


Hi Codeforces!
The Codeforces Round 397 by Kaspersky Lab and Barcelona Bootcamp (Div. 1 + Div. 2 combined) is going to be held tomorrow at 8:05 UTC!
This round is organized in collaboration with Hello Barcelona ACM ICPC Bootcamp 2017 and supported by Kaspersky Lab.


Over 100 students from 17 countries and more than 25 universities such as Cornell University, University College London, École Normale Supérieure, University of Tokyo, Saint-Petersburg State University and Moscow Institute of Physics and Technology gathered in Barcelona to train together for the ACM ICPC Finals.
For eight days students have been solving problems, listening to lectures, learning and making new friends. The training schedule is intense consisting of full-length practice contests, interleaved with one-day educational modules on topics we find especially important. Every contest is followed by an in-depth explanations of every problem and technique encountered in all forms.













It is hard to convey the atmosphere of the event in words. It is said, a picture is worth a thousand words and here is a selection to give you some idea of this fantastic bootcamp. You can see more pictures from the event here and here.
The round authors are Endagorion, ifsmirnov, zemen and Arterm. The round is combined for both divisions, will contain seven problems and last for three hours. Good luck!
UPD: The scoring is 500-1000-1250-2000-2500-3250-3500.
The contest is finished. We hope that you enjoyed it. Congratulations to the winners!







Super-Duper Unusual Time !!! I shall miss going out with my valentine but give this contest.CF contests are much better :)
Too bad I must go out with my valentine. Wait... I don't have girlfriend....
CP is my valentine.
For someone unrated and "somebody new", you know too much about usual and unusual timings. :D
A contest at 8 in the morning is obviously unusual for anyone who is new ... I liked the comment by Bedge. Dating sites should consider the last option . :P
I have not a GF But I have CF So, cout<<"Happy Valentine CF!!!! Let's go for ..... .... (contest)" <<endl;
Please change the contest time if possible.
why ?
I'm a programmar. I have no life, no valentine.
don't hate me. the day is for love.
Well I don't have any Valentine's day plans. So I guess I will be here :D
Finally I'm not alone in Valentine's Day.
I am with several thounsand people doing a CF round ^_^
pache mali nakon baw :))
Valentine's day special ;)
OK you didn't mention in the Announcement so i guess i can ask the usual question and get an answer, Is it rated???
It's a Codeforces round and they are always rated unless something does not go wrong during the contest. They don't have to mention it everytime.
Over 100 students from 17 countries and more than 25 universities such as Cornell University, University College London, École Normale Supérieure, University of Tokyo, Saint-Petersburg State University and Moscow Institute of Physics and Technology gathered in Barcelona to train together for the ACM ICPC Finals.
this means some users might have seen the problems before...
We are writing this contest at the same time :)
Phew, finally a Valentine where I won't be alone (body pillows don't count haha) and depressed! Love you guys! :)
Hello,
Me and my friend both want to compete, but we're in the same house, so we have the same IP.
Will we get banned, or is it allowed for two people to compete, even though they share the same IP address?
are you using the same computer ??
Nope.No problem, but never copy your friends code :).
We obviously won't.
Thanks a lot for the answer!
Face each other across the table so you can't see each other's screen, but you can make snarling faces when she hacks your solution.
Bullet for my valentine...:)
wow naice music man yo are real gurmet in music just owned my \M/ RESPECT \M/ man
Never steal anyone's girlfriend (code)
:D :D
CF is my girlfriend,i love cf~~~~
A codefoces a day keeps the girlfriend away. :)
Contest for my valentine :p :D
See, everyone's talking about girlfriends and not boyfriends...
feminist triggered
Feels bad when the contest starts 15 minutes before all of your lectures ends :/
And the lecturer decides to end the lecture 15 minutes earlier
cf is my wife :) <3
Not a good time for Indian college students. In between the second half classes.
missing classes bro, coz cant miss a cf round ! :)
Lol, me too. XD
a nice reason to bunk afternoon classes
I ran away from school lessons to write contest. Hope that is not in vain :)
Me too!
Expect stories about Valentine in statements :D
Sorry to ask it but I didn't find the answer! Is it rated?!
yes, it is rated
Each and every contest, I hope of learning new ideas of problem solving, though I feel bad when I end up solving nothing in the contest; hoping today that changes I think it's going to be exciting
All the best everyone, and thank you codeforces
You could see predicted rating changes on my service.
Вы можете узнать предсказание изменения рейтинга на моем сайте.
How can I hack? Who has test for C?
5 6 4 Answer should be -1
I hacked a solution using 11 17 10
Your website predicts that I'll become an expert. If it won't happen, I'll sue you for losing my nerve cells =)
LOL That's why I don't believe in predictions, sometimes they just give you false hopes
congo :D
Does your service update the ranks after system tests? Cause I'm no longer rank 1070.
Edit: Never mind, it fixed itself.
multiple 502 Bad Gateway issues when trying to submit solutions really screwed my time penalty :/
This contest in a nutshell:
The roses are red,
The violet's blue.
Your pretests are passed,
I will hack you!
Admins be like: it's not fair some contestants have fast internet connection while the others have slow one, so let's make CF slow for everyone
weakest pretests ever
i agree D pretests was insane
Now I'm worried. How does the wrong solution look like? =)
check 3
3 2 3
there exists an answer for it
Phew... I'm good at this one.
My stupid wrong solution for D passes pretests:
1) if f[i] = const, so g[i] = const m = 1, h[1]=const
2) f[i] = i, , so g[i] = i, m = n, h[i] = i.
otherwise -1.
That was my solution too, I was shocked when it passed pretests.
I submitted one ridiculous solution to D that's dubious and very obviously incorrect. It passed pretests so I thought it was correct then got hacked last 5 minutes :(
Does anyone know what was pretest 10 of E?
Me right now
How to solve D?
For problem F I was trying to solve it by Mo's algo but kept getting RE on pretest 3. Can problem F be solved by Mo's Algo?
The O((n+q) sqrt(n) log(n)) algorithm using Mo's algorithm is too slow. Optimizing it to O((n+q) sqrt(n)) should be fast enough, but I don't know if that is possible. I solved F with a O(n log(n+q) log(10^9)) algorithm.
i have O((n+q) sqrt(n)) and it tle.
Code
I believe most G including mine will fail. For example try 11, 13, 17, ... (all primes except for 2, 3, 5).
All three accepted solutions for G failed with this case:
Can the judge's solution handle this?
What is the answer for this case?
I don't know, but everyone got TLE or RE.
I've been waiting for a couple of hours to see: 1) what is the official solution to the problem 2) whether it works on this test case or not Why isn't anybody answering? My guess is that your comment hasn't been seen yet and might not be seen at all.
I'm sorry to admit that all of our solutions time-out on this case as well.
We misjudged 2, 3, 5, 7, ... as the hardest case for the small-prime part of the solution. In fact, including 2 greatly reduces the number of reachable masks. If we knew about the truly hardest case, we would probably reduce limitations on m to 25 or 30.
We offer our apologies to the contestants who saw this case through and didn't submit a solution because of this. Still, we tend to think that this issue, as critical as it is, shouldn't make the round unrated since the number of affected competitors was comparably small. The tests were weak, but they were all correct.
This mistake is a good lesson for all of us to be conscientious when preparing problems.
Do you think the problem is still solvable by modifying your solutions under the given constraints?
If yes, this is not a big deal (the problem is just about weak tests and it sometimes happens). The round should be rated for sure.
If no, it means the problem is incorrect, and the round should be unrated.
I am currently investigating if the problem is still solvable. I will write about my results here.
Thank you.
By the way, except for this issue, I generally liked the round. The simple solution for E (see the midpoint of the diameter as a root) was nice, and the key idea for G (generate masks for small primes, do some DP for large primes) was also nice.
I wrote a solution that carefully reduces the size of mask as we approach to the big primes ( ≥ 29): you can see that you don't need to track the middle bits in the mask, only the number of "empty" positions in the middle and masks of size m - p from both ends.
This approach reduces the number of states to 2·3·5·...·23 + 222·18 + 218·22 + 26·34 from which the second part is already OK, and the first part is in fact small if there is 2 among primes, and is small enough to be solved via bruteforce (around 108 states) if there is no p = 2.
This solution runs in 2.5 seconds.
Nice, now the solution looks good.
Where can we view this solution, it does not seem to be under KAN's submissions?
I think he means Endagorion's submission.
Endagorion's submission 24707929 Gives ML on 82-test when re-submission 24718304. I try 3-4 times, always ML.
What's changed???
Seems like new tests are added.
The original submission passed cases until 81 and got AC.
While the new data set consists of 103 cases.
Made a huge (rating) leap forward this contest and I agree, incorrect problem(s) => unrated.
I think more importantly, problem writers should always have a proof/argument that a solution is correct, or at least a concrete bound on the worst-case runtime which is close to the allowed time-limit.
Having weak tests or unoriginal problems is one thing, but having incorrect author solution (and what currently seems to be an essentially unsolvable problem) is a completely different issue.
My hope is that not only you guys, but all problemsetters on CF can learn a lesson from this incident.
As for myself, I am glad that I started on problem G but testing my solution gave major TLE on the primes from 3 to 37, I ended up not submitting anything and just going to sleep.
I totally agree. However, when it is about tests that meet a particular format (like the masks obtained in this case), it is enough to prove that the solution is alright by simply testing the worst cases (and I think that's what they wanted to do). The big problem was that they didn't prove that the worst case was the above mentioned. Anyway, generally, solution must have a practical or theoretical proof that they work properly all the time (and this practical proof was incomplete). I really liked the problem and had the right idea and got TLE on the last test. I hope that, in the eventually that no solution is found, they will make the right decision to make this contest unrated. Even if they do not, I enjoyed the contest and the ideas, but the big problem was the intention that authors had to increase |S| as much as possible which I think wasn't needed to make the problem interesting.
Just curious, is there a significantly easier solution when let's say |s| <= 20? That's pretty easy to bound, but was wondering what solutions you were trying to prevent by setting |s| to be larger.
I think that this situation is a result of two mistakes:
1) It seems you set constraints based on "experimental worst case running time". I don't like when there is no specific reasonable bound on running time and constraints are set so high because it seems running time is in fact better because "we will not reach many states because blah blah". IMO mistake was not "not finding worst case test", it was not bounding running time in other terms than "worst time on tests we invented".
2) I really like following rule "set constraints as low as possible so that you are sure no unwanted solutions pass". What were you trying to achieve setting constraints so high? Cutting off 2^m solutions which don't use any weird heuristics? I think additional heuristics is not what makes solution valuable and that this was not worth distinguishing. If goal was to not allow 2^m memory then 40 is still unnecessarily high.
Can problem F be solved by MO's algorithm ?
I had an idea but didn't have enough time to implement it
You can solve it with MO's algorithm. But I'm not sure if it will be fast enough. My solution TLE'd on pretest 7.
I passed pretests with it — but I had to optimize it a lot (like using Fenwick tree instead of sets) to make it work in 1.7 (my first code works around 40 seconds). Will see if it passes system testing.
Upd. Nope, it doesn't pass :)
Can someone please tell how to solve D ???
It can be seen that for any x in [m] h(x) is a fixed point of f, and that all h(x) are unique (otherwise the first equation cannot be satisfied). Let's make m equal to the number of fixpoints of f, and h(x) = x'th fixpoint. Obviously, for any x that is a fixpoint both equations are correct. If we take x that isn't a fixpoint, then f(x) must be a fixpoint in order to satisfy the second equation. If it isn't, or m = 0, then answer is -1.
1) Given h(g(x)) = f(x), as x is in [n] and same is for h(x): h(g(h(x))) = f(h(x)) -(1)
2) Given g(h(x)) = x, using this in eq 1, h(x) = f(h(x)) -(2)
3) For some i, f(i) = ai Comparing with eq 2, i = h(x) ai = h(x) Hence, ai = i Basically, m would be the count of such numbers such that f(i) = i. This will easily help us in calculating h(x). Example, say this holds for indices 2,4 and 7. So m=3 and h[1] = 2 h[2] = 4 h[3] = 7
4) Now, using h(g(x)) = f(x), g(x) can be calculated. h inverse can be stored in an array. While calculating g(x), if h inverse (from the calculated h inverse array) is 0, there is no corresponding value of g(x) that satisfies the equation and hence solution does not exist.
slow connection vs I_love_Tanya_Romanova :(
What is expected solution of F?
My Mo's algorithm(NsqrtNlogN) gave TLE on pretest 7.
My MO's worked in roughly 500ms.
Is your solution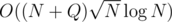 ? I got TLE with that (as expected)
? I got TLE with that (as expected)
yes but i used bit instead of segtree so it works pretty fast
what is bit? I know, that it's binary-indexed tree, but for what purpose does it exist? I don't know anything about it
he probably means usual fenwick tree
I also passed with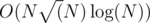 in around 2sec.
in around 2sec.
Did you have logN factor or you managed to get rid of it somehow?
edit , it failed systemtest
Should have stress-tested it :)
I hope, it's not NsqrtNlogN. My NsqrtNlogN solution also gave TLE on test 7.
My idea is that: For each position i, find index i < j1 < j2 < ... such that a[j1] ≥ a[i], a[j2] ≥ a[i] and a[j2] - a[i] ≤ (a[j1] - a[i]) / 2,... Easy to see that each position we consider at most log(109) next positions. Then we can sort queries and using two pointers and fenwick tree.
Can you explain it a bit more please? What will we do after finding j1, j2, ...?
For me, finding j1, j2, ... is the hardest part. The remaining part is simple. When answering query [l, r], we just consider pairs l ≤ (i, jk) ≤ r (multiplying each a[i] by - 1 and do same things to get other pairs). It can be solved offline by fenwick tree.
Thank you. I got AC with it. 24722019
What is the proof for this solution by the way?
Suppose we are only considering pairs (i, j) such that i<=j. It can be shown that for some fixed i, the only pairs we need to consider the ones j1, j2, j3.. which are found out as explained above.
Suppose we have calculated j1, j2, j3 and now we want to find j4. Then j4 will be the smallest index to the right of j3 such that arr[j4]>=arr[i] and arr[j4]<=(arr[i]+arr[j3])/2.
For all values in the array v to the right of j3 such that v>(arr[i]+arr[j3])/2, observe that abs(arr[j3]-v) will always yield a better answer than abs(arr[i]-v). So, we don't need to consider such values v with respect to i (they will be considered for some other i).
Similarly, we repeat for all j1, j2, j3... such that arr[j2]<=arr[i] and arr[j2]>=(arr[i]+arr[j1])/2, and so on. So there are a total of n*logC important pairs we need to consider, where C is the maximum value possible in the array.
Code: 24726286
Thank you, now I got it.
May I ask how to find j1,j2,...?
Round 397 for hacks :"D
Most silliest problem A ever :D
But, people's like me will overthink it without reading problem statement carefully.
I happened to have discussed with darry140 about problem F beforehand, and he came up with an O(NlogNlogC + QlogN) solution, though I never implemented it.
http://tioj.infor.org/problems/1905 (Chinese)
Unfortunately coding complexity exceeded for me.
Hacking party :)
My idea for E was to find the centroid, then recursively solve from it. It failed in test 3, but I think it is due to implementation error. Could anyone verify if the idea itself is correct, though?
You should find midpoint of diameter, not centroid.
You are usurping ideas of others, Swistakk. :D
Not really, I said few comments below it is not mine idea :P.
I think it can be solved just by simulation the merges. As we must greedily merge the tree if we want the final graph to be a path.
At least I got Accepted in E by simulating the merges (Code : 24663567).
Anyway, I was surprised to know that the solution can be something related to the midpoint of diameter (Thanks Swistakk :D )
It won't always be midpoint of diameter. You have to check if the subtrees are mergable.
Actually I also simulated merges in an ugly way (that's why I have 6 unsuccessful attempts and terrible time), I learned that diameter trick from friends ;p.
Do you mean that the midpoint of diameter must be a point on the final path? I cannot think of a way to prove so. (Or it is some other useful trick?)
I would be appreciated if you could let me know more about it :D
What does it even mean that some point lies on final path? If we forget about folding paths in half which needs to be done at the very end, if we root tree in that midpoint of diameter all merges happen within subtrees and don't involve root. This is because merging doesn't change height of any subtree.
That awkward moment you realize half your code deals with the centroid and you didn't even notice.
Wrote a bottom-up queue starting from leaves and then realized the last node to exit it is indeed always the centroid.
Wow I'm really glad to have the same solution as yours. But my solution only missed
while(ans%2==0) ans/=2;to be correct though :( link.Could have been my first time being able to solve E :'(
Btw, how to prove that it will be okay to just keep dividing the even answer by 2 ? I couldn't realize it in contest
If you have a path of length 2n then you can choose the midpoint of the path and merge two paths of length n.I missed it in the contest too, it's really a pity.
How to solve D?
My solution was this -
Either f(x) = h(x) = g(x) = x, or f(x) = h(x) = constant.
The answer exists if and only if f(x) = x or f(f(x)) = f(x) for all x.
Oh! I must've calculated it wrong :(
That condition can be simplified to just f(f(x)) = f(x) for all x
edit:solved
To see that there exists a solution if, and only if,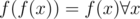 , apply g to both sides of the second condition:
, apply g to both sides of the second condition:
And apply h to both sides:
Now, represent f as a directed graph with edges of the form (x, f(x)). If you draw some vertices and edges, you'll see that all "components" have the same shape: a bottom-up tree of height two (root and leaves). Draw a hull labeled [n] around the graph.
Beside the set [n], draw a second hull labeled [m] with some vertices inside. If you draw some edges from [n] to [m] (labeled with g) and from [m] to [n] (labeled with h), you'll see that all g-edges coming from one component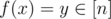 must end at the same vertex
must end at the same vertex 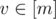 and the h-edge from v must end at y.
and the h-edge from v must end at y.
Here is the formal construction. Let's denote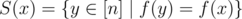 .
.
Let g' and h' be such that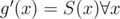 and
and 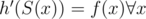 . Also, let
. Also, let 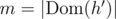 . Any unique assignment of the first m natural numbers to the elements of
. Any unique assignment of the first m natural numbers to the elements of 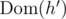 will produce functions g and h that satisfy both conditions, if
will produce functions g and h that satisfy both conditions, if 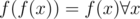 holds. Check that to complete the proof! (
holds. Check that to complete the proof! ( )
)
This construction is implemented here in O(n) time: 24681642
In Problem E, why the answer of the first sample is 3? Why can't we fold again to make a path of length 2?
Ah, I misunderstood...
The number of vertices becomes even. You can not fold around a particular vertex. The lengths will not be equal ( 1 and 2 ).
What was the intended time complexity for F? My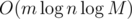 (where M = 109) solution got TLE in system tests as well as most of the other solutions that passed the pretests. IMO there is no point in not including the maxtest in pretests for problems like this.
(where M = 109) solution got TLE in system tests as well as most of the other solutions that passed the pretests. IMO there is no point in not including the maxtest in pretests for problems like this.
+1
My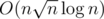 got TLE on pretests (as I expected), so there were some big tests. However it seems there were no biggest ones or pesimistic ones in some sense what can also be deduced from ratio of AC on pretests / AC on systests, which I really don't like, so fully +1 to this post.
got TLE on pretests (as I expected), so there were some big tests. However it seems there were no biggest ones or pesimistic ones in some sense what can also be deduced from ratio of AC on pretests / AC on systests, which I really don't like, so fully +1 to this post.
My O(MsqrtN) just got TL 22.
Now I got AC in 2401ms after adding one if-statement that should optimize the constant factor. 24669254
My code was accepted without any change after resubmitting... 24663826 24675644
Intended complexity for F was in fact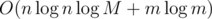 , which, in fact, does not differ from yours much (the editorial will be published soon). However, my model solution works in 600 ms on each case, and the another jury solution with dynamic segment tree (
, which, in fact, does not differ from yours much (the editorial will be published soon). However, my model solution works in 600 ms on each case, and the another jury solution with dynamic segment tree (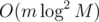 fits into 2 seconds as well. So we decided to set the TL to 3 seconds trying to block
fits into 2 seconds as well. So we decided to set the TL to 3 seconds trying to block 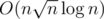 solutions from passing and having in mind that any reasonable implementation of a segment tree will pass.
solutions from passing and having in mind that any reasonable implementation of a segment tree will pass.
More, I decided not to include a "pessimistic" test to pretests. There were some random tests with n up to 30000 and a maxtest, in which, however, all queries were short. This was mainly done to check not for TL but for mistyped \texttt{maxn}. As far as I see, most of incorrect -ish solutions failed on a special tests constructed against these kind of solutions, and none of these tests were included in pretests intentionally.
-ish solutions failed on a special tests constructed against these kind of solutions, and none of these tests were included in pretests intentionally.
I apologize to everyone whose asymptotically correct solution didn't pass final tests because of this. Maybe it would be a good recommendation to run your solution via a custom test before submitting; hopefully, it is usually not that hard to generate a maxtest for a range query problem, and doing so saved me from TL several times.
Time limit is set in a way that it's unclear whether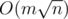 solution should pass or not. Maybe you didn't even consider such solutions? Or what was the intention? For example, mine gets to test 22 and I believe it will pass with some optimizations.
solution should pass or not. Maybe you didn't even consider such solutions? Or what was the intention? For example, mine gets to test 22 and I believe it will pass with some optimizations.
If there is a variety of possible complexities to a problem like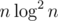 ,
, 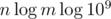 ,
, 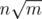 ,
, 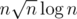 etc etc than I think one should always include maxtests. I think that it is not cool to make a raffle who gets AC among people who don't have optimal complexity and let many solutions pass on pretests and let them TLE on systests only. I don't see any profit of not including maxtests other than being able to say "Haha, we are problemsetters and you naive contestant thought that n sqrt(n) log n will pass because you passed pretests, but we are smarter than you and include maxtest in systests only". I think it should be transparent whether submitted solution works fast enough on maxtests, otherwise we randomize results.
etc etc than I think one should always include maxtests. I think that it is not cool to make a raffle who gets AC among people who don't have optimal complexity and let many solutions pass on pretests and let them TLE on systests only. I don't see any profit of not including maxtests other than being able to say "Haha, we are problemsetters and you naive contestant thought that n sqrt(n) log n will pass because you passed pretests, but we are smarter than you and include maxtest in systests only". I think it should be transparent whether submitted solution works fast enough on maxtests, otherwise we randomize results.
Btw, very nice problem :).
I don't agree. Those with suboptimal complexity can and should check themselves how their solution works on maxtests designed especially against their solution. I think there should be a test with maximum possible value of N to check array sizes and to fail quadratic solutions (those people shouldn't be able to lock a problem and see correct solutions because maybe it's their second account and they want to cheat).
Getting AC with almost good complexity isn't a raffle — it just depends on the speed of your code. It's up to you to implement it well. Adding strong pretests won't help make your code faster. It can only tell you "your code is too slow, you should make it faster" what you should be be aware and afraid of at the moment you're starting coding.
And by the way I also don't like situations with several similar complexities. There always will be some participants that will be close to TL from some side what adds randomization (it isn't a raffle though).
Question for problem setters on CodeForces, TopCoder, AtCoder, etc: Is there a standard on these sites about setting the time limits? (whether it be an actual rule or just a guideline). I only have experience writing problems/judging for ICPC in a couple regions, and in those, there is no definitive rule, just a general rule of thumb: the time limit is set to >3-5x the slowest solution that is the intended algorithm without heuristic optimizations (this includes the slowest Java solution for ICPC, which sometimes makes the time limit large...), and any solution that is deemed "too slow" via complexity analysis should have a runtime of at least 2x the time limit given a reasonable amount of optimization to the code (e.g., fast I/O, simple heuristics that don't change the time complexity--like break'ing loops early, etc.).
Is there anything similar for these sites? I know that on Polygon, they warn when a program marked TLE is within 2x the time limit or an AC solution is more than 1/2x the time limit, so maybe those are the constraints?
Where is the editorial?!
can anyone explain problem c ?
Lets assume that a is less than b. If it's not, we just swap them.
The answer is -1 if (a < k) and (b isn't divisible by k). Why? Because player A can't win (he has a<k points) and after player B won as much as he could (he won exactly b/k times), he is left with (b mod k) points. And both players don't have enough points to end game.
Otherwise, answer is (a/k) + (b/k).
Let player A win first round with score k, and player B with score (b mod k). Than let player B win with score k and player A with score (a mod k).
Let's call scores after second round as A2 and B2. A2 and B2 are divisible by k. This is so because we subtracted (a mod k) and k from a, same for b. So the answer is 1 + 1 + A2/k + B2/k = a/k + b/k.
Ask if something isn't clear to you :)
Upd2: here is table for k = 3!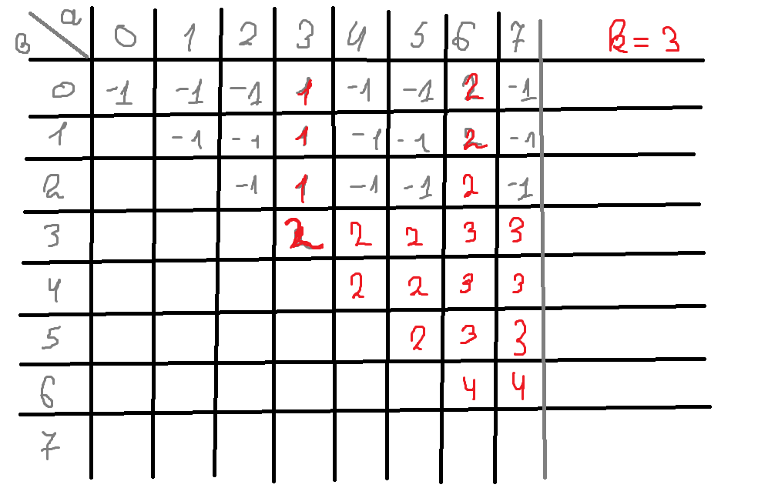
"And both players don't have enough points to end game"
That's the part that's not clear to me. If k=137, a=138, b=136 why is answer -1?
See that a>k and b<k, so we can assume that a won a set, and b did not win any for sure.
But if that was the case, the game should have ended on the 137 th (k-th) point, but a is 138 (a>k), thats why it's impossible to have a game like that.
The key point is :there exists optimal solution in which the number of non K: 0/0: K sets < 3
Why? Because if there exist > = 3 non K: 0 / 0: K sets, then at least 2 of them, denoted as S1 = K: a, S2 = K: b, must be won by the same player, and we can rearrange S1, S2 to S1 = K: (a + b)%K, S2 = K: 0, [S3 = 0: K] which is no worse than previous solution with reduced number of non K: 0 / 0: K sets.
Where can I find more problems like C?
C is adhoc... It won't be easy to find problems like this.
Unfortunately codeforces doesn't have that tag yet. But there is another platform/site that allow you to search for problems tagged with adhoc. I'm not sure if I'm allowed to mention the site name here (since it's a competitor to codeforces :p )
Having the adhoc tag doesn't mean that the problem will be like C. Just means that the problem is as random as problem C.
Does O(n.sqrtn.lgn) works for F?
Why can't I submit now given that system test is already over?
When will you open this round for practice?
Why my solution for F using kd-tree in O(nsqrt(n)) but got TLE?
Which ACed solutions is "random"?
I thought the solution is based on the data is randomized.
However,I have found that I can't make the number of the pairs (now,i) more than O(n).Sorry for my rude remarks.
UPD:One of my friends prove hat the number of the pairs (now,i) is O(nlog) at worst.= =
Let's congratulate Merkurev. He won contest and became Legendary grandmaster.
What is the best way of solving F? I'm thinking segment trees for some weird reason.
I'm pretty sure that if you can't solve A during the contest you won't solve task similar to this F next time. At least for 2-3 years
WTF!!
I got TLE for O( n log(n) ) solution for problem E, 24663759
test 47 is the star shaped tree. Your solution is probably quadratic on that case.
You're right , Thanks.
I did a stupid thing to calculate node's degree , got AC with 24670094.
I solved similarly, just with dfs, here's my code: 24669733. I didn't checked it out fully, but is degree(x) fast enough?
Yes ,degree(x) is the problem.
I used BFS but in unusual way, I went from outside (starting from leafs) to inside. Code is not so readable, but if you want, you can check it out.
Second time I am using BFS on trees in this way, and it really helps to make an implementation easier. I don't know if people already use it this way.
Where can we find editorial?
Btw, any ideas to solve problem F fast? The time limit is so tight for me.
Hey guys, have a way to show only div2 on standings? Because i maked a sheet with my positions on each contest.
Add all div.2 participants as friends
I cant understand the impossible case for problem C . Can anyone explain how the answer is impossible for test case 2 . Problem C.
When ( (a < k && b < k) | (a % k != 0 && (b / k) == 0) | (b % k != 0 && (a / k) == 0) is true.
(a < k && b < k) -> Not even 1 game is possible.
(a % k != 0 && (b / k) == 0) -> A has won (a / k) games and now have a % k remaining score, but B didn't won any.
(b % k != 0 && (a / k) == 0) -> B has won (b / k) games and now have b % k remaining score, but A didn't won any.
PS — The answer for test 2 is -1 because not even 1 game is possible. [For a game to be possible, there must be exactly 1 winner].
for
6 14 14 ?
How ans is 4 ?
Suppose by a=14 i made 2 set ( i assume that each set is consist of k serves) ,
b=14 i made 2 set ( i assume that each set is consist of k serves) .
Now there are a=2 remaining (a%k==2) , b=2 remaining (b%k==2) ,
Now if i make a set with a+b=4 serve , here in this set there is no winner . So ans should be -1 .
Is there any condition that each set's serve number should have to constant ?
Total for A: 14 points Total for B: 14 points
Testcase #8 in E is very tricky, I spend last hour on finding bug that weren't even there :(
CodeForces contests are very hard for me:( like please!
That's because you're not smart enough. Keep training and one day you'll definitely beat tourist (no).
I’ve managed to solve problem F with Mo’s algorithm.
Let’s assume that an is a permutation of n. (For general case you can first discretize an.)
Let . For queries with length ≤ size (r - l + 1 ≤ size), we can solve them with an
. For queries with length ≤ size (r - l + 1 ≤ size), we can solve them with an 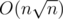 DP.
DP.
For those with length > size: let p = i * size + size - 1 and q = i * size. Assume that now we are answering queries with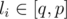 .
.
The key is to discover that if we just deleted x with this function,
then we could insert it back with this function.
(This trick is used in Dancing Links.)
And my solution is:
Step 1: build a list with elements [ap...an],
Step 2: delete [an...ap + 1] (invoke del(ai) with descending indices, the order is important!),
Step 3: insert [ap + 1...an] back.
When doing step 3 we can also maintain an array mem[i] which stores the answer of range [p, i].
Step 4: build a list with elements [aq...an],
Step 5: enumerate all queries j in descending order of rj,
Step 6: delete [arj + 1...arj + 1],
Then we perform the same operations
Step 7: delete [aq...ap - 1],
Step 8: insert [ap - 1...alj] back,
Step 9: insert [alj - 1...aq] back.
Notice when doing step 8 we can get the contribution of [alj...ap - 1], the minimum of it and mem[rj] is the answer to the query j.
Here we get a solution with complexity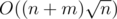 .
.
You may see my code 24667598 for the implementation details.
It's a solution with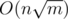 if you choose the size of each block carefully..
if you choose the size of each block carefully..
by the way, congratulations for becoming an IGM...
Thanks for pointing it out. I should have calculated the complexity precisely.
The overall complexity should be O((n + m)size + n2 / size). Therefore we should let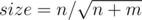 and the complexity becomes
and the complexity becomes 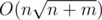 .
.
Also, you can easily optimize your implementation by removing pos array. You're welcome.
Problem F was awesome in my opinion. Natural statement and solution that is easy but at the same time very hard to come up with.
Can Anybody Explain the problem C ??? I am not getting the problem....
The sets are done and we have sum of two persons' scores. Output the maximum number of sets that could be happened.
i think the problems were highly enjoyable .... i had fun in this contest .... hope there will be an Editorial soon
I have solved problem F with single Segment Tree with fractional cascading. In fact it works a bit slower (545ms vs 483ms) than my solution without fractional cascading (as usual), but still faster than any other solution.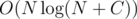 and other parts of code are obviously
and other parts of code are obviously 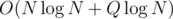 .
.
Interesting thing: function "update" is called not more than 60N times on each of the tests. So it seems to be
Idea of solution is next:
I sort all queries by R and answer on them like on "Query on suffix", adding elements of array one by one. I keep segment tree with next structure: Value of each leaf is a minimum difference for i-th element of array on current prefix. Value of inner vertex is a minimum answer on subrange. The core idea is to continue updates only when we can improve answer for current prefix. It's based on simple thing: if right son in Segment Tree has a better value then we can get in left, we don't need to update left, because all queries are processed on suffix. To check if I can improve answer, I also keep sorted part of array in each vertex of segment tree and search for nearest element in subarray for currently added element via binary search. This is the part which can be asymptotically improved by fractional cascading.
I think it's not worse than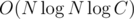 according to this comment. But as I mentioned before it works like
according to this comment. But as I mentioned before it works like 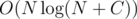 on testset of this problem. But maybe someone see the test, which can make my solution to work longer?
on testset of this problem. But maybe someone see the test, which can make my solution to work longer?
Hello MrDindows, could you please help me to understand your solution?
I saw your code without fractional cascading and I could understand most of it (functions
build(),main()andgetAns()), but I'm having trouble to understand functionupdate(). When you callupdate(1, 0, n - 1, curr - 1, a[curr], d);, what is the purpose of passing the position behind the current r (curr-1)? And what is the purpose of variabledpassed by reference?I know that immediately after
build(1, 0, n - 1);, the inner nodes will hold sorted arrays of their respective segments (fielda) and the actual answer for their respective segments (fieldans). So, now, if a query coincides exactly with a segment of an inner node, then the answer is just the fieldansof the respective node. But if a non-trivial segment is asked, then it's not easy to get the answer only with what we have so far. That's why you sort the queries and perform the updates one by one.But what exactly means to add a new element in your solution? What do we need to update in the inner nodes? I'm having trouble to understand this part... (which is basically the whole solution, hahaha)
From what I understood, the query is simply getting the smallest element from l to r. The update works like this: d is the best result so far. The update works from right to left so it remembers the best answer to the right of the position where you are on the update. If you can use some element in this range to get a better answer (something like abs(elem-a[cur])<d), you continue the update. Else, you simply update the best answer (d) and return on this line:
d = min(d, getAns(cur, l, r, l, to));
The idea is that you don't need to update every single position since you update the queries by increasing order of r, so the queries will always go on until the end so if you updated the later positions with a better answer, you don't need to update this position. You use curr-1 because you'll pair up a[curr] with some a[i<cur].
I've also used his solution and code to fully understand problem, so I'll try to explain from my perspective.
We are processing queries from smaller R's to larger. Let's say that we have done the following for all previous R': When we are at next R we want to check if a[R] can help us. What should we try to do? To check for all R's that are smaller of our current and see what is a[R] - a[someR]. But that will TLE. That's the point of segment tree, because we want do it now. We are saving in all leafs a[R] - a[leaf], and in inner nodes minimum of their children. Whenever we face new R we must update all leafs. Again, if we do that naively, (I mean leaf per leaf) that will TLE into oblivion. So here comes powerful update. Since R is increasing, we want to make better solutions as right as possible, because when we do query(L, R) we want to have best possible solution on that interval. We will update leaf that corresponds to a[R - 1] with a[R], while traversing through segment tree we can actually update all other nodes. First of all, we don't want to spend time updating nodes that can't make better solutions with current a[R] (that's the d part), so we are always checking that. Now the core idea: Some nodes don't need to be updated because query will never cover them.
now. We are saving in all leafs a[R] - a[leaf], and in inner nodes minimum of their children. Whenever we face new R we must update all leafs. Again, if we do that naively, (I mean leaf per leaf) that will TLE into oblivion. So here comes powerful update. Since R is increasing, we want to make better solutions as right as possible, because when we do query(L, R) we want to have best possible solution on that interval. We will update leaf that corresponds to a[R - 1] with a[R], while traversing through segment tree we can actually update all other nodes. First of all, we don't want to spend time updating nodes that can't make better solutions with current a[R] (that's the d part), so we are always checking that. Now the core idea: Some nodes don't need to be updated because query will never cover them.
Next level graphics
...[...x....y....]...
...L.............R...
On that picture X is value that is greater than y. Querying L..R will use only y, since x is obviously larger. We are using that logic in updating. Why would we update whole left subtree of current node (if we need to go in right) if we can't make our solution better with it? So when we must go in left subtree when updating, just go, but while going right, apart from updating right subtree, we will update only the rightmost leaf in left subtree to be sure that we are making better solutions on positions as right as possible.
You can also note that after segment tree initialization, we can't do classic queries to get information about solution on segment L..R. Let's say that solution on L..R will be made with L1..R1 and L2..R2, that don't overlap (segment tree query idea). We don't know about solutions with any number from L1..R1 with any number from L2..R2. That's why we must do all work described above.
I hope that this helps.
Could you please explain more about why it's not worse than O(NlogNlogC)?
Thanks for the round! I really enjoyed problems D and E! Couldn't solve them during the contest, but algebra problems are really fun and only one line was missing to get AC in problem E. Won't miss next time!
Can we have official editorial
editorial?
Recently I missed CF contest...
Can somebody please explain the dfs and dp on trees solution for problem E?
In the first place you root given tree in its center (middle point of diameter, which you find using dfs/bfs few times). Then you solve problem with dfs, starting at root(center):
for leaf node answer is 0
for non leaf — non root node answer is k if for all its children answer was k - 1
for root :
where i is maximal number such that 2i divides nominator. I'm not sure whether that's dp/dfs solution you expected, but that's more or less how I implemented it.
why the center ?
It is impossible to merge a path containing center inside (a1, a2, ... , ak can not be the center node). There are few cases to consider. To make things a bit easier let us assume, that in our tree there is unique center (edge-diameter is even and equal 2d). In following points by child tree I mean child tree of a center
if path we try to merge starts in a child tree A and ends in child tree B of depth < d there must be another child tree C of depth d to make diameter equal to 2d
there must be another child tree C of depth d to make diameter equal to 2d  one of nodes on path has degree > 2
one of nodes on path has degree > 2
if path we try to merge starts in a child tree A and ends in child tree B of depth d then
Still it is possible to merge using center as merge point (v could be the center node), but in the first place we must reduce each child tree to a single path (whole graph will be star like). Then if there are at most two different lengths of arms in this star it is possible to reduce whole graph to a single path.
I consider my proof writing rather far from perfect, thus any remarks and further questions are welcome (to point out what is ill written here and make me better proof writer).
From my understanding: Lets start with simple path. Now all the nodes between left unfolding and right unfolding are "contenders" for root. i.e., all the nodes which are not included in unfolding(outside of unfolding). Lets denote midpoint of current path be "m". Now if we perform a "left unfolding": with "m" being replicated: Midpoint of new diameter would be vertex on which unfolding is performed. else: New midpoint could be same vertex "m" or vertex on which unfolding is performed. Similarly for "right unfolding". In any case midpoint of diameter will be "outside" the unfolding. Now, It can be seen that further steps doesn't affect the midpoint. So, midpoint will always be outside the unfolding and thus can always be root.
I actually wanted any solution(no editorial). The tags on the problem said dp and dfs so I mentioned them. Thanks for the explanation. :D
Can't find the editorial.... Can someone share the link if it is out?
the editorial http://mirror.codeforces.com/blog/entry/50456
I hope official editorial will be posted soon.
http://mirror.codeforces.com/blog/entry/50456
Any idea why this fails for Div2 E ? http://mirror.codeforces.com/contest/765/submission/24705450
I have exact same problem 24699663.
center is not the only node v for which dist[v] == diameter/2
consider graph:
8
1 2
2 3
3 4
4 5
5 6
6 7
5 8
if you measure dist from 7, then both 4 and 8 have dist = 3, and only 4 is center
Thank You .
There can be up to two centroids! In this case, they are adjacent.
Best,
Mircea
would there be an editorial for this ?
You may find these useful:
This and this.
How can DP be used to solve problem E ?