


Four participants will advance to the finals. Check the exact time.
EDIT: 15 minutes to the start.
| # | User | Rating |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | maomao90 | 163 |
| 2 | Um_nik | 163 |
| 4 | atcoder_official | 161 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | nor | 153 |
| 9 | Dominater069 | 153 |
Four participants will advance to the finals. Check the exact time.
EDIT: 15 minutes to the start.







This round should be easier to advance now that some people have advanced from 3A.
Now we only have to compete with weaker contestants like tourist.
Frantically trying to regain first place in contribution xD.
He got it!
Sad story below (and judging by the outcome some parts of it may not be entirely accurate but this is how i believed it went):
I was pretty sure that registration is automatic and it was so in round 3A also. So I came pretty late, at 18:52-53, and checked the menu — both register and enter button were inactive, so I decided that everything is fine. Couple of minutes later everybody joined the room including me then the countdown went to zero and I wasn't able to open the problem. Apparently you had to register and I didn't :(
"and it was so in round 3A also" — it wasn't
However I understand your feels. That sucks.
That's probably my poor english. I meant that I thought it was cause I don't remember registering for it.
How to solve hard? Anyone got any idea?
misof suggested to change the word 'good' into 'attuned', I was thinking that could be a hint.
I've never seen this word before and didn't try to find the exact meaning during the contest :D
#agoodlesson
Any more hints?
Spoilers
SpoilersBlack magicExperimental result (I have no proof).
Let's call two strings equivalent when the difference is constant, for example 01021 and 12102. Let's call k is a pseudo-period of s when s and k-th cyclic shift of s are equivalent. Let's call a string nice when it has non-trivial pseudo-period like 010211210220210 (pseudo-period is 5).
Then, when two strings are attuned, at least one of them is nice.
But what about the reverse? If one of them is nice, will this pair be attuned? (Seems not since a string is not attuned to itself except strings like "RRRRRRR")
I guess the condition is something like: the union of their pseudo-period will be all divisor of the length. I haven't done the experiment, just guess from the result of my solution. :)
It seems this kind of approach is very hard to do, I found lots of complicated patterns and gave up.
After reading your hint, the task became much easier and passed systest in practice room. Though it's very hard to go to that direction.
Here's as far as I got during the contest: let 1, w, w^2 be the three cube roots of 1 in the complex plane. Convert each robot's sequence to a sequence of these values e.g. rock=1, paper=w, scissors=w^2. The result of a game can be uniquely determined from a*conj(b), where a and b are the moves chosen (1 if a tie, w if a wins, w^2 if b wins). Also, the result of a match can be uniquely determined from sum(a * conj(b)).
The set of possible match results can thus be determined from the cross-correlation of two robot's strategies. For the cross-correlation to be a constant function, it's Fourier transform must be zero everywhere except in the DC term. This Fourier transform is the product of the Fourier transforms of the strategies (plus some conjugations, which don't really matter), so two robots are attuned iff there is no frequency (other than DC) for which both have non-zero Fourier coefficients.
After that I got stuck. There is a fairly straightforward O(2^K*N) DP, which is too slow (although pretty close — it gets most test cases in the practice room). cgy4ever's practice room solution seems to do a recursive search, and presumably makes the assumption that most Fourier transforms with non-zero non-DC components will have many such components, and hence the recursion will not be too deep; I think it's also assuming that the number of zero/non-zero patterns is small. Those seems like reasonable guesses, but I'm not sure how to prove them.
You just described the intended solution except the last few steps. :)
So the O(2^K*N) DP can be optimized into O(3^K) without any more observation. And we can optimize it into O(2^K * X) where X is the number of different masks. Where X is these values for K = 1 to 18 (http://ideone.com/j7lSKR for K = 18):
It will need few minutes (5 minutes for me) to get these values. And you can know all masks after that. The simple dfs just works since there are very few cliques (the max clique is 5 for K = 18).
And that is the reason we can't set K to something smaller or reduce N from 10^5 to 1000, as long as we can get the graph in O(N^2*K^2), we can do this: if two vertexes has same neighborhoods, then put them one class. After that there will be very few classes (even much smaller than 281 for K=18), do dfs for the compressed graph, there will be very few cliques as well.
Hmm, maybe K = 15 is also fine (so O(3^N) could work), but I'm a bit afraid some unexpected solutions could pass. I'm sorry to see that you stucked in the last step.
I use O(N*k^3) gauss elimination and get TLE...
For medium, looks like everyone used the (much more clever) recursive solution, so I'd like to share my solution:
Let the string expri be the string formed by implicating the first i letters of the alphabet after A. So expr1 = B,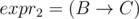 ,
, 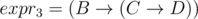 .
.
We can see that expri encodes all strings that begin with i - 1 zeros followed by a one, so you can use them to encode n - 2k - 1 in binary. If the binary representation of n - 2k - 1 has ones in positions p, q, r, our final answer is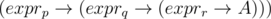 .
.
Even though maybe today's hard was a nice problem (I lack understanding to give a good judgement), but I think better place for such problems is New Year Snark's contest, not extremely short TopCoder.
On GCJ I made a bet that quickly done ABC without D should be sufficient, because 25 people get to finals. On TCO since only 4 people are getting there each round I rook risks and tried to solve hards. From the strategical point of view I think those were pretty good decisions, but it turned out I should have definitely reverse that. Among 8 people that got on TCO nobody solved any hard. Hards on 3rd TCO rounds were like n times harder and there were 3 times less time. I think you should rethink purpose of hards on any TCO rounds, they basically have 0 impact on the results of competition and that very small amount of finalists is based on problems of difficulty comparable to Div1 B+C. In my opinion it is wasting challenging and interesting problems. Any TopCoder rounds is not a good place for them (unless you decide to made them significantly longer, which could be a very good option for more important rounds).
+1, I fully agree.
Even on SRM's quite often nobody solves Hard (am I right?). I think Easy should be harder than usually in third rounds of TCO, but maybe as-hard-as-usually Hard would be enough? Is it that important to avoid the situation with more than four participants solving all problems? I don't think so.
I understand that it's hard to estimate the difficulty, especially in short topcoder contests. But if Hard was harder on purpose, it was a bad decision I think.
"Even on SRM's quite often nobody solves Hard" : Petr solved 8 Hards in recent 10 contests, so I think they are not that hard at least recently.
" Is it that important to avoid the situation with more than four participants solving all problems?" : Hmm, it is ok if more than 4 people solve all problems, but that would not be very good if it is like last year's 3B (the score between 2nd and 9th place is less than 50).
"But if Hard was harder on purpose, it was a bad decision I think." : I agree. They are more original than average SRM on purpose, instead of more difficult. But sometimes more original just means more difficult.
eatmore solved Hard in 3A and advanced (since some people from top 4 can't attend the final). Petr was getting very close, I believe if he opens Hard first (or open it after solving Easy) then he can solve it.
And in today's contest, bmerry was getting very close. rng_58 could solve it quickly after reading my hints, so that is possible to be solved in 75 minutes if you can get the idea quickly.
So I don't think they are too hard for that slot. And the implementation of them is shorter than average Div1-Hard, so they are good for a 75 minutes contest. For me, the amount of details and implementation in them is much less than those hard tasks in other long contests, even some ICPC rounds.
The difficulty varies from round to round, because
We select tasks with the best originality first, instead of deciding how many people should get AC for each slot first.
It is hard to predict how many people could solve a task, especially when the task is novel.
So it is always hard to decide what strategy to use. rng_58 was using the same strategy (try to solve Hard) in both rounds, but that didn't stop him winning today's contest.
Problem in those tasks is that they are both really time-consuming. The approach in 3A was like "Hmmm, let's do some weird construction (out of many possible) that can get something, code it even though there is no reason why that should lead to something and then note it didn't produce all numbers, but produced all prime numbers, so that's fine!" Problem with it is that it is defiintely not first path you will follow in consideration tree, it is highly doubtful (why did it generate primes at all xd?) and time-consuming. If you are a two times ACM champion, spent whole contest not touching all other tasks and be lucky then maybe you are able to solve it. Otherwise be prepared for rating going down by >=100 for getting 0 pts (cause you didn't have time for other problems). That is fine task, but because of what I listed I do not consider tasks demanding some experiments as a good fit for 75 minutes TC. And out of that many people one of them getting main right idea, but lacking a lot of details and whole implementation is not really what you should aim for :P.
I know that estimating difficulty of tasks is in general hard, but those two were like total killers in my opinion being both very hard to come up with and time consuming. I haven't seen such hard tasks as those two in a long while and surprisingly they were both posed in a shortest out of all competitions :P.
And yeah, I agree trying to solve hard is not completely ruining your chances for getting very good position, because of that funny scoring system (which I like). At least that's fine :) (but getting at least good position is harder).
I don't know how many TCOs you have done, but I have always encountered some of the hardest problems I have seen at this competition (not coincidentally, most of my sharp rating drops are TCO rounds). The usual distribution is:
So there's a strategy element in that you have to choose if you're very skilled or fast. It looks bmerry was very close, if he had solved it then the scoreboard would look as I'd expect.
If I'm going to complain about one thing, it's that medium was too easy -- 30 people competing for speed meant that you didn't have any time to think, you had to solve it almost as you read it. Score distribution of 3A (1 hard, 4 medium) looks much better. Remember only 4 people can qualify.
Solving hard in 70 minutes is worse than solving easy and med, each in 20 minutes. To make Hard "guaranteed ticket to finals", organizers should set it to more than 1000 points.
How to solve 250 ?
Choose two letters (not necessarily different) and remove all other letters from the two strings. If the two strings are not equal even after removing everything else, then it means those two letters cannot be part of the result together.
This should give you a way to build a graph of letters in which two letters have an edge between them if they can't be used together. The answer is the size of the maximum independent set of this graph (in other words, the biggest subset of this graph such that there is no edge that connects letters inside this subset).