


Только что закончился гран-при Екатеринбурга. Посылаю лучи недовольства в адрес людей, считающих что можно ограничиться фразой "формат вывода определите по сэмплу".
Задача G, имхо, тоже очень сомнительное развлечение. Это, конечно, очень забавно, но будет обидно, если кто-то не отберется по спонсорскому зачету в Петрозаводск из-за того, что не справился с угадайкой.
Как решать задачу H?






И еще, кто-нибудь кроме нас писал специально на JavaScript, чтобы решить задачу K?
Мы на питоне сдали. Боялись, что считать не успеем, но в итоге сразу зашло.
Аааа горит! Как решать задачу C?
Динамика:
i— количество типов,dp[1] = { K }. Хотя динамика — громко сказано.Для
i = 2..N:M— сколько нужно голосов, чтобы выжить самому старшему;cnt— количество умерших на предыдущем слое динамики. ЕслиM - cnt > K(подкупать умерших не надо, так как они и так будут на нашей стороне, ибо иначе умрут), то копируем предыдущий слой и дописываем-1самому старшему. Иначе самый старший может выжить, если подкупит тех, у кого на предыдущем слое динамики не было денег вообще. То есть подкупать тех, кто до этого умирал — не надо, они и так будут на стороне самого старшего, так как их цель — выжить (1 приоритет); подкупать тех, у кого ничего не было — можно, их цель заработать побольше (2 приоритет); подкупать тех у кого и так что-то было — нет смысла, потому что они всё равно захотят убить самого старшего (3 приоритет) или он может заплатить им больше, но тогда нарушит 2 приоритет для себя; ну и нужно подкупать самых старших (4 приоритет).Подкупать нужно единичкой, чтобы у старшего осталось как можно больше.
Надеюсь понятно написал.
Ответы на пару тестов
можно не рассматривать случаи с умершими, а просто считать что они получили -1. Тогда мы выбираем нужное количество с минимальными значениями и даем им на 1 больше.
Технически — тоже самое, но вроде if написать проще, чем задумываться о таких вещах)
P.S. Ну хоть один человек ответил, а то я уже стал думать, что может все вокруг считают, что я какую-то другую задачу объясняю.
Более-менее понятно, спасибо большое!
А мы весь контест решали С, потому что считали, что у грабителей с меньшим номером должно быть больше денег (как диаграмма юнга). На клар нам ответили "No comments".
H нам дали в четверг на тренировку. Ту же задачу, но с куда более жесткими ограничениями. Простого куска хватило для этой задачи. Баяны -- это классно! :)
Вот и пропускай тренировки после этого.
Problem H: https://en.wikipedia.org/wiki/Schreier%E2%80%93Sims_algorithm
Well, is it allowed to use such tasks in contests? This task is just a copy of Schreier and Sims' idea and there is zero originality. I hope authors to come up with original tasks.
And problem I — I believe it's not a good idea to try to separate MCMF and Hungarian. Both are O(n^3).
MCMF worked 0.336 seconds in my case, not even close to TL (and I believe it can be still optimized a lot, by changing long long to int etc.).
Interesting fact: most of the people who had issues with MCMF fitting into the time limit never have issues with
long long.Were they actually trying to separate them though? I passed with Dijkstra on Set in my Min Cost Flow. So it was even O(N^3logN).
OK maybe my implementation was bad — is O(E log E) dijkstra faster than O(V^2) in practice?
With set: 1.2s
V^2: 0.49s
MCMF with Ford-Bellman works 0.8
Написал много гавнокода на К. Какие проблемы могут быть?
Ключ может быть пустой строкой. У меня был WA2 из-за этого.
Facepalm :( Пофиксил прошла
Anyway thanks
Вы еще не в параллель с онасайтом решали. Условие F и J понять было совсем нельзя, и в I были кривые тесты. (и в A еще, но там нас не сильно задело). Ну и H на 13 минуте заслать готовое решение, которое я в четверг объяснял -XraY- это было смешно.
Кстати, говорят H еще была на контесте Unpredictable в птз летом 2011.
Лучше бы вы четверть провели на этом
Лучше для кого?
Для меня
.
Кволы опенкапом? Совсем там поехал? Зачем давать на опенкап контест из трех задач?
В упор не понимаю, почему ты так гордишься этими кволами. С задачей "дать порешать что-то неACMщикам" он справился. Давать на опенка задачи для неACMщиков — это странная тема.
Ну в OpenCup есть не только спон... первый дивизион. Так что идея такая была, если бы не свойство отбора на Всесибирскую Олимпиаду, заключающееся в том, что его пишут все (редкий случай, когда Div1 и Div2 полностью совпадали).
Проблемсет с квалификационных раундов — отличный Div2 problemset, на самом деле. C задачей "сделать хороший Div2" в OpenCup вообще мало кто справляется. У СПбГУ вот с методикой "упрощённых версий Div1" только 2-3 последних ГП стало хорошо получаться. Так что предмет для гордости, как мне кажется, есть.
В Саратове, насколько я знаю, каждый год на основе школьной олимпиады организуют не плохой контест. Просто меняют ограничения в задачах, возможно одну-две заменяют. То же самое могло получиться на основе квалов ваших
Вот стремление вылезти с любым проблемсетом в первый дивизион мне кажется совершенно непонятным. В Division 2 тоже участвует много команд, и к задачам этого дивизиона свои требования, близкие к тем, которые были предъявлены к задачам квалификационного раунда. Хотя в среднем Div2 получается на уровне среднестатистического четвертьфинала (исключив, пожалуй, московский — обычно проблемсет вполне себе на Regional), что всё же для команд из нижней половины таблицы сложновато.
В том виде, в котором квалификационный раунд есть сейчас, он удовлетворяет этим требованиям практически идеально — только перевести условия на английский и можно было бы давать. А предлагается из идеально соотвтетствующего второму дивизиону проблемсета сделать "какой-то" для первого.
Кто-нибудь может указать, откуда в Н следует, что даны перестановки?
"Если в какой-то момент часть материи перетекает из одного мира в другой, то возникающая в первом мире пустота тут же заполняется материей из некоторого другого уголка вселенной. И наоборот, если в какой-то из миров переносится материя, этот мир тут же отдаёт часть своей материи другому миру."
То есть в каждый мир приходит хотя бы одно ребро. Раз исходит ровно одно, приходит хотя бы одно, то перестановка.
Здесь не указано, что что-то приходит. Может, оно через вход назад лезет?
Кстати, а если это не перестановки, задача решаема еще?
Non-deterministic?
А как решать "D"? А то 10 мин крутить машину, чтоб потом пихнуть 1 мб ответов — не решение.
Напишем квадратичную динамику. Потом оптимизируем её до линии префиксными суммами.
Я заслал квадрат. Он работал 0.6 =)
What was case #3 of J and #8 of I?
Расскажете как решать А из див2?
Так же, как А из div1.
P.S. Вот это шутканул — так шутканул.
Скажите, как решать задачу Е (о триангуляции Одина) из див2. А лучше дайте глянуть на код. Что ж там за 3 тест? Спасибо.
http://pastie.org/private/nosnymkmwwzneiw9ncd6yw
???
iddqd
Переберём треугольники, построим описанную окружность. Проверим попадание вершин соседних (по вершинам) треугольников в эту окружность.
Даблы получают WA7. Дроби на лонглонгах WA11. Дроби на даблах AC.
Не для слабонервных
У меня WA3 было когда сначала неправильно находил серединный перпендикуляр. Потом когда неправильно решал систему.
Написал все в лонгах. на вики есть статья, как легко определить попадает ли точка в описанную окружность
Делал в даблах, делил на sqrt и прочую нечисть, никаких эпсилонов, ОК.
надо проверить свойство, описанное в условии. для каждого треугольника ни одна из вершин всех остальных треугольников не должна лежать строго внутри описанной окружности
Как решать A? Мы придумали персистентное декартово дерево, но оно по памяти не заходит.
Построим дерево деления плоскости следующим образом. Разобьем bounding box на два прямоугольных треугольника, а каждый треугольник будем делить рекурсивной процедурой следующим образом: если треугольник не содержт внутри себя других точек множества, то этот треугольник назовем листовым и ничего делать не будем, а иначе выберем случайную из точек, лежаших внутри треугольника, разобьем его на три с помощью этой точки и запустимся от них рекурсивно.
Таким образом, мы получим дерево из треугольников, в котором листы образуют корректную триангуляцию нашего множества. Имея такое дерево, легко по точке получить треугольник триангуляции, содержащий ее. Из каких-то эмпирических сооображений следует, что глубина такого дерева будет близка к логарифмической.
Тем не менее, с интересом бы послушал, какие еще решения сдавали.
После некоторых размышлений мы пришли к мысли, что, наверное, сдавалось решение вида "выберем 100 случайных направлений, отсортируем вдоль них наши точки, а дальше для каждого запроса будем находить ближайшие вдоль этих направлений и пытаться вписать нашу точку в них".
А покажешь свой код? У меня такое зашло в дорешку, но мне не нравится моя реализация :)
Код не очень красивый, потому что в рекурсивной функции построения хотелось уйти от векторов и динамической памяти и сделать все in-place. Еще я заметил, что там есть bounding box (и что на выпуклой оболочке всегда ровно четыре точки) только под конец, поэтому там есть бинарный поиск чтобы найти, в какой из треугольников выпуклой оболочки попала точка :)
У тебя код гораздо чище и аккуратнее.
Круто, спасибо! :)
В условии сказано:
Данные, хранящиеся в KSON, можно представить в виде дерева, в котором промежуточными вершинами являются объекты, а листьями — строки-значения или пустые объекты.
Думаю, что же такое имеют ввиду авторы под пустыми объектами. Наверно, {}. Задаю вопрос жюри:
Что такое пустые объекты упомянутые в условии?
Получаю ответ:
""
Отлично. Какое хорошее жюри, решило не давать такой корнер кейс. Но в восьмом тесте есть {}, и если заменять ссылку на {} на "", то получается WA, а если не заменять — OK. Чем же тогда является {} как не листом в дереве и как его наличие в тестах соответствует с условием? Можно было бы понять ответ жюри, если бы ссылки на {} нужно было бы преобразовывать в "", но нет, их не нужно ни во что преобразовывать.
Призываю жюри ответить, почему был дан такой ответ на вопрос по задаче.
Вопрос был понят скорее как "бывают ли пустые строки" — на него приходилось отвечать много раз.
В вопросе специально было указано "упомянутые в условии".
Судя по всему, корректность 8 теста сомнительна, так как фраза " Этот список ключей указывает путь от корня KSON к некоторому листу, хранящему строку-значение" подразумевает, что если лист есть, то он хранит соответствующее значение.
Вариант, что лист есть, но он хранит {}, в данной формулировке кажется несколько неестественным. Возможно, что 8-й тест будет удалён.
А можно узнать 10 тест?
Возможно ли, что жюри в будущем будет более формализовывать условия задач, в которых так важен формат входных данных, или, хотя бы, отвечать "I am Groot" на вопросы участников, не вызывая у них неправильного понимания условия?
Олег, это был, откровенно говоря, опенкап с самыми хреновыми условиями за последние несколько сезонов. Несмотря на то, что среди задач были действительно клевые, раунд в таком состоянии, как мне кажется, не должен становиться туром открытого кубка.
Да вроде пофиг. Опенкап — неофициальное соревнование. Тот факт, что Яндекс платит за него деньги, все еще не делает его официальным.
Но условия, конечно, хлам полный. У нас вчера еще в трети задач ограничения в кларах приходили :)
Просто интересно, а что ты тогда считаешь официальным соревнованием?
Начнем с наличия более-менее внятной регистрации :)
Свободной (не через секторы) и анонимной регистрации на OpenCup не будет. Соответственно, не будет ни школьных "команд" из одного человека, ноющих на форумах про то, почему не решается самая простая задача из второго дивизиона, ни максиманов-бредоров с 15 аккаунтами у каждого, ни северокорейских команд по 30 человек.
Возможные изменения в схеме регистрации скорее уж могли бы быть в сторону какой-то интеграции с baylor-овской базой для команд, участвующих в ACM-зачёте (в частности, в спонсорском), если бы baylor предоставил соответствующий API.
А в чём претензии к существующим правилам регистрации секторов? Казалось бы, всё детально расписано.
...удалено (решил ...)
А как Вы отвечали на данные вопросы? "Да, могут"?
Как минимум, должен был быть общий клар по этому поводу.
Когда я писал код по этой задаче, я, наоборот, отталкивался от того, что ключи не могут быть пустыми строками (ибо как-то это глупо).
Общий клар про ключи был. Там было сказано, что они не содержат других символов, кроме (описание). Пустая строка под такое описание подходит. Явного запрета ключам быть пустыми тоже в условии нет.
В див.2 неприходило кларов :/
Нету у кого-нибудь крутого теста на K?(WA test #10)
А Вы правильно обработаете
Value:key.иValue:?Да, обработав второе стал проходить второй тест. После первого 6-ой. А сейчас даже не знаю в чем ошибка =(
У меня еще было что неправильно обработал случай
value.key, когда key есть объект kson у которого есть пара"" : "some string".А что должно в ответе получаться-то? Надо обращаться по ключам нулевой длины?
Да.
Да вроде никто уже и не удивляется наркоманским условиям уральских контестов.
Так как все-же H решать?
Гуглить по словам "алгоритм шраера-симса".
Да, я видел ссылку выше. Так ничего конкретного не находится.
Нам гуглить не помогло — мне кажется это понять и закодить меньше чем за 2-3 часа не выйдет :)
Помогло только найти опенсорсную библиотеку и заинлайнить её в один файл Егоровским плагином.
Ну ты преувеличиваешь сложность. Мне halyavin минут за пять его полностью рассказал, говорит, что на туре они его придумали за пару часов. Могу вкратце пересказать, если интересно, о чём оно :)
Ну я же написал "понять" — halyavin эту работу сделал за тебя :) Или ты знаешь, где в интернете настолько понятно написано?
Ну я про сложность решения, а не про сложность конкретного изложения :)
Очень интересно, расскажи вкратце, пожалуйста.
Сорри за задержку с ответом. Вот код решения: http://pastebin.com/Rayq5Lfe
Алгоритм Шраера-Симса для чайников:
Идея такая. У нас есть некоторая группа, порожденная данными перестановками: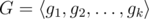 . Выделим в ней подгруппу G1, являющуюся стабилизатором единицы: она будет состоять из всех перестановок, которые мы можем породить, которые оставляют единицу на месте. Тогда ответ, очевидно, равен p·|G1|, где p — количество различных мест, где может оказаться единица под воздействием всей G, а |G1| — мощность группы, оставляющей единицу на месте (иными словами, мы сначала ставим единицу на место, а потом дорасставляем остальные элементы). План такой: сначала считаем p, а потом рекурсивно сводим задачу к G1, предъявляя набор перестановок, порождающий G1.
. Выделим в ней подгруппу G1, являющуюся стабилизатором единицы: она будет состоять из всех перестановок, которые мы можем породить, которые оставляют единицу на месте. Тогда ответ, очевидно, равен p·|G1|, где p — количество различных мест, где может оказаться единица под воздействием всей G, а |G1| — мощность группы, оставляющей единицу на месте (иными словами, мы сначала ставим единицу на место, а потом дорасставляем остальные элементы). План такой: сначала считаем p, а потом рекурсивно сводим задачу к G1, предъявляя набор перестановок, порождающий G1.
Сначала посчитаем, где вообще потенциально может оказаться единица под действием нашей перестановки. Будем для простоты считать, что единица может оказаться на местах 1, 2, ..., l. Найдем все этим места простым DFS'ом, используя применения исходных перестановок как ребра. Каждой из этих позиций будет соответствовать какая-то своя перестановка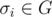 , которая ставит единицу на место i: σi(1) = i, эти перестановки мы тоже посчитаем в DFS'е.
, которая ставит единицу на место i: σi(1) = i, эти перестановки мы тоже посчитаем в DFS'е.
Утверждение: G1 порождается всеми произведениями вида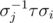 , где
, где  — произвольная образующая группы G, sigmai — любая из сигм, а j выбирается таким образом, чтобы после применения σi и
— произвольная образующая группы G, sigmai — любая из сигм, а j выбирается таким образом, чтобы после применения σi и  загнать единицу обратно на первое место. Действительно, такое произведение будет лежать в G1, так как оно оставляет единицу на месте. Почему такими произведениями все порождается? Рассмотрим произвольный элемент G1. Он получается произведением каких-то образующих G:
загнать единицу обратно на первое место. Действительно, такое произведение будет лежать в G1, так как оно оставляет единицу на месте. Почему такими произведениями все порождается? Рассмотрим произвольный элемент G1. Он получается произведением каких-то образующих G: 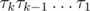 , где все
, где все 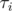 — это какие-то образующие G. Перепишем это произведение в виде
— это какие-то образующие G. Перепишем это произведение в виде 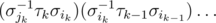 , нетрудно видеть, что перестановка не изменилась от этого, но теперь очевидно, что она порождается набором перестановок, который я назвал выше.
, нетрудно видеть, что перестановка не изменилась от этого, но теперь очевидно, что она порождается набором перестановок, который я назвал выше.
Отлично, теперь мы можем совершить рекурсивный переход: ответ на нашу задачу это l умножить на ответ на задачу G1, для которой мы знаем набор образующих (из них всех можно смело выкинуть единицу, так как они все оставляют единицу на месте). Однако, за один такой шаг мы увеличиваем количество образующих в l раз, что приводит к экспоненциальному времени работы.
Теперь ключевое соображение заключается в том, что если есть огромный набор образующих, то из него всегда можно только n(n - 1) / 2 осмысленных. Это делается некоторым подобием метода Гаусса. Рассмотрим k перестановок. Заметим, что можно оставить максимум одну перестановку, у которой на первом месте 2, максимум одну перестановку, у которой на первом месте 3 и так далее (если σ1 и σ2 обе переводят 1 в x, то σ2 можно заменить на σ1 - 1σ2). Проделаем такую операцию, после чего мы получим n - 1 перестановку с чем-то нетривиальным на первом месте и дофига перестановок, которые оставляют единицу на месте. Проделаем с ними то же самое, и так далее.
Теперь ход алгоритма понятен: на каждом шаге мы сводим задачу к перестановкам на единицу меньшего размера, а потом фильтруем образующие описанным выше методом. Работает типа за n3, кажется.
У меня он был написан в качестве заготовки для задачи, не вошедшей в прошлогодний Hackercup :)
В I же минкост заходит?
ну Q2 * MCMF заходит)
а можно код? а то в своём в не вижу ошибок...
http://ideone.com/b55GJK
http://pastebin.com/bW2pmndf
Покажите этот блог знакомому школьнику, который думает увлечься спортивным программированием. Не дайте ему совершить нашу ошибку
А еще ссылка на обсуждение на официальном сайте соревнования ведет на пост с названием "вертел я такие условия"
А какие будут конструктивные предложения?
Это ветка обсуждения проблемсета. Другой ветки с обсуждением нет. Не ставить ссылку на обсуждение с официального сайта недопустимо.
Качество условий действительно оказалось не на высоте, экспресс-попытка это исправить оказалась неудачной (как минимум, не по всем задачам). Всё же авторам стоит давать кому-то из опытных проблемсеттеров доступ к задачам на вычитку до начала онсайт-раунда.
where can see the problems?
Как насчет задачи J?
Правда ли что ненулевых запросов может быть только 2?
неправда
нет, неправда
Пара хинтов:
Изначальная матрица нам не нужна, в конце просто прибавим ее к ответу. Далее считаем что она нулевая.
Пусть ответ это матрица d, тогда dij = dik + dkj для любых i, j, k.
Из второго пункта следует, что существует такой массив φ, что dij = φj - φi.
Можно узнать, как найти этот массив?
ну нужно решить систему уравнений φt - φs = deltast. Попробуй решить такую систему уравнений, когда граф состоящий из ребер из s в t — дерево.
Как доказать, что в В асимптотика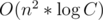 ?
?
Не понимаю, откуда взялось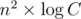 , но там вроде можно за
, но там вроде можно за 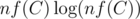 , где f(C) — максимальное число делителей среди чисел от 1 до C.
, где f(C) — максимальное число делителей среди чисел от 1 до C.
Что с опенкапом в итоге, зачётный этап или нет? "Положение в кубке" на opencup.ru до сих пор не обновилось.
В общем зачёте этап зачётный. Остальное обдумывается (в основном на предмет совместимости задачи H и спонсорского зачёта).
UPD: Вряд ли четыре балла в спонсорский зачёт, полученные формально законным, но не вполне этичным для команды ACM-зачёта путём, на что-то повлияют, так что этап включён и в спонсорский зачёт. Результаты на сайте обновлены.
Что это за тема с отбором "по спонсорскому зачету в Петрозаводск"? Впервые слышу.
Анонс за прошлый год; в этом году анонса вроде не было, но зачет опять есть — вот.