


Привет всем!
556A - Дело о нулях и единицах
Если в последовательности остались хотя бы одни единица и ноль, тогда существует подстрока 01 или 10, которую можно удалить. При этом порядок удаления не важен: в любом случае мы сделаем min(#единиц, #нулей) операций, так как за раз удаляется один ноль и одна единица. Поэтому ответ: #единиц + #нулей - 2min(#единиц, #нулей) = |#единиц - #нулей|.
Время: O(n).
556B - Дело о поддельных шестеренках
Заметим, что через n нажатий кнопки система приходит в исходное положение. Поэтому самое простое решение — это промоделировать процесс из n шагов и, если на одном из них встретится последовательность 0, 1, ... , n - 1, выдать "Yes", иначе "No". Но можно это решение ускорить. Например, сразу по значению первого элемента определить нужное количество нажатий, перейти в это положение и один раз проверить.
Время: O(n) или O(n2); решения: O(n) и O(n^2)
Предположим нам не нужно разбирать некоторую последовательность. Тогда ни в одну из матрешек этой последовательности не нужно вставить другую. Поэтому нам не нужно разбирать последовательность матрешек лишь в случае, если они идут подряд, начиная с 1. Пусть длина этой последовательности равна l. Тогда вытащить одну из другой нам нужно будет n - k - l + 1 раз, при этом останется одна цепочка из l матрешек 1 → 2 → ... → l и остальные цепочки по одной матрешке. Всего n - k + 1 цепочка, поэтому вложить одну в другую нужно n - k раз. Всего будет сделано 2n - l - 2k + 1 операций.
Время: O(n); решение.
Между островами i и i + 1 мы можем положить мост, длина которого попадает в отрезок [li + 1 - ri;ri + 1 - li]. Получаем задачу: есть n - 1 отрезков и m точек на прямой, необходимо каждому отрезку сопоставить какую-то точку, лежащую в нем, причем каждую точку можно сопоставить только одному отрезку. Будем идти по точкам слева направо, и хранить в сете отрезки, которые еще ничему не сопоставлены и которые содержат рассматриваемую точку. Пусть мы обрабатываем очередную точку. Сначала добавим в сет все отрезки, которые начинаются в этой точке. Далее выберем из них тот, чей правый конец имеет наименьшую координату. Утверждается, что этот алгоритм находит ответ, если он есть. Предположим это не так. Пусть мы на каком-то шаге выбрали для точки A другой отрезок (пропускать точку не имеет смысла). Тогда посмотрим, какая точка B сопоставлена отрезку, который был бы выбран нашим решением. Точка B лежит заведомо правее A. Поэтому мы можем поменять точки для этих отрезков и снова получить ответ.
Время: O((n + m)log(n + m)); решение.
Решим задачу с помощью двух деревьев отрезков: для столбцов и для строк. Будем хранить для каждого столбца самую нижнюю съеденную дольку, а для каждой строки — самую левую. Пусть приходит запрос x y L. Находим значение в дереве отрезков для строк на месте y. Пусть это значение равно ans. Теперь нужно вывести x - ans и в дереве для столбцов обновить значения на отрезке [ans + 1, x] до y, а в горизонтальном обновить значение в элементе y дo x. Аналогично с запросами типа U. Чтобы разобраться с большими ограничениями на n нужно писать либо неявное дерево отрезков, либо сжатие координат.
Время: O(qlogq) или O(qlogn); решения: 1 and 2.
555D - Дело повышенной секретности
Назовем активной длиной La длину части веревки от груза до последнего встреченного колышка. После каждого встреченного колышка активная длина уменьшается. Будем моделировать процесс для каждой длины веревки независимо. На каждом шаге будем бинарным поиском находить, за какой колышек зацепится груз сейчас. При этом если активная длина при этом уменьшается хотя бы вдвое или мы делаем первый шаг, то просто переходим к следующему шагу. А иначе пусть текущий колышек имеет номер i, следующий — j (без ограничения общности i < j). Тогда заметим, что после колышка j мы снова зацепимся именно за колышек i. Действительно, 2(xj - xi) ≤ La, поэтому веревка зацепится не правее чем за i-й колышек. И либо i = 1, либо La ≤ xi - xi - 1, поэтому левее, чем за i-й колышек она тоже зацепиться не может. И вообще, пока активная длина будет не меньше, чем xj - xi, груз будет наматываться на эту пару колышков, следовательно, можно сделать сразу несколько ходов. При этом после этих ходов длина веревки уменьшится хотя бы вдвое. Поэтому всего таких будет сделано не больше log(L), где L — изначальная длина веревки.
Решение: O(mlogLlogn); решение.
555E - Дело о компьютерной сети
Для начала, сведем задачу к задаче на дереве. В каждой компоненте двусвязности ориентируем ребра в порядке обхода DFS. Утверждается, что мы получим компоненту сильной связности. Пусть это не так. Тогда граф можно разбить на два подграфа A и B так, что не существует ребер, идущих из B в A. Причем изначально ребер между A и B хотя бы два. Но это невозможно, так как, зайдя в эту компоненту B, мы должны будем выйти по одному из ребер между A и B, а это невозможно. Противоречие.
Поэтому мы можем сжать все компоненты двусвязности.
Теперь надо обработать несколько запросов вида “ориентировать ребра на пути” и проследить за отсутствием конфликтов. Подвесим дерево за некоторую вершину и предподсчитаем LCA для исходных пар вершин. Запустим dfs из корня и для каждого поддерева посчитаем количество вершин, являющихся началами исходных путей (переменная а), вершин, являющихся концами исходных путей (переменная b), и предпосчитанных LCA (переменная c). По этой информации можно ориентировать ребро из корня поддерева в предка: если a - c положительно, тогда вверх, если b - c положительно, тогда вниз, если оба положительны, тогда решения нет, если оба нули, то как угодно.
Время: O(n + qlq) где lq это время подсчета LCA на запрос; решение, использующее немного другой метод для последней части.






Автокомментарий: текст был переведен пользователем Lord_F (оригинальная версия, переведенная версия, сравнить).
LoL that's just inviting downvotes
Actually I am interested why not to prepare editorial before the contest?
P.S. Of course, not to publish editorial before the contest, but simply write it and save in drafts.
And I am interested why doesn't anybody post their solutions. I don't force somebody to post a solution, I just mean that every editorial some people submited different code and concept, but now all quiet. Strange things.
I agree with you
So let me start with Problem B:
For each gear, calculate minimum number of rotations which will get the required active tooth
Answer is Yes if all gears require the same number of rotations
Else, answer is No
Alternatively, since the limits were relatively small, (N < 1000), an O(N^2) solution would work fine, so you could instead simulate pressing the button N times, then checking to see if it works each time
Or, you could define the button operation, and call it until the first gear has the 0th as the active tooth, once this is the case, if any a[i] != i => "No" if all a[i] == i => "Yes"
Div1 A was a bit confusing
Hi there! Although I couldn't get it through in the contest, here's my solution for Div2D/Div1B:
Define gap as gap[i] = L[i+1]-R[i].
Sort all the gaps in non-increasing order.
— Define min_gap : The actual gap between adjacent islands = L(i+1)-R(i)
— Define max_gap : The difference R(i+1)-L(i), that is the maximum size of the bridge allowed.
— Extract the largest bridge available in range[min_gap,max_gap] and use bridging this gap.
— If no such bridge is available, output "No".
Here is a link to my AC solution. : http://mirror.codeforces.com/contest/556/submission/1180956
Can we sort gaps in increasing order and extract smallest bridge in range[min_gap,max_gap]? I used this approach but got wrong answer on test case #6(may be implementation error).
Yes, it is correct because of the following invariant that is maintained: The bridge we have extracted will be :
a) The list of available bridges for this gap, as [min_gap,max_gap] is the range of bridges available for this gap.
b) So we will in any case have to choose one of these. Since all the gaps after this are less than this gap, therefore these bridges will fit them too. It makes sense to choose the largest available possibility as this way we will minimize the chance of "choosing the wrong bridge" later on.
EDIT: Sorry, I misread your comment. No that would be incorrect as explained by @crew_underfog_p1. I have clarified above as to why sorting it in non-increasing order works.
The forward approach should be wrong as per my understanding. Consider there is a gap1 with mn,mx = (1,10) and there is another gap2 with mn,mx = (2,3) and the bridges available are 2, 8. So according to your greedy allotment, the leftmost gap i.e gap1 will be alloted 2 and the gap2 cannot be allotted 8. This would lead to WA. A similar scenario should occur in backward approach unless you re using swaps as mentioned in the editorial. Please correct me if I have misunderstood.
Thanks :-)
you are wrong with your ideas thezodiac1994 . FoolForCS's solution is correct
I had the same WA in test #6, notice that FoolForCS solution process the gaps in decresing order
I solved Div1 C without any segment tree but unfortunately I have not solved it in contest.
При попытке открыть решения высвечивается "Недостаточно прав для просмотра запрошенной страницы". Ещё в Div2A количество операций равно min(#zeros, #ones).
Lord_F : Editorial's source code link is not working. Can you fix that. ?
Oops. Will fix this.
Still not working.
Still not fixed. I'll do it momentarily after I post the remaining problem editorial
Fixed now =)
Автокомментарий: текст был обновлен пользователем Lord_F (предыдущая версия, новая версия, сравнить).
I got several WA's on Div. 1 A before the problemsetters rewrote the descriptions (thank you! :P), but I was still failing on pretest #6, and it was 5 minutes before the end of the contest that I realized that 1 → 2 → 4 → 5 means '1 in 2 in 4 in 5' (5 is the one outside while 1 is the one which doesn't contain anything else). I thought it meant '5 in 4 in 2 in 1'... (And of course I didn't solve this A :( )
So I'd like to ask the descriptions to be made clearer again. Would it be possible to say 'for example, 1 → 2 → 4 → 5 (where 1 is in 2, 2 is in 4, and 4 is in 5)' in the problem? Thank you in advance.
Despite, the problem itself is really a nice one, which requires mathematical thinking & ideas rather than complex implementations. A good Div. 1 A :)
Quote from the statement: A matryoshka with a smaller number can be nested in a matryoshka with a higher number
Oh sorry... I paid too much attention to the numbers... Well, that's my fault. The arrows may really be misleading sometimes, though.
in div1-B/div2-d it's written that" Now we have a well-known problem: there are n - 1 segments and m points on a plane, for every segment we need to assign a point which lies in it to this segment and every point can be assigned only once."
Can someone please tell me what this problem is popularly known as or give link to some valuable resource related to the problem??
Maybe I'm wrong about that one. When I was given this problem I already knew such greedy solution, so I thought it actually is well-known.
Could you give more valuable resource about this problem ? Thanks
Problem B div 1 was very good ! I hope more interesting problem like this :)
case of chocolates:
can explain output in this test case?(test case 5)
input:
10 10 5 6 U 4 7 U 8 3 L 8 3 L 1 10 U 9 2 U 10 1 L 10 1 L 8 3 U 8 3 U
output: 6 7 3 0 10 2 1 0 0 0
For problem 555-C I like the segment tree approach but I would be interested in knowing how some people did it using set and map . If someone who solved the problem using set could let me know I would appreciate it .
Here is a way of doing it with map. Consider two different maps: one storing the left events and one storing the up events. These maps take the x-coordinate of the query and map it to the answer.
Add (0, n + 1) and (n + 1, 0) to the triangular grid of points and query both of these points going up and left. These points will now be in both maps.
Suppose that there is a new query (x, y). Suppose that this query is to the left (the up case is similar). If (x, y) was already queried, then the answer is 0. Or else, let g < x be the greatest integer so that (g, n + 1 - g) was a left query (such a thing exists because 0 is in the left map). The query for (g, n + 1 - g) can reach to a certain x-coordinate h. It is easy to see that (x, y) can also reach to at most h (draw a few diagrams and you will see).
In order for this to not be the answer, (x, y) must have been queried as an up event or some up event between g and x cuts the line from (x, y) off. This can easily be checked by querying the up map.
Link to solution: http://mirror.codeforces.com/contest/555/submission/11803362
If we use just one map and for every
xstore query direction and result, the code gets even shorter:http://mirror.codeforces.com/contest/555/submission/11828084
edit : ok I found the problem with the approach I wrote earlier.
A simple solution with set:
The key observation is that each query simply breaks the problem into two similar sub-problems, which in general look like:
(for the starting state w=h=0). We will maintain an ordered set of such sub-problems. Each sub-problem consists of an interval on the diagonal and two parameters w,h. The ordering will be by interval coordinate, let's say x, so that given a query with coordinate x we can quickly get the sub-problem from the set.
Given a sub-problem and a corresponding query it's easy to split the sub-problem into two subproblems and put them back to the set.
Complexity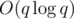 . Submission
. Submission
I think all of the problems were really interesting! I hope we'll see more contests from you two! :)
Was it just me or atleast before the announcement in Div1 A/Div2 C someone thought of applying union-find?
Honestly, the announcement was more like an explanation, not a modification. I understood the problem statement before the announcement.
The test data of Div.B is not perfect, my code passed but it's wrong. Here is my wrong but accepted submission 11799654, And this is the data in: 3 1 1 2 3 4 5 6 2 out: No
I hope it can be added as a test data.
The test data of Div1.B is not perfect, my code passed but it's wrong. Here is my wrong but accepted submission 11799654, And this is the data in: 3 1 1 2 3 4 5 6 2 out: No
My code output "Yes".
I hope it can be added as a test data.
I'm sorry to post the message twice indeliberately because my web condition is not very well.
sorry, i misread the problem statement.
I didn't use y and I got accepted too and the reason is quite simple: since the statement indicates that xi + yi = N+1, you really don't need to use y anyway once you have x and N.
Can someone please explain 555E solution to me? I didn't understand the editorial.
First, notice that it is always possible to orient the edges inside a biconnected component such that there is a path between any two vertices. This is evident from the algorithm of finding those components — simply orient the edges in the direction you first discover them in, and the criterion that you check inside the DFS will ensure that it is always possible to find the way back in the tree.
Next, you condense the tree — that is, replace every biconnected component with a single vertex, and the bridges in the original tree will be the edges of the new tree. The problem is now reduced to orienting edges in a tree. There are multiple ways to proceed from here, I'll give mine.
You need to find the LCA (least common ancestor) for every query pair (you probably need to do this regardless of which method you choose to solve the problem). Now, for every pair A, B, if their LCA is C, we know that the only path from A to B is to go up from A to C, then down from C to B, so the edges along the way have to be oriented accordingly. Now, if the distance between A and C is X, we will say that from A, at least X edges above it have to be oriented upwards (and vice versa for B). Then we can go through the entire tree from bottom to top, calculate this N as a maximum of the value stored in the node, and values for all children — 1, both for upwards and downwards requirements. If both values are positive, we output No.
Don't forget that there might be multiple trees if the original graph is not connected. If the original queries are from different components, you'll notice that when calculating their LCA, for instance.
Thanks! I get it now.
Well, You are a little wrong in your definitions above.
The tree formed by compressing the components distinguished by the bridges is different from the block-cut tree formed by compressing the biconnected components of the graph. Also, the components referred above will NOT be biconnected components.
Eg : Consider the following graph with 5 Nodes and 6 edges
1 2
2 3
3 1
3 4
4 5
5 3
Here, If we consider the biconnected components , there will be two different biconnected components A and B, having the following nodes
A --> 1 , 2 , 3
B --> 3 , 4 , 5
while there would be only 1 single bridge component (the components referred above) consisting of all the 6 nodes, coz there are no bridges in the graph.
Refer this for more info about Bridge Tree : http://threads-iiith.quora.com/The-Bridge-Tree-of-a-graph
In a graph, the biconnected components are distinguished by the Articulation Vertices while the bridge components are distinguished by the bridges.
Also, if we assign direction to edges inside a bridge component, it will form an SCC, coz each bridge will be a part of a cycle (imagine creating a Spanning Tree of the bridge component and add edges one by one compressing the cycle each time into a single node untill the whole tree is compressed into a single component)
The above problem can also be solved by forming the Block-Cut Tree by shrinking the BCC's , but it's important to note the distinction between the two different types of tree's.
Here is an accepted solution using the Bridge Tree approach .
http://mirror.codeforces.com/contest/555/submission/11884660
Oh, yeah by biconnected components I meant the ones where you can connect any pair of nodes with two edge-distinct paths (as opposed to vertex-distinct), guess that's not what it normally stands for.
Well, I believe Rivx is not wrong, you just call things differently. In the editorial I use "biconnected components" exactly as the bridge component. In Russia in order to specify the difference we might use either "edge-biconnected component" or "vertex-biconnected component".
Ok. Didn't know about the terminology used in Russia , because everywhere on the internet, Biconnected components refer to the vertex-biconnected components.
Why is La ≤ xi - xi - 1 in D? If we have pegs at 1, 2, 3 and 10, and start at 2 with length 5, then we will loop around 3 and come back to 1, no?
Yeah, unfortunately I forgot about this case: this inequality doesn't hold at the first iteration. Fixed this.
Auto comment: topic has been updated by Lord_F (previous revision, new revision, compare).
I am not able to understand the solution discribed for problem
555A - Case of MatryoshkasThe editorial states the answer is 2n - k - 2L + 2 , which is simply wrong for the test case
so
ans = 2*3 - 2 - 2*2 + 2 = 2whereas the answer is 1
Should'nt it be
2n - k - 2l + 1?If anybody could point what's wrong in my submission : 11800309 , getting WA at pretest 13.
It's already fixed. Sorry)
You should add
breakinelsebranch ofifinside twoREPs. Try to test on1 2 3 6 4 5— in this case you'll count4 5as one matryoshka, which is wrong since you can't take a matryoshka from the one which is inside another matryoshka.i have a question about d problem .
-> "And either i = 1 or La ≤ x(i) - x(i - 1) so it won't also rotate around a peg to the left to peg i."
he sad if La ≤ x(i) - x(i - 1) then "we can skip through several steps momentarily".
but he didn't explain if La >= x(i) - x(i - 1). can anyone answer ?
there are three situations. 1. is the end of the rope between i and j 2. is the end of the rope between i-1 and i 3. is the end of the rope between (<i-1) and i-1
if we are in 1. situation. the La will be at most half of his length if we are in 2. situation. "we can skip through several steps momentarily". if we are in 3. situation. (no answer)
I already mentioned it in the comments. Note that it is only possible at the start, so you only need to check for this situation once per query (and it only takes one extra step). I.e. If you didn't start at i, this situation is impossible.
Thank you very much. i understood it.
В английской версии разбора написано, что задача, к которой мы свели задачу B (div.1) -- это "well-known problem". Я ее в первый раз увидел, поэтому стало интересно, где она раньше встречалось или упоминалась? Если кто-нибудь знает, поделитесь, пожалуйста, ссылкой.
У меня в С div1 более простое решение, которое делает эту задачу даже проще, чем B.
Предположим нужно выполнить операцию Up к столбцу x, ищем самую первую операцию справа от x. Если найденная операция тоже Up, то новая операция будет ограниченна тем же, чем была ограниченна и найденная операция. Если же найденная операция Left, то новая операция Up будет ограниченная найденной операцией Left.
И тогда получается, что вместо двух ДО достаточно иметь set, map и пару массивов, хотя само решение будет таким же O(q log(q)), но пишется проще и быстрее.
Код
Вроде много таких решений было. Не знаю насчёт "легче В", но на В, по моему мнению, вполне может сойти и так, и с деревьями отрезков. Тем не менее, судя по результатам, общая сложность раунда была абсолютно нормальной.
Очень часто участники даже не читают задачи, которые, скорее всего, не смогут решить. Это психологический эффект. А если и читают, то из-за того же эффекта не будут сильно пытаться думать о решении. Уверен, если бы задачи B и C имели иной порядок, то С решило бы больше людей, чем B, и опять же, всё из-за психологического эффекта.
I wrote up a solution for Div2 D which I think is easier to implement and has been discussed in the comments.
Any comments are more than welcome :)
Thank your for your effort. Could you please explain more your phrase "Specifically, if we sort the gaps based on their max_d, we get the nice property that we will take care first of the gaps with smaller separation while still giving priority to those with smaller min_d." ?
I am getting wrong answer on test case 38 of 555D. Any help would be appreciated. Here is my solution.
555E — Case of Computer Network
The solution posted on paste.ubuntu.com with link present in this article is wrong.
Take this test:
It outputs "Yes" instead of "No".
I've found my mistake (hopefully, the only one): there was a problem with initialization of parents while compressing biconnected components which lead to incorrect LCA finding. Now the solution must be correct.
Actually, I have a solution which uses Tarjan LCA algorithm so answers to all tests from the testset are correct.
Can you please explain me div1 C?
Does implicit segment tree mean that we only assign children to nodes when they are needed, in a lazy manner ? It kinda reminds me of trie. Is that right ?
Yes, it does. In the second solution given for Div1 C children in the segment tree are created only when they are needed in lines 65-69.
I think you meant Div1 C. Thank you it helped me a lot.
I'm having trouble coding the implicit segment tree. Could please point out my mistake if you had anytime to spare ? Thank you very much.
I'm getting TLE on 10th .
Submission
I am using indices instead of explicit left and right pointers (and an array of nodes instead of creating new nodes on the fly).
I believe your get is strange: you can visit a node even if q is not in [l;r].
Thank you so much. I fixed it and got AC.
In the solution code of problem Case of Computer Network in editorial, what is the purpose of function compress(int v, int cid) ?
It finds biconnected components and condensates them.
Could somebody explain me DIV 2E/DIV 1 C ? I am unable to understand it. I was looking for a clean code in all java submissions and it's one of the cleanest http://mirror.codeforces.com/contest/555/submission/11839184 , but I am still unable to understand it, especially those two lines
I'd be very grateful if somebody helps me. I spend couple of days without any result.
The short version of
Case of Chocolaterequires quite a bit of observations (and proofs).You cannot understand it through the code itself.
The short explanation is that you only need to look at 1 of your neighbors to tell the result.
Sorry, but it doesn't help at all
Sorry for giving a short answer there. It's not easy to explain.
Consider treating each bite as an entry and assume we bit 2 already (
'U'from(0, n + 1)and'L'from(n + 1, 0)).Let's take
'U'for instance. Suppose our starting point is(x, y).We need only to look at the entry to our immediate right.
(x2, y2).'U'and it reaches(x2, y3), then we can reach(x, y3).'L'and it reaches(x3, y2), then we can reach(x, y2).Similarly with
'L', we only need to look at the entry to our immediate left.Now the only thing to consider is how to use an ordered container to store the entries.
Hi, Can someone please tell me how would the Go About 555B — Case of Fugitive if the question was to find the number of ways the bridges can be assigned modulo MOD ?
Thanks :)
If anyone's getting a Wrong Answer on Div1 D, consider the following situation: You are trying to rotate the rope so that it gets attached to some peg on the right side. But, if all pegs on the right side are too far off, it won't get attached to any peg on the right and will keep moving and might get attached to some peg on the left.
The following test case may be helpful:
3 1
-27 -23 36
2 38
1
To correct this, 2 things may be done:
Note that this case may only arise while performing the starting move, so you perform the first 2 moves beforehand (2 because the 1st one may not work as in the example above). Code
You consider attaching it to a peg on one side and if that doesn't succeed (you end up at the same peg), try attaching it to a peg on the opposite side. If that too doesn't work, current peg is the answer. Code