


Hi, everyone!
Russian Code Cup 2016 is over, the problems for the Final Round were more difficult than usually, but the participants didn't give up. The champion is Gennady Korotkevich tourist, the second place winner is Vladislav Epifanov vepifanov, the third place winner is Nikolay Kalinin KAN. Congratulations to the winners, the complete results are at the RCC web site http://russiancodecup.ru
Before proceeding to the tutorial, we would like to thank Mail.Ru Group for organizing the tournament and providing the prizes, and the judges from ITMO University for problems. Chief judge Andrew Stankevich andrewzta, judges Vitaly Aksenov Aksenov239, Nikolay Budin budalnik, Dmitry Filippov DimaPhil, Borys Minaiev qwerty787788, Ilya Peresadin pva701, Grigory Shovkoplyas GShark, Artem Vasiliev VArtem, Nikolay Vedernikov Niko, Ilya Zban izban.
And now the short tutorial. To get more details, you can read the programs of the judges solutions, published at the official site http://russiancodecup.ru together with the official tests.
Probably the easiest way to solve the problem is greedy. Sort people from the first line by increasing of their stamina. Give them tickets in this order, each time using the place which is furthest away from the other line. After that try to assign people from the second line to the remaining seats by sorting people by stamina and seats by the distance.
The time complexity of your solution must not exceed O((nm)2), however using std::set one can get a solution with complexity of O(nm log(nm)).
Let us divide the graph to biconnected blocks. Each block is either a bridge, or a cycle. Our goal is to remove one edge from each cycle, so that the number of remaining colors were maximum possible.
Let us build a bipartite graph, one part would be blocks, another one would be colors. For each block put an edge of capacity 1 for each color of an edge in this block (make multiple edges, or bigger capacity if there are several edges of some color). Add two vertices: source and sink, add edges from source to blocks, if the block is a cycle of length l, set its capacity to l - 1, if it is a bridge, set its capacity to 1. Add edges from color vertices to the sink of capacity 1.
It is quite clear that size of the maximum flow in this graph is indeed the answer to the problem.
As a final note, the judges know the solution that runs in O(n) and requires no maximum flow algorithms, challenge yourself to come up with it!
The solution is constructive.
- First let us use backtracking to find solutions for all n, m < 5, it is also better to precalculate all answers, in order not to mess with non-asymptotic optimizations.
- Now m ≥ 5.
- Let us put asterisks from left to right, one row after another. When adding the new asterisk, we add 4 new L-trominoes, except the first asterisk in a row that adds 1 new L-tromino, and the last asterisk in a row adds 3 new L-trominoes. Let us stop when the number of remaining L-trominoes k is less than 4, or there are less than 5 free squares in the table.
- Now there are two cases
- there is a free row
- thee is no free row
- If there is a free row, we stopped because k is now less then 4. So:
- k = 0: the solution is found
- k = 1: if there are already at least 2 asterisks in the current row, put the asterisk in the beginning of the next row, if there is only 1, put it in the end of the current row
- k = 2, k = 3 — similar, left as an exercise.
- If there are now free rows left, one can see that you can only add k from the set {0, 1, 2, 3, 4, 5, 6, 8, 9, 12, 15} L-trominoes.
- And finally there is also the special case where the size of the board is 3 × m, m ≥ 5 and k = 2 * (m - 1) - 8 — in this case the first column should be left empty, and the rest of the board must be completely filled with asterisks.
First let us consider all paths from the starting square to the finish one. Let us say that two paths are equivalent, if each obstacle is at the same side for both paths. For each class of equivalence let us choose the representative path — the one that tries to go as low as possible, lexicographically minimum.
Let us use dynamic programming. For each square let us count the number of representative paths that go from the starting square to this one. When the obstacle starts, some paths can now separate. The new representatives will pass this obstacle from above (it will be to the right of them). So we add the sum of values for squares below it, but above any other lower obstacle, to the value for the square right above the obstacle.
To overcome the time and memory limits that the naive solution with O(nm) memory and O(nm2) time complexity, we use segment tree for range sum queries with mass update, running scanline and events "start of an obstacle", "end of an obstacle". This leads to the solution with O(m) memory and O(n log m) time complexity.
First let us consider a slow solution. Let us find a condition for each number k after what number of seconds Borya can distinguish it from the given number. Let us look at their initial encoding. Increase both numbers by 1 until the encodings are different (or one of the numbers needs more than n digits to represent in which case the beep allows Borya to distinguish the numbers as well).
Now there are two main ideas that allow us to get a better solution. First, we don't have to check all numbers. We only need to check numbers that differ from the given number in exactly one digit.
Second: to get the time when the numbers can be distinguished we don't need to iterate over all possible values. We just need to try all digit positions and all values for that position, and check only moments when the digit at the position will first have this value in one of the numbers.
So the complexity is now polynomial in n and since n ≤ 18, it easily fits into the time limit.
We give the outline of the solution, leaving technical details as an excercise.
First note that the answer will always use min(k - n, 0) subarrays with maximal sums. Sof let us find the sum of min(k - n, 0) maximal subarrays, elements that are used in them, and the following min(k, n) subarrays. We can do it using binary search for the border sum, and a data structure similar to Fenwick tree. For the given value of the sum this tree must provide the number of subarrays with greater or equal sum, sum of their sums, and the set of the elements of these subarrays. It should also allow to list all these subarrays in linear time complexity. This part has time complexity O(n log2 n).
Let us now describe how to solve the problem in O(n2 log n). Let us try all values of x — the number of subarrays with maximum sums that we will use in our solution (there are O(n) variants, because top min(k - n, 0) subarrays will definitely be used). Let elements with indices i1, ..., im be the ones that are not used in these subarrays. Now we must add k - x segments that would contain all of these elements. Note that each of these k - x segments must contain at least one of these elements, and no two segments can have a common element among them (in the other case the solution is not optimal). These observations let us greedily choose these k - x segments in O(n log n) and the final solution complexity is O(n2 log n)
To optimize this solution, we keep segments [ij + 1; ij + 1 - 1] in the ordered set. When we iterate over x and increase its value, we remove some of the ij-s, and recalculate the required values for the affected segments. After that we must take k - x maximal values from the set, so since there are O(n) changes in total, this part now works in O(n log n).






Can we not show tutorial on a home page? There are people who plan to participate virtually (including me) and even if they do not plan to read it, some keywords like "FFT" or "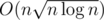 may be noted unintentionally.
may be noted unintentionally.
I roughly understood the tutorial of Problem C, but could anyone tell me how to prove that there is no other special cases except the case that the tutorial mentions? And how to prove the correctness of this solution? Thanks a lot :)
I have doubt about the tutorial of Problem F.It says that the answer will always use min(k - n, 0) subarrays with maximal sums.However,there may be several subarrays which have the same value.Certainly,how to choose them make a difference on the answer because they cover different elements.Could anyone tell me how to deal with it?Thanks.:)
Bump. I have the same question :)
If some pair of subsegments have same sum, it doesn't matter, which of them you will take in "k - n" (k > n) set. Let's see, why:
Let's sort all subsegment by decreasing of their sum (we don't care now about subsegments with equal sum). Suppose, we didn't take first k - n segments, and x (x ≤ k - n) is 1-based index of first subsegment which is not in optimal answer. Obviously, there are k - x + 1 segments in answer with indexes bigger than x. We can see that k - x + 1 ≥ k - (k - n) + 1 = n + 1. We can always choose one subsegment from ≥ n + 1 segments so that other ≥ n segments cover whole array (suppose we can't: every segment covers some index in array that is not covered by any of other segments, but we have n + 1 segments and only n values in array). Let's delete this segment from our answer, and add segment with index x to answer. We didn't lose property that our set of segments cover whole array, and we didn't decrease sum of our segments: segment with index x had greater or equal sum than segment that we deleted from our set.
So, if there is an optimal answer, we showed that there is an optimal answer with any k - n subsegments with maximal sum, without worrying about subsegments with equal sum.
Thanks for your reply.:)But I have another problem to solve.I can get the elements that are covered by subsegments whose sum is bigger than a specific number in O(nlog).Then I need to keep a priority queue to find the next biggest subsegments when enumerate how many maximal subsegments are used.So if every subsegments has the same sum,I have to solve it in O(n^2log).Is there any better way to solve it?
You can do that faster than in O(n2log) if you, for example, sort segments by tuple <sum[l..r], r, l>. Suppose there are x (x < k) segments with sum > y for some y, and there are > k segments with sum ≥ y. Indeed, there can be a lot (about O(n2)) subsegments with sum equal to y, so it is not easy to enumerate n segments that we need. We need just to skip first k - n - x segments with sum y, and then you can take segments with sum y one by one, because we will do that only n times.
In order to skip first segments we can use some data structure that can add new integer into structure and answer 2 types of questions: how many integers less than given are there in the structure, and what is i-th integer in structure. It can be done by fenwick tree (built on sorted prefix sums), or by advanced C++ STL data structures, like this.
When we have such data structure, when we fixed r bound of current subsegment, we need to ask how many integers equal to s[r] - y are there in our structure (because s[r] - s[l - 1] should be equal to y). If we can add them all to "k-n" set, just skip all segments with this r. Otherwise, you need to skip first k - n - currentSzeOfKnSet, and enumerate next few segments. Here you will need to know i-th integer in the structure.
Has anyone received RCC2016 t-shirt yet?
Yes, and honestly you should fell yourself happy if you haven't received it yet.
Can someone teach me how to solve B with a complexity of O(n) ? I just spent an hour to figure out the Maxflow algorithm...
For problem B, Can someone please explain, how Dinics algorithm( O(EV^2) ) is being used even when n = 10000
Why is it not giving TLE?
Max-flow is O(V) since all edges to sink have capacity 1, thus the whole algorithm is actually O(EV).
I have a slightly different solution to Problem A. Proof is at the end in comments :)
89634185