


Привет, Codeforces!
Завтра, 15 марта 2017 в 18:05 (время московское) состоится очередной рейтинговый раунд на Сodeforces для участников из второго дивизиона. Участники из первого дивизиона, как обычно, смогут поучаствовать вне конкурса. Это мой второй раунд, надеюсь, он вам понравится больше, чем предыдущий.
На раунде, как обычно, будет пять задач и два часа на их решение. Советую внимательно прочитать условия всех задач. Также советую перепроверять решения на правильность, даже если они прошли все претесты — вердикт Претесты пройдены еще не значит, что решение полностью правильное! Желаю всем получить удовольствие от контеста и научиться чему-то новому, решая задачи.
Как и в прошлый раз, задачи будут про Антона и его друзей.
Хотелось бы поблагодарить Алексея Вистяжа (netman) за помощь в подготовке контеста, Владислава Вишневского (Vladik) за тестирование раунда, Дмитрия Клебанова (dmitriyklebanov) за вычитывание условий, и конечно же, Михаила Мирзаянова (MikeMirzayanov) за замечательные платформы Codeforces и Polygon.
Разбалловка: 500 — 1000 — 1500 — 2250 — 2500.
UPD. Контест закончился, системное тестирование уже началось, разбор скоро появится.
UPD2. Появился разбор.
UPD3. Поздравляю победителей контеста!
Div. 1
Div. 2
Всем спасибо за участие! :)







Auto comment: topic has been translated by gepardo (original revision, translated revision, compare)
Why not in main page?
404 not found
FOUND! I'm here.
You must have been waiting for a long time for commenting in this round
yeah, I have been waiting for 403 rounds! :D
finally a regular round after 10 days .
Looks like more hacking is gonna happen in the contest.
Also love the statement
I wish you to enjoy the contest and learn something new solving the problems.
Thanks for the contest.
ERROR 404 :p
Expecting a lot of Hacks !!
Codeforces should have just skipped round 404 and have gone to round 405. That way, whenever someone searched for round 404, they would have got the error message "Round 404 not found" xD
Delicate way of saying that pretests are guaranteed to be shit.
True
Verdict "Accepted" also doesn't mean that the solution is completely correct, but we tend to forget it.
I think it means that problem statement is complicated, but is it true?
I saw sources that passed C with brute-force,but a simpla 10^18 1 test shut them down.
Also,there were some with sqrt(n-m),but n<m crashed them.
Pretests were really bad
Div. 1 Round not found.
Btw anyone knows the reason behind the low frequency of cf rounds thesedays.
I hope short statements!!!
Why? Longer statements are usually more understandable and more interesting to read.
mmmm..! Actually I mean short and understandable!!! You can see Csacademy's problems!!! Some of part of stories is really useless!!! We can make a short interesting problem.
Yes, such statements are good. I hope you'll find my statements short enough, understandable and interesting :)
Don't worry! I guess your contest is strong and interesting enough to don't think about the statements :)
In Allah's safeguard
Also check all your solutions for correctness even if they passed all the pretests. Verdict Pretests passed doesn't mean that the solution is completely correct!That's look like problem's are a little bit tricky and suitable for hack...:)
This is the first contest that I skip because I have 1900 rating!
You can participate unofficially too. Main thing is learning, not rating, and I'm sure you can learn new things from any contest (no matters Div.1 or Div.2).
Yeah, that's true. Rating doesn't matter much :)
says an International Master
It is too late for me to join it. :(
Contest 404 not found :P
Contest 404 not found ! :P
Желаю всем на этом раунде +404 к рейтингу!
главное, чтобы ничего не потерялось:)
Надеюсь это намёк на возможность взломов.
:|
Verdict Pretests passed doesn't mean that the solution is completely correct!
be carefull everyone , today's questions will have many hacks :)
wishing everyone positive rating change , good luck ..
Hoping of getting a color change to dark blue:)
This post scares me for the contest.
Anybody noticed the "tag not found" tag? :D :V
Let's see if there will be server problems this round...
The comment is hidden because of too negative feedback, click here to view it
Nice
It looks like you smoke too much this time :V
The comment is hidden because of too negative feedback, click here to view it
Автокомментарий: текст был обновлен пользователем gepardo (предыдущая версия, новая версия, сравнить).
Auto comment: topic has been updated by gepardo (previous revision, new revision, compare).
Last time I did a comment like this I lost a 100 point in rating but...
This is the last CF round before the selection test here...
I really hope that I can get to Div1 so I can impress everyone I know with a new color wish me luck!!!
it doesn't matter buddy
rating does nothing on the field
hope we can make it together
The contest starts in 12 minutes. Good luck all!
The contest starts in 12 minutes. Good luck all!
Did you experience a bug? The site said the the contest had started.
I think the score distribution for hacks isn't fair. Hacking a Div2A and Div2D isn't the same. Harder problems should have more points for hacks than the easier ones. Also it would be interesting if hack score decreased with time :P
Good thinking!!
Unable to Hack
Hack system not working
I hate acting like a copy-past machine
I'm talking about div2 A
Long submission queue. Anybody else facing this problem?
yes..
Rating prediction for this contest could be found here
Extensions:
Have a high rating and don't lose anything:)
This rating-predictor is vert accurate. Thank you very much for it :)
I'm glad to read this:)
Thank u very much for the predictions.Great work.Anyway what do use to make these predictions.
Actually prediction is quite wrong word, couple of my friend misunderstand it too. I would be happy if someone propose better service's name:) My app just periodically calculate rating change based on open formulas, assuming that current standings is final.
Got it.Thankyou once again :-)
It predicted exactly the same for me.
Unfortunately today's prediction is a bit wrong — my tool predicted for everyone exactly 1 point higher rating than official.
I haven't figured out yet what is reason of this, for previous contests prediction was absolutely correct:)
Judge 404 not found :P
Please fix it (I submitted my solution to E and scared when seeing long long queue :D).
UPD: Nevermind it got TLE :P
My solution is saying in queue for the last 5 minutes. :( and only 10 minutes are left for the contest.
Same here :(
Oh, another round about me! Thank you, my brother!
Good luck everyone in solving tasks about me!
the round is extended by 10 minutes.
What just happened? Was the contest extended?
So hard round, especially math in D
I think D is dynamic programming (maybe I'm wrong).
combinatorics
How did you solve it?
The best complexity i have discovered so far is N^2
read Vandermonde's identity and try to solve it yourself :)
this was exactly what i needed.Too bad i didn't use it in the contest,but thank you for showing it to me.
you're welcome
A similar problem of today's E : link
just wait until the end of the round
This problem was bad. It timed out solutions based on ordered statistics tree for example, but allowed sorted vectors. The query answer complexity is the same O(sqrtn*logn)...
How to do it?
I tried sqrt root decompostion .But it was TLE.
UPD: sqrt decomposition passed in 702 ms.
I've tried to store a treap in every node of the segment tree, but i didn't manage to code it in time. The time should be O(q log^2 n)
i tried it here, it got TLE, maybe weak implementation, idk
http://mirror.codeforces.com/contest/785/submission/25524189
I'll try sumbitting mine after the testing phase ends.
You can't pick block size as sqrt(n) if you use BIT. Sqrt(n) only optimizes stuff like N/x + x, whereas BIT has a log factor. Look at this comment: http://mirror.codeforces.com/blog/entry/50329?#comment-343301
for me I solve it with sqrt decomposition and a BIT for each block
and it passed the pretests
I solved it with sqrt decomposition and sorted vectors, 2.5 sec on pretests.
Sorry for this, I didn't know about this problem before. Anyway, I hope you enjoyed other problems :)
I knew INVCNT but not this one :(
How do you do C? I was trying binary search, it was working alright on smaller cases, but it wasn't working on bigger cases.
(1e18 * (1e18 + 1)) / 2 is really big...you shouldn't try a day that is bigger than 1e10
Ans is not more than 1e9. Cause in worst case ans = sqrt n which is not more than 1e9.
Nope, if n<=m, then ans is n.
The result is < sqrt(2 * 1e18), not 1e9
Why ?
Let m = 1, and N = 10^18. ie from 2nd day onwards bird start depleting the barn.
=> x*(x+1)/2 — 1 = N.
=> x^2 + x = 2*N + 1
=> x can be up to sqrt(2N)+1. => search from 0 to ceil(sqrt(2*1e18)+1)
I used binary search. But I guess there was an O(1) solution as well.
Hating Math more and more.
Where is math? In task D?
isn't C math? :/
It can be solved by binary search also.
you have to do math calculation in the BS :P
My 10 minutes are wasted... :(
How to solve D?
for each i such that arr[i] == (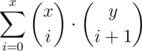 to the answer
to the answer 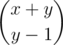
let x = number of ( from 1 to i — 1
let y = number of ) from i + 1 to n
add
this can be simplified to
Can you show how to simplify it? I got the summation part, but I couldn't simplify.
This can be seen as you have
I also came up with the summation part but couldn't simplify it. Now when I saw that I feel like a total retard.
You and me both. :(
Another way of looking at it is by saying that we have a group of (x+y) items, x of which are '(' and y are ')'. Now find all ways to select k (from 0) items from x and k+1 items from y.
This is the same as selecting k items from x and (y-k-1) items from y.
If we consider this summation, this is basically, selecting (k+y-k-1) items (i.e y-1 items) from the group (x+y), considering the ways in which we can 'divide' the (y-1) items in the two distinct groups.
=> Reduces to all ways of selecting y-1 items from (x+y) group.
Funny thing is, I remember doing this reduction long back. Just couldn't redo it during the contest no matter how hard I tried. :/
Is this ok? Suppose we have x "(" and y ")", and we want choose k items from each. so it should be (x + y)Cy ? But for case ()) and k be 1, it will give answer as 3 but not 2.
Here I'm not going with the same logic as rajat1603 where he omits one "(" and adds k + 1 to y. Infact, if we have at position i, X chars "(" until i and Y chars of ")" after i, the answer should be xCx . yCx, am I right? :)
If it was xCx*yCx, you are double counting a lot of cases, for example (()). at pos = 0, you will get 1C1*2C1 = 2 at pos = 1, you will get 2C2*2C2 = 1 at pos = 2, you will get 2C2*2C2 = 1 at pos = 3, you will get 2C1*1C1 = 2
=> total ways = 6, there's a lot of double counting in there.
To remove double counting, iterate from left to right, and only add when a new '(' is encountered, finding number of ways where the current '(' is included. That's why we omit one count for '('.
This way, in your example we get
at pos 0, two pos (.) and (). or (3-1)C(1) at pos 1, we get 0 (since not '(') at pos 2, we get 0 (since not '(') => total = 2.
According to the definition we can use (x-1) instead of (y-1), how would that be true?
Suppose you have 2 collections of size x and y respectively. Consider the number of ways choosing y-1 from the combined collection. Now each of these ways can be broken down to choosing some number of items from among the x, and some number of items from among the y. This is exactly what the first formula says.
My idea for D is divide and conquer compute answer for left part and right part and merge the answers and then compute the answer for range l to r , i don't know where i went wrong could some one please help : link [submission:http://mirror.codeforces.com/contest/785/submission/25527662]
Let me check if I got your idea correctly: you're counting the number of RSBS which will include the '(' occurring at position i. Is that it?
i am counting number of sequences such that that rightmost ( is at i
This formula is giving 5 for the first sample:
)(()()
Could you please check my code? 25530480
UPD: Sorry, found my bug.
Steps :
where C(n,r,mod) i am using Lucas theorem here .
Did it work for you? I got WA case 4...
The case )()()()(((( gives wrong answer with this approach. But I don't know how to fix it.
I think the right summation for ans is:
why do you think that explain please ?
Why i from 0 to x ? Why not 0 to min(x, y) ?
I thought the same...
for i > x you can consider the terms as 0 so it it doesn't matter.
I have understood it, thanks a lot :D
using Vandermonde's identity
A and B are silly problems
E is so standard, and now I found that it's even a copied problem
for D I can't come up with an easy-coding solution and I hope it has an interesting solution
I think C is good but it's so easy for a div2 C problem
Yup, its copied from SPOJ. I just found it out. I wished I found it earlier.
You can also find solution here — How to solve SWAPS
My idea of D is to calculate the partial sums of open brackets and close brackets, and sweep a line from start to end while doing some combinatorics. However this is quadratic and I got TLE on pretest 6. Cannot find a method to optimize it.
Was server slow or problem with my service provider? I waited to hack two solution in two tab, refreshed again and again but couldn't put the cases :/
Same here. Because of that problem I ended up putting the wrong hack and got unsuccessful hack.
A big glitch in COdeforces is there.I hacked a user's submission which was clearly wrong.The thing is time was over when my hack was in process, hence I got -50 points loss without hack being processed. Moderators please check the glitch
I solved the problem E in the last minute ,but I submitted it failed because it just had a "%lld" which was commented out.
404 rating not found :(
Too many Binary Search problems these days!
What is the hacking input of problem C?
n<m
ans is n, Hacked solutions will give RE because sqrt of negative number is not defined.
also binary search that has x * y where x , y can be up to 1e18
I got hacked on that one and sent my second submission in Python =D
I hacked two guys with 1 10000
and one guy with 1e18 1
2 3 worked for me (:
2 3
Problem C has funny test data.
I passed the pretests but got TLE-hacked. :-(
The algorithm I used is speed through the first m days, and then manually implement the rest. I barely passed the pretests with a 499ms running time, but then failed with a hack.
what is the pretest 4 in E ?
What is the time complexity of this code? I tried to hack (unsuccessful ) it with test case:
1e18 1
its ans is 1414213563
this guy saves 1 initially in i and m in ans, and he updates i every time by 1, i.e., his while loop should be running 1414213562 times! But no TLE.
Yes, it iterates about 1.4e9 times. But the loop is very very simple, so it might run faster than expected. It runs within 600 ms in my desktop.
Also thought abouth this solution, but i guessed that there will be TL :/
And it got AC :/
Just determine on how simple your code is, i saw some people using similar approach with time complexity O(answer - m) as well but unfortunately got TLE.
What is the hack for problem C? :'v
Anything with n<m worked, like 2 3
If someone uses like m*m without long arithmetic, that just 100 and 10^18
How to solve C?
I tried binary search over fucntion
f(mid) = n-m-(mid*mid + mid)and set answer as the ceil of the root of the equation.Solution Link: Solution
mid * mid is way too big
So, what should be the approach?
I used BigInteger on java. So i guess, that it is a long arithmetic also
The upper bound can be lowered to about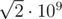 as this is approximately the maximum value of answer - m.
as this is approximately the maximum value of answer - m.
How did you get the upper bound ?
The answer is finding minimum value of X such that m + (1 + 2 + ... + X) ≥ n, which is same as finding min X s.t. X(X + 1) ≥ 2(n - m).
So, X should be around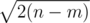 , and here the maximum value of n is 1018. So upper bound is about
, and here the maximum value of n is 1018. So upper bound is about  .
.
Thanks :)
I should have read this comment earlier was trying to figure out the same thing and understood after 2 hours that the problem is with overflow.
PS : Thanks for the explanation
easy . mid * mid might be too big but mid * mid / 1e18 is good enough . just be careful to write mid / 1e18 * mid
Автокомментарий: текст был обновлен пользователем gepardo (предыдущая версия, новая версия, сравнить).
Auto comment: topic has been updated by gepardo (previous revision, new revision, compare).
You are old driver!
Pretest 7?
+1 instead of -1: ans=(1+math.sqrt(1+8*(n-m)))/2 for me it passed tests
It doesn't :/
http://mirror.codeforces.com/contest/785/submission/25527584 Please point out the mistake!!!
Debugging yourself teaches much more.
Too much code
https://ideone.com/vmqY38
double sum=(double)((double)(e)*(double)(e+1))/2;This may be the problem
Хороший раунд
Apparently O(10^9) is enough for problem C: 25509756
Почему зависло на 100%?
Problem C : What is wrong in this approach ?
if(m >= n){ cout<<n<<endl; return 0;} else { ll i = 1; while((i*i)+i < 2*(n-m)) i++; cout<<m+i<<endl; return 0; }
i could be near to 1000*1000*1000 (sqrt(2*(n-m)).
and your solution is O(i)
i did casework based on the index of the last '(', and then got a binomial formula. My code is here: http://mirror.codeforces.com/contest/785/submission/25528358
does anyone know how to do the binomial thingies more elegantly, as these take quite a long time to implement. I tried checking others' solutions but I think that most didn't use explicit binomial formulas.
http://mirror.codeforces.com/contest/785/submission/25529002
Try this.
In problem test case 16 999999998765257152 10 of problem C, my ans on ideone is showing correct but on CF it shows different answer why? http://ideone.com/mn2iXL
What does this means? http://prntscr.com/ekdcpv
same code giving ac with g++ 5.1 and wa with g++14 what's this ??? ac code wa code what's the problem
Seems to be a
doublerounding issue here:sqrt(1 + 4 * q)). The result of this statement for the failing test case is2828427123.0000000..., which is close to 'double' precision limits. So it might also be saved in memory as2828427122.9999.... When implicitly casting this toint, it truncates downwards, so that's where the-1of your answer comes from. The solution is described here. In short, add+0.5, before downcasting to 'int'.Problem C:
sqrt WA
sqrtl AC
how powerful is sqrtL?
sqrt ac in g++5.1
I think depends on how you've calculated:
I did: (long long) ceil ((-1 + sqrtl (1 + 8*(n-m))) / 2);
but same code is ac in g++5.1 and wa in g++ 14 i have given links in my comment above
Забавно. Моё решение задачи С упало на фин.тестах, потому что строка: (long long)ceil((sqrt(1+8*(long double)(n — m)) — 1)/2) + m для значений 999999998765257152 10 под MS C++ выдаёт 1414213571, а под GNU C++ 11 — 1414213572. Я "в восторге".
Тесты специально так подбирались. Рассчитывалось, что все решения без бин.поиска обломаются и не пройдут по точности. Это сделано специально.
Зачем решать в одну итерацию, лучше за логарифм, логично.
UPD. Если таким тестом действительно отсекалось альтернативное решение задачи, то это по крайней мере глупо, не говоря уже о корректности. Задача решена и решена правильно. Если она должна решаться только бинпоиском, то будьте добры, составьте так условие, чтобы прямое решение не проходило. Гробить решение за счёт погрешности библиотечных функций — это свинство.
Да, но ведь было много решений формулой)
Почему "Гробить решение за счёт погрешности библиотечных функций — это свинство"?
Потому что контесты не направлены на выявление багов компиляторов. Если я использую sqrt, я полагаю, что он даст правильный результат, и не прыгаю с бубном возле ноутбука во время систестов в надежде, что при специально подобранных входных данных эта функция вернёт мне необходимые милионные доли результата, тогда как тип данных эту точность подразумевает.
Контесты направлены на получение верных решений. Мне кажется, довольно глупо использовать sqrt для вычисления корня из целых чисел порядка 10^18, забив на возможную погрешность. Не понимаю, как можно засылать и надеяться, что не будет специально подобранных тестов. Это как будто написать самые тупые хэши и надеяться, что авторы не будут их ломать. Или написать неверное асимптотически решение с оптимизациями и надеяться, что оно зайдет, а когда не зайдет, сказать, что отсечение верных решений (ну оно ж верное, просто медленное) — свинство.
Написать кривой хэш или накосячить с асимптотикой — это вина программиста, а то, что sqrt по-разному работает на двух компиляторах под один и тот же язык — нет. Вот в этом моё негодование.
Разумеется, программист не виноват, что sqrt — неточная функция. Но он должен это знать и уметь использовать ее так, чтобы это не доставляло проблем. Поэтому Ваше негодование кажется мне, мягко говоря, немного необоснованным.
На мой взгляд, лучше знать особенности работы библиотечных функций (например, погрешность в стандартной функции
sqrt), прежде чем их использовать. Сильные тесты должны были сломать такое решение по точности. И да, это решение не предполагалось мной как правильное.Советую лишний раз не использовать функции, работающие с вещественными числами, без крайней на то необходимости.
В таком случае, почему оно должно заходить под одним компилятором, и откидываться под другим? Это тоже стоит знать и учитывать, когда решаешь задачу?
Разумеется
В задаче В поставил необходимую константу 2е8 вместо 2е9. Удивительно, что никто не взломал во время раунда. Из-за этого в итоговой таблице опустился на 700 мест.
"Вердикт Претесты пройдены еще не значит, что решение полностью правильное!"©
guys, help? What's the difference between addition and subtraction? first loop passed the worst case (1e18 1) in 904ms and got AC while the second got TLE.
code with 1st while: here code with 2nd while: here
also, what other details can reduce running time? and thanks
ignore
What?
n-m is constant. I suppose it is a compiler optimization.
In your code, "n-m" is constant through all the iterations of the loop, whereas "s+m" is not constant because the value of 's' changes in the loop. I believe, the compiler optimises the "n-m" case by avoiding recomputing the value of "n-m".
And what's about
-faggressive-loop-optimizations? Is not the optimizer able to make simplification in such simple conditions?Thanks
Hi! Tell me please what's wrong with this solution for B. Runtime eror. Can't find a mistake :( http://mirror.codeforces.com/contest/785/submission/25512453
comparator(x, x) should return false
Your comparator function should give false for equal parameters, which is the reason that your sort won't work well. Use '<' in place of '<=', that should suffice.
to avoid mistakes like this, you can use
std::stable_sortinsteadI was actually looking for exactly such a mistake during contest, but unfortunately (for me) everyone in my room got it correctly.
Автокомментарий: текст был обновлен пользователем gepardo (предыдущая версия, новая версия, сравнить).
Auto comment: topic has been updated by gepardo (previous revision, new revision, compare).
Поправьте ссылку на разбор. http://mirror.codeforces.com/blog/entry/50996
UPD: Пока писал, уже поправили.
жду разбор задачи
Какой? Разбор уже давно как опубликован.
вголос
n=3; on my computer: --1 1 --2 2 --3 3 here: --1 0 --2 1 --3 2 Why did this case take place?
Isn't it an undefined behaviour?
Thanks
You're welcome :)
My submission for C was off by one in some of the test cases. Can somebody help me with it? Here is my solution 25525973
Your solution has wrong logic, please read the editorial.
Thanks! Nice editorial
I tried to solve problemE with segment tree plus ordered multisets but I am getting TLE on test 7.
The complexity of build function in my code in O(N * LOGN * LOGN * C). where C is the constant factor in segment tree.(C ≈ 4).
http://mirror.codeforces.com/contest/785/submission/25568923
Is there any way to optimize the build function.