


В последнее время формат типичных задач на соревнованиях по программированию расширяется новым видом задач, которые принято называть интерактивными. Решения таких задач в некотором роде общаются (взаимодействуют) с тестирующей оболочкой. Обычно, интерактивные задачи используются для задач двух видов:
- Задачи на online-алгоритмы, т.е. такие алгоритмы, которые не читают все входные данные сразу, а могут читать их только по мере своей работы. Простой пример: задано множество из n чисел. Надо обработать n запростов. Каждый запрос содержит элемент множества, до обработки запроса надо вывести минимум чисел в множестве, а потом удалить этот элемент. Естественно, после последнего запроса множества станет пустым. Если решать эту задачу как офлайн-задачу, то можно решать ее <<с конца>>, обрабатывая запросы от последнего к первому (т.е. фактически добавляя в множество элементы). В таком случае решение совсем тривиально. Онлайн-формулировка не позволяет решению прочитать очередной запрос до обработки предыдущего, что вынуждает писать решение, обрабатывающее запросы в прямом порядке. В таком случае необходима структура данных типа
std::setв С++ для поддержания минимума в динамическом множестве. - Задачи на игры. В таком случае участнику надо написать программу, которая делает какие-то ходы, а ответы на эти ходы зависят от того, как именно сходила программа. Здесь в качестве игр могут выступать не только типичные игры, но и «угадайки». Например: было загадано число от 1 до n. Программа участника пытается его угадать, а интерактивный модуль отвечает больше или меньше загаданное число очередной попытки участника. Требуется отгадать число, сделав не более
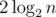 попыток. В качестве решения здесь участник может использовать бинарный поиск.
попыток. В качестве решения здесь участник может использовать бинарный поиск.
Интерактивные задачи немного сложнее для поддержания в тестирующих системах, так как требуют одновременный запуск решения в связке с неким интерактивным модулем в таком режиме, что вывод модуля перенаправляется на ввод решения и наоборот. Такой функциональности можно добиться, используя пайпы (pipes) операционной системы.
В настоящий момент есть несколько источников интерактивных задач, в них похожим образом устроен процесс тестирования. Опишем этот процесс, обобщив опыт существующих разработок. Я уверен, что одинаковый workflow тестирования значительно упростит процесс переиспользования подобных задач. Призываею использовать именно его в тестирующих системах. Конечно, предварительно его следует обсудить в комментариях.
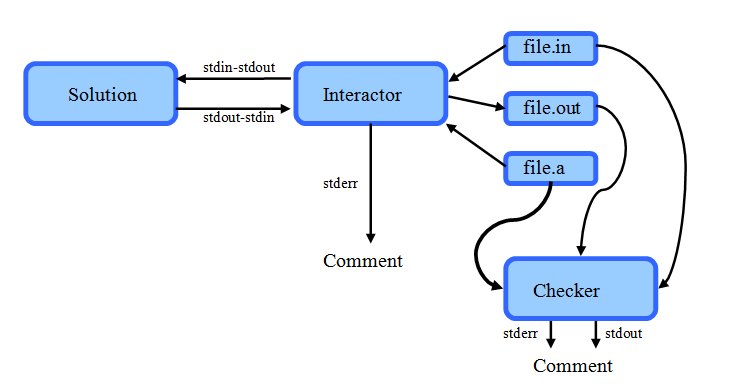
Пакет задачи состоит из:
- Одного или нескольких тестов, возможно с ответами (на картинке это файл file.in и file.a). В качестве ответов обычно используются выводы интерактора при тестировании модельных авторских решений.
- Интерактивного модуля (сокращенно, интерактора) — специальной программы, которая <<общается>> с решением.
- Тестирующей программы (чекера).
- Крайне желательно наличие авторского решения.
- Крайне желательно наличие специальной программы — валидатора. Валидатор получает на вход текст теста (file.in) и возвращается с кодом возврата 0 тогда и только тогда, когда тест корректен. Здесь есть хитрость, так как по-идее еще надо валидировать непосредственно данные, отосланные решению (стрелочка от интерактора к решению stdout-stdin). В настоящий момент такую валидацию лучше встраивать в интерактор.
Как происходит запуск решения и его оценка в интерактивной задаче.
- Сначала запускается в <<связке>> одновременно решение и интерактор. На решение как обычно наложены традиционные ограничения на время и память. На интерактор похожие ограничения тоже должны быть наложены, но довольно лояльные (например, 15 секунд/256MB). Интерактор запускается с теми же параметрами командной строки, что и обычный чекер — именем файла для чтения описания теста (в схеме file.in), именем файла для вывода информации о результатах взаимодействия (в схеме file.out), именем файла с ответом (в схеме file.a). Возможны дополнительные классические параметры testlib, если интерактор написан на нем.
- Ждем события, что один из процессов завершился (сам собой или был прерван).
- Первый случай, первым завершилось решение:
- Если завершилось по причине превышения каких-то ограничений, то сразу возвращаем вердикт
Time Limit Exceeded,Memory Limit ExceededилиIdleness Limit Exceeded(последний, если программа продолжительное время вообще не расходовала процессорное время). - Если завершилось с кодом возврата неравным 0, то возвращаем
Runtime Error. - Если завершилось благополучно и с кодом 0, то продолжаем ждать пока завершится интерактор.
- Если завершилось по причине превышения каких-то ограничений, то сразу возвращаем вердикт
- Второй случай, первым завершился интерактор:
- Если завершился по причине превышения каких-то ограничений, то сразу возвращаем вердикт
Judgement Failed. - Если завершился с кодом возврата неравным 0, то обрабатываем его как обычный чекер:
- код 1: возвращаем вердикт
Wrong Answer, - код 2: возвращаем вердикт
Wrong Answer(илиPresentation Error, если такой вердикт поддерживается), - код 3 или любой другой: возвращаем
Judgement Failed.
- код 1: возвращаем вердикт
- В случае любого из ненулевых кодов возврата, вывод интерактора на стандартный поток ошибок (stderr) следует считать комментарием тестирующей системы о тестировании на этом тесте.
- Если интерактор вернулся с кодом 0, то ждем завершения решения. Применяем к нему пункты о превышении ограничений или ненулевом коде возврата из предыдущего пункта. Таким образом, считаем, что оно благополучно завершилось с кодом 0.
- Если завершился по причине превышения каких-то ограничений, то сразу возвращаем вердикт
- Ждем завершения второго процесса, считаем, что он благополучно завершился с кодом 0, иначе вердикт очевиден.
- Запускаем чекер, передавая ему в качестве аргументов file.in (описание теста), file.out (вывод интерактора) и, если есть, file.a (файл ответа). Таким образом, командная строка запуска имеет вид:
check file.in file.outилиcheck file.in file.out file.a. Чекер запускаем с лояльными ограничениями (например, 15 секунд/256 MB). Ждем завершения процесса. Если ограничения были превышены, то возвращаемJudgement Failed. В противном случае смотрим на код возврата:- код 0: возвращаем вердикт
OK, - код 1: возвращаем вердикт
Wrong Answer, - код 2: возвращаем вердикт
Wrong Answer(илиPresentation Error, если такой вердикт поддерживается), - код 3 или любой другой: возвращаем
Judgement Failed.
- код 0: возвращаем вердикт
- В случае любого из ненулевых кодов возврата, объединенный вывод чекера на стандартный поток вывода (stdout) и ошибок (stderr) следует считать комментарием тестирующей системы о тестировании на этом тесте.
Некоторые тестирующие системы используют альтернативные способы получения информации о вердикте после запуска чекера. Например:
- PCMS2 считает, что чекер всегда должнен возвращаться с кодом 0, а его вердикт считывается из специального XML-файлика.
- EJUDGE имеет свою собственную систему кодов возврата, несовместимую с общеприятой.
По этой причине настоятельно рекомендуется использовать testlib для разработки как чекера, так и интерактора, чтобы инкапсулировать способ передачи вердикта в проверенную совместимую библиотеку.
Вот пример простого интерактора под testlib.h, который делает задачу A+B интерактивной:
#include "testlib.h"
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
setName("Interactor A+B");
registerInteraction(argc, argv);
// reads number of queries from test file
int n = inf.readInt();
for (int i = 0; i < n; i++)
{
// reads query from test file
int a = inf.readInt();
int b = inf.readInt();
// writes query to the solution, endl makes flush
cout << a << " " << b << endl;
// writes output file to be verified by checker later
tout << ouf.readInt() << endl;
}
// just message
quitf(_ok, "%d queries processed", n);
}
В данном случае не имеет смысла встраивать логику проверки в интерактор, хотя это возможно сделать. В некотором смысле она в нем имеется, например он может остановиться с вердиктом PE, не найдя ответа на очередной запрос (программа участника завершилась досрочно).
В задачах на игры иногда имеет смысл переносить большую часть логики чекера в интерактор, хотя лучше этого избегать.







Поддерживаются ли сейчас интерактивные задачи на CodeForces ?
Правильно ли я понимаю, что registerInteraction нет ни в какой выпущенной версии?
Пока нет, но мы к этому идем.
В транке http://code.google.com/p/testlib есть поддержка registerInteraction. Как только я буду уверен, что с ней все нормально, выпущу релиз. Возможно, что-то надо подпилить.
Чекеры под современные testlib-ы поддерживают четвёртый опциональный аргумент — файл, в который нужно вывести комментарий. Этим пользуется, в частности, тестирующая система TestSys.
Возможно, интерактор тоже должен поддерживать такой аргумент вместо вывода в stderr. Это может быть первый и единственный опциональный аргумент.
А может быть, интерактору, раз он берёт на себя часть функций чекера, следует дать те же аргументы, что и чекеру. Правда, тогда надо обезопасить answer-файл жюри, который придётся класть куда-то для интерактора, от программы участника.
Да, именно так. Интерактор должен запускаться ровно с теми же параметрами, как и чекер. Только второй параметр
output-fileон должен интерпретировать как файл, куда надо выводить. Я дописал чуток в транк к testlib — текущий вариант поддерживает и четвертый параметр и -appes.Обезопашивать надо той же песочницей. Например, итерактор и прочие файлы может быть в другом каталоге, а решение запускаться так, чтобы не иметь возможности читать из него. Казалось бы, ровно эта задача уже возникла и должны быть решена: нельзя позволять читать file.in решению участника.
Возможно, следует стремиться к использованию только двух основных схем:
Задачи на online-алгоритмы. Интерактор является только буфером ввода-вывода (не даёт прочитать следующий запрос, не получив ответ на предыдущий) и не содержит никакой проверяющей логики (разве что валидацию). Вся проверка происходит только на этапе запуска чекера. Формальный критерий: решение, запущенное напрямую (без прослойки-интерактора), также работает в системе правильно.
Подлинно интерактивные задачи. Все данные теста, которые нужны интерактору, можно поместить во входной файл (problem.in), а выходной файл (problem.a) оказывается не нужен. Все функции проверки в этой схеме берёт на себя интерактор. Формальный критерий: можно фактически обойтись без чекера (заменить его на тривиальный чекер, не делающий ничего и завершающийся с кодом 0).
В промежуточных схемах, когда какую-то часть проверки берёт на себя интерактор, а какую-то чекер, я не вижу чётких критериев, которые разделяют эти две части работы (примерно как разница между PE и WA). Возможно, получится такие критерии выработать и использовать. Если нет — появляется довольно большая нестандартизированная неопределённость в протоколе взаимодействия интерактора и чекера через выходной файл (problem.out). Мне кажется, она приведёт к тому, что в этом месте будут появляться придуманные за пару секунд протоколы (свой протокол в каждой задаче), в которых будут скапливаться баги и которые непонятно, кто и как будет тестировать.
Ведь даже сейчас тестирование чекера — слабое место в технологии подготовки задачи. А если чекер будет разбит в связку интерактор-протокол-чекер произвольно, проблем в этом месте будет ещё гораздо больше.
От problem.a даже во втором случае отказываться рано. Например, он может хранить оптимальное значение для некоторой получаемой величины. Так же как в обычном случае, можно будет в зависимости от сравнения этого числа и полученного значение возвращать
WA,JEилиOK.Делать два стандарта из одного не хочется. Более того, я охотно верю, что промежуточные варианты все-таки существуют. Например, интерактор только осуществляет взаимодействие, а чекер проверяет корректность и оптимальность вывода. Вероятно, микроформаты в .out файле не такое и большое зло.
Ещё следует упомянуть локальное тестирование. Я, например, не умею средствами командной строки хотя бы запускать две программы, перенаправив им stdin и stdout крест-накрест.
Насколько я знаю, для этих целей бывает олимпиадная утилита run2 (по аналогии с run, который запускает решение обычной задачи на тестах и замеряет используемые время и память). Эта штука — примерно то же самое, что и модуль, используемый для этого в тестирующей системе.
Так вот: на онсайт-соревнованиях с интерактивными задачами, где рабочие места всё равно настраиваются, можно раздавать участникам эту утилиту, чтобы им было удобнее тестировать свои решения локально. С онлайн-соревнованиями, конечно, сложнее из-за существования различных операционных систем и их версий.
У нас весь запуск решений осуществляется посредством утилиты
runexe. Думаю, что мы в внедрим в нее поддержку такого запуска. Вроде у нас даже есть вариант для Linux, хотя и экспериментальный.Для задач на онлайн-алгоритмы есть известный трюк: следующее число ввода есть f(ответ предыдущего запроса, значение в инпуте), причем f хорошо обратима. Поскольку следующий запрос содержит явно ответ на предыдущий, решать офлайн не получится.
Upd. Кстати, кажется (я могу ошибаться), у interaction-а подобным способом (stdin/stdout) есть существенный недостаток — он просто не успеет за разумное время передать 10^5 запросов.
Дополнительное кодирование — это неудобно, не наглядно и чуть затрудняет всем жизнь. Примерно как и генераторы больших тестов в формате ТопКодера. Если технология не позволяет сделать лучше — да, хороший способ. Но тут как раз разговор о том, как стандартизировать технологию, чтобы такие неестественные костыли делать не приходилось.
С чтением и записью действительно может быть проблема, связанная со скоростью передачи данных. Как минимум, максимальное время, потраченное на взаимодействие, в этой схеме наверняка придётся замерять отдельно автору задачи. И его не следует включать в то время работы решения жюри, которое умножается на 2 или 3 для участников.
Вот as for me так интерактивные задачи надо вкомпилировать в тестирующую оболочку и не париться, честно. А попытка стандартизации протокола обмена — посмотрим, что из этого может выйти.
Ошибаешься. Только что проверил на A+B — миллион запросов пробегают примерно за 2 секунды процессорного времени как программы, так и интерактора. В сумме wall time тратится примерно 8.5 секунд.