


Привет, Codeforces!
Поздравляю всех с наступлением весны!

01 марта 2016 года в 18:00 MSK состоится девятый учебный раунд Educational Codeforces Round 9 для участников из первого и второго дивизионов. Снова отмечаю плотность соревнований и чемпионатов в эти дни и надеюсь, что она вас не спугнёт и вы напишете ER9.
<В этот раз я ничего тут не менял>
О формате и деталях проведения учебных раундов я писал уже ранее. Также об учебных раундах вы можете прочитать здесь.
Раунд будет нерейтинговым. Соревнование будет проводиться по немного расширенным правилам ACM ICPC. На решение задач у вас будет два часа. После окончания раунда будет период времени длительностью в один день, в течение которых вы можете попробовать взломать абсолютно любое решение (в том числе свое). Причем исходный код будет предоставлен не только для чтения, но и для копирования. Таким образом вы можете локально тестировать решение, которое хотите взломать, или, например, запустить стресс-тест.
Если у вас есть идеи каких-то задач, которые вам кажутся интересными, или может есть уже что-то почти готовое, что вы по каким-то причинам не можете дать на раунд (злой координатор сказал, что задача БАЯН), официальное соревнование (жюри не хочет переграбливать соревнование), можете писать мне.
Не стесняйтесь присылать простые (и даже очень простые) задачи (но обязательно интересные). Почти каждый раунд достаточно быстро выбираются кандидаты для задач C, D, E, F, а вот задача A обычно ставится самой последней, когда уже почти всё готово.
</В этот раз я ничего тут не менял>
Снова комплект задач был полностью предложен участниками сообщества. Задача А как и в прошлый раз была предложена пользователем unprost (будьте готовы к длинному условию). Задачу D предложил Денис Безруков pitfall. Задачу E достаточно давно прислал Алексей Чесноков CleRIC. Задачи B, C и F были предложены пользователем Lewin Gan Lewin.
Благодарю их и всех кто присылает задачи или просто наброски!
Подготовкой задач занимался я (Эдвард Давтян). Спасибо Маше Беловой Delinur за проверку английских текстов условий. Тестерами задач выступили те кто их предложили: unprost, Алексей Чесноков CleRIC и Lewin Gan Lewin. Большое им за это спасибо!
На раунде вам по традиции будут предложено шесть задач. Надеюсь они вам понравятся!
Good luck and have fun!
UPD1: Первая часть соревнования завершена. Можете взламывать другие решения.
UPD2: В связи с техническими проблемами фаза открытых взломов будет открыта позже (через несколько часов).
UPD3: Разбор задач на русском языке готов.
UPD4: Соревнование закончено. Системное тестирование начнётся через несколько минут.
UPD5: Лучшие три взломщика:
P_Nyagolov — 31 взлом
khadaev — 27 взломов
halyavin — 23 взлома







Thank you:)
А те, кто присылает задачи, сами могут участвовать? Скажем, при условии не засылать конкретную задачу, или засылать, но через определённый промежуток времени. Скажем, когда большое количество людей решит задачу, да бы это выглядело более-менее честно. А ну хотя тогда еще надо ввести правило, что они некоторое время должны ничего не делать (якобы решать присланную ими задачу), а не решать другие задачи.
В общем, своими рассуждениями по этому вопросу я сам на него ответил — проще запретить участвовать.
Кажется это не честно. Раунд в любом случае нерейтинговый. Так что при желании тестеры могут его просто прорешать виртуально.
Hello spring and hello another amazing editorial. Good luck to everyone
On one hand i also want to prepare some problems but on the other hand i don't want to miss any CF round...
Допустим на фазе открытых взломов, кто-то подобрал тест, ломающий некоторое решение. Кликать по каждому и копипастить — то еще занятие. Как вам идея реализовать возможность прогнать этот тест на всех остальных решениях? Например, участник, взломав товарища, может кликнуть по появившейся ссылке "попробовать на остальных!". Количество успешных/неуспешных взломов на счет не влияет, а время взломшиков поможет сэкономить, может еще что-нибудь придумают интересное, если не будут тратить время на однообразные действия.
Мне кажется, суть этапа взломов, в том чтобы научиться читать чужой код, понимать его, и искать в нём слабые места, и заодно смотреть на другие подходы к решению задач, а не свалить как можно больше решений не читая
Прогоном отдельного теста по всем имеющимся решениям занимается уже System Test, тут задача свалить все неправильные решения, и как я понимаю, тесты уронившие решения на этапе взлома, добавляются в набор для System Test
Если какой-то тест ломает много решений, то достаточно поломать одно из них, и не тратить время на остальные. Так будет эффективнее.
Чтобы говорить об эффективности, нужно сначала определиться с целью, т.к. эффективность определяет степень достижения цели.
Если цель повалить как можно больше решений — да, эффективнее свалить одно, а все остальные уже автоматически (но с этим хорошо справляется System Test в конце соревнования)
Если цель научиться читать чужой код разной степени корявости — то нет, не эффективнее, потому что один тест, может валить разный код, по совершенно разным причинам. Допустим, одно решение может падать на A, B тестах, а второе на тестах B и C, имея при этом разные ошибки
I think it would be better if it was rated ^_^
There'd be no difference between regular cf round and educational round if it was rated .
I'm running in the the contest and I don't know from which files to take the input and write the output at problem F because input.txt and output.txt don't work for me. I know the code is good because with cin and cout it ran until test 8 I think where I got th time limit exceeded. Please help me.
How would you pass 7 tests with reading from a wrong file? And how does passing 7 tests mean that your code is "good"? Read from the stdin, not from a file. Your program is too slow apparently.
I passed test 7 reading with cin. And i tried to read with fstream.
It's guaranteed that printf() and scanf() are fast enough in C++. And note that maybe your algorithm is too slow.
Of course my algorith is too slow without scanf and printf and this is the point. It doesn't work when i try to read from input.txt
Ok.
can E be solved without FFT?
I don't think so.
aha, then it should be harder than F if the intended solution for F is bitset, IMHO.
Of course it is not intended solution. I'm sorry for that, but I can't increase the size of input, it is already about 67MB. The right solution has complexity O(n2logn).
It's also possible to get O(n^2)
Wow, that's nice! You can sort all edges in O(n2). I didn't notice it during the contest.
Could you explain it?
Are you sure? The input size is O(n2).
Yes. As you can see aij < 109 not aij ≤ 109. It is by the reason of large input size.
I meant that your complexity can't be O(nlog2(n)) because it's smaller than the input size. Maybe you meant O(n2log(n))?
You are right. I fixed it.
There seems to be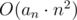 bfs solution (let
bfs solution (let 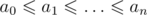 ): let's look for possible sums of k elements, we can get them by starting with k·a0 and trying to find sums, rechable from this by not more than k replacements of a0 with some ai. Basically, there is a graph with
): let's look for possible sums of k elements, we can get them by starting with k·a0 and trying to find sums, rechable from this by not more than k replacements of a0 with some ai. Basically, there is a graph with 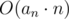 vertices and
vertices and 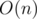 edges from each.
edges from each.
It is even possible to optimize this solution with bit operations, because all edges are to vertices with sum different from current not more than by an, so we can use some bit manipulation to find edges to yet not visited vertices in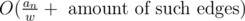 , which amortizes to
, which amortizes to 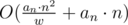 , where w is amount of bits in processor word, i.e. w = 64.
, where w is amount of bits in processor word, i.e. w = 64.
I hope explanation is relatively clear, you can look in my code (and try to hack it, I was too lasy to implement above optimisation after seeing that code works reasonably fast without it).
Has anyone solved E with just FFT on complex? I get TL6 even with some optimizations.
UPD: I did it, 4991 ms :)
You can raise polynomial P to the k-th power just by raising every value of FFT(P) to the k-th power.
But if we raise double in 1000th power, there may be problems with precision?
I think you can't do that with doubles (too high degree k). But my third solution do that with NTT. Of course it works faster, but it is not correct of course. To make it correct we should get several random primes.
You do all FFTs on arrays of size 106. That's O(k·maxa·log(k·maxa)·log(k)). If you do FFT on arrays of size equal to the degree of polynoms then complexity will be O(maxa·log(maxa) + 2maxa·log(2maxa) + ... + k·maxa·log(k·maxa)) = O(k·maxa·log(k·maxa))
This solution seems to work without FFT: http://mirror.codeforces.com/contest/632/submission/16447568
Включите взломы!
I still cannot hack solutions. What is going on? Can anyone hack now?
How? :P Why doesn't the hacking phase start immediately after the contest is finished?
cannot hack
It will be fixed soon.
thank you.
I can't hack solutions.
is someone facing the same problem ?
See the UPD2.
where can I see editorial to these problems?
Contest is not over yet. Usually the editorial is published as soon as the hacking phase finishes.
Oh, silly me, I thought in 632B - Алиса, Боб, две команды Bob could take any segment...
F: We can prove that if matrix is MAGIC, after removing all values which are maximum among the matrix elements, the remaining part of matrix is collection of MAGIC matrices.
Then we can solve this problem by solving smaller problems recursively. The naive implementation of this idea took O(N^3) times, but good implementation make this algorithm O(N^2 log N).
If you do it in reverse order, starting with empty graph and adding edges in increasing order, then it'll work in O(n2).
Oh, your solution is much easier to implement. (But it requires O(N^2 log N) time since we sort the elements, I think.)
Yes. But edges can be sorted in O(n2) if you notice that in magic matrix there are only O(n) different values. So it's not hard to improve it to O(n2).
Can someone explain why am i getting runtime error in the 8th pretest of the 3rd question?
Here is the code.
comparison function should return false when both elements should be considered the same
now your function returns true so it breaks the sort function. To fix that just change
<=to<Don't read this comment
Ignore the usual comparator, you are defining a new one. The function should work exactly as operator <. Can you say that A<B and B<A are both possible at the same time?
I get you now :)
I am telling you that sort uses < operator, not <= and in rivudas' case it happens that A<B and B<A at the same time ( a=xyz and b=xyzxyzxyz ) :)
ignore
Yeah, precisely what I am trying to say is that it's an incorrectly defined cmp function :)
It's because the sort function assumes that when your comparison function returns false, if and only if a is strictly less than b. (In other words, a must be placed before b.)
Let's say
a=xyzandb=xyzxyzjust as you said, the sort function triescmp(a, b)and got true. That meansashould be beforeb. But then if for some reason it calls the reflexivecmp(b, a)(or transitive likecmp(b, c)cmp(c, a)) and it got true again, there would be a contradiction, thus the runtime error.Don't read
Work sometimes doesn't mean work always. You cannot prove correctness by giving examples.
And to be more specific why you case might work, STL sort is based on intro sort which uses different sorting algorithms depending on the contents and the size of the array. I made your example fail simply by increasing the size of the array.
http://ideone.com/CQt5jE
Now its CLEAR!! Thanks, or I'd have lost a good night's sleep lol :)
I've got an off-topic question : how do you suggest new problems ? I mean, to whom do you have to send them ? To GlebsHP?
"If you have ideas for some problems or maybe already prepared problems that you can't use in rounds or official competitions, you can write to me"
you can write to Edvard :D
Oh sorry, I didn't read that well. Thank you ! :)
Edvard, do you know approximately when the hacking phase will be open?
It is already opened. Sorry for late answer.
"UPD2: There are some technical problems. The phase of open hacks will be opened later (several hours)."
NourAlhadi when i decided to learn hacking :3 :3
How to solve problem E ?
А вы тоже читаете анонсы educational раундов, только чтобы увидеть, что же написано в угловых скобках?
I found someone with amazing short (compare to other which use FFT) code to E:
http://mirror.codeforces.com/contest/632/submission/16452555
Problem C. C++ solutions using
bool comp(string& a,string& b){ return a+b<b+a;}seems ~2-3 times slower than solutions using the same in dynamic languages: Python, Perl. That's interesting.Hi, I want to know some idea about how to solve problem D :)
I solved it this way:
Remap all values from array co counts arr, where index is a value and value is a count of times the value presented in input. Only use numbers <= M (numbers > M won't be in any possible solution).
Cycle from M to 1. This way we pick our L for test.
Factorize our L in prime factors (using e.g. Eratosthenes sieve). From factorization generate all possible distinct delimiters (including non-prime ones, e.g. for 30 it would be 30, 15, 10, 6, 5, 3, 2, 1). Get sum of counts[delimiter].
Pick the best sum.
Can't say what exactly complexity this solution is, but something around O(500 * M), where 500 is max possible distinct delimiters of any number (it is somehow defendant on M too, 500 is my estimation for max value of 10^6).
It's actually less, maximum of divisors between 1 and 1 000 000 is actually only 240. 240·M is still very risky for 2 seconds, but the actual sum of delimiters is almost half that,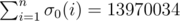 , where σ0(x) is the divisor function.
, where σ0(x) is the divisor function.
And ln(1000000)*1000000=13815510... Coincidence? I think not.
PS The reason behind this is that harmonic series diverge as ln(n).
I think I understand. It's somewhat easy I failed to think that because i misread the problem, thinking it was asking for a contiguous sub-sequence
acc!!! I don't even needed to calculate the primes :) I used some kind of dynamic programming
16463867
can anyone show some ideas about E? I see the post above mentioned FFT, I searched it but still no idea...
What is "Unexpected verdict"? Hack #217732.
Another solution got "Unexpected verdict" on the same test (Hack #217738). So I guess one of incorrect author solutions was marked as correct by mistake.
Yes. You are right. You hacked my third solution with one (not random) module and binary exponentiation of DFT (not polynomials). Module is 998244353.
DP solution for problem E is awesome. I wonder how people think this way in contest time.
Can anyone one please give some problem link that is solvable using this technique.