


Всем привет!
Завершился Russian Code Cup 2016, задачи финала оказались очень сложными, но участники не спасовали. Победил Геннадий Короткевич — tourist, второе место занял Владислав Епифанов — vepifanov, а замкнул призовую тройку Николай Калинин — KAN. Поздравляем победителей, официальные результаты финала на сайте http://russiancodecup.ru
Перед тем как перейти к разбору задач, хочется поблагодарить Mail.Ru Group за организацию турнира и призы, жюри из Университета ИТМО за подготовку задач. Председатель жюри Андрей Станкевич andrewzta, члены жюри Виталий Аксенов Aksenov239, Николай Будин budalnik, Артем Васильев VArtem, Николай Ведерников Niko, Илья Збань izban, Борис Минаев qwerty787788, Илья Пересадин pva701, Дмитрий Филиппов DimaPhil, Григорий Шовкопляс GShark.
Наконец, разбор задач. Мы приводим краткий разбор, отправляя за деталями к кодам решений жюри, опубликованным вместе с официальными тестами на сайте http://russiancodecup.ru
Эта задача решается жадным алгоритмом. Давайте отсортируем людей из первой очереди по тому, сколько они готовы пройти. И будем их поочерёдно расставлять, выбирая каждый раз место следующим образом: среди незанятых мест, до которых он может дойти, выберем то, которое наиболее удалено от второй очереди (точки с координатами (0, m + 1)). После распределения мест для первой очереди, мы сортируем людей из второй очереди и жадно расставляем их по свободным местам, начиная с минимального.
В задаче проходили грамотно написанные решения с асимптотикой не более O((nm)2), которые соответствуют описанию этого жадного алгоритма. Если пользоваться сетом, то асимптотику можно сократить до O(nm log(nm))
Разобьем граф на блоки — циклы и мосты. Нужно из каждого цикла удалить одно ребро, и при этом оставить в графе максимально много различных цветов.
Построим двудольный граф, в котором левая доля — блоки, правая — цвета. Из блока проведем ребра в каждый цвет, который есть в этом блоке (если цвет встречается несколько раз, проведем несколько ребер). Из цветов ребра в сток. Из истока ребра в блок, если блок — мост, то с пропускной способностью 1, иначе с пропускной способностью на 1 меньше длины цикла. Несложно видеть, что максимальный поток в этом графе и будет являться ответом.
Так же в этой задаче есть решение, не использующее потоки, и работающее за O(n), предлагаем придумать его в качестве упражнения.
Задача решается придумыванием конструктивного алгоритма.
- Для упрощения разбора случаев для всех n, m < 5 запустим полный перебор. Здесь, чтобы избежать неасимптотических оптимизаций и уложиться в TL, стоило сделать предподсчет.
- Теперь, не умоляя общности, можем считать, что m ≥ 5.
- Начнем расставлять звездочки подряд по таблице (по строчкам сверху вниз, в каждой строке слева направо). При добавлении каждой звездочки (кроме крайних) добавляется 4 новых уголка. При добавлении звездочки в конец строки добавляется 3 новых уголка, в начало — 1. Прекращаем процесс как только k становится меньше 4 или как только свободных клеток в таблице остается меньше 5.
- Дальнейшее развитие событий делится на два случая:
- осталась свободная строка
- не осталось свободной строки
- Первый случай. Раз осталась свободная строка, значит мы прервались, потому что k стало меньше 4. Тогда:
- k = 0: ничего добавлять не надо, все сошлось
- k = 1: если в текущей строке поставлено уже ≥ 2 звездочки, поставим звездочку в начало следующей строки, а если нет, то в конец текущей
- k = 2: если в текущей строке поставлено уже ≥ 3 звездочки, поставим звездочку во второй столбец следующей строки, а если нет, то в предпоследнюю клетку текущей
- k = 3: если в текущей строке поставлено уже ≥ 4 звездочек, поставим звездочки в первый и третий столбец следующей строки. Если поставлено три, поставим во второй столбец следующей и в предпоследний текущей. Если две — в начало следующей строки и в пред-предпоследний столбец текущей. Если одна — ставим звездочки в m - 1 и m - 3 столбцы текущей строки (нумерация с нуля).
- Второй случай. В таблице осталось 4 свободных клетки, куда можно поставить звездочки. Несложным перебором случаев можно вывести, что, ставя звездочки в эти клетки, можно получить следующие значения k: {0, 1, 2, 3, 4, 5, 6, 8, 9, 12, 15}. Разбор этих случаев остается читателю в качестве упражнения.
- Также стоило не забыть про случай прямоугольника 3 × m, где m ≥ 5 и k = 2 * (m - 1) - 8 — в этом случае надо оставить первый столбец пустым, а все остальные полностью заполнить.
Для начала рассмотрим все возможные пути из начальной клетки в конечную, в которых перемещение из клетки идет либо вверх, либо вправо, а также они не пересекают препятствия. Введем понятие класса эквивалентности путей. Пути находятся в одном классе, если они не являются различными по определению из условии задачи. В данной задаче требовалось найти количество таких классов.
Решать задачу будем методом динамического программирования. Для каждого класса будем рассматривать самый нижний путь: сумма высот клеток, по которым он проходит, минимальна. Состояние динамического программирования — это количество таких нижних путей проходящих через данную клетку. Тогда, когда мы встретим препятствие, все пути, которые проходят через клетки ниже его верха, могут разделится на два в случае, если выше них нет другого препятствия, которое помешает это сделать. То есть при обработке препятствия, в клетку над его верхней границей надо добавить сумму значений по клеткам ниже его верха, пути из которых имеют возможность разделиться.
Наивная реализация этого алгоритма требовала O(nm) памяти и O(nm2) времени, поэтому надо использовать дерево отрезков для оптимизации подсчета суммы при переходах динамического программирования, а также хранить не все поле, а только текущий столбец. Таким образом получается O(m) памяти и время работы составляет O(n log m).
Для начала рассмотрим решение, которое находит правильный ответ, но работает долго. Что обозначает, что Боря точно может определить, какое число было изначально? Это значит, что он может отличить его от любого другого числа. Поэтому рассмотрим все другие числа и для каждого найдем первый момент времени, когда его можно будет отличить от заданого. Для этого сравним, как кодируются два числа в первый момент времени. Если они кодируются одинаковым образом, то добавим к каждому единицу и сравним еще раз. Будем так продолжать пока два числа не будут кодироваться по-разному. Если вдруг одно из чисел не помещается на табло, то по условию задачи, Боря об этом узнает из-за громкого звука и, значит, в этот момент сможет отличить его.
Основная идея решения заключается в том, что нам не нужно проверять, что число можно отличить от всех 10n - 1 других. Утверждается, что если мы можем отличить число от такого же, в котором изменили ровно одну цифру, то можем отличить и от всех других чисел. Таким образом необходимо узнать первый момент времени, когда можно отличить число от 9n других.
Заметим, что эту подзадачу тоже можно решать быстрее чем за 10n. Для этого переберем разряд, по которому можно будет отличить два числа, а также его значение. После этого найдем первый момент времени, когда одно из чисел примет именно такое значение и проверим, можем ли отличить два числа. Таким образом получаем решение, которое работает за полиномиальное от количества цифр время.
Для начала заметим, что в ответ обязательно войдут min(k - n, 0) максимальных по сумме отрезков. Для решения задачи найдем сумму min(k - n, 0) максимальных отрезков и элементы, которые они покрывают, а так же следующие за ними min(k, n) отрезков в явном виде. Сделать это можно с помощью бинарного поиска по значению суммы на отрезке и структуры данных вроде дерева Фенвика: для заданного значения суммы дерево Фенвика поможет найти и количество отрезков с хотя бы такой суммой, и сумму отрезков с хотя бы такой суммой, и множество покрытых элементов, и перечислить все отрезки с такой суммой за их количество. Эту часть решения можно сделать за O(n log2 n).
Немного отвлечемся, рассмотрим, как можно решать задачу за n2 log n. Пускай мы перебрали x — количество максимальных по сумме отрезков в ответе (O(n) вариантов, поскольку min(k - n, 0) максимальных отрезков войдут в ответ обязательно). Пусть элементы с индексами i1, ..., im остались непокрыты, и нужно их покрыть используя k - x отрезков. Заметим, что каждый из этих k - x отрезков обязан содержать хотя бы один ij-й, при чем два отрезка не могут пересекаться по какому-нибудь ij-му. Можно отсортировать эти k - x отрезков лексикографически, и если l-й отрезок покрывает число ij, а l + 1-й отрезок покрывает ij + 1, то эти два отрезка либо пересекаются по какому-то подотрезку отрезка [ij + 1; ij + 1 - 1], либо не пересекаются по какому-то подотрезку отрезка [ij + 1; ij + 1 - 1]. Таким образом, если для каждого отрезка [ij + 1; ij + 1 - 1] выписать число, равное максимуму из его максимального подотрезка и минус минимального, то наилучшее покрытие — взять весь массив, но не взять минимальный префикс (до i1), минимальный суффикс (от im), и k - x максимальных чисел среди выписанных. Таким образом, решили задачу за n2 log n.
Чтобы соптимизировать это решение, можно хранить отрезки [ij + 1; ij + 1 - 1] в упорядоченном множестве. При добавлении нового максимального отрезка нужно удалить несколько ij-х, пересчитать в сете максимальные и минимальные подотрезки для затронутых отрезков (это можно сделать за O(1), зная максимальную сумму на префиксе и суффиксе подотрезка), и взять сумму k - x максимальных чисел из множества. Суммарно удалений ij-х O(n), поэтому вся эта часть работает за O(n log n).






Как можно было написать все 6 задач в течении двух часов? Неужели по 20 минут на придумывание каждой достаточно для такого набора? Даже если тупо набирать код каждой, участники вряд ли успеют сдать все.
Да похоже просто кто-то захотел, чтобы даже люди с красными никами почувствовали себя ничтожными в этом бренном мире, полном коварных задач и ехидных авторов.
Can we not show tutorial on a home page? There are people who plan to participate virtually (including me) and even if they do not plan to read it, some keywords like "FFT" or "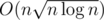 may be noted unintentionally.
may be noted unintentionally.
I roughly understood the tutorial of Problem C, but could anyone tell me how to prove that there is no other special cases except the case that the tutorial mentions? And how to prove the correctness of this solution? Thanks a lot :)
I have doubt about the tutorial of Problem F.It says that the answer will always use min(k - n, 0) subarrays with maximal sums.However,there may be several subarrays which have the same value.Certainly,how to choose them make a difference on the answer because they cover different elements.Could anyone tell me how to deal with it?Thanks.:)
Bump. I have the same question :)
If some pair of subsegments have same sum, it doesn't matter, which of them you will take in "k - n" (k > n) set. Let's see, why:
Let's sort all subsegment by decreasing of their sum (we don't care now about subsegments with equal sum). Suppose, we didn't take first k - n segments, and x (x ≤ k - n) is 1-based index of first subsegment which is not in optimal answer. Obviously, there are k - x + 1 segments in answer with indexes bigger than x. We can see that k - x + 1 ≥ k - (k - n) + 1 = n + 1. We can always choose one subsegment from ≥ n + 1 segments so that other ≥ n segments cover whole array (suppose we can't: every segment covers some index in array that is not covered by any of other segments, but we have n + 1 segments and only n values in array). Let's delete this segment from our answer, and add segment with index x to answer. We didn't lose property that our set of segments cover whole array, and we didn't decrease sum of our segments: segment with index x had greater or equal sum than segment that we deleted from our set.
So, if there is an optimal answer, we showed that there is an optimal answer with any k - n subsegments with maximal sum, without worrying about subsegments with equal sum.
Thanks for your reply.:)But I have another problem to solve.I can get the elements that are covered by subsegments whose sum is bigger than a specific number in O(nlog).Then I need to keep a priority queue to find the next biggest subsegments when enumerate how many maximal subsegments are used.So if every subsegments has the same sum,I have to solve it in O(n^2log).Is there any better way to solve it?
You can do that faster than in O(n2log) if you, for example, sort segments by tuple <sum[l..r], r, l>. Suppose there are x (x < k) segments with sum > y for some y, and there are > k segments with sum ≥ y. Indeed, there can be a lot (about O(n2)) subsegments with sum equal to y, so it is not easy to enumerate n segments that we need. We need just to skip first k - n - x segments with sum y, and then you can take segments with sum y one by one, because we will do that only n times.
In order to skip first segments we can use some data structure that can add new integer into structure and answer 2 types of questions: how many integers less than given are there in the structure, and what is i-th integer in structure. It can be done by fenwick tree (built on sorted prefix sums), or by advanced C++ STL data structures, like this.
When we have such data structure, when we fixed r bound of current subsegment, we need to ask how many integers equal to s[r] - y are there in our structure (because s[r] - s[l - 1] should be equal to y). If we can add them all to "k-n" set, just skip all segments with this r. Otherwise, you need to skip first k - n - currentSzeOfKnSet, and enumerate next few segments. Here you will need to know i-th integer in the structure.
----------------------
Получил сейчас вот это. Точно так и задумывалось? А то я футболку-то не выиграл
Аналогичная ситуация! Место на отборе: 380. Футболка уже пришла. Но вопрос всё же актуальный: футболки всем кто прошел на отбор или нет?
Has anyone received RCC2016 t-shirt yet?
Yes, and honestly you should fell yourself happy if you haven't received it yet.
Can someone teach me how to solve B with a complexity of O(n) ? I just spent an hour to figure out the Maxflow algorithm...
For problem B, Can someone please explain, how Dinics algorithm( O(EV^2) ) is being used even when n = 10000
Why is it not giving TLE?
Max-flow is O(V) since all edges to sink have capacity 1, thus the whole algorithm is actually O(EV).
I have a slightly different solution to Problem A. Proof is at the end in comments :)
89634185