


Hello, fellow programming contest enthusiasts!
We are pleased to invite you to take part in the forthcoming Codeforces Round #426, which is going to be held at Sunday, 17:35 MSK. In case one of the things you fear most is a Codeforces round being authored by a purple guy, we've got some badgood news for you: this round will feature two CMs – me (xen) and GreenGrape – as its writers!
The classic Codeforces rules will be applied to this round. There will be five problems for each division, with three of them shared by both. The round will last for two hours. Forgoing a long-standing Codeforces tradition, we will not have the scoring disclosed until shortly before the contest.
In this round, you are going to assist Slastyona the Sweetmaid – a renowned lover of sweets, cupcakes, candies and all other kinds of confectionery! In her everyday life, Slastyona often faces challenging problems, some of which cannot be solved without your help.
Kudos to our testers: Kirill Seemann Simonov, Evgeny rek Tushkanov, Yegor Voudy Spirin, Evgeny WHITE2302 Belykh, Vladislav winger Isenbaev and Alexander AlexFetisov Fetisov. We would also like to thank Arthur tunyash Riazanov for his ideas on some of the problems. Thanks to the Codeforces coordinator Nikolay KAN Kalinin for his assistance in making this round happen (and for his patience, too), and, of course, to the one and only Mike MikeMirzayanov Mirzayanov for creating the magnificent Codeforces and Polygon!
You may ask: “Is it rated?” Well, for what's it worth, it seems it is, since we've commited all our passion and efforts to prevent the contrary :)
In any case, we wish you luck/bugfree code/high rating/whatever and hope that solving our problems would be a great pastime for you on this lovely Sunday evening.
UPD. The scoring is:
Div. 1: 500 – 1250 – 1500 – 2250 – 2500
Div. 2: 500 – 1000 – 1500 – 2250 – 2500
UPD 2. Our congratulations to the winners!
Div. 1:
Div. 2:
UPD 3. Editorial

artwork by Ilya Shapovalov






are the problem statements as long as this blog ? :|
Probably yes, since we "are going to assist Slastyona the Sweetmaid".
yes it was ...
Sir, how can you wish high rating for all of us??!! As on codeforces rating system it is not possible to get high rating for everyone in a contest ( As far as i know) . :)
Everything is possible in Sweetland :)
That's only logical :)
Slastyona is beautiful <3
awkward boner
... Mike, change my handle from I_love_Tanya_Romanova to I_love_Slastyona since I don't love Tanya Romanova anymore
This should be the .... sweetest announcement to a contest ..... ever! xD
I liked your style of writing, looking forward to seeing as interesting problems as this blog.
Wow! I just read the whole blog in one breath! You would make a great writer if you weren't a problem setter! :D
Don't know about the problem statements, but it feels good to read such announcements which are fun to read :) It helps to set the mood for a good contest :) Thank you authors!
deleted
We will miss IOI participants :(
Good luck everybody
IOI participants and some coaches are AWAY? TIME FOR AN ORANGE HANDLE!
(Text: I have a BOLD idea)
Edit: My feel after the contest
It seems like everybody refers to that color as yellow here on CF. I was starting to think I have some type of color hue blindness because it looks orange to me also.
I forgot about the fact that there is a line on 2300 rating, now it sounds like an even more BOLD idea to get an actual orange from purple in one round.
I am really sorry, but that animation character seems really gay
I hope problems are not the same
:O
you will see what you want to see
Why contests on CF is holding at 8:30 pm(BDT) now a days.. It used to held at 9:30 pm before... ???
The illustration is awesome.
^ v 6 why this case is "undefined"? ^>v<^>v = 6 isn't it possible in 6?
Don't discuss problems during an active contest!
what about now?
Now it's ok. The reason why that case is "undefined" is because you can start at position "^" and end at position "v" in 6 moves going either counterclockwise or clockwise. Therefore we don't know which direction was actually chosen... and it's "undefined"
If you have any doubt regarding any question.You can use the option "Ask A Question", which is down side of the Dashboard
All the best!
"undefined" means that we "cannot decide" it is "clock wise" or "counter clock wise". It does not mean that it is "impossible".
I think people who live in a country called "Sweetland" look a little different
I used to type scanf, but used cin this time and forgot to type cin.tie(0) ,so I got lots of TLE on PC. Now, I know how to solve PD, but I'm out of time. QQ
Replacing cin by scanf takes about 60 seconds, there are still more than 400 seconds remaining, you are not out of time man.
What was the hack case for div2 A ? ( Please Tell After Contest )
Let's denote:
cw_state is the Toy's state we achieve if we rotate it in clockwise.
ccw_state is the Toy's state we achieve if we rotate it in counter-clockwise.
Then:
"undefined": cw_state = ccw_state OR (final_state != cw_state && final_state != ccw_state)
"cw": if cw_state = final_state
"ccw": if ccw_state = final_state
Hope you find it useful
"It is guaranteed that the ending position of a spinner is a result of a n second spin in any of the directions, assuming the given starting position."
DIV2 seems to be dominated by Chinese participants... 8 in Top 20 and 16 in Top 40. DIV1 also has 6/20. Any idea why?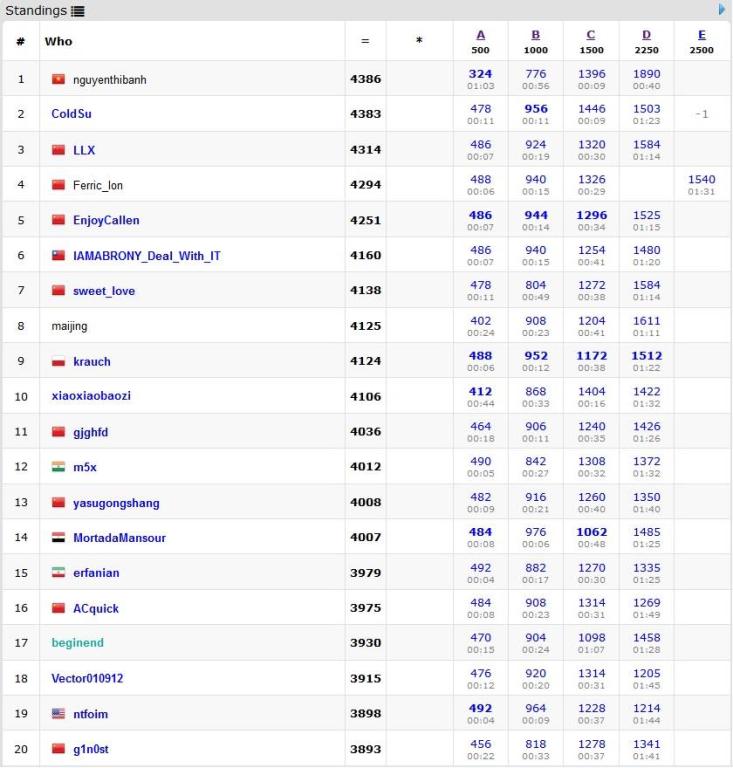
1/7 of the planet :D
But 8/20 > 1/7 The relative different is too huge that this alone is not a good explanation. Maybe the style of questions have an effect
They have 150 crore
Could someone explain DIV2C? 834C - The Meaningless Game Out of ideas here =(. My approach does not seem to pass in time. My bet is that there is some relation with the exponents of the prime factors of the a, b given.
This is my simple decision but so far I do not know whether it's right)
http://mirror.codeforces.com/contest/834/submission/29014215
Assume, Slastyona won when k1, k2, ...kx were chosen, and Pushok won at k(x + 1), ...kr. There x — number of rounds which Slastyona and r — number of all rounds.
Then A = k1 * k2 * ... * kx, B = k(x + 1) * ... * kr.
Then a = A2 * B;b = A * B2
So if B = a / A2 then b = A * (a / A2)2 and b = a2 / A3. So a2 / b must be cubic. Anaogically b2 / a must be cubic either.
a can be written in form x2y and b can be written in form xy2 from this we can write ab as (xy)3 with binary search we find xy then check if really (a / xy) * (b / xy) = xy.
Does C++'s
cbrtfunction do the cube root finding inO(logn)? I did the same approach but was getting TLE on a pretest.I don't know the implementation details of
cbrt, I think it may use binary search and then Newton's method or some other fast converging series, but I'm not sure. But I think your solution's slowness comes from working with floats, because they bring a lot of unnecessary precision: we only want to decide if a number is cubic or not and if so the cubic root of it. Compared tocbrtwe do a lot less work,cbrtactually calculates the exact cubic root with much more effort.You are using slow output. Use printf instead of cout, when you have to print out a lots of lines (3*10^5), also use "\n" instead of endl.
A binary search isn't even necessary. We can just precomp all of the perfect cubes up to 10^18 (there are only 10^6 of them) and store them in a hashset or set. Depending on languages queries will be O(1). Easier to implement too :)
O(1) solution: Find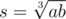 . If it's not an integer, return NO. Otherwise, if s divides both a and b, return YES, otherwise return NO. (Cube root can be found by binary search, for example.)
. If it's not an integer, return NO. Otherwise, if s divides both a and b, return YES, otherwise return NO. (Cube root can be found by binary search, for example.)
To prove that this works, note that ab must be a cube, since every round it is multiplied by k3 for some k. Moreover, if we set ab = s3, then the product of all k played in the game is s. Thus we need to have both a and b divisible by s, since they are the product of all k played in the game, plus probably some more numbers. And this is all we need; if ab = s3, let a = sx and b = sy, so we see xy = s. Thus a = x2y, b = xy2, so one possible game is a winning a game with k = x and b winning a game with k = y.
EDIT: To avoid TLE, use very fast input/output methods because you're reading 700k numbers.
How to find s is O(1)? Is it not O(log(a*b))?
Yeah, I meant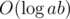 , but it's basically very very fast that it doesn't really matter. (In fact, in finding cube root in my solution, I set it to always do 20 iterations, finding the answer between 0 and 220. So that's constant time, even if a larger constant.)
, but it's basically very very fast that it doesn't really matter. (In fact, in finding cube root in my solution, I set it to always do 20 iterations, finding the answer between 0 and 220. So that's constant time, even if a larger constant.)
Ouch, should've used persistent segment tree instead of wavelet for div1B ... I am not familiar enough with it to make adaptations :/
But my n*k*logn*logn did not pass? Was urs better complexity??
I think you could achieve O(nklogn) with persistent segment tree.
What I was planning:
maintain dp[] and pos[] for the dp state after using dp[i] boxes, and the position of the first cake after the last box has been sealed.
Iterate 0 <= i < n, query the amount of distinct element within the range (i, pos[j]) and update dp[j+1] and pos[j+1] if |{elements}| + dp[j] > dp[j+1]
???
BUG SPLAT screw my rating
Yikes, should've sticked with segment trees instead of trying out wavelet.
Edit: The idea is incorrect.
Yes I have O(knlogn).
Why do you need persistence? every time I need to do a query on my segment tree I update it first, and I don't need to remember any of the older versions.
I didn't know that there is a way of finding distinct numbers without persistence, my bad. :P
Normal max-segmenttree was enough.
Can you explain how? :)
I solved it using a normal max-segtree. My solution required lazy propagation too. Code
Can you please explain your solution a little: 1) How do you define dp[i][j] that is what does it store? 2) How does a max segment tree help with the problem?
you can do NKlogN with just a normal segtree.
normal segtree with DnQ , knuth or something else? Please explain a bit? Thanks!
Lets say dp[i][j] represents that the end point of the ith partition is the jth element. One also has to find the the previous occurrence of each element of the array. Build the segtree with values for the previous iteration(that is when you considered i partitions ending at all positions). Now to make a transition-- in (i+1)th iteration and on the jth element we add 1 to all the indexes k where prev[j]<=k<j. Simple range update. dp[i+1][j]=max query over 0-(j-1). Code for reference-- http://mirror.codeforces.com/contest/834/submission/29023045
Segment tree wasn't needed, you can just stretch the range as you need while using D&Q optimization.
May I ask what is "D&Q optimization"?
Aren't you familiar with Divide and Quonquer?
I didn't expect it to be abbreviated in this way. X_X
http://mirror.codeforces.com/blog/entry/8219 the third optimization here. You can have a range [l, r] and stretch it to the right/left by adding/removing one by one to find C[k][j].
What would be the complexity of such algorithm?
O(n*k*logn)
Can Divison2D / Div1B be solved by D&C DP???
That's what I did, and it passed pretests. A little bit scared; hopefully I pass systests too...
EDIT: Yay.
I proudly continue the tradition of finding the stupid bug less than 60 seconds after the contest ends. Ouch!
Same here, I found the bug is the last 10 seconds but do not have enough time, maybe 5 more seconds can save me. Here's my bug: array size 50 -> 51 Silly enough
How to not TLE on Div 2 C? I got 20 submissions (seriously, you can check it out xd) and anything I did it got TLE.
Did you optimize input/output? I also had the same problem and changing cin/cout to scanf/printf made it pass pretests.
Hmm, I don't have TLE on Div2C, but I do have "Wrong answer on pretest 2". Is that better?
How to solve Div2C?
This is my solution; we can see that after (say) m rounds, a & b are in form:
a = (k1 * k2 * ..ki)^2 * (k_(i+1) * ...*km) = K1^2 * K2 (we can shorten to that)
Similarly, b = K1 * K2^2
So if we find K1 and K2, then we check if a & b are in those form. This is how I did it:
a*b = (K1 * K2)^3 <= 1e18 => binary search on [0,1e6] to find K1*K2
Obtain K1 = a / (K1 * K2).
Obtain K2 = b / (K1 * K2)
Then check if a == K1*K1*K2 && b == K1*K2*K2
thnx
Note that we could only consider prime k are being chosen in each round. Additionally, for {a, b} to be valid, a*b must be a cubic root of a natural number, since a*b = k1^3 * k2^3 ... kn^3.
Therefore, we could consider the prime divisors of the cubic root of a*b, for each prime divisor, count the amount of times that a prime p shows up in a and b. For {a, b} to be valid, all (cnta+cntb) must be divisible for 3 (again, k*k^2 = k^3), and max(cnta, cntb) <= min(cnta, cntb)*2 (as we are considering at most k : k^2).
This gives a complexity of O(sqrt(cubic_root(a*b)) * N) = O(1e3 * N)
This will TLE,right?
It is actually sufficient to get AC.
http://mirror.codeforces.com/contest/833/submission/29006186
First, (a*b)^(1/3) is an integer. Put t=(a*b)^(1/3), and we obtain that the answer is "yes" when and only when it holds both (a%t==0) and (b%t==0). Then is an o(N) method.
However, I got 3 TLE as a result of cin and cout...
Was nklog^2n not supposed to pass for Div2-d?Divide and conquer dp optimisation with persistent tree was giving tle on test 11.
You can remove the logN factor. Update costs in O(1) when moving from i->i-1, by checking the next_right occurrence of current value is > mid or not. Use the query to persistent segment tree only for the rightmost valid split point and henceforth use the above trick.
You can see my code for the same.
Wait, whoa, do you need to use a persistent segment tree? As in, why can't you just loop from the rightmost valid split point? It should be O(NKlogN) because each number is in at most O(log N) ranges, right?
EDIT: Yay, I passed :D
During contest in last minute,I tried to memoize some part on those values.But my bad it got MLE. Then I lowered the Memory for memoisation.And now O(n*k*logn*logn) passes the TL.
Code:29025279
In DIV 2 C,if the product of the scores is not perfect cube the answer is surely NO. Why did I get Wrong answer then? My solution
Maybe a test case like this:
1
1 64
The answer is NO right!
Yes, the answer is NO
Is there a clever solution for Div 2 E/ Div 1 C, or it's just case analysis?
notice that answer is atmost
This is because answer bounded by the number of solutions to x1 + x2 + x3 + ... + x9 ≤ 18
Now generate all those sequences and then check if it can be somehow squeezed between L and R.
That's what I meant under case analysis. The "check if it can be somehow squeezed between L and R."
fix the prefix which you are going to keep same as that of R and put a number just smaller than the digit at R and then put rest of the digits in descending order and check if its >= L.
I Think that is too big :(
during the contest !
What is solution for B div 1 ?
I have tried some DP with greedy part, but first it was wrong, than I got TLE.
A well-known technique from here. Inside the DP, one needs to compute # of distinct numbers on a segment, which is also a well-known problem (can be e.g. solved with persistent segment tree). <offtopic>I don't understand why authors would suggest such a problem, with exactly zero ideas, which is solvable just with trendy standard techniques... </offtopic>
Thanks !
At least I had part with persistent data structure :D For second part I tried some greedy, brute-force etc. But everything was WA or TLE. Also I am not sure how solution in complexity O(n k log ^2 n ) gives AC, when I tried my wrong O(8*nk log n) and got TLE :D
Can you prove why Divide n Conquer is applicable? I used it because I had a strong intuition but no concrete proof.
Oh, I thought about D&C, but didn't realize subproblem can be solved using persistent segtree. I actually found that problem pretty challenging. After a lot of thinking I came up with a nontrivial idea that required segtree that takes largest sum of suffix ending at given position (but made a stupid bug, so it didn't pass pretests). Actually, at least it has better complexity (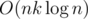 instead of
instead of 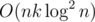 ).
).
D&C is O(NKlogN). Only first iteration we need to use persistent.
But there are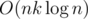 queries to distinct(l, r) subroutine that works in
queries to distinct(l, r) subroutine that works in  . Am I missing something?
. Am I missing something?
Why the extra log factor in the number of queries? There are nk DP-values to compute. Each requires a single distinct(x, y) call, then you expand that interval [x, y] to the left one-by-one.
In divide&conquer optimization I know there is a log factor. If you not use this particular optimization I am happy to hear it as well.
There is an extra log factor in D&C optimization, but you don't have to do queries each time (for this problem).
Notice that if you know uniques(l, r) then you can get uniques(l - 1, r) in O(1) time by simply precomputing next(i) to be the index of the next occurrence of ai.
Here is my code: 29006192
Note that I used a -per query range tree, but with a persistent segment tree this code would be
-per query range tree, but with a persistent segment tree this code would be 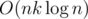 . Note that there is only a single query in each call to calc (which computes dp[m][currentk]).
. Note that there is only a single query in each call to calc (which computes dp[m][currentk]).
Ah, yeah, thanks, got it. It should have been clear to me after your previous comment but I somehow got it just now.
http://mirror.codeforces.com/contest/833/submission/29026441
It can be solved with just DnC optimization too (without using persistent segment trees)
Ah yeah, I thought about doing it that way (D&C with keeping additional infos about some intervals that can be updated by adding/deleting its borders), but I remembered this is really complicated technique (at least for me it demands being really careful). I already solved a problem A from this gym contest: http://mirror.codeforces.com/gym/100513 using such approach and I remember I was really proud :P (reversible F&U also played a role there and it was before D&C became known). Good to hear that somebody did it that way :).
I found that problem good, I solve it without any "special" dp technique, just solve the standard dp with data structure to speed it up. Overall complexity O(n * k * log(n)).
Note: I used segment tree, but no persistence.
Yeah, the solution with regular dp seems nicer. The issue is, for people familiar with divide-and-conquer optimisation and "count unique numbers on a segment" problem, the solution is obvious right away (but then might take a while to implement, but this is my personal issue).
Let me elaborate why I don't like such problems (which can be solved just by applying standard hammers). Imagine a problem which can be solved either by a complex standard algorithm (e.g. ukkonen), or with a tricky idea. Then there are three options: (1) someone knows the algorithm and has it prewritten, (2) someone knows the algorithm and doesn't have it prewritten, and (3) someone doesn't know the algorithm. Then the contest goes as follows: people from (1) solve the problem in a few minutes, everyone sees it on a scoreboard. Then people from (3) think for a while and come up with a custom solution. Finally, people from (2) are screwed the most — the solution is obvious to them, and it is obvious from the scoreboard timing that everyone submits precisely this solution. And then they spend infinite amount of time to actually implement it.
This turns the contest into some weird competition highly dependent on knowing the algorithm and having its implementation. That's not what programming contests are for, IMO. And that's why I think good contests shouldn't have problems which are solvable by standard hammers. It is fine for educational contests, but not for regular ones.
I think you maybe need some data structure to do it. such a segment tree.
Can Div2 D be done somehow with ternary search. We can observe that the required dp expression will be unimodal but not monotonous.
But it is not strictly concave/convex so no it can't be solved by ternary search.
in div2 A is this test valid ?
^ ^
6
???
No, since neither cw nor ccw is the answer
no ,if ^ ^ then n%4 should be equal to 0
That was the reason why I didn't submit any solution, I couldn't figure out why this is undefined for half an hour, it should have been mentioned in the question.
I think it was mentioned in the input section but I wasn't sure of it so I asked again.
Actually it is not undefined! This test case just does not exist at all. Look at the last phrase in the input section: "It is guaranteed that the ending position of a spinner is a result of a n second spin in any of the directions, assuming the given starting position." Starting at ^, there is no way to end at ^ after 6 spins. It can only and at v postion =)
Div2 C pretest 9 killed me!!!
Problem A is meant for begineers...why 10^9 then...10^5 was enough
there won't be any difference . you can solve it with o(1) code . the A problem of the previous contest was 10^18 .
So you can't bruteforce it, but have to use case analysis.
What's pretest 5 of D?
What is the pretest 11 of div2D?
Nice problemset btw. Thanks to the authors.
I find Div1A/Div2C to be a very poor competitive programming problem, because of the massive input/output. Many TLEs are caused by reading the input or writing the output very slowly (I got 5 TLEs because I didn't realize this). Is it really impossible to just put n ≤ 104 or something more sane, that doesn't require knowledge about specific programming languages and instead focuses on the algorithmic part?
Sadly, I can only use python and of course I get TLE even if my idea is right.
I also used Python initially; I only switched to C++ because the solution I had in Python was simple enough to port (so I could do that with my limited knowledge; as it turns out, my knowledge didn't include knowing to use scanf/printf instead of cin/cout). It's a shame that some problems have too tight time limits that slower languages are immediately ruled out.
yeah actually I think in codeforces unless you use C++ or Java, there is a very high chance that you will get TLE due to large input. (even if you pass pretest, you won't survive main test)
Anyway, it is still very fun to solve these problems.
Yeah, I guess that's why I do Google Code Jam and other output-only contests more often than Codeforces and other online judges.
you can use pypy and optimize the output
Thx! I didn't realize that xrange is faster than range before!
In this case n ≤ 104 would let other, suboptimal algorithms pass. For example what I tried initially involves finding the prime factorization of a & b and checking the exponents of each prime, which might squeeze under the time limit for n = 104 since there are only ~3000 primes up to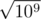 .
.
yeah I understand. One time limit doesn't fit all languages.
You might be able to by setting the constraint instead to ab ≤ 1018. This implies that this is be a solution only if max(a, b) ≤ 1012. Factorizing 1012 too many times might not be achievable. But it's far from guarantee.
Setting constraint to ab ≤ 1018 is not a good idea. It suggests that their product has big significance in this problem.
Make a, b larger, say 1018. There is still a way that doesn't use any integer greater than 1018. This will allow languages with arbitrary integer support (e.g. Java and Python) to avoid finding that solution, but oh well. The problem itself doesn't really lend to a good variation: large n means slow languages (Python) immediately fail, large a, b means C++ and other languages with at most 64-bit integer support has to find an additional wrinkle.
Make the input/output format different. Give the input as a PRNG, maybe, and make the output to give the checksum (e.g. all testcase IDs of the YES answers).
What about not using python for programming contests? It seems really weird to use a language knowing that's very slow and is likely to get a TLE.
I thought programming contests are supposed to be about the algorithm, not about the language.
In my opinion, programming contests should be about programming. It includes knowing how to (and how not to) use available tools.
I agree. I like Python too but I've learned (the hard way) never to use it for any problems involving large input and/or a lot of computation.
Yeah, I know not to use Python with problems involving lots of computation (that's why I tried using Python for the first submission; I thought I would still pass under the time, since I analyzed the amount of computation to be not too large). I just forgot that I shouldn't use Python for large input/output too.
gg
http://mirror.codeforces.com/contest/833/submission/28993116
Does something like this work for div1B?(I couldn't fix mle because I didn't have time)
It works, just fixed the array size. I had such stupid mistake last round too, now I am in div2 :(
Nice round, I like the problems. Thanks authors, great work :)
On a side note, just a little complaint. I don't like the time limit for Div1-C. What kind of sub-optimal solution did you wish to fail by setting a strict time limit? My solution takes close to 2 seconds ...
UPD: Got accepted in 980 ms after heavy optimizations. I see many accepted solutions taking more than 800 ms. Really don't see the point in setting time limits like this. Please try to keep this in mind when you are setting problems in future.
This submission for C didn't pass and I'm salty: 28999828
I mentioned in another comment that it's possible to solve Div1A/Div2C even when a, b ≤ 1018 in nearly constant time (basically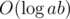 ) without using any integer greater than 1018.
) without using any integer greater than 1018.
First, you need to know how the intended solution works first. We want to express a = x2y and b = xy2. The intended solution is to compute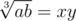 , but this will not work here because ab exceeds our bounds. So we need another way.
, but this will not work here because ab exceeds our bounds. So we need another way.
Find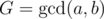 , which can be done by Euclidean algorithm. Euclidean algorithm, finding the GCD of a and b, never uses any integer greater than max(a, b). Now let a = Gp, b = Gq.
, which can be done by Euclidean algorithm. Euclidean algorithm, finding the GCD of a and b, never uses any integer greater than max(a, b). Now let a = Gp, b = Gq.
Back to our intended solution, we want to do a = x2y and b = xy2. Thus G = xyg, where . Moreover, this means x = gp, y = gq. So a = g3p2q, b = g3pq2.
. Moreover, this means x = gp, y = gq. So a = g3p2q, b = g3pq2.
Thus we can obtain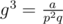 , since we know the values of a, p, q. Now, we can easily find g by the same cube root algorithm. This gives x, y, and thus we're done. If at any point there is a non-integer involved (for example, g3 turns out not to be an integer, or g3 is not a cube), then the answer is NO; otherwise, the answer is YES.
, since we know the values of a, p, q. Now, we can easily find g by the same cube root algorithm. This gives x, y, and thus we're done. If at any point there is a non-integer involved (for example, g3 turns out not to be an integer, or g3 is not a cube), then the answer is NO; otherwise, the answer is YES.
This basically means the problem could have used a, b ≤ 1018 and C++ people can still solve the problem, even if they have to take an extra step as above (compared to people with arbitrary-precision integers like Java and Python users, which can implement the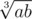 step directly).
step directly).
I implemented this method during the contest, and it turns out that it even runs faster than the intended solution. Probably because long long arithmetics are much slower than int.
The truth is, nobody will care about Python users if that means making problem significantly harder. And making problem easy to Python and Java and far harder for C++ users is not what coordinator should aim at, so your point is invalid. 700000 numbers is far from "massive input" in my opinion and slow input in Python is much less important issue than making problem three times harder for C++ users.
[Suspicion of cheating]
Look at ColdSu submission time, isn't it suspicious? he basically solve div 2 A-C in 11 mins with 2 WAs in between.
If that is not suspicious enough, look at his previous contest, the submission time is very close to each other early on.
Ok fine, maybe he is a really fast coder, so let's look at his previous contest code.
28218772 28213808 28225192 28216740 28232863
We will notice that there is 2 different template, where the first 3 uses same library and the last 2 uses a different set of library.
Ok, maybe he just uses 2 kinds of template. Now, let's look at his tab width. The first 3 and last 2 have different tab width again. Isn't it too suspicious?
KAN
It might or might not be a cheater. Nevertheless, you should report such findings privately to the coordinator.
Ok, I will keep that in mind next time. Though, I usually prefer the idea of transparency, so mind explaining the rationale?
slowest system testing :( ...
It's probably because of long execution times on C. However don't be unsatisfiable, they started the system test pretty fast, and 1 h after the contest end it's at 82%, while sometimes they don't even start the system test by 1 hour after the contest.
Figured out a solution for Div2 D problem using persistent segtree (to count different elements in range) and divide and conquer optimization for dp. Could not code it at time, but I'm glad to see people getting AC with this solution. One of the best problems I've seen on Codeforces. Congratulations to the writer =)
huehuehue
Impressive! What is your secret? Offering a lamb sacrifice prior to the contest?
After every AC on systests you have to listen to this: https://www.youtube.com/watch?v=IIeSGUK-Lyo
It's an AC-song.
After following this advice, my rating is monoton increasing. It seems to work!
Cheers to you!
I got accepted on Div.2 C o(N*170)!
rating predictor?
I got timeout in C because I put:
Instead of:
I hate this round!
P.S. Is CodeForces became harder recently? I previous 3 contests I couldn't even solve B. I've been blue...
Same thing. I added cin.tie(nullptr); and replaced endl with '\n', and now my solution passes easily (343ms).
In the past ios::sync_with_stdio(false) has been sufficient. This is bullshit.
Same thing, but in upsolving =)
But hopefully we learn something today.
Unfortunately, it won't help in my case. There are unlimited number of tiny things to know in order to get it right.
So today, I missed a tiny thing
a_n, previous 3 rounds I missed another tiny thingsa_(n - 3),a_(n - 2),a_(n - 1).The problem is that when after
krounds I will need some tiny thinga_(n + k)and even ifa_(n + k) == a_(n), I most likely forgeta_nby that time.The only way to get improved in competitive programming is to solve problems at higher rate than forgetting tiny things.
In my case of having full-time job and participating/upsolving once/twice a week, I learn tiny things at the same rate I forget them. That's why my rating is completely flat over fucking years (after removing statistical noise).
I enjoy very much learning new concepts and new algorithms but my rating is not high enough to solve interesting problems using interesting algorithms (segment trees and more).
In this case you should just add this line to your template and never return to this frustrating bug.
Same here. Lost 100+ rating:(
For Div2C, two conditions are necessary
a*b should be perfect cube.
gcd(a,b) should be divisible by cube_root(a*b)
How to prove second part? I found it by observing few test cases and intuition.
If you multipy by k_1,k_2,...,k_n, and their squares, then both numbers will be divisible by (k_1*k_2*...*k_n), because you multiplied them both. Also cube_root(a*b) = (k_1*k_2*...*k_n).
Problem C was very-very nice, respect to the authors
Please help me with my solution of Div2 — C. http://mirror.codeforces.com/contest/834/submission/29023242
The output from my system matches the jury's answer for visible inputs but the codeforces system gives the wrong answer.
I have seen the correct approach for the problem, want to know what error caused this for future reference.
Thanks
nope, it doesn't, third line (it's even written in checker's comment: wrong answer 3rd words differ — expected: 'yes', found: 'no')
yes it does for the online judge but when i run the inputs manually on my computer terminal, the answer for 3rd is 'yes' same happens for some other inputs also.
This has happened to me a few days ago... What I suggest to do in this case is to ideone your code (www.ideone.com) and check if the reading is ok (in my case, it was solved by doing this). Another thing, maybe it can be some precision error, because you are using double variables. Try adding some epsilon and recheck your code. Hope you solve it =)
Thanks it seems to be a precision error. I added small value before taking the cuberoot and it was able to pass the 2nd test case. But then it got a wrong answer on the 928th input of 6th test case. This input is not visible so I am not able to figure out that if it is a precision error or some problem with my algorithm. Is there something that can be done to solve the problem of precision?
http://mirror.codeforces.com/contest/834/submission/29080463
Can someone please elaborate on how to solve D without dp optimisations?
Any tip for Div1D?
"the numbers of red and black threads differ at most twice" sounds like a bad condition to me. Let's change it. Let R and B be the number of red and black threads on the path. One can verify that the original condition is satisfied if and only if
R - 2B <= 0 and B - 2R <= 0. That's much better because this condition is additive (that is, we can glue two pieces of a path together knowing this pair(R - 2B, B - 2R)of values for each piece).Let's assume that we fixed a vertex
vand we what to count the answer for all path that go through it. We can represent each vertex as a pair as shown above. After that, we need to count the number of such other pairs that the sum of their first and second elements are both non-positive. It's some kind of "sum in a rectangle" queries. We can do it inO(N log N)using sweep line and a binary index tree. We also need to subtract the pairs from the same child ofv(it's done exactly the same way).vis not fixed, though. But it doesn't matter. We can fix it using centroid decomposition.Alternatively, you can calculate products for paths where 2B - R ≥ 0 and 2R - B ≥ 0 and multiply them. Every path will appear in product once or twice (at least once because 2B < R and 2R < B can't hold at the same time) and only good paths will appear twice. So to find the answer to the problem, you need to divide this product by product of for all paths.
You sir, rocked this problem
how you make sweep line + BIT online ? because we should add some new points for some fixed v, and sum query of a rectangle.
how you add points ?
There's no need to add new points. We can generate all points and all rectangles (for a fixed
v) and answer all queries offline after that.So, how you don't count more than answer !?
You can run this algorithm once for a tree "with plus", and then run it separately for subtrees of root(centroid) "with minus".
Ok,thanks .
As I wrote above, I subtract the answer for the pairs from the same child of
v. It takes care of redundant pairs (including pairs of a vertex with itself).what's wrong with the this code for DIV2/B. same code code got AC with cin instead of scanf. RunTime Error Code-:Your text to link here... Correct Code-: http://mirror.codeforces.com/contest/834/submission/29003340
when i removed "," between %lld then also it gives runtime error link-: http://mirror.codeforces.com/contest/834/submission/29024786
Try using scanf("%lld%lld\n",&x,&gd); it may be the case that, when you read the string, you are getting the remaining characters of the line of the integers. Also, try removing the "ios::sync_with_..." command I think it will work using this =)
Div2 D
Contest submission: typedef long long ll; (TLE)
While upsolving: typedef int ll; (AC)
dont know when i am gonna stop using typedef and #defines
How did ColdSu manage to get purple from green in three rounds?
Two contests to be red .... :))
I am really curious how did he do that, I mean he was green 3-4 months before.
read this
Does anyone have any idea on how long it is before we get the English editorials?
I do. As soon as we manage to :)
Thought so :P
Got Div2 C TLE because I used endl and did not include cin.tie(0); Fucking bullshit!!!!!
Woke up today morning and saw both my submissions were 'skipped'. Can someone explain why that happened ?
May be your code matches with someother code which is already submitted earlier
what's wrong with my code about Div2 C? 29017171
You just check for prime factor less than or equal to
a, but you have one factor bigger than that(eg 66 = 2 * 3 * 11). Also I think that this solution will get TLE verdict.I check the square of a prime less than or equal to 'a',so I think 'a' will be 1 or a prime greater than 1e5.And I get WA on test 2,I hope someone can explain what's wrong with my thought.
The last prime may be less then 1e5 and even if it is the case you still have to handle this after the loop. Run your code to this case, the right answer is YES.
Thx!Just 'a' will be 1 or a prime after the loop.I pass the test 2,but got TLE on test 9.
Div 1-C problem's time limit is quite too tight. I have a solution with complexity O((K+9,K)*log(K)*K) but takes 4 seconds for test max.
My code: #29034060
I keep getting WA on test 2 in div 1 A 29038659. I dont understand what is wrong with my program
UPD: It's fixed now, just consider case:
1 25000 5