v] + c[v][u]). It seems to be ok.
Messing up the judge solution for Div1 easy is understandable, it could happen to anyone. What surprises me is that there was clearly no tester for the problems — or did the author and the tester mess up in exactly the same way?
They could write a stupid solution (take all permutations, or just check the answer is divided by any number from 1 to N). I think they just decided not to.
Well, i'm very interested what solution did they have. I think, error not in solution, but in statement. This solutions probably have been to another task.
They didn't use 5 and 11 for N = 11. What problem could it be?)
find LCM to all numbers from 1 to n except 5 and 11 ?
Well it looks almost impossible to me to write two or three wrong solution to this one. I think it was more like wrong last minute change in primary solution or something like that. Although it's definitely not the reason of bad statements.
Or there was indeed no testing.
Sorry, this was completely my fault. The testers did their job correctly.
Here's what happened. I made some very last minute changes to the checker, but I made a few mistakes
Again, I'm very sorry for this. I want to reiterate that this is 100% my fault. I know what mistakes I made, and I will actively try to avoid making the same mistakes in the future.
And what was the wrong solution you copied?
My prime sieve has a loop:
This should be 2 * i. It is a typing mistake that I forgot to change locally and also forgot about when I was updating the checker.
Coding (Computer Science as a whole) is evil, when you are 110% sure that your code is correct it can easily prove you wrong :D
Initially writer's solution and testers' solutions were agreed. However, when we found a bug in the validator, we also accidentally replaced the solution with an incorrect one.
Hey man, what's going on? Why points are not updated yet? it's been a couple days.
Div1 250's results show that clearly not even tourist is good enough to compute LCM of n numbers.
Lol, that is indeed LCM(1, ..., n), I didn't realize this. And as I looked at some codes in my room (almost) nobody realized this also :P.
But how did you solve it then?
Checked every prime separately, as vast majority of people (those who had sieves in their codes).
What is interesting is that I can't express why that is more natural for me than directly observing that it's LCM(1, ..., n), but it seems that it's also more natural for many people (of course none of those two ways is better than the other one)
How can you compute LCM(1..N) without using a sieve?
Hahaha, ok, you're right, I see :p
My first try in Python was: ~~~~~
from fractions import gcd
class ThePermutationGame(object):
def __init__(self): pass def findMin(self, N): res = 1 for i in xrange(2, N+1): res *= i / gcd(i, res) return res % 1000000007MAX = 100000
t = ThePermutationGame()
print t.findMin(MAX)
~~~~~
Took 5 sec on my computer for MAX = 100000 ... no way I would submit that (though maybe no TLE in Java) So I went for the prime sieve like everyone else.
I'm not entirely sure but I think: LCM(1,2,3,4,...) = LCM(1,LCM(2,3,4,...)) etc. which would make it possible to calculate the order of a permutation in the following manner:
Just a thought. Haven't tried it on the Div1 problem.
That would work but you would need big integers because N ≤ 100000, which would be hard to fit in the time limit.
OK, I'm late
That moment when you think your self misunderstood div1-250 because of test n=11 then that announcement comes(the test n=11 is incorrect)
That moment when you see the announcement (if your point at least 180 then it will be changed to 248)
That moment when you see that your div1-250 has failed the system tests then you notice that every one has failed it too.
A contest full of surprises.
You have to be really sure that your solution is correct, in order to submit it for 240+ out of 250 points, while it fails 3 sample cases :) Those guys are my heroes today :)
Probably, they haven't even checked the solutions on sample cases.
Some guys don't testing easy)
I opened hard first, so no surprise!
I opened medium first)
Something very weird happened to Errichto. He submitted it as a first person getting 242 pts for that. I asked him why did he do so even though his solution didn't match samples. He said that he used "Batch test" option and it told him that everything is OK. (Inb4 — yes, he submitted it before announcement)
I hope he was not looking at section "Success: true" which I was looking the first time I used the batch test.
Hah, in fact, he did ( ͡° ͜ʖ ͡°) ( ͡° ͜ʖ ͡°) ( ͡° ͜ʖ ͡°)
There you go. I have been expecting this reply.
Weeeell... I was indeed looking at "Success" section.
I turned out well on 250 but later I submitted 500 without passing samples.
My 500 program always returns 0 and I didn't notice. It's a bit funny. (I had to change dp[0]=0 to dp[n-1]=0)
Finally, I discovered how to gain advantage by solving 500 first. On a serious note, by the time I opened 250, all the samples were fixed and all it took me to solve was factorizing 27720.
Afair, you didn't solve 500 :D
To make it worse, I figured out the bug was in this line
The value unexpectedly goes beyond infinity in some cases and this fixes it:
What is proof for div1 easy/div2 med? I got the hint through example that we have to find LCM upto given number.
assume that you have a permutation and you want to see how many steps does it take to be back to 1 say Y steps then note that after another Y steps you will back again to 1 so any multiple of Y is OK, it's easy to see that for every i from 1 to N there is at least one permutation that make the value of Y equal to i , in other words Y could be any value from 1 to N so you should find a value that is multiple of all numbers from 1 to N , which is LCM(1,2,3 .. , N)
After reading your solution, I re-read the statement. I found out that I made mistake in reading the statement. I wrongly assume that he will apply <=x step instead of exactly x. Thanks anyway.
Was the problem statement of 500ptr clear for everyone? I was confused, what the primary goal of Alice is: either to reach N-1 or to minimise traveled distance. On one hand we have "She wishes to travel to node N-1.". On other hand minimising travel distance occurs in the statement at least twice: "Alice wishes to minimize her travel time" and "Alice will always choose an option to minimize the total cost". Thus for me it was totally unclear, what the answer for the following graph is. Two vertices: 0 and 1 and two edges {from 0 to 0 cost 0}, {from 0 to 1 cost 1}. Won't Alice just loop along the first edge and get total travel distance 0 * 10^9 (she traverses that edge 1,000,000,000 times without reaching the node 1)? Now the correct understanding is clear, but anyway has somebody faced the same difficulties?
When did people get their notifications that 250 is incorrect? It seems to me that I got mine after 1 person in my room already submitted it for 190 points. I was very puzzled that someone decided to submit a problem without sample tests passing (submitting on last seconds when samples don't pass doesn't count :) ), though as I saw later, there were lots of people who submitted it with >190 points. Did I somehow manage to miss the notification?
No, but it seems that some people submitted it without checking the samples or at least they checked the first two samples or maybe they were sure that the test n=11 is wrong and it will be fixed
Ok, good to know. Thanks!
I think that there is another possibility. If someone was just a little late and opened Easy 1~3 minutes after the round started, then 190+ points seems natural. (According to the submission times for people who scored 190+, this should be the case for some people.)
Announcement was made when it was possible to get sth like ~200 pts if you opened 250 in the beginning. At that time large amount of people already had working solution, but was puzzled why it doesn't match samples and when announcement was made submitted it immediately. I was confused that announcement regarded only third sample and not a fourth and fifth one, so I submitted it sth like 1 minute after announcement and got ~196 pts.
If you're interested in how to solve the hard problem, first try to count the total number of valid paths. There exists a really nice and simple closed form solution that involves the number of points and the number of points on the convex hull (I'll post this formula later to let people think about it for a bit). However, it is too simple and I was afraid of people guessing, which is why it is in its current form.
What was the intended complexity? I think I know how to solve this in O(n4), but n ≤ 100 is a contraint such that it might work or might not. And problem is very nice in my opinion, but at least on first thought, code will be pretty long and tedious.
Intended complexity is O(n^4), but I believe the constant factor should be really low. That is, you can generate all paths in such a way that they are all unique, so you don't need to do any postprocessing to remove duplicates. In addition, this method requires only generating a prefix of each path, so it reduces runtime a bit further. I believe my solution runs in about .3-.4 seconds in the worst case. rng_58 had mentioned that I should lower constraints, but we decided to increase TL instead. This makes it slightly easier to time out exponential solutions. In hindsight, I probably should have lowered constraints, since it seems rather intimidating to be so close to theoretical time limit (and the code is nontrivial to implement, so it may seem not worth it to implement it and then see it time out).
I will admit coding this modified version may seem a little bit tedious. However, this seemed like one of the easiest ways to check if people correctly derived the formula for total number of paths.
Lastly, if you want to double check your formula, the total number of paths is h*(N-h+1) + (N-h)*(N-h-1) where N is total number of points and h is number of points on convex hull. This is true for any point set where no three points are collinear. You can also simplify this a bit to N*(N-1)-h*(N-2) or (N-1)*(N-h)+h, but I'm not sure how to interpret these two simplifications. I'll post a short explanation for why this works a bit later, and this should also describe the idea of the intended solution.
Yes, that's exactly the formula I got :). Moreover at least in my idea I need to enumerate all those paths, so formula alone doesn't help much :D.
Here is its sketch:
Every path contains a path around a whole convex hull but one side and two interior "spirals":
Let s be the number of points not in convex hull. Then for any vertex I generate s+1 partitions of those points (with regard to some angle ordering) and I generate all intersections of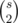 lines with convex hull sides.
lines with convex hull sides.
One can see that there are exactly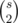 ways to partition those s points into nonempty subsets. For each such subset we are in fact interested in only one starting point (which is pretty hard to describe without pictures) and want to repeteadly go to leftmost point until we ran out of points forming some kind of a spiral or a snail :P (we do it naively in O(n^2)). And what we are interested in is the ending point which will be in fact starting point of some paths. Every generated event (s+1 partitions in each vertex and 2 intersections of "interior" lines with hull) corresponds to one path and we determine which snail we are interested in and increase a counter for its ending point.
ways to partition those s points into nonempty subsets. For each such subset we are in fact interested in only one starting point (which is pretty hard to describe without pictures) and want to repeteadly go to leftmost point until we ran out of points forming some kind of a spiral or a snail :P (we do it naively in O(n^2)). And what we are interested in is the ending point which will be in fact starting point of some paths. Every generated event (s+1 partitions in each vertex and 2 intersections of "interior" lines with hull) corresponds to one path and we determine which snail we are interested in and increase a counter for its ending point.
In fact that preprocessing of snails is a very stupid idea. Moreover I'm not sure about that mysterious special point for each snail. There are O(n2) possible paths and for all of them we know thrown side of convex hull and partition of interior points into two sets, so we can start from end of that thrown side and naively generate snail, which results in O(n2·n2) = O(n4)
Yes, that's pretty much my intended solution. It doesn't seem too hard once you have the general idea (of course, getting the general idea is the hard part). If you're familiar with the gift wrapping algorithm for convex hulls, this is just a straightforward extension of that.
Why are the s+1 angle partitions and the (s choose 2) line partitions the only partitions possible?
First, I apologize if this is informal. It's hard to prove this without using pictures, but I'll try my best. Also, I'll start from the very beginning, in case some people missed some stuff (so I apologize if I'm telling things you already know).
The first observation is that the path will be a growing spiral, then shrinking spiral. You can also additionally note that you can separate these spirals by a straight line. (sketch of proof, it not, we'll have to intersect our own path or make a right turn).
Conversely, you can also notice that drawing a straight line will uniquely determine the two spirals. (the proof for this is a bit harder, but it boils down to showing that if we are at some point on the convex hull, there is only one choice we can make at each step of our path). There are many such lines, but we're only interested in the number of different partitions of points. There are as many partitions as the number of ordered pairs of points, so there are N*(N-1) such lines we can draw (the number of ordered pairs of points), so the total number of partitions is at most N*(N-1).
At this point, you can code this solution (i.e. choose 2 points, partition the rest of the points, and generate all paths), but you'll notice that some paths are duplicated. Removing duplicated paths will solve this problem in time.
I think Swistakk's explanation is along the lines of my reasoning for counting those unique paths, but if you'd like I'll provide an explanation below to describe how to count paths uniquely (this is much harder to show, and as a fair warning, I'm not sure if I can provide a very rigorous explanation below).
As Swistakk said, we'll travel along h-1 of the edges of the convex hull consecutively, then we'll have an "open edge" which isn't included on our path. One condition we must satisfy is that the line we draw through here will then partition the rest of the points into two parts. The way we draw lines is that the first point is on the "growing" spiral, the the second point is on the "shrinking" spiral.
So, once we choose an open edge of the convex hull, only the right point of this edge can be on the growing spiral, and we can see that there are s+1 partitions of the non hull points once we choose one of the hull points to be part of our line. Or alternatively, you can view this as once we choose a hull point as our first point, there are only s+1 partitions of the inner points.
You can reason similarly that any of the (s choose 2) lines of the inner points will form a line that crosses two convex hull edges, so there are (s choose 2) * 2 partitions possible for these inner points overall (i.e. choose two points, this separates into two sets, and label one "growing" and the other "shrinking"). Now, you may notice that this count is excluding the lines where the second point of our line is a hull point. To show that these are redundant, we can see that when we draw this line, if we rotate the line counterclockwise about the first point of our line until it hits a new second point, it doesn't change our path, so we can see we can ignore paths where the second point of our line is a hull point.
This covers all the cases (i.e. the first point of our line is either a convex hull point or not a convex hull point). Showing these paths are unique takes a slightly more work, and I would be happy to elaborate if you wish (but this is getting a bit lengthy, so I'm going to cut myself short here).
So in summary, we can get a bound of N*(N-1) partitions. Doing a little more reasoning gets us the exact formula. The proof is actually pretty tough, and what I have above is mainly just intuition on how to approach this.
But there is a unique path starting from any point on convex hull. I guess there is some misunderstanding on my part.
Sorry for the confusion. When I said "first point", I was referring to "first point of the separating line", not "first point of the path". Does that answer your question?
My point of view was following: Consider that our cutting line cuts a side of a convex hull in point P. Watch how possible partitions changes when point P travels around convex hull. Everytime we cross a vertex we get new s+1 partitions since we are changing thrown edge and everytime we cross a line formed by 2 inner points we get one new partitions, because we can "swap" those two points between parts. If none of that happens (P doesn't cross neither a vertex nor any lines) then partitions do not change. That is pretty much everything on why there are exactly (s+1)h+s(s-1) paths and an explicit way to enumerate them.
Were you eating palmiers while creating that problem :)?
Haha, those do look very familiar :) I don't quite remember what I was thinking when I was creating problem. I think I had the div2 version first in my head, but then I realized that I could actually solve the counting total number of paths case as well.
For those who don't follow TC thread — decision was made that this SRM will be unrated.
I was expecting to finally become red after rating update ;__;...
I have expected to go back to green, I couldn't understand easy problem and test casecases. Skipped to medium read announcement and go back to easy. 99 point and many people getting 240.
I hope Petr will cover this round in his digest anyway :)
BTW, does someone knows — did TC ever had 2 unrated rounds in a row before?
Yes, one guy mentioned it in a thread about this SRM. 361->362->363 :)
Maybe Petr should also cover div2 round this time? :)
i hope i'm not too late can someone explain how to solve Div 2 level 3 problem i took a look at this solution and got stuck in the two loops where he is filling his "ans" vector i couldn't understand the idea behind it
The same idea is described here. The only difference is that we need all points to be included in ans, so there will be spiral, not convex hull
got it, Thanks !