


Hi, Codeforces!
Codeforces Round 402 (Div. 1) and Codeforces Round 402 (Div. 2) are going to happen on February, 26th, at 08:05 AM UTC. The round will run at the same time with Innopolis University Open, Olympiad in Informatics. Division 1 problems are the same as olympiad problems. Some of Division 2 problems are prepared by MikeMirzayanov, thanks to him.
The problems are developed by MikeMirzayanov, YakutovDmitriy, VArtem, FireZi, burakov28, pashka.
We hope you enjoy the problems!
UPD:
problem scores for div1: 500 — 1000 — 1500 — 2250 — 2250
problem scores for div2: 500 — 1000 — 1000 — 1500 — 2000 — 2500
UPD 2: Congratulations to winners!
Top-10 (Div.1)
Top-10 (Div.2)







too bad, I can't do this round :(
Is it the time issue?
Actually no, I have some work to be done at the same time :\
.
how many problemset sir ?
see this
LOL!!
One problemsetter of each color
Now that's what I call justice
there are two reds, no cyan, no green, no grey and no white
Are you having Color Blindness :3
there are one grandmaster, and one international grandmaster
but it is the same color ;)
only women can see the difference between these two colors.
like this
This makes no sense, "green-yellow" is the shade of green farthest from yellow here...
You're still thinking in masculine color space.
Feminine color space has three dimensions. It's like the transition from flatland to 3-space; impossible to imagine unless you already live there.
VArtem is International Grandmaster and pashka is Grandmaster
sorry man there's no thing called completely justice in this world :(
Do you mean Sunday, 26th?
Is there any reason that recently Codeforces Contests are announced in short time before contest start time?
kind of a surprise :D
It's not only surprise but also sad for me. The contest time is quite close to my training contest in group.
In fact, I have moved the training contest time from Friday to Sunday because its original time overlap to CF #401...
Deleted
Nice time !
Wow! Another chance to get high rating! :3
it depends on your rank not on the difficulty of the problemset
I love it when there are contests on every 2-3 days. :)
I love it,too.But I find it's difficult.
It completely collides with Grand Prix of Wroclaw of OpenCup. Which one do you participate?
If I'm not wrong the Gran Prix starts just when the CF Round ends...
Grand Prix starts just when CF Round starts
Why did codeforces start holding its contests at such an odd times? Earlier it was used to be around 16:00 UTC.
Maybe because of this
The round will run at the same time with Innopolis University Open, Olympiad in Informatics.there is always a pole between you and things you love to do
this pole is my school :(
I'm not gonna participate in this round tomorrow
Its Sunday in India..So no School :)
actually in my country the weekend is on Friday and Saturday
as I said before.
there's no thing called completely justice in this world :(
I face the same problem :(
Five problems as usual ?
8:00 am GMT +6 is the best time!
Is it rated?
Is this the first time that the two divisions have different number of problems?
lol
No, but it's really rare. round #364
UPD : I didnt send that message,this guy send it with my account. I know that it is rated :D . pls stop down-voting me . my contribution was +3, but now -25 :'(
sorry
Hack for DIV — 2 B ???????
others bug :-"
Mine was
11001 3
Answer is 4.
How to solve Div2D?
Binary search
I did Binary Search.
can you explain a bit?
You binary search on the number of elements to delete from the string (just mark the indices in a boolean array). Then, if the string I'm looking for is a subsequence of the original string with modified characters then it's possible for her to continue playing so I try a higher value. If it isn't a subsequence then I have to try lower. Checking if it's a subsequence can be done in O(n).
Suppose i is the answer then it is possible to construct the pattern for any value less than or equal to i. So we can form a sequence like TTTTFFFFF (t=possible f=not possible). We have to find the last T where it is possible to construct pattern. Which can be done through Binary Search.
25045586
Binary search(O(log(n))) on length of permutation and check till which index there exist a subsequence 'p' in it (in O(n)). Hence resultant complexity is O(n*log(n))
Hey, shouldn't we include the time it would take to delete the elements as well?
Also, are you using some other method for deleting? Because otherwise, the deletion itself would take O(n) time.
You don't actually have to delete elements from the string, replace characters at required indices with some special character and check for subsequence(which can be done in O(n)). Refer to my code to get the idea.
Cool. Thanks!
I think It can be done using hashing + BIT or hashing + Seg tree.
Link: String Hashing
If you read this you can link strategy to this problem. Of course, binary search is easy one solution but It would be worth to learn so it can be applied many problems like this( Sometimes it is easier to implement String Hashing than other Solution).
PS: Accuracy of Solution depends on Probability of collisions.
Really cool binary search.
Ideas on D div.2?
binary search
Take l=0 r=n-1 . DO binary search. Change the first (l+r)/2 elements as say '_' and check if p is a substring of t — http://www.geeksforgeeks.org/given-two-strings-find-first-string-subsequence-second/.
If yes make l=(l+r)/2+1 and ans=(l+r)/2 else r=(l+r)/2-1.
Display ans
binary search ... imagine that you have a query that answer if the current S has a subsequence T. This "function" is: true true true.... false false false.. You just have to find the last occur of true. You have to find the optimal prefix of the array permutation that answer TRUE on this query :) ! I hope it helps you ! Sorry for my bad english!
.
0.0
Hey guy stop it please
Usually I'd use a "strict <" in function "cmp". It could be the problem. Just a hint for you to dive in.
However, please do not post your code everywhere, especially in unrelated posts.
share your code using idone or just give the link of your submission :| Dont spam the page
Seems like problem E's parsing is harder than task itself lol.
I think so. It cost me too much time.
How to solve it?
edit-Just figured it out.
I guess solving independently for each bit will work.
Handling the variables and parsing is the difficult part, yes.
I don't think so. You can use a map to point a variable to its declaration location in input, ignore the := operator and easily parse a binary string to an integer/boolean array.
I misread problem E. I could have solved it :(
problem was quite easy but parsing it was hard.
Parsing was not an issue in my case.
From problem E, how do you handle cases like this?:
3 5
a := 10100
b := a OR ?
c := b XOR ?
Notice that each bit for ? can be decided independently. So, for each column of bit, just try 0 and 1 and take the optimal one.
Oh. My train of thinking was along that line. Now I feel stupid :(
RIP Rating
For every bit in every variable, you should know it's value, for when the corresponding bit in ? is 0 and for when the corresponding bit in ? is 1. For example:
a = [[1, 1], [0, 0], [1, 1], [0, 0], [0, 0]]
b = [[1, 1], [0, 1], [1, 1], [0, 1], [0, 1]] (you calculate this using just variable a)
c = [[1, 0], [0, 0], [1, 0], [0, 0], [0, 0]] (you calculate this using just variable b)
E.g. the emphasized array in c means that if ? = "..0..", then c = ".. 1 .."; and if ? = "..1..", then c = "..0..".
I believe that a large number of chinese can solve Div2E, for a similar problem has appeared in NOI2014. The similar problem's chinese name is "起床困难综合征", you can find it on many websites. NOI is olympics in infomatics in China. Sorry for poor english.
Hey man... Don't do that!
(I've learned Chinese for years and the characters this man posted has nothing to do with "Olympics in Informatics in China". Don't waste your time on searching that)
LOL~ The Chinese characters are the name of the problem that is similar to Div2E mentioned by __stdcall.
I mean that, the problem's name is "起床困难综合征". You can submit the problem on this website. http://uoj.ac/problem/2
Sorry, my mistake...
But it's a really interesting title
That's also my fault. I have updated my comment in order to prevent from misunderstanding.
"Get up difficult syndrome."
How to solve Div1 C?? Thanks in advance :)
I used DSU on tree technique. Removing character at index p is equivalent to removing all edges at depth p in the trie. The hash of a vertex is the hash of the string formed when I go from the root to this vertex. For each vertex v, I store the hashes of all vertices in its subtree.Then I can easily find out the number of distinct hashes in its subtrees after removing edges from v to its children.
Code
the link is broken.Please check it
Fixed. :)
It's working for me. If it's still not accessible to you, just google "DSU on tree codeforces".
Okay, so, at some point, you will have a set S with the hashes of all vertices in the subtree rooted at v (using DSU on tree). But how exactly do you remove the edges leaving v? I imagine that you pass through each element of S applying some hash-related operation to remove the first edge, then you'll get a new hash and you'll put it in another set S'. After this pass over S, the size of set S' is the answer. Is that it? If yes, what is the hash-related operation to remove the first edge? Thanks for the help!
Suppose I am at vertex u. And the heaviest child is v. After I have processed v, the global map I use already has the hashes of all nodes in the subtree of v. I need to check other subtrees of u. Let us consider node w in some subtree of u (let that be x) such that w is not the heaviest child of u. Now, I need to calculate the hash of w assuming that the edge u->x does not exist. This is equivalent to calculating the hash value of w assuming the edge u->x has the same character on it as the edge u->v. I do exactly this in my code. Then the number of nodes which remain after deleting the edges from u will be equal to the number of nodes in the trie-1 (because it includes v too which must be subtracted).
The above explanation is very specific to my code.
I solved it in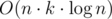 , where k = 26, the alphabet. Solution idea is pretty simple – "Let's try and merge all child tries of the current node and see what total size we get". You can merge two tries in time proportional to the size of lesser one, and it is well known that in worst case each node will be in
, where k = 26, the alphabet. Solution idea is pretty simple – "Let's try and merge all child tries of the current node and see what total size we get". You can merge two tries in time proportional to the size of lesser one, and it is well known that in worst case each node will be in  mergers.
mergers.
So, the algorithm:
Could you elaborate why it is O(n k log n)? I thought of the same approach, but wasn't sure it would work.
I've tried to implement the similar approach but failed with the "rollback" part, could you please give some detail on that?
One of the simplest ways: every time you change any variable, push back {what was changed, what value it had before} into a vector, then reverse it and apply the same operations backwards.
Thank you, I will try that)
I practically copied your code and submitted it without the nodes' size verification (i.e. the swap(u, v) in merge()) and the runtime was 200ms. Any idea why?
i thought your solution will fail on a test with binary tree where every left edge is "a" and right is "b" (quite a few vertices will be merged then), but it didn't. however, i also ran solutions of top-10 and only half of them where fast enough on my computer, some even getting 40s+.
I almost solved problem E (DIV 2). but time ran out. I am such a slog. Treat each bit independent of other m-1 bits!!!
you are not alone
How to solve problem D in Div.1?
any ideas? What was the approach?
I read some AC codes and found this excellent idea: The operation is reversible and so we can try to turn both the current configuration and the desired configuration into a configuration like:
UUUUUUUU
DDDDDDDD
UUUUUUUU
DDDDDDDD
UUUUUUUU
DDDDDDDD
and then you can combine the two sets of operations to get the final operations. Sorry for my poor English..
the idea works because each time we try to fix the top-leftmost block to be LR, if the block is originally UD then we fix the next block to UD and turn, and if the next block is LR then the block below it is LR(done) or UD and so on... eventually we will have a "ladder" and this ladder cannot continue indefinitely, so there will always be solution.
Was it intended to fail MNlog(N) solution on Div 1B?
You have
O(M*N*log(N)*len(var))~= 1/2 * 10^9. That's a lot to STLI changed map to unordered_map after the contest and got AC. How do you tell when unordered_map is faster?
unordered_map is generally (quite a bit) faster if nobody is attacking your hash (to cause collisions) and when you have sufficient buckets (check out c++ stl reserve()).
The only thing that made problem E tougher was the input format. Takes loads of time to write the code to process the input variables.(String splitting n all). I missed solving it by 2-3 mins due to this.
The crux idea of the problem was not that difficult according to me. Complexity of N × M × 2 is good enough.
http://mirror.codeforces.com/contest/778/submission/25048949
My solution to D.
I just keep changing every LR to UD, and then every UD to LR, recursively, until it is done.
Is this solution correct?
It's not the solution that we expected, I don't know how to prove it but it looks like it's correct.
Suppose m is even. Let's call 'step' changing avery LR to UD and then every UD to LR, as done in matthew99's solution. We want to show that eventually all cells become L or R.
A cell is 'stable' if it is L or R and it stays the same after performing an arbitrary number of steps. Suppose by contradiction there is a cell that never become stable, and consider the first one which has this property (it means that all the cells on the left and those placed in some preceding row eventually become stable. We can assume they are already stable, provided a sufficient number of steps has been performed). This cell must be U, and we can also determine the type of many other nearby cells, as shown:
(asterisks denote stable cells, dots denote unknown cells).
The same pattern must continue in diagonal until the border of the grid is reached. But this is impossible because there's no way to tile the cells above that diagonal using dominos (if you color them like a chessboard, the number of black cells and the number of white cells would be different).
Even after getting good rank my rating won't go up just because there were 3000 people in the contest. Bad day!!!!
The fact that you got a good rank was because there were only 3000 people , if there were more people it would proportionally increase :P
roz shankar bhagwaan ko ek lota jal chadao, rating badhegi bacha! bum bum bhole!
Div2E TL on 33 test
Replace map with unordered_map
Accepted
Just why....
I passed with map,maybe your code is ...
me either :( and I wonder why map<> got TLE though it takes N * M * 2 * log2(N) which is less than 10^8
map<> have log2(N) comparison. But 1 comporation for string = lenght. Your solution have O(N*M**Log2(N)*len). It is a lot.
So I converted XOR OR AND to each 0, 1, 2 but still got TLE.
http://mirror.codeforces.com/contest/779/submission/25049704
No, he is referring to the variable name you use as key for the map!
You can use int IDs instead of string names to get very low runtime.
I understood. thanks!
Why is that so? For strings map checks for complete length thats why 10*log2(N) instead of log2(N) in integer?
Yes, map is a BST, so it bases on comparisons, and string comparison is O(string size)
unordered_map is O(1)(instead of O(log n) ) on avg. maybe it is crucial here
Actually he is saying map<> got TLE and unordered_map got AC.
sorry for the misunderstanding there.
-removed
Div2 round was a race to see who types faster =(
100 % true. The harder part of problem E was processing the input Strings
and who reads faster
Amazing problemset.
Here, take my downvote
At problem div1E, is 47th test particular in any way? I am getting WA on it with an answer pretty close to the expected one...it must be something special about (47 is magical, isn't it:)) ) because I passed 46 tests and the solution makes sense.
LE: I found a test that I was failing and now I have AC. So, if at any time, there is anyone in need of a test that might have some similarities with 47th test (or of a strong and really small test as it proved itself to be), here it is:
The answer should be 14, but my almost perfect program was returning 13
This is the first time I solved 4 and I'm getting my ratings reduced :(
Same here :(
For div2-F/div1-C I saw a few submissions using dsu on tree technique.Can someone please explain the approach briefly.
I used the same and I've explained it here.
Cool..Thanks.
Can someone prove complexity of this solution? 25040913
So let's prove asymptotic O(26 * n).
2 vertex have merged, so they won't be merge again. So my solution works 26 * O(count of merges).
For each level O(N) merges, not?
for each level O(len(h)), sum(len(h)) = n
Solution complexity is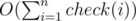 , right?
, right?
And check(i) complexity is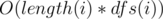 , right?
, right?
And dfs(i) complexity is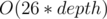 , right?
, right?
So, depth is O(N). Then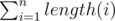 = N.
= N.
Since depth = O(N), solution complexity is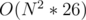
UPD: I think that this piece of code in dfs reduces depth to log2(N)
If there insted of this if will be this one :
apparently your code will take TLE
So I think that complexity of your solution is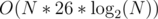 . Isn't it?
. Isn't it?
f(n) — complexity of sum dfs with n nodes.
m <= 26, sum(s_i, i <= m) = n — 1, f(n) = max(sum(f(s_i)) + m * min(s_i)) if (m = 1) f(n) = 1
let's prove f(n) = n log2 n
if (max(s_i) <= n / 2):
else:
Idea of your solution is: "merge subtrees of each vertex". Due to
if (v.size() < 2) return 0;it works like a well known technique, when we return set in dfs and merge smaller set to larger, and in your case it merges smaller subtree to larger. So it does O(NlogN) operations of merging single element, and in your implementation it is done by dfs, for each iteration of which you create 26 vectors and in total it works O(NAlogN).In worst case (binary tree) you do more then 200N calls of dfs(): http://ideone.com/ngO6lG
Can some please explain how to approach problem E of DIV 2 ?
For bitwise operations (like AND, OR and XOR), this sort of optimization problem can be solved independently for each bit. Just evaluate and sum all variables for all (two) possible choices for bit i.
to calculate sum means to maximize the sum , mth bit of sum should be 1 , and to minimize the sum mth bit should be zero ?
No, I mean the sum of the i-th bit for all variables. If the variables have values 0xf, 0x7 and 0xd, then sum(0) = 1+1+1 = 3, sum(1) = 1+1+0 = 2, sum(2) = 1+1+1 = 3 and sum(3) = 1+0+1 = 2. Now consider only sum(i). Let a = sum(i) when choosing the i-th bit of '?' as 0 and b = sum(i) when choosing the i-th bit of '?' as 1. Choose 1 for the minimum only if b < a. Choose 1 for the maximum only if b > a.
Didn't get this part Let a = sum(i) when choosing the i-th bit of '?' as 0 and b = sum(i) when choosing the i-th bit of '?' as 1. Choose 1 for the minimum only if b < a. Choose 1 for the maximum only if b > a. Could you please explain why you are doing this ?
Simulate the process taking ? as 0, the number of 1's is a. Do the same taking ? as 1, the number of 1's is b. Choose 1 for the minimum only if b < a. Choose 1 for the maximum only if b > a. Do this for all bits.
Thanks tfg
Remember that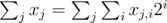 where xj, i is the i-th bit of the j-th number. Then
where xj, i is the i-th bit of the j-th number. Then 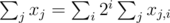 . So minimizing/maximizing
. So minimizing/maximizing 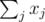 is the same as minimizing/maximizing
is the same as minimizing/maximizing 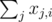 for all i. Since bitwise operations do not have carry-in or carry-out (they're bitwise!!!), we can evaluate the i-th bit for all variables (xj, i for all j) for both choices of a bit (0 and 1) and minimize/maximize
for all i. Since bitwise operations do not have carry-in or carry-out (they're bitwise!!!), we can evaluate the i-th bit for all variables (xj, i for all j) for both choices of a bit (0 and 1) and minimize/maximize 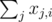 for each i independently. This is why I do what I'm doing in the part you didn't get!
for each i independently. This is why I do what I'm doing in the part you didn't get!
Edit: And sum(i) =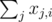 .
.
Thanks pimenta
Can someone tell me why I got WA on the contest 25046285 and why I needed to getline() one extra line?
TLE 54
Thanks for reply. can you explane me problem with input ? I will change my code to get AC easily.
getline() takes input till end of line character. If you have input
2 2
abc
def
If you do cin>>a>>b and then getline(), you are actually taking empty string input terminated by EOL character of 1st line, not the 2nd.
If you want to take line input n times, you should do
cin>>a>>b
getline(cin, str)
for(i=0;i<n;i++) getline(cin, str)
I have used getline() in my submission for this contest's Div-1 B.
Thanks I understood story about getline(), but again I am not sure about WA, actually for me it looks that our inputs are same. Len added onlyonr getchar more and it changes result. I understood it is for new line, but again I am readin n+1 lines.
Hello! I tried to solve problem C-Div2 using C++ by sorting the objects by their a-b value. The complexity should be O(N*logN). I tried both sort from <algorithm and an iterative quicksort, but I got TLE on pretests 8, respectively 9. Could you please help me figure out what I did wrong?
EDIT: Code with STL sort, TLE on pretest 8: http://pastebin.com/ZkrnPpXG
A code is usually nice to post here, if you're expecting help :) The idea is correct, though. One of the common mistakes you might have, ensure that your comparator to sort returns FALSE on equal objects.
Sorry, you're right. Here is a link to a my last submitted code that got TLE on pretest 8: http://pastebin.com/ZkrnPpXG.
I think my cmp function makes sort skip swapping the current pair if they're equal by returning 1. Is that ok?
https://en.wikipedia.org/wiki/Weak_ordering Here, you may want to read this for better understanding) In short, that's not ok, replace '>' with '>=' to avoid TLE)
P.S. Also, seems to me your solution won't work when n == k, your first cycle (after sorting) would go out of array bounds.
Or just do like this:
bool cmp_a(obiect x, obiect y) { return x.a — x.b < y.a — y.b; }
Thank you very much!
I really like this round. I think Div.2 A has a little difficult, but B and C are easy. And my classmate FizzyDavid (Codeforces.com/profile/FizzyDavid) is Div.1 rank 7 and he becomes red. My rate also has a little rise! Congratulation to him!
-- Sorry, I am a Chinese, so my English isn't good. Sorry for my bad English!
Will editorials be published for this one?
While this is not a huge concern in competitive programming, is there a straight forward way to read a line of input into a vector/array in C++? (Just like foo = input.split() in python)
I don't think there's a very simple way.
I usually do this:
I am also using stringstream for the task, but feeding the string back into a stream after reading it seems to be unnecessary intuitively. :/
(Is there a less "simple" way, but we can feed it straight into the stringstream?)
should just work, since in most cases
stringworks just like avectorHowever, be careful when using this method:
But getline only take cares of a delimiter, if there is an uncertain amount of spaces in a line then I can't split them without using other methods, can I? (For example, div2E)
In the div2E problem it's enough cin and cout to read the input properly. (http://mirror.codeforces.com/contest/779/submission/25044527)
Can anyone help me figure out what I am doing wrong for div2E / div1A ?
submission
I'm trying a simple binary search on a, coupled with a linear time check to see if p is part of t. It fails test 7.
shoud be left = mid and right = mid not mid+1 and mid-1 int case left = 2 right = 3 => mid = 2 and after that right = 1
Why the first one gave runtime error but second passed? 25061791 25061827
In first solution you use comparator which is wrong. It should not return true for cmp(a, a). Compare is used as a function object which returns true if the first argument is less than the second, and false otherwise.
thanx ,but what if i want to return true for comp(a,a)?
waiting for edutorial~ brute force for F seems available- -but why?
If you merge always merging the smaller subtrees into the largest one, the complexity will be O(n*logn*number of characters) as said here: http://mirror.codeforces.com/blog/entry/50658?#comment-346232 The proof is something like: You have a subtree of size 1, to use it on the merge you need some subtree of size at least 1, now you got size at least 2. Do the same, now you got 4... It's clear that you'll use some node at most logn times.
get it, thanks~
where can I get editorials to div 1 problems?
Can somebody explain 402 D div2 in laymen trms with some test case or proper approach?
Notice that if you take out k letters from the string and you can still form the other word, then, if you take out less than k letters from the string, you can still form the other word. Then, you could see what happens if you take 1, 2, 3, etc. letters from the original string and see if even without those letters, you can form the other word. Of course, this is too slow to pass. Then, we have to binary search the amount of letters we can take, while being able to form the second string. For each length, evaluate if the original string minus the first k indexes still contains the objective string. If it does, you can take out more indexes. Else, you must take less indexes. My submission: 25066942
screenshot screenshot
My submissions did not get judged by system test but got rank-changed. I register late in the extra registration after contest start. Is this an intended system behavior or a bug?
This does seem like a bug. I have joined in on extra registration before and rest of it is completely normal, Post Tests should have run for your submissions.
it should be unrated
Why?
Why haven't we got the editorials till now ?? They should have been uploaded by now :)
Sorry I mistake
Can someone please explain the statement for Div1 C? Is it necessary that after eliminating the pth letter all words to be different? So that the language will have the same amount of words?