


Hi everybody!
I am writing this post from a sunny Tehran where the 29th International Olympiad in Informatics is being held. Me and Mikhail Endagorion Tikhomirov are here as a part of Russian Federation delegation on the Olympiad.
In about four hours the first round of the main competitive programming school student event of the year starts. Russian Federation is presented by one of the youngest team ever in the history of Russia on IOI consisting of:
Vladimir voidmax Romanov, Denis Denisson Shpakovskiy, Alexandra demon1999 Drozdova and Egor Egor.Lifar Lifar.
In Russian version of this post me together with Endagorion are going to make a text coverage of what is happening on the contest. We will mainly concentrate on Russian delegation there, so we are not going to duplicate all the live information in the English version of the post, but we invite all of you who are interested in IOI to discuss the problems and the results in the comments section below.
SPOILER ALERT: the text of this post and the comments may possibly contain lots of spoilers to the competition problems, so if you are going to participate in any online mirror, or you simply want to solve the problems buy yourself then be careful.
PS Some photos with comments in Russian are available at the Telegram channel here.
Some useful links (more to be added):
- Rankings by snarknews with lots of extra interesting information.
- List of the contestants according to the great IOI database.
- IOI website
- Post by SeyedParsa about the Olympiad.
- Mirror contest hosted by Yandex.Contest.







When will the contest start? :)
time
Would there be a live scoreboard?
We do not have a link for results either. Let's wait until they announce it.
How can we see the live results?
http://ranking.ioi2017.org/Ranking.html or
http://scoreboard.ioi2017.org/Ranking.html
does not seems to work for me...
Hmmm, I'm not sure why it's not working for you. Perhaps try using a different internet browser. I'm currently using chrome...
can you capture us a ranking pic
The correct link is: http://scoreboard.ioi2017.org/Ranking.html
online mirror
1 hour after the original start.
All links you need:
http://ranking.ioi2017.org/Ranking.html
https://contest.yandex.ru/ioi/contest/4767/enter/?ncrnd=5279
http://jonathanirvin.gs/files/ioi2017/day1/notice-ISC.pdf
http://jonathanirvin.gs/files/ioi2017/day1/nowruz-ISC.pdf
http://jonathanirvin.gs/files/ioi2017/day1/train-ISC.pdf
http://jonathanirvin.gs/files/ioi2017/day1/wiring-ISC.pdf
So far the have asked not to disclose the content of problems. The PDF's are not available by the links you given, I believe, for exactly those reasons.
Yeah, I will enable those links once we are allowed to upload the problems, or the mirror contest on Yandex has started.
re-enabled
Anyone knows how to submit problems on contest.yandex?
Here you can get some python soft, which watches for submissions of listed participants and sending some alerts on their's submissions. Probably, I fixed all changes in format from 2016 I already found.
PS. To watch for teams other than Russian you should change participants
UPD. Bug in subtask merging fixed
Everything OK with contest.yandex? I got 100 on C, but don't believe it
Their checker seems to be wrong because I sent solution which always returns 0 and got 100 points :D
As long as I know, they are working together with scientific committee on resolving this issue.
Could someone please rejudge all the submissions? My 42pts solution to Problem C should have been a 0pt one. Edit: Fixed now,thanks!
I think Wiring (or at least something very similar) was used in the Moscow Pre Finals ACM workshop this year, though I'm not sure on the original source.
Statement of the problem in Moscow Pre Finals
Hello! I provided that problem (plus Casting) in Moscow Pre Finals, and I wrote about that here : http://mirror.codeforces.com/blog/entry/53499?#comment-375609
Is everything ok with first problem? I've got 1.82 points for 02.out which is correct.
half of the time has passed
matthew99 : 0
Deemo : 0
Usa team only one participant is on the scoreboard
something wrong ?
maybe they are applying tourist strategy? :P
https://twitter.com/jonathanirvings/status/891323914814672901 https://twitter.com/jonathanirvings/status/891324469238738946
shame :(
anyway, I believe that there is something wrong with the scoreboard
look at Yuta submissions, it says that he got 100 in the third problem
but the scoreboard does not show that
and every time you reload the scoreboard the whole results change
the scoreboard seems ok to me. Yuta score is 219.67 as of now
everything is ok now :D
VPN problem :/
Do you have to use VPN for websites hosted in Iran or what?
There is really only one USA contestant on site, it looks like he came with the Chinese team (straight from China).
OMG geniucos is place 100. That's not fair. Also other chineese participants have very low score. I hope in the last minute to see +100 points and each of this participants.
Women have to cover their head, really? Non-muslims and guests of the country too? In 2017?
is this what disturbs you the most in 2017?
for me what disturbs me the most is that sometimes pornstar is more successful job than programming in 2017
For those who don't believe me link1 link2
Yeah, credibility of that statement was crucial to the downvotes
EDIT: Lol, I opened the links and they tell that in fact average programmer makes more, so even your sources contradict yourself xD
Now I noticed that link1 provides more than one estimate for yearly income, but at least some estimates mentioned are more than what link2 provides.
anyway, I believe income of pornstars varies a lot from person to person. what's why I said "sometimes" in my statement.
For various definitions of "successful". Money isn't everything.
I agree, but what are other factors of success than money? I can think of fame, but I don't think this favors programming over pornstar.
anyway I don't want to go deep into this discussion since I only wanted to say that women covering their head is not the biggest issue of 2017 and it seems that there are a lot of pornstars fans here who will keep downvoting my comments and furthermore this topic is not related to this blog topic.
job satisfaction? even though programmers orgasm less while doing their jobs, i believe they are, in general, more satisfied than porn stars.
You don't orgasm when you get AC?
not always literally :d
Oh, but children in Africa are still starving/dying of thirst in 2017 — how can you talk about pornstars!! Is this what disturbs you the most in 2017?!
Just because you can one-up something bad with the existence of something worse does not make the former any righter. Your argument makes no sense in response of what dalex said.
is this what disturbs you the most in 2017? Y ou care about and the fact that your country sponsors the war in the Donbass?
Stahp
We were allowed to take it off during contest, fortunately.
Omg! Attila Gáspár last minute first place submit
Tourist strategy maybe? :D
Though AFAIK he doesn't participate on online judges like CF, so probably haven't heard about it. (He is from the same country as me)
:oo
Like a real boss!
Looks like he got WA on the last 13 minutes and then solved the problem just in time.
is it rated?
For me it was crucial to note that this game is equivalent to the game where every person chooses outgoing edge every time (it is not fixed after first visit) and winning condition is whether train visits charging stations infinitely many times. I guess it was real motivation, but it was just harder to define such game properly.
Now we can try searching for a trap P. Trap is a set of vertices such that there is no charging station in P, for every outgoing edge of second player's vertex in P there is an outgoing edge to trap and for every first player's vertex on P all its outgoing edges lead to trap. In other words a set of vertices so that if train enters it then second player can ensure that train stays within it and since there are no charging stations there, he won.
We can find trap as a complement of a set S which is constructed in following way: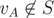 has an edge to S then put it there
has an edge to S then put it there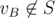 has all edges to S then put it there
has all edges to S then put it there
1) S:=charging station
2) if
3) if
where vA and vB are shorthands for some vertices belonging to first player and second player and steps 2) and 3) are repeated until possible.
It is obvious that we can't put any vertex from S to trap and that if we can't put no more then remaining ones form trap. Every trap is included in that largest trap. So we successfully identified some of vertices where B wins. However we can find more of them. If we can enter trap from vB then clearly it is also winning for him. Analogously if all edges from vA go into trap it is winning for B as well. So we can keep adding them until there are no more which we can add. It may seem like we identified all winning vertices to B, however in second step we may have identified some charging station as winning for B, so we may as well forget it was charging station because once we enter it we know that B won. If that happened, we run whole procedure once again from scratch (with updated set of charging stations). And again, and again, and again... Until it stabilizes. If at some phase we didn't identify another charging station as winning for B, we already identified all winning vertices for B and it is easy to see that remaining ones are winning for A.
There are at most n phases and they can be simulated easily in topological sorting manner in O(m), so total complexity is O(nm).
Does anybody have their checker code for A to test the output? I'm getting WA on Yandex, but my checker gives me 85 points.
I am having trouble with this too, is there a specific way we are supposed to submit the output files? (Name, extension, etc)
You have to submit a .zip file with 01.out, 02.out, 03.out etc. inside it.
It doesn't have to have all the files, if you submit a zip with only 01.out, it will get judged too.
Thanks!
Really strange results, I think.
So many good rated programmers on CF, do not have so good result on IOI... Both CF and IOI team (other sites too) should think who made mistake ( maybe nobody, but for me something looks wrong ).
What did happen with USA team, I see only one programmer on the list ?
These contests are really different from each other. Nobody did anything wrong.
but even past gold medallist like reyna and geniucos(silver) did not perform well though
Look at the distribution of places among participants from countries doing usually well. China, Iran, Romania, Bulgaria, Poland.
Has someone seen the logic? Something went really wrong
Why is this even a point? Tasks today were slightly different, but still they were normal, algorithmic problems. I'm glad that competitive scene is not boring and other countries have chance to have good scores as well.
Normal, algorithmic problems =)
My point is that this IOI day was very unusual. And pointing about CF / IOI difference — usually there is high correlation between IOI medals and CF ratings. Usually way less good people fail the contest completely.
Look at the IOI predictions : almost all people predict Reyna and matthew99 to be in the top5.
You call this "not boring', from a observer's point of view. I would rather name it depressing.
Yeah, I agree with you that some results of day 1 are quite surprising, mostly due to the output only task.
On the other hand, the IOI contest system doesn't check the country of a contestant and give extra points, but it only evaluates the submitted code. If certain countries are so strong, why didn't they submit better codes?
Because who would think that on the output only task solutions which are just a simple bfs from a random cell will get > 80 points.
First problem ruined the standings. Couldn't they give a normal easy problem like in all other iois...
Not you again complaining about bad distribution of problems topics/difficulty/type/whatever xD
Why not? lol
I thought you replied to me and I was ready to start a flame war. =)
If Usain Bolt usually runs 100m in 10 seconds we will not run it in 11 during the Olympiad.
However, such things happen at programming contests. Sometimes contestants just fail completely and nothing can be done about it.
Similar situation happened this year on Polish OI. Several strong contestants with international medals failed the OI badly. There was a problem with faulty testcases that let many wrong solutions pass. This time it's output only task. You can't be prepared for all, it's more than running 100 metres.
In my opinion, in IOI there can be more catastrophe — due to the blindness of the scoreboard, long-duration contest and a few hard tasks, contrary to CF — in which you basically try to solve from first problem. Results depend on whether a student can find relatively easy task and successfully solve it. 3-problems are not enough to prevent the catastrophe, but there is still another contest day.(I still think 6 tasks are not enough, though) You can see what will happen then.
For predicting, predicting IOI winners are very hard. Predictors take too much weight on ratings on CF — but some students do not even participate in CF, like the winner today, and contest tendency are very different as I mentioned.
Yeah, Poland has only two participants scoring in ~ gold medals, terrible performance. Romania claimed 5th and 6th places, terrible as well. However China's scores is indeed a mystery. But it is participants fault not some mysterious underlying factor that went wrong. Output only task may have tweaked results in a bit unpexpected way, but don't put too much blame on it. And you know, you can't expect all strong contestant to excel. You seem to always be very surprised that there exist some contestants that underperformed (last POI as well), but that is just statistics.
I personally find wiring problem really hard and wouldn't solve it during contest, but train was at most medium to me. Optimal strategy for nowruz in my opinion was to quickly code something that works fairly sane, get ~70 pts and forget about it. And still there is second day and probably some outliers will fix their score.
I didn't mean those countries failed at all! The distribution is just "a bit" bigger than standard =)
"Distributon is bigger"? What does it even mean?
Usual Chinese: 1 3 5 10. This year Chinese: 3, 40, 76, 122.
Kacper, for your own sake, please do not use words you don't understand.
https://en.m.wikipedia.org/wiki/Distribution_(mathematics)
I thought the most natural interpretation was a probability distribution with large variance/standard deviation...
Let's ask him if he meant bigger variance :D. Did you, kpw29?
I also had completely no idea what he meant, +1 for kostka
I meant "contestants are at totally random, usually worse places than usual". Sorry for my bad English, I didn't want to offend your statistician feelings
In my opinion that's how IOI should be. The tasks were interesting and none of them required some complicated algorithms or structures — just pure thinking and observations. Yes, the standings are surprising, but how does that make anything 'wrong'
People from places 1-10 are not allowed to express their opinions =)
Just kidding, congratulations for your performance!
Thank you! I completely agree that my opinion is biased, but come on, it wasn't a bad problemset. And the relative scoring problem gives you 80+ easily and is a great tie breaker as well :D
You still have a chance for a bronze <3
I will try my best to get it
Congratz <3
I will explain my comment on a little different way :)
I didn't read tasks, 95% I could not solve something when I see amount of AC. I believe problems had good quality, I saw problemsetters and they are amazing.
But distribution of tasks today wasn't so good :
Difference between gold and silver now 130 points, bronze with 50 points.
Many top programmers had really bad place ( as top countries )
Big amount of contestants couldn't solve any whole problem, or even half
I do not know what is first task, but looks like approximate problem, when other problems are too hard, it is not good to put approximate problem. Top coders will try regular problems first, spent hours and many will have small amount of points, and all other coders will optimize their approximate task 3-4 hours, write fast brute-forces for other and finish as high-placed medalists...
Best programmer will win at the end, there is no doubt I think, all reds can show second day that they deserved gold, but distribution wasn't good.
They saved energy for today rated contest :D
Could someone provide the editorial to today's problems?Thank you!
Few claims:
0) Solve subtask when all red sockets come before all blue, really easy
1) Assume we are working with only optimal solutions. Let denote cables as RB and BR depending on what color is left socket. Then there are no two RB and BR cables with intersecting interiors. Otherwise we can somehow switch them and get smaller solution
2) Because of 1 we can divide whole line into intervals so that within each intervals all cables have same color of left socket.
3) If we take some of such intervals then one of these two cases holds: a) if we take sockets of cables in that interval then all red sockets are before all blue sockets (or all blue before all red) or b) we can divide this interval into two and do not cross any wire (it follows from another exchange type argument)
4) What gives us observation that we can focus only on solutions that consist of disjoint "atomic parts" so that in such atomic part all red/blue sockets come before blue/red, what gives us already O(n2) dp and can solve third subtask.
4.1) Watch out that two consecutive atomic parts may have one border socket in common, as in RBR case for example.
5) So we should look at input as consecutive groups of monochromatic sockets. If a new group is starting we can determine optimal point of dividing previous group (left part we take from dp and right part goes into new atomic part). It holds that if we keep appending points to new group then this optimal points of partitioning only move left. Moreover we can search them trying to move our point one by one, no divide&conquer opt needed, what gives us O(n) solution. No idea why, though (but it got 100 pts). I have some intuition about it but it is rather blurry. Can somebody enlighten me?
Let me first rephrase that in the DP and the transitions.
State in the DP[g][l] is, where g is the number of monochromatic groups processed and l is the number of right-most elements from the last group not paired with anything. Solution is DP[number of groups][0]. Let the size of the g-th group be G[g].
Exchange argument shows that the wiring in former groups doesn't affect wiring in the current one.
The transitions are:
The complexity is at most twice the sum of group lengths, that is O(N + M).
Why does this work? Well, from the exchange argument you presented, the sockets groups connected shall be consecutive. It should be clear that if there are more socket on the left, it pays of to use the right-most one multiple times (while all others just once), and vice versa.
For the first transition, how do we store that the left-most point from the next group is already paired?
In addition, how can we calculate transition 2 with prefix sums?
First question: You don't. You just pair it again in step 2. It's fine.
Second question: What you essentially do is pair B[x..x + k] with R[y..y + k]. WLOG red color is right of black. This means that the sum of lengths is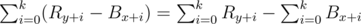 — that is, difference of two subarray sums. You need to be careful when calculating k, x and y, there are lots of +-1 errors to do :-)
— that is, difference of two subarray sums. You need to be careful when calculating k, x and y, there are lots of +-1 errors to do :-)
Thanks!
Are x and y just the left-most unmatched positions in the monochromatic segments?
EDIT: Turns out yes, I got AC with your method. Thanks again!
Yes, my solution is something like that and it got 100.
dunno y but I read "wiring solution" as "wrong solution" ...
What about the following sequence of sockets: R R B R B B? I do not think your claim 3) holds.
It holds. Connections are 13, 23, 45, 46 and we can partition it into 123 and 456
Whoops. So now I'm confused. Which part of your solution isn't right?
I also tried implementing something very similar and for some reason only got subtasks 2 and 4.
My solution got 100 pts xD. All claims I did are correct, but I just don't know why the last one is correct (about optimal point of division moving left).
Is the following claim true?
Assuming claim 4, the optimal splitting point of a series of B R R ... R R B must be (a+b)/2 where a = pos[first red] or pos[blue before first red] and b = pos[last red] or pos[blue after last red]
Not sure if that's related.
Are you trying to consider 4 cases in final version of algorithm or was that a way of stating 4 claims simultaneously :P? I tried similar claims and they work for the subtask with [1, n+m] coordinates and it is even doable to prove it (up to +-1 all versions are equivalent). However for a full version of problem they didn't seem to work. I tried points close to (pos[firstR] + pos[lastR])/2 (+-10 sockets around this point) but it gives WA. Then I gave it another thought and deduced that optimal point lies between (pos[blueBeforeFirstR] + pos[lastR]) / 2 and (pos[firstR] + pos[bluePastLastR]) / 2, but there can be a lot of them and I think we would need to search them all in a solution based on that fact.
And what's up with Italy? Usually they perform poorly, but now all of them got 100p from B. Looks like someone leaked the problems tbh smh fam.
0 100 0 results are suspicious but there is no way to prove even if they cheated somehow. This competition is based on trusting the leaders.
seems to me this is a old problem from years ago link which was used recently. Maybe all of them seems to coincidentally came across it?
Organizers cheating is way worse than contestants cheating :)
There's a quarantine as well.
There is always a possibility of problems leaking, but I wouldn't suspect cheating based on just that. Maybe they have seen something similar, or talked about techniques needed to solve it. It may look suspicious, but 4 people is too little sample to draw such bold statements. And they didn't score 0 100 0 either.
Italy team leaders here. What can I say? We were quite surprised too by our team performance! :)
We never cheated and never will, for the record.
By the way, we are here in Tehran if anyone wants to chat us up about this. We have the same usernames on Telegram.
I will also add something: one of my research topics is Parity Games (you can check it looking for Giorgio Audrito on Google), so that I even had an already-implemented solution for task Train. I also quickly discussed with Jakub Łącki about that being a known problem, but I didn't raise objections since we never explained that topic to the students.
If I wanted to cheat, it would have been much easier for me to just pass the Train's solution, instead of working on the Wires' one (which I don't even really know, apart from the hints they provided us).
So leaders telling the organizers that their problem is well known isn't enough reason to reject the task? What could be worse?
Just copy problems from some papers and you have IOI task ready. Here you go future IOI hosts.
Well for parity games I don't think it's problematic. But if it's for the other way around (like, that wiring one), then it's quite serious.
There are different understanding of an expression "well known". I don't think this was a serious issue, train didn't seem to be known to contestants. However one year ago when I was beta-testing IOI, I solved second subtask of aliens (what could have been treated as full problem for n-1 contestants) by copying my old solution from an old CF E problem (and adjusting it slightly to this problem) it was still not enough for organizers to exchange it. I absolutely hate fact it was posed as IOI problem.
Wow, strange to hear such things about the Aliens problem. For me the fact that intermediate subtasks were somehow straightforward DP optimizations is completely discarded by the contribution this problem made to the everyone's knowledge of DP optimization techniques. After that IOI the so-called (at least in Russia) Lagrange optimization provoked lots of discussions, even though it appeared on some Asian judges before.
Yeah, I agree that this problem made a considerable contribution into community's knowledge about this very nice technique, however that's not a main goal of a IOI task. There are just three problems a day to make a nice and entertaining contest which is a final destination point of alogorthmical olympiads education for many contestants. They should be given problems that make a fair medal distinction and are very fun to solve, not as Enchom said ones relying on who has read more theory.
By the way, I suggested a task for that 2016 IOI and it was rejected because idea you need to have to start working on problem could have been encountered on some already existing tasks. I agree, that's a valid point to disregard a task on IOI, but there was a ton of other things you needed to figure out to solve it, it had very nice subtasks substructure and etc. When I heard this I thought "oh, ok, I understand this, that's a fair point", but when I learned that alien task was chosen, which basically asks "Do you know a this do opt technique? If so then 60 ptd. Do you additionaly know this technique nobody knows? Then 100 pts" I felt insulted.
And by the way, why is it called Lagrange optimization? I have searched through some papers about it, but do not remember seeing Lagrange's name. To me it is called "parametric search"
Langrange usually means that you are moving a constraint to the objective function, so it makes sense here. Although I am very surprised that this has appeared in IOI, given that the committee seems somehow strict about restricting the techniques to what appears in the syllabus (from what I have heard).
One reason is that there are not many substitute tasks available (because preparing a task requires a lot of work), and the best tasks have already been included in the task set. So if a task is rejected, then the substitute task is probably not so good.
In fact, I have attended the IOI task selection meeting quite many times, and a proposed set of three tasks has never been rejected!
Also: team leaders have to translate the tasks, which already takes a long time. If the task set is rejected, then there will be further discussions etc. and it will take a long time before the translation can begin.
I don't buy that, why you think some weak people perform well = maybe cheat?
ishy got bronze in ioi2013 and then he came first in ioi2014, do u think he cheated? ofc not. Plz correct this point of view and attitude.
My opinions / questions / rants about problems
In my opinion, this problemset is worser than IOI 2013 Day1, however bit better than IOI 2010 (which was at least experimental and taught setters a lesson)
I don't get the hate for output-only problems. They are unique in their own way and I personally really like them. Ever since one was given in 2010 I have been hoping for more. You could get 80+ points with very simple solutions. Maybe there is some labor work if you want to push for a few extra points, but at the least it is a great tie breaker.
P.S.
IOI 2010 is my favourite problemset of all time, so perhaps we just have a very different view on IOI
Can you tell me what was your very simple solution, and the reason why it works? If it's a very simple solution that's easy to come up, and prove, and get 80 points, then it's hard to understand the scoreboard.
My thought-process during the competition:
Try something completely randomised. Got WA. Hm, maybe I should give this problem more thought.
Okay, so, we essentially want a tree with a lot of leaves. Which trees have a lot of leaves? Well, ones that aren't too deep. I wonder how I can get a tree that's still big, but not deep. Well, the spanning-tree from BFS is as shallow as you can get.
Straight up BFS won't give me a tree, though. How can I modify it? Well — just go with the simplest idea — if when processing a vertex in the BFS queue we have already processed more than one of its neighbours, just straight-up throw this vertex out.
Yeah, that sounds good. I can imagine it working if I pick some fairly central cell as my BFS origin.
Got 80~85 with that. My code was essentially just one BFS. I tried picking different origins for it at random, letting it run for a few minutes and ended up with 88 pts.
There's no need to prove anything — it is super intuitive that this will perform fairly well in the average case and you have all the tests from the beginning of the competition. A quick visual scan of them shows them to be fairly random.
I see. So it seems that 80p is not really labor-heavy, but rather about ideas. I apologize for it.
Still, I don't like the concept of output only tasks. In most cases, after easy hurdles we are usually only left with menial works, overfitting etc. I don't think "trying lot of super intuitive stuffs and submit the best" are that good either. It's not appropriate for 5 hours, and I like problems which I know why my solution work. I don't like to code for all my solving time too.
I understand your point of view and I think it just boils down to personal opinion. I have seen more competitors that dislike such problems than competitors who like them, so I can assume that I'm in the minority for the moment.
Some people refer to this as "great soluton which can't be more intuitive", so I will just point out that its main motivation "Which trees have a lot of leaves? Well, ones that aren't too deep. I wonder how I can get a tree that's still big, but not deep. Well, the spanning-tree from BFS is as shallow as you can get." is completely shite, that doesn't make any sense if you think about it. However it doesn't change the fact it still does something sensible, BFS will pack vertices densely, will not leave holes that are hard to fill and waste space, but provided justification doesn't hold what breaks "what a great way to think about this problem" argument.
What exactly is your problem with my logic? I haven't claimed that this solution is great — I was just showing how you can get good points with a simple thought-process. Maybe I'm just dumb and got points by being lucky with my logic, as seemingly implied by you, but in that case could you enlighten me as to why my logic is complete "shite".
Ok, so since I guess my comment was kinda offensive (:f), I better explain myself and I did considerable effort :P.
First of all, tree has a lot of leaves if it is not deep? I have no idea where have you got this idea. Probably you imagine something like "oh, binary tree has a lot of leaves and trees with long branches don't". But full balanced binary tree has haLf leaves and is shallow but a comb (path with one leaf attached to every vertex of path) has also haLf leaves but its height is half of its size. In my opinion better intuitive description of when tree has a lot of leaves is when every non-leaf has many leaves attached to it on average (which is kinda equivalent, but maybe a bit more intuitive wording).
However we should not forget that trees on grid are far from general trees. For simplicity assume we talk about trees on empty nxn grid. They have quadratic expansion (|vertices on height d| = O(d^2)) as apposed to binary ones that has exponential. In fact every tree on grid has O(n) height which is already far from shallow.
I prepared pictures of few patterns we can come up with and measured their performance and their properties.
As you can see, whether tree is deep has 0 correlation with whether it has many leaves. Diameter of a tree is rather a "macrostructure" property whereas whether tree on grid has many leaves is rather "microstructure" property. It is obvious that BFS will not produce trees 1, 3, 5, but at least for me it is not intuitive which of trees 2, 4, 6 your BFS can produce and I think it may depend on details of implementation and results they give vary a lot.
Tree from BFS. Much better than your patterns =)
I don't think so. This looks like it has density of leaves 1/4 (I am not 100% sure, though) whereas in my patterns densities are 1/3, 1/3, 0, 0, 1/4, 1/4 (it can be proven that 1/3 is optimal density)
I think its density is also 1/3.
upd. I tested a bit, and if I was not mistaken, it makes 0.3 density on large empty field. But with wrong start position, it left some corners not filled at all, reducing density to 0.25.
So it seems to be really a good solution, because it produces a good answer, is really simple and needs no handmade patterns.
Your patterns 1 and 2 are also good, but it's hard to adapt them to a field with obstacles.
I agree that this looks like a really good solution and Enchom's 88/100 prove this. I also agree that my patterns are hard to adapt to field with obstacles and that's why I coded substantially different solution which was decent, but not very good also (74 pts). But my point was not proving that this solution is poor. My point was to prove that Enchom's thought process was completely off and he got lucky because his solution performs well because of substantially different reasons than ones he mentioned.
You gave some counterexamples with fixed patterns, but his words "Which trees have a lot of leaves? Well, ones that aren't too deep." are still correct in general case. This can also be rephrased as: "We should branch out as often as possible."
I would also like to add, that idea with BFS come up as opposite to DFS, which obviously generates long paths without leaves.
"Which trees have a lot of leaves? Well, ones that aren't too deep." are still correct in general case. This can also be rephrased as: "We should branch out as often as possible."
No, these words make no sense and no, they can't be rephrased this way. And no, I didn't give pathological counterexamples, these are perfectly fine examples. I see no connection between diameter and number of leaves. However your rephrasing seems fine to me since number of leaves can be expressed using average degree of internal vertices and size of tree, but that is another irrelevant point.
Don't defend this point simply because you're on the same side of "existence of output-only tasks" argument.
Dude, all I mean by that sentence is that if you're gonna be picking some fairly random tree and you want a lot of leaves, by making it not deep you essentially guarantee that there will be a good amount of leaves.
Of-fucking-course that you can find examples of deep trees with many leaves and not-deep trees with few leaves. That's the whole point of output-only and marathon problems — nobody is optimising the worst-case scenario.
As MrDindows said, in this particular problem the idea of not-deep tree comes mainly from opposing DFS and BFS. Try and run a DFS and check out how many leaves that will give you. My argument about depth essentially just tells you that BFS will be much better.
You can continue claiming that my logic was faulty and I was lucky. I am not sure if you're doing it simply because you dislike these types of problems or because you just invested too much time in this argument, but my logic on this particular problem is not off. My statement clearly is not correct in the general case, on hand-made examples, but in this problem it's more than enough to give you an idea that BFS will perform well (as in opposition to DFS or other types of traversals)
The `simple solution' that I had in mind was observe (from either eyeballing the data, or a for loop) that there are almost never 10 rocks consecutively (###########). Using this observation, one can divide the columns into groups of 10 using vertical #s, connect these up at the bottom (stop these vertical dividers at row n — 10), and solve the vertical strips separately. For each strip, one can find the leftmost path going upwards, and then extend it to the right once a while to form leaves.
I think in a grid without 10 #s in a row, this gets about 10% of the total grids as leaves, which then compared to the values of k given are good enough.
Of course, picking random location and BFSing is even simpler than this (there is also an iterative leaf adding scheme (permute the cells, turn them into .s as long as things don't break) that also does very well). On the other hand, I view construction as a shorter `proof' that the required values of k aren't too hard.
All test cases have k ≥ 0.2 * n * m, so this vertical splitting approach might not fetch more than 50% points. On the other hand, picking 100 random cells and doing a BFS from them gets about 20% of the grid as leaves (80/100) which is more than what I had expected.
Yeah, I totally agree. I really enjoy oo-task as well and I think they should appear from time to time at IOI.
In real life, this model is probably more common.
Exactly. You get much more approximation problems than actual fully solvable ones. I enjoy such problems much more than problems that just test how much theory you've read.
" problems that just test how much theory you've read." — is this how you see typical problems? :|
Clearly not all, but I don't like it when some at IOI give off such vibe. For example last year's problem Aliens is a great problem — but the 100 point solution is based on a very unpopular DP optimisation. I hadn't heard of it before that problem and while one can argue that you can come up with it — I think it's reasonable to say that coming up with it by yourself is very difficult. Yeah, it's not a great example since only one person solved that one for a 100, but it illustrates my point.
I don't say in any way that I'm right, though. Reading things and learning algorithms/structures/optimisations is part of begin a good competitor and it should be encouraged, but I still prefer problems that you can solve even with minimal prior knowledge — just elegant ideas. I really enjoyed problem Wiring from today, for example.
For me, even though it is rather impossible to get 100 pts in nowruz, I would call it the easiest problem today. It was really no rocket science to get something not very clever at >70 pts in which case you can say you "did the problem". Remaining 20 pts was a time consuming battlefield for people at the very top. Even though I am against that type of problems on IOI, saying they require no brain and are only labor-heavy jobs is far from truth.
And I don't know who proposed wiring problem, but I doubt it was copied from paper. Even if it was, I don't think it's something really bad. Copying it from OpenCup was surely not a possibility since call for IOI tasks closes way before it was conducted. Probably if it had been spotted by someone from ISC it would have been removed, but it seems nobody knew that.
I always consider IOI as a quite different thing from other competitions like TC, CF, AtCoder, GCJ, FHC, ICPC, etc. In my opinion, the distance between TC and IOI is even bigger than the distance between TC and IMO.
Let's say, standard algorithmic competitions are freestyle swimming. Then, TopCoder Marathon Match is breaststroke swimming. IOI is individual medley.
I don't say it's good or bad — they are simply incomparable and different set of people like them. Obviously, high rated people on CF are not necessarily good at IOI.
I did the on-site contest, and I scored 100 on P2, never seen anything similar before. Definitely a genius "a-ha!" moment ;-)
IOI sucks since Richard Forster is gone(after IOI2014)
Someone correct me if I'm wrong, but doesn't the IOI President have mostly organisational work? The scientific committee chooses the problemset.
So they gave a top-5 task, a top-40 task and the rest can go and play a lottery of "let's see if my ideas/approaches are actually worth anything after implementing them". Nice.
Do you mean that usually tasks like today's first is a lottery?
Marathon-like tasks in IOI setting – yes. Why are TopCoder marathons multiple weeks long? Because it gives you time to actually analyze and optimize based on your results, try different approaches etc.
What can you do in 5 hours, when there are two other problems as well? Try to come up with one/two ideas, implement them and pray that they are the right ones, because you really have no way of knowing it for sure. Sure, in this particular instance there actually was a somewhat sensible BFS approach, but I can bet there were contestants with different sensible approaches scoring way less.
And then there are optimizations. Again, all you can really do is tweak a couple of things, randomize a couple of things and submit your best result. Depending on your luck this can give quite a significant point difference even with the similar approach. The scale of the issue depends on how much can it affect the leaderboard. The score on the last two tasks around medal cutoff is around 30. So if we just look at the first day, this is the task the decides bronze medals.
Dynamic programming in wiring gives you 7 points. Seven! This is usually reserved for complete brute forces. But at least you can get more than that by picking a better seed in the first task. So in my opinion ISC completely failed to create a contest for all of the contestant and heavily focused on the top 15% and threw a marathon-like task to differentiate the rest. I'm hoping that they realize that a lot of people care about simply getting a bronze medal and give them a fair way to obtain those.
Last year we got a really hard prbolem when 34 points were rewarded for obvious exponentional solution xD. Btw I solved wiring problem but have no idea how to produce a solution that gives 7 points and no more. Actually 30 points in total can be scored by O(n^2) approach, I thought it could have been rewarded more, because it really already demanded some careful problem analysis.
Isn't your DP solution this :
dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + |Ai — Bj|
I don't think making this to pass Subtask 3 is easy (at least, I don't see it right now)
Ahh, indeed :). When I said about O(n2) approach I actually had on my mind one from point 4) from my solution which in fact works in O(n * s), where s is the size of the largest group of consecutive sockets (which already has subtask 2 as its subroutine), but yours is "tru n^2" :P.
It's like really easy to come with a dp solution in o(n^2)(which cannot be upgraded, unfortunately), if you do dp[number of reds matched][number of blues matched]. I came up pretty fasy with that, but it leads nowhere.
I just have found out (after stress-testing different solutions) that this subtasks doesn't contain tests with 32-bit integer overflow. So, at least you can be sure that the answer in each test of this subtask is <=INT_MAX =)
welcome to iran, i wish you the best, good luck ! ;)
Let's rest our mind here and have a tea :)
Do you know if there's a mirror for day 2 too Zlobober?
Update : It seems there is.
How do you know, there is?
We plan to start IOI 2017 online mirror round exactly one hour after the start of official contest.
From Yandex website. I think they mean both rounds as they didn't mentioned about only the first day.
I knew that, I just thought you know something more :)
But well, in "Contest links will be available here." they mention linkS, so probably you're right.
Make sure you don't miss the editorial.