


Tutorial is loading...
Автор задачи: MikeMirzayanov.
Tutorial is loading...
Авторы задачи: MikeMirzayanov, Kniaz.
Tutorial is loading...
Автор задачи: Kniaz.
Tutorial is loading...
Авторы задачи: MikeMirzayanov, Kniaz.
Tutorial is loading...
Автор задачи: Kniaz.
Tutorial is loading...
Автор задачи: Kniaz.
Огромное спасибо Пикляеву Мише (awoo) за перевод разбора на английский.






Very nice contest. Thank you <3
алгоритм Евклида за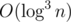 ???
???
Видимо в абстрактной модели, где числа в длинке и процессор не умеет их делить за О(1) :)
Там можно вообще убрать этот множитель, ведь все НОДы прекалькаются динамикой — в таком случае на подсчет одного уходит О(1).
Не смог удержаться... Уважаемый автор, если вы считаете, что сложность деления работает за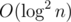 , то тогда учитывайте в асимптотике и сложность сложения, вычитания, умножения — они ведь тоже не за константу работают, а в лучшем случае за
, то тогда учитывайте в асимптотике и сложность сложения, вычитания, умножения — они ведь тоже не за константу работают, а в лучшем случае за  (кроме операции умножения). Но вообще такие оценки не очень сильно помогают, они скорее всего сбивают с толку. А вот для длинки — самое то.
(кроме операции умножения). Но вообще такие оценки не очень сильно помогают, они скорее всего сбивают с толку. А вот для длинки — самое то.
I think a typo in F: It should be (l — 1) / (y ^ (n — 1)) instead of l / (y ^ (n — 1)).
Can someone explain O(1) solution of problem C?
I just found this accepted solution 23972771 of problem C implementing a O(1) algorithm. It might help you.
After one T=n*m(time period) you can consider all other time period as T'=(n-1)*m which will add 1 to the answer of middle rows and add 1 to corner rows alternatively.One can derive a closed from expression for the middle bottom and top rows after n periods.The botom row will be the minimum and middle rows the maximum after Total time=k*T'.Now all that is left is the remainder<T' which may influence the answer by 1.
Also I want to thank authors of B for creating test 17.
Задача C. М̶а̶к̶с̶и̶м̶а̶л̶ь̶н̶о̶е̶ Минимальное количество заданных вопросов одному ученику равно f(n, m), так как...
Во время одного периода его спрашивают один раз, и есть момент когда всех спросили по одному разу, а его нет. То есть если его спросили хотя бы один раз, то и остальных спросили как минимум один раз.
in problem D, how to check the following string (base 16)
101
because if we take greedily from the suffix, we will end up with 01, but we cant add 1 to make it 101 (>n)
Seems you have just answered your own question.
Whenever you can't take anymore numbers, you need to check whether your created number contains any leading zeroes, if yes delete them (and be careful not to consider a number consisting a single zero as leading zero).
Dynamic programming is usually associated with overlapping subproblems. The way solution for E is described may cause confusion...
That made think this solution was totally different from my solution, when it's actually pretty much the same. Anyway, really cool problem.
Can somebody explain editorial for Problem E . How dpmin is used for calculating the answer ?
Can someone explain the last part of editorial of E, how are we finding optimal values of dpF_x(the final weight of subtree of x) which should be between dpmin_x and dpmax_x by dpW, dpmin, dpmax
In general, problem E is a linear programming problem.
variables are the weight w of each edge. equations are p = old_p — old_w + w >= 0, w >= 1, p >= w of subtree, w <= old w.
we can use DP to split the equations to small groups by keeping the max w (dpmax) and min w (dpmin) of each subtree.
finding the maximum w is easy. but i run out of time to find the feasible solution (the dpW to reconstruct the tree).
very nice problem.
(1 WA for
positiveweight)Hey guys I m not able to understand greedy approach behind DIV 2 D and also how it can be done with DP ? .please help me out!
The number formed in a given base will never exceed base.Proof using contradiction:Consider you have done maximal matching as given in editorial.Now if you try to increase the length of right component by 1 (reducing left by 1) the netchange will always be positive as left component will be multiplied by base^(exp+1) and right component by base^(exp).
I did it by an easy to prove brute-force DP: Store the given number $$$k$$$ as a string $$$s$$$. Consider $$$dp[i]$$$ as the minimum decimal number, which when converted to base-$$$n$$$, is equal to $$$s[i]s[i+1]s[i+2]...s[n]$$$.
Now to get recursive relation, you have to use the greedy fact that there is a monotonic relation between power of $$$n$$$ and $$$dp[i]$$$. It's proof is very easy. For the exact recurrence, you can view my submission.
87005109
Кажется тут небольшая опечатка
Максимальное количество заданных вопросов одному ученику равно f(n, m), так как меньше всего раз спросят ученика сидящего на последнем ряду за последней партой.Должно же быть
Минимальное количествоДа, спасибо, исправлю.
Вопрос по задаче D.
Может кто-то объяснить, как из предложения:
Следует следующее предложение:
Имеется ввиду, что мы доказали, что для очередной строки лучше всего отрезать наибольший возможный по длине суффикс.
Хм, мне казалось тут было доказано, что разбиение числа k без последней цифры не хуже, чем просто числа k (по количеству разбиений).
Аналогичный вопрос. Доказан был довольно очевидный факт, что для более короткого числа ответ будет не хуже, чем для длинного. А вот как отсюда следует выгодность взятия наибольшего суффикса я что-то не понял.
Could anyone please tell me why the difference between the max and min number of questions in C would be more than 1? If k>n*m then the entire matrix can be filled and whatever is left, that is, k%(n*m) would be filled in order, so at max the difference between max and min should be 1?
The order of asking the rows looks as follows: the 1-st row, the 2-nd row, ..., the n - 1-st row, the n-th row, the n - 1-st row, ..., the 2-nd row, the 1-st row, the 2-nd row, ...
Notice that the 1st and the last row gets asked way less time.
Can someone explain how to find the feasible solution for problem E? I just do not get the answer from the Editorial. Please.
E can be solved by a simple greedy algorithm too. Observe the fact that it is always beneficial to reduce the edges that are at a lower depth before the ones above them. You will reduce the weight (and strength) of an edge only when all the edges in its subtree are at their minimum possible values. You can use DSU on tree technique to implement this and BIT/segment tree to keep track of current sum of weights in any subtree.
This is my code for the same. Complexity is O(n*logn).
Good day to you,
I've solved this int very similar manner — but with slight differences.
I made dfs, while pushing all nodes to "priority_queue" [priority on time of visit === lower first]. I sometime had to merge those queues, for which I pushed the bigger into the lower [this shall be O(Nlog(N)) amortized, if I'm right].
For updates, I — instead of fenwick — propagated this information ONLY to parent [who could do it to its parent when processed ... and so on], making a "STOP" at node/edge, which is being "helped".
Anyway I think the overall idea is very similar
Seems my solution is similar to yours, but I just use deque instead of priority_queue and have O(n) complexity. just need to merge those nodes whose weight can be reduced
see my code
UPDATEA: My time complexity is O(nlogn) because of the merging node approach.
I tried a similar approach to yours, using DSU on tree. However, I don't understand why a fenwick tree is needed, though without it I get WA. Could you shed some light on that?
This is my implementation (from my understanding of the solution): 24814935
The weights of the edges do not stay constant. They keep changing. So I used a Fenwick tree to get the current sum of edges in any subtree.
Thanks for the reply. It's still a little unclear to me why I can't use simple tree DP (I'm getting WA with it). I have already considered that the weights of the edges don't stay constant and I thought tree DP can handle that. My approach was to take the edge with largest visit time and reduce the weight and strength of that edge accordingly. Then, I take away the difference between original weight and new weight from the sum of weights in the current subtree. I'm not sure how a fenwick tree is different from simple tree DP for this purpose. What's wrong with my approach? Can you provide a counterexample? If you're confused with the explanation of my approach you can look at the code above (hopefully it's not too messy XD) Thanks in advance.
Even though I couldn't solve it during the contest, I really liked C which in hindsight is elegant when you properly see it's periodicity.
How this submission got accepted for problem B : http://mirror.codeforces.com/contest/758/submission/23954612 .
The answer for this input RB!YRB!! is 0 0 1 2 , But that submission is give 0 0 1 0 output for that input . How this got accepted ? Am i wrong ? Or dataset was weak . RB!YRB!! solution is RBGYRBGY so R=0 B=0 Y=1 G=2 .
It is guaranteed that in the given string at least once there is each of four letters 'R', 'B', 'Y' and 'G'.As many people here asked for more details on the solution to problem E, here you go.
Can I get the data sets of any problem???
Here's a much simpler solution for F: For each number $$$x \in [l, r]$$$, compute its signature, by factoring it as $$$p_1^{a_1} p_2^{a_2} \ldots p_m^{a_m}$$$ and reducing $$$a_i$$$ modulo $$$n-1$$$. The solution is just the number of ordered pairs of different integers with identical signatures. This works for all $$$n \geq 2$$$.
thanks for such a fast reply