


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | jiangly | 3631 |
| 4 | Kevin114514 | 3574 |
| 5 | maroonrk | 3521 |
| 6 | strapple | 3515 |
| 7 | Radewoosh | 3461 |
| 8 | tourist | 3428 |
| 9 | turmax | 3378 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 140 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 133 |






Can't understand C's explanation.
For maintaining minimal alphabetic letter in current string $$$s$$$ there's enough to precalc $$$ms_i$$$ — minimal letter for each suffix of $$$s$$$. Minimum on suffix starting from position $$$i$$$: $$$ms_i = min(s_i, ms_{i+1})$$$. This way is faster: just $$$O(n)$$$.
Before adding to stack a letter at position $$$i$$$, while letter in the top of the stack is not greater than minimum on suffix starting from position i, pop the letter from the stack and add it to the answer.
Alternately F can be solved with Divide and Conquer Optimisation as well.
I seem to get TLE with Divide and Conquer Optimization , was any pruning required to pass the time limit ?
It's Complexity O(n^2logn)?
Problem E can also be solved offline with an O(n) memory complexity, by sorting the queries w.r.t k and solving all queries with the same k together using dynamic programming.
Intuitions about the time complexity:
I don't know exactly how to calculate a generalized upper bound for the time complexity, but I had the intuition that it would fit in time using this approach
Implementation: 26497630
(1/2 + 1/3 + 1/4 + ... + 1/n) = O(logn)
Oh yes you're right, it's logn. I got confused about it. Thanks.
dropped
Note, it's order.
Hint for proof: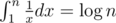
I didn't learn integrals in school yet. But I could see that your formula is not correct:
Seems that functions are crossing and lying nearby but not equal.
click
Actually, it's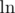 not
not 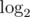 . And you can see that the difference between
. And you can see that the difference between 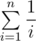 (a.k.a harmonic number) and
(a.k.a harmonic number) and 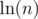 go smaller as n go bigger. It will eventually equal 0 when n big enough. Furthermore,
go smaller as n go bigger. It will eventually equal 0 when n big enough. Furthermore, 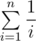 is smaller than
is smaller than 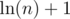 and as we can ignore constant, we can say it's O(logn)
and as we can ignore constant, we can say it's O(logn)
Thank you, I thought
logalways meanslog2in informatics, notln.Here is another proof: 1/1+1/2+1/3+1/4+1/5+1/6+1/7+..<1/1+1/2+1/2+1/4+1/4+1/4<1+1+1...+1=log n and 1/1+1/2+1/3+1/4+1/5+1/6+1/7+1/8. <1+1/2+1/4+1/4+1/8+1/8+1/8+1/8<1+1/2+1/2...+1/2=log n/2 So 1/1+1/2+...+1/n is O(log n)
But the time is worse than using sqrt precalculation..
Look, if all k will be different your code will make this Q times:
memset(dp, -1, sizeof(dp));It is optimized of course but making your complexity bigger.Sorry for necropost, but in this case your solution works in
O(n sqrt(n))time:Because your solution takes O(n) operations per one block, but this is O(n) memory, u are right
hi excuse me but if all queries have different k's then you say if (k != prev) {memset(dp, -1, sizeof(dp));} so you basically fill the dp with -1's in every query but isn't this O(n^2)? could you explain why you don't get TLE? thanks ,and sorry to bothering you :D
I understand that this contest is quite old but 797C - Minimal string has a typo and says "lexigraphically" instead of "lexicographically". I'm not sure if this is correct way to report typos but don't see any other.
Fixed, thanks.
Can anyone give me a DP solution for Problem B? Why is this approach wrong?
Here is the DP solution in case you need it still.
http://mirror.codeforces.com/contest/797/submission/41646680
Can anyone tell me where am I wrong in this code. It is giving wrong answer for an input. I am not getting why my code is giving wrong output for that input. Printing o before n. http://mirror.codeforces.com/contest/797/submission/33380771
can anyone can give me some test cases on the question C I am getting WA at test 21?
test this maybe it would help :D
input: czzbaz output should be: abzzcz
Yeah mate, really helpful test case. After testing with this one got AC
Someone please explain problem 797F . Can't understand the editorial!!!
someone please simulate this case:
acdb
s = acbd, t = '', u =''
s = cbd, t = a, u = ''
s = bd, t = ca, u = '' [first char 'c' was taken and string t was appended]
s = b, t = dca, u = ''
if the last character is to be extracted from t then it is 'a' and it will be in the last position of u which is not the output given in the test case.
i think i am misinterpreting the following lines
"Extract the first character of s and append t with this character.
Extract the last character of t and append u with this character."
Problem statement of C is very misleading. At first I could visualize string T nothing more than a queue and sorting seemed impossible.
problem c at first i had difficulty understanding the question and then with whatever i understood ,i wrote a dp solution but it got WA on TC 17.if anyone has dp solution or can find the error in my code , it will be helpful.96818512 is my submission.
try this test case: eeddcbeeec
correct ans is: bcceeeddee while your code gives: bceeecddee
HI, can anyone help me to provide the time complexity of my solution to problem E,
Here is the link to my submission:- https://mirror.codeforces.com/contest/797/submission/100305884
I guess it is n√n,
I have solved for every k individually and for a particular k, i have solved for all different values of p and storing the result for traversed indices for every p.
I think that worst case complexity would be, n + 2*(n/2) + 3* (n/3) + ... x terms s.t. x*(x+1)/2 = q; Because as k increase from 1 to n I can solve for particular k and pparticular p in n/k time, so, if all k are different then it will be, n + n/2+n/3... = nlog(n), and if there are multiple p for same k then it will be (dup, no.of different p for same k), (n/k * min(dup,k)).
In problem C the statement is completely wrong. It should be:
Move1: Extract the first character of s and append this character with t.
Move2: Extract the last character of t and append this character with u.
Great play on E :)