


Всем доброго времени суток!
Как известно, в ноябре 2015 были опубликованы формулы для рассчета рейтинга. Как мне кажется, наиболее неоднозначная часть — определение вероятности, что один участник выступит лучше другого: 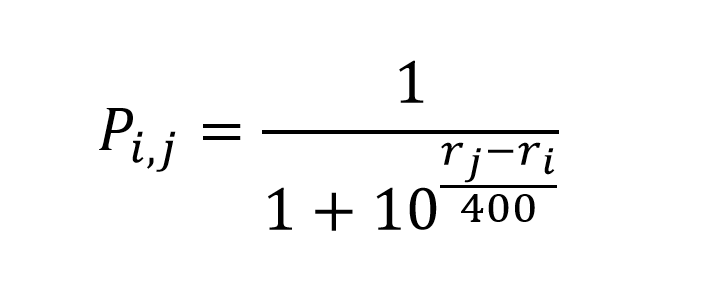
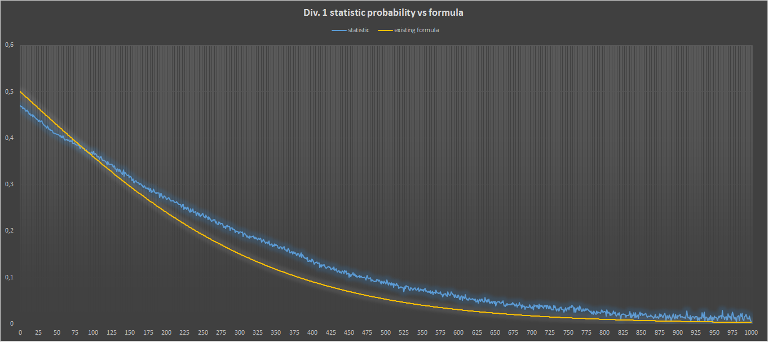
А где вероятность — там мат. статистика. Уже прошло довольно много рейтинговых раундов на Codeforces, поэтому я задумал вычислить данную вероятность статистически. Было решено провести вычисления на раундах cf №200 — №350 (отдельно по дивизионам). Для этого я написал небольшую программку (иссходники). Закинул полученные результаты в Excel и получил такие графики:
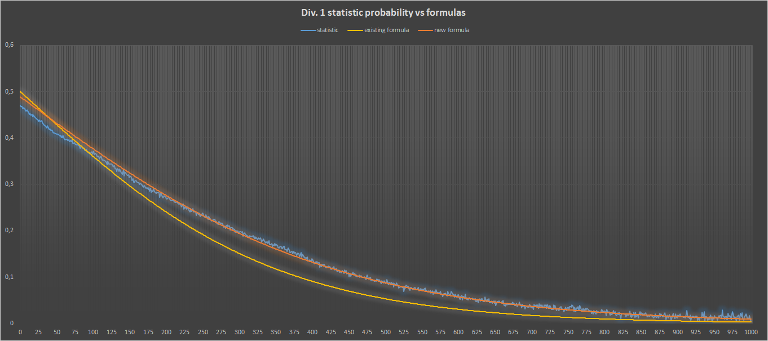
для первого дивизиона
для второго дивизиона
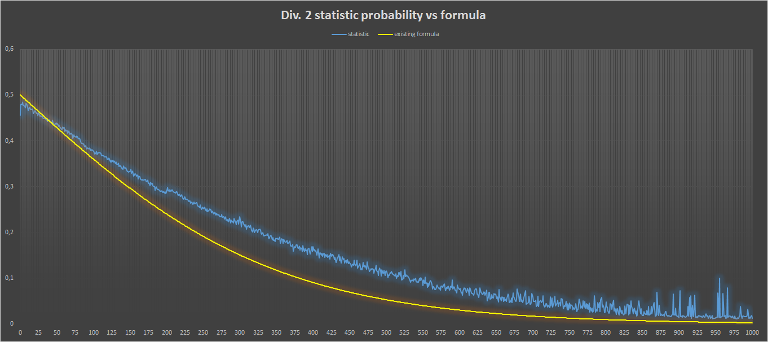
Кажется довольно не плохая аппроксимация но я решил попробовать найти что-нибудь поближе:) Подбор выполнял вручную (так что наверно можно получить результаты получше) вышло:
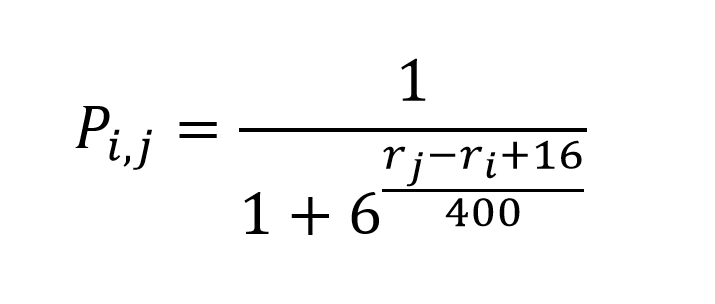
но согласитесь, формула выглядит как-то не научно... поэтому легким движением руки превращаем ее в:
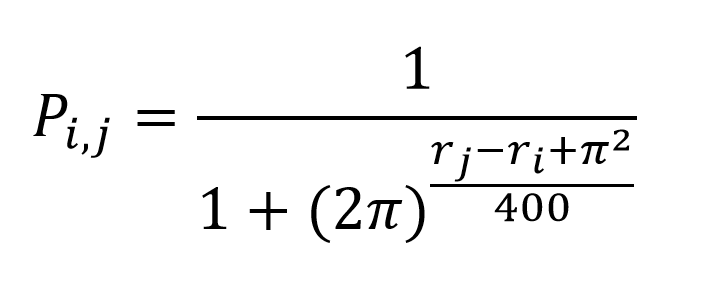
Теперь посмотрим, как это выглядит на графиках:
для первого дивизиона
для второго дивизиона
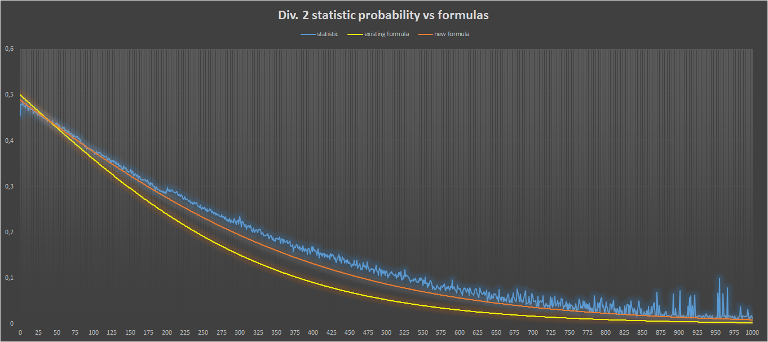
Кажется, так выглядит получше:)
Может возникнуть несколько вопросов, так что попробую ответить:)
1) Почему при нулевой разнице рейтинга статистическая вероятность победы не 50%?
Потому, что пользователи с одинаковыми рейтингами иногда занимают одинаковое место.
2) Почему во втором дивизионе аппроксимация хуже?
Скорее всего это из-за читеров, так как большое расхождение начинается при разнице рейтинга от 200.
P.S. Что побудило меня на эти исследования?
По результатам 3 раунд VK CUP неожиданно для меня понизился рейтинг. По этому, пользуясь открытыми формулами, быстренько посчитал сиды для всех участников контеста, у нашей команды вышел seed = 97.3936 а место — 96.. но причина падения — в этом раунде рейтинг считался не для всех сразу, а отдельно по дивизионам. Но я уже разогрелся и не захотел останавливаться на полученном:)
P.P.S. На всякий случай, отмечу, что я глубоко уважаю Михаила MikeMirzayanov Мирзаянова, Максима Zlobober Ахмедова, Глеба GlebsHP Евстропова и всех остальных причастных к созданию и функционированию Codeforces и у меня нет никаких претензий, только предложения по улучшению:)







Такое наблюдение: Любая формула влият на рейтинги учасников. Они, в свою очередь, влияют на статистику того, насколько часто учасник, рейтинг которого выше на столько-то, побеждает другого.
Вопрос: К примеру, были введены новые формулы. Не изменится ли тогда статистика таким образом, что новые формулы будут под нее подходить уже не так хорошо?
"Вопрос: К примеру, были введены новые формулы. Не изменится ли тогда статистика таким образом, что новые формулы будут под нее подходить уже не так хорошо?"
я хотел проверить, но к сожалению у меня не вышло быстренько промоделировать обновление рейтинга по предложенным формулам. Попробую сделать это позже:)
Кажется, что при замене коэффициентов в формулах аппроксимирующая формула изменится соответственно. Т.е. вместо ~6 в основании степени появится коэффициент ~3.60 .
Auto comment: topic has been translated by WasylF (original revision, translated revision, compare)
Auto comment: topic has been updated by WasylF (previous revision, new revision, compare).
Немного удивляет что в нуле получается что-то отличное от 0.5 (по измерениям). Как у вас ничьи обрабатываются?
"Может возникнуть несколько вопросов, так что попробую ответить:)
1) Почему при нулевой разнице рейтинга статистическая вероятность победы не 50%?
Потому, что пользователи с одинаковыми рейтингами иногда занимают одинаковое место. "
в случае ничьи считаю, что никто из двух соперников не победил другого. Если считать, что победили оба, тоже не выйдет 50%, будет больше. А как выбрать ОДНОГО победителя — не ясно:)
Небольшой пример. Если участники разделили 4-7 место, то для каждого из них rank=5.5 (а не 4 или 7). Если это исправить, то и соотношение Pi, j + Pj, i = 1 будет верным.
в формуле никак не фигурирует rank, поэтому в случае его изменения (описанным образом) ничего не произойдет:) Важно лиш то, у кого rank меньше, а у кого больше.
Нужно ещё добавить:
По-моему правильно считать, что каждый из них победил наполовину.
I believe the formula should satisfy Pi, j + Pj, i = 1.
I think it should be p(i,j) + p(j,i) + (probability of both participants having identical result) = 1 :)
OK, that explains why the blue graph at 0 is less than 0.5.
Yep, the writer seems to have taken care of the mathematical details :P
you are right:)
Кстати, в коде, который выкладывал MikeMirzayanov, как я понимаю, ничьи тоже не обрабатываются (всем указывается наименьший ранк, то есть все друг друга "победили")
по крайней мере API возвращает одинаковые ранки для участников с равным количеством очков. Например, по результатам ВК раунд 3 у 4 участников (2 команд) ранк 17.
http://mirror.codeforces.com/api/contest.ratingChanges?contestId=643
Ну то, что отображается такой ранк в результатах, это логично (это ровно то, что вкладывается в понятие "место")
Вот при расчете рейтинга, не нужно ли его увеличить до (first + last) / 2.0 — это вопрос.
(и кажется, что это логично сделать, если формулы несмещенные)
Забавно. На многих контестах по несколько сотен участников набирает 0. Если для них считать по first вместо (first + last) / 2.0, то получится, что рейтинг каждого из них уменьшится не так сильно, как должен (а в некоторых случаях должен даже увеличиться).
Почему-бы не запретить ничью? Точнее сделать его очень невозможным, при равенстве очков сортировать по последнему АС в точности до секунды или по количеству посылок? UPD: не подумал про нули и отрицательные баллы.
Эти две формулы (+меры по борьбе с инфляцией) задают модель рейтингов на Codeforces. Если бы данная модель хорошо описывала участников соревнований, то у WasylF получилось бы именно такое распределение. результаты хорошо аппроксимируются формулой с константой 6^(1/400)=10^(1/514) вместо 10^(1/400), т.е. разность рейтинга между любыми участниками должна быть в 1.285 раз больше текущей. Возникает 2 соображения по этому поводу:
Распределение рейтинга, соответствующее реальному уровню участников ещё не установилось окончательно, а так называемая "инфляция рейтинга" у наиболее сильных участников — это лишь процесс установления соответствующего распределения; меры по борьбе с инфляцией этот процесс сдерживают. В этом контексте, было бы любопытно посмотреть на эти же графики не интегрально за всё время, а в разные моменты времени с интервалом в несколько месяцев.
Возможно, модель рейтинга станет лучше, если учитывать нестабильность результатов участника (аналогично параметру Volatility на Topcoder) или использовать нормальное распределение (Topcoder) вместо логистического (шахматы).
Я не разбирался с формулами, но есть ощущение что слишком трудно происходит переход между дивизионами. По крайней мере из 2 в 1. Может есть статистика ск-ко человек меняет дивизион за раунд?
Упомянул Zlobober не упомянув Gerald
Gerald: "Это из-за того, что я уже не красный?"
RAD : "=((("
Надо добавлять какие-нибудь бейджи / списки благодарности / краткие биографии для особо отличившихся членов сообщества! Я, например, даже не знал, что RAD был координатором.