


Hi everyone!
I would like to invite you to participate in September Clash at HackerEarth. The contest is scheduled to start at September 10. The contest will last for 24 hours so everyone should be able to find some time to comfortably participate.
There will be six tasks in the problemset. Five of them are standard algorithmic problems with partial solutions allowed — you get points for every test that your solution passed. And the last task is an approximate problem — your score for this task depends on how good your solution is compared to the current best solution.
RomaWhite is the author of this problemset. He is an experienced contestant and problem setter so you can be assured of a high quality problemset.
I was working on the contest as a tester and editorialist, and I personally found the set very interesting. I hope that everyone from beginners to experienced contestants will be able to find some problem that challenges and interests them.
As always, belowthebelt was a great help, and I would like to thank him for taking care of all the technical aspects of contest preparation.
While problem solving is rewarding enough on its own, there will be some added incentive for you to do well.
Top5 of leaderboard will receive some nice prizes:
$100 Amazon gift card + HackerEarth T-shirt
$75 Amazon gift card + HackerEarth T-shirt
$50 Amazon gift card + HackerEarth T-shirt
HackerEarth T-shirt
HackerEarth T-shirt
Good luck to everyone — hope to see you at the top of the leaderboard.
UPD1: Contest is now over. Final test case generation for approximate problem is being done and leaderboard will be finalised soon. Editorials have also been released for all problems.
UPD2: Additional cases for approximate problem have been added and problem has been rejudged. Leaderboard is now finalised. Congratulations to the winners and thanks to everyone for participating.
The top 5 are:







The contest begins in 10 minutes. Good luck, everyone. :)
12 hours down. 12 more to go. There is still plenty of time to climb to the top of the leaderboard.
I've always wanted to ask, do you send multiple t-shirts to people that are in top 5 repeatedly? Also, thanks for the problems! I really liked KGCD.
How to solve KGCD?
Well, first of all it's obvious that gcd(a, b) = gcd(b, a - b), so a pair of numbers (a, b) is good if and only if after we do steps from the kgcd procedure, we reach a pair of numbers (a', b') with a' > 0, b' ≤ 0 such that a' + b' = gcd(a', b'). Now obviously gcd(a', b')|a' + b' so we need only to find pairs of numbers (a', b') such that a' + b'|a' and a' + b'|b', because it's equivalent to a' + b'|gcd(a', b'). But a' + b'|a' ≡ a' + b'|a' - (a' + b') ≡ a' + b'|b'. So the only condition we need is that a' + b' = d, where d is some positive divisor of a', so the good "ending" pairs are of the form (a', d - a') = (k * d, d - k * d), where a' = k * d.
Now, a crucial observation is that using the kgcd procedure, the pair of numbers form long "linear" chains that do not intersect (a, b) - > (b, a - b) - > (a - b, 2b - a) - > ... - > (x, y), that's because we can reach pair (x, y) only from (x + y, x) directly. So we can partition pairs of numbers in equivalence classes by their "ending" pairs, that is the pair (x, y) with x > 0, y ≤ 0. Now by the above obsevation, we are only interested in pairs of the form (k * d, d - k * d) for some d and k. If we look at the chain that starts from these kind of pairs and go backwards, then they look something like this (k * d, d - k * d)
< - (d, k * d) < - (d + k * d, d) < - (2d + k * d, d + k * d)
< - (3d + 2k * d, 2 * d + k * d) < - (5 * d + 3k * d, 3d + 2k * d) < - ...
So the first pair is (d, k * d) which is a good pair(easy to see), and then as we continue we get an infinite list of good pairs with the first number bigger than the second, except of the first pair.Now, to make the explanation shorter, each pair is of the form (Fn * k * d + Fn + 1 * d, Fn - 1 * k * d + Fn * d) so if we fix n, k, d we've got ourselves a pair. Now for a fixed n we need to find all k, d with Fn * k * d + Fn + 1 * d ≤ N (it's enough, because the second number will always be less, except the first pair (d, k * d) which we count separately). So if we range d from 1 to N, we get that we need to find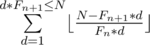 which can be done in O(sqrt(N)) using an well known technique. In the end the total complexity of O(logN * sqrtN) per test because fibonacci numbers grow exponentially(I think).
which can be done in O(sqrt(N)) using an well known technique. In the end the total complexity of O(logN * sqrtN) per test because fibonacci numbers grow exponentially(I think).
The code is really short: http://ideone.com/flvne6
Can you explain this well-known technique? That's where I got stuck during the contest.
You can look here: http://math.pugetsound.edu//Inversion.pdf
It's quite different from what is needed in this problem, but the main part is Lemma 1 in the paper.
Thanks a ton. Your reply was super helpful!
Editorial for KGCD should be available on the website.
Can someone please explain the problem "Perfect Permutations"...
It can be solved using generating functions. Let f(n, k) be the number of permutations of {1,2,...,n} with k inversions. Let the generating function be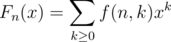
Now consider a permutation with n + 1 elements. Let i be the position of n + 1 in it. Then, the number of inversions containing n + 1 is n + 1 - i. So, we get:
So, using F1(x) = 1,we have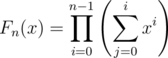
Now, since k < = n, as given in the problem,
Next we need two theorems:
We have to find the coefficient of xk in Pn(x)Qn(x), which can be done in O(k)
This is pretty much what the testers solution (i.e. my solution) does. The setter (RomaWhite) however had a quite different solution that did not use generating functions, and instead relied on inclusion-exclusion to find the answer. You may refer to the editorial to see that solution described.
The approximate problem hasn't been rejudged, yet. Do you have any estimates on when this will happen?
And regarding the approximate problem: I really liked the problem. It seems pretty complex and in a way it's a pity that it was used in a 24h contest instead of a multi-day one (e.g. the Circuits series). I feel that there are many aspects of it which I didn't have time to explore/understand (including understanding the generators, which I just used for generating local tests, without having time to understand their logic).
Regarding approximate problems in general: Please continue providing the source code for the test case generators and regenerating the test cases after the contest. This is the only way to judge solutions based on their quality, instead of how well they "overfit" the test cases.
And finally some general suggestions, based on my experience (this is my opinion only): If you're going to only use 50-100 test cases for judging the problem, there's no need to include a huge variance in the test cases (e.g. large intervals of choosing the parameters, etc.). With large test case variance, it means that the final test cases will contain only a few test cases of each "class"/"type". And what you want is to have more test cases of the same "type", in order to avoid that some solution is just lucky/unlucky on some cases of this type, but has a different behavior "on average" for the cases of that "type". A simple example regarding the problem from this contest could be to have smaller ranges for choosing M, N and K (so that most cases are similar in regard to this, but different regarding the way the matrix values are generated).
I don't like this problem, because its result depends only on 2-3 tests with big value of k. It could work with another scoring function or another generator or by calculating final score for each test separately.
Ah, I didn't really have much time to look at the actual scores on the original 50 test cases. Locally I tried to minimize the sum of (diff1/1 + diff2/2 + ...) and didn't really compute actual scores according to the scoring formula. Anyway, this is another point in favour of not having some parameters range too much across tests (in this case the K parameter), because the class of tests with large K was very small, and luck (or bad luck) on these test cases can influence the final result a lot.
What I liked about the problem was that it wasn't "easy". Up to the end of the contest I could still come up with improvements and I'm sure I was very far from anything close to optimal. In fact, an interesting thing about the problem is that given more time, my solution would be able to keep producing better scores on most of the test cases. I believe this is also true for your solution — I saw the "relax" function, which is quite similar to mine. Given more time, it would have probably "relaxed" the values much more, thus improving the final score.
I read your code and didn't understand what are you doing there. Could you provide brief explanation?
We are expecting remaining tests to be generated on Tuesday, and rejudging should happen as soon as the new tests are made.
Two of my most recent submissions from the contest have been in "Rejudge" mode for many hours (the last one and the 3rd most recent one). What is going on? At this point it will probably not make too much of a difference in the rankings (I think that my best submission was already rejudged), but it's worrying to know that some of the submissions will randomly not be rejudged on the final test cases.
PS: I posted the same comment on the problem page, but maybe there's a higher chance of getting an answer here.
Sorry for not replying on the problem page. I had forwarded your message to the site admin after seeing it on the problem page but forgot to reply.
I am sure the issue will get resolved soon (I am not sure how long myself, but as soon as I know I shall share).
UPD: Problem appears to be fixed now.