


Hello CodeForces!
I know this happened to everyone — you made an interesting mathematical/algorithmic/whatever discovery and you were very proud of it and later you realized it's already well known. What's your story?
I'll start:
I discovered a variant of Mo's algorithm around 4 years ago. I was solving the following problem: Given a static array a1, ..., an and q = O(n) queries. You are allowed to solve them offline. Each query has the form (l, r) and you're supposed to answer, if you were take all the numbers from al, ..., ar, extract them into another array and then sort that array, what would be the sum of all elements at odd indexes?
This is how I was thinking: If all the queries could be ordered such that both their left ends and right ends form an increasing sequence, you could answer all those queries by adding/removing elements from some augmented balanced binary tree or segment tree in O(nlogn). Then again, the same is true when all the queries can be ordered such that their left ends form an increasing and right ends form a decreasing sequence. So, why not decompose the set of queries into such sequences? When we sort the queries by their left end, this becomes equivalent to decomposing an array of numbers (right ends) into several increasing/decreasing subsequences. Then I remembered a theorem which states that, in an array of n2 + 1 numbers, there is always an increasing subsequence or a decreasing subsequence of length n + 1 — this means that we can decompose any array into  such sequences, in time
such sequences, in time 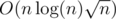 — perhaps there is a better algorithm but this was good enough for my problem. The final complexity is — there are sequences of queries and each one can be solved in
— perhaps there is a better algorithm but this was good enough for my problem. The final complexity is — there are sequences of queries and each one can be solved in 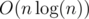 .
.
Also, what were your silly childhood discoveries?
I remember discovering, when I was around 7, that in some apartments you could run around in a circle through a sequence of doors while in others you can't — and I really loved those where you can! Later I found out that they were equivalent to cyclic/acyclic graphs.







I self-discovered binary search in a programming contest when I was in grade 8. The funny thing is, after the contest, when someone asked me if I used binary search to solve the problem, I said I didn't.
Who was not able to optimally play a game "Pick an integer number between 1 and 100, I will guess a number and you will tell me whether I guessed correct number/is it smaller/is it larger and so on until I guess it" when he was 8 years :P?
You have a bad sense of humour :|
OMG this is gold who downvoted this LMAO
I thought of a variation of sqrt decomposition on trees link. Though it was not something path-breaking , I felt I had come up with something on my own.
P.S. I realized it was a sqrt decomposition sort of thing only after some had mentioned it.
Probably the best algorithm that I've ever discovered by myself is bubble sort :)
There is no any special story, I just wanted to sort the given array.
Masturbation
Then I Discovered wikihow explained it and it was a well-known technique
Well, it would be too strange to discover it from someone else
actually it's aladeen to discover that from someone else
Orz
In a IOI team selection contest, I used the "Merge Small to Large" technique without knowing it has logarithmic time complexity. I thought it will just decrease the run time anyhow.
After contest, a friend of mine (Bruteforceman) asked me if I've used DSU on Tree. I said no, I just did some optimizations. xD
I found out how to find fib(n) in O(log n) in a boring school class . then i found out that fibonacci matrix is very well known :(
I self-discovered how to find LCA in O(logN) time while I was trying to solve a problem. After getting accepted, I looked the editorial and saw that it had already a name and algorithm to find it.
I don't know why your sequences of indices needed to be either increasing or decreasing? That seems to me like a stnadard Mo. However ~4 years ago I was wondering about Mo on trees when it is tricky, because given most naive numbering of vertices (preorder) if you move to the next number path to next vertex can be long. But I noted that if sequences of both leftpoints and rightpoints are increasing/decreasing then one pass will take linear time, so I wanted to decompose sequence of numbers into increasing of decreasing sequences in
increasing of decreasing sequences in 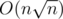 . Actually I only found trivial
. Actually I only found trivial 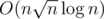 . But I discovered some way to do my main goal, Mo on trees in
. But I discovered some way to do my main goal, Mo on trees in 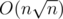 . It involved sqrt decomposition of trees where I divided whole tree into
. It involved sqrt decomposition of trees where I divided whole tree into  components of diameter
components of diameter  (I think it can be what sdssudhu wrote about, but I didn't read link). I think it was way before it became famous and now it has come to the point where people code this 4 times faster than me (recent Bubblecup :P).
(I think it can be what sdssudhu wrote about, but I didn't read link). I think it was way before it became famous and now it has come to the point where people code this 4 times faster than me (recent Bubblecup :P).
When I was probably 13 I came up with a formula for number of subsets of K elements of set of size N (binomial symbol) through trial and error.
Parking the bus.
I literally searched about it on geeksforgeeks first before I finally realized that its good to use quora too sometimes.
Dial's Algorithm, a fancy generalization of the 0-1 BFS. link
Wow, I actually "discovered" this as well :D
Lol even I have "invented" this in a recent contest. I posted a comment about it as well https://mirror.codeforces.com/blog/entry/76506#comment-611349
When I was in grade 9, I was inspired by the autocomplete function, and I self-discovered the Prefix Tree even though I knew nothing about graph or tree at that time.
OOP sucks.
How is this even related to this post?
Truth always finds a way to sustain
I discovered hash table. When I was in 7th(or 6th?) grade, I encountered a task that required me to output elements of an array in increasing order, where numbers are only at most 100. I didn't know hashing at that time and thought about sorting and comparing adjacent elements, which I thought was too much code. Then I found out that I could create an array of size 100 and for each a[i], set the a[i]-th element of the array to 1, and output all elements in the array that are 1 with a for loop. I proudly announced my "discovery" to my coaches, to which they immediately replied, "Oh you mean hashing". I actually knew there was a word called "hash", but not until then did I know what it really means.
I feel like this is closer to a "counting sort" algorithm than a hash table.
But congratulations on your discovery!
it's hash table where the hashing function is f(x)=x :P
When I was in Grade 7,I was confused with a problem:Given an positive integer n,and output d(1) + d(2) + ..... + d(n).(d(i) means the number of positive factors of i).I first got an equality:d(1) + d(2) + .... + d(n) = [n/1] + [n/2] + .... + [n/n].However,I didn't know how to calculate the sum in less than O(n) time.After a month, I met a Math Olympic problem:how many different values are there in [2000/1],[2000/2],.....[2000/2000].I soon found out the answer is close to 2sqrt(2000).A sudden idea came into my mind:why not calculate [n/1] + [n/2] + ... + [n/n] by grouping it into O(sqrt(n)) types?Then I managed to solve the problem in a time complexity of O(sqrt(n)). To my surprise,when I searched on the Internet,I knew that Yu Hao Du had already discovered the algorithm many years before!
I kind of discovered Red-Black trees. Although I knew BSTs at this point, I was aware that it was not balanced if the input was not, well, proper (ehh?!). So I wanted to come up with a way to balance the tree while taking the input. Although my idea was not fully correct, it was very similar to RB BST. Well, considering that I didnt know much about algorithms and data structures except of sorting and BST, needless to say I was quite happy, until I googled it and found that it was a well-known DS already. P.S. This was when I was in 7th grade. However I started CP in 9th, as I give more time to dev type things.
Here
When I was at the semi-final of NOI in 7-th grade, there was a question like "Given n, find all numbers x such that x! has n 0's at the end.". So, I discovered x! has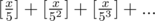 zeroes at the end, then wrote some untidy code and got AC, funny thing is that my code didn't work on sample case #1, but I decided to send it. Nobody solved that problem expect me, I was proud of it (also I was first at semi-final)!
zeroes at the end, then wrote some untidy code and got AC, funny thing is that my code didn't work on sample case #1, but I decided to send it. Nobody solved that problem expect me, I was proud of it (also I was first at semi-final)!
After starting math olympiad, I found it was just well-known Legendre's function :P
My simple but long detailed story :P
In 8-th grade (wasn't into CP then) I was fascinated by Apple's smooth scroll view effects and decide to make my own 1D vertical version.
As is widely noticed, when dragged past the bounds, the view moves gradually slower. I had no idea what function it was and randomly chose square root as the function from dragged distance to displayed distance.
But directly using square root caused a "popping" effect around the bounds because it grows at a different speed from identity function f(x) = x (during normal dragging) around x = 0. So I decided to find a point where it grows as fast as identity function.
After some brainstorming, I came up with the following: let Δ x be a very small value, then we just need to find such x where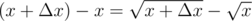 . Solving this, we get
. Solving this, we get 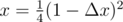 . Since Δ x is very small, we can say
. Since Δ x is very small, we can say 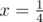 . This is the point where x and
. This is the point where x and 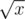 grow at the same speed.
grow at the same speed.
When I excitedly told one of my classmates about it, he said, "Yeah it's differential method, or derivative." Then I got to know it and found my discovery known to the world for centuries.
Upd. And this classmate made it to the National Training Team of PhO this year. Congrats!
I was almost discovered derivatives after we had a homework to cut from cardboard: models of some square functions. Every next distance to new dot you put on y axis increases linearly according to previous dot.
In 4th grade while we were learning to calculate squares of rectangles, I discovered how to calculate square of right triangles :D This was amazing for me.
I created the BFS algorithm by my own) It was required in the problem where fire was spreading in a maze) I coded about 200 lines of code :D
When I was 6th grade, just starting out with programming, I had a problem that required removing elements from a list in O(1). I thought about it a lot and invented my "Best Friends Array". Each element 'held the hand' of his two 'best friends' on the left and on the right correspondingly. When someone was to be removed, he just took the two hands he was holding and made them hold each other, then went away.
Doubly-linked list with a lot of imagination.
Delta encoding technique, in the contest i still got WA on systests but was able to come up with it having never seen it
I found how to find modular inverses of 1, ..., n in O(n), but now it's well-known.
I got to know this some long time ago and thought it is really great and hard to come up with and then I learnt about getting inverse of n! and then getting 1/i! from 1/(i+1)! :P...
I found Fenwick Tree could be used to solve Longest Increasing Subsequence.:)
I self discovered Co-ordinate Compression while doing a contest . More like an observation than an algorithm discovery
:)
When I was about 10, I learnt how to draw this thing without lifting a pencil, and self-discovered to generalize the technique for all drawings.
I believe many of you also did this ;)
Nb. It's eulerian path!
It's literally well-known problem =)) I solved it after a few of tries at a child.
I discovered the Newton-Leibniz Integral Rule when I was in 11th standard (16 years of age). I remember coming up with this cool method to solve Integral problems in which there was a requirement for differentiation of a definite integral and I felt like I had developed an algorithm for it. As it turned out, about 6 months later, this "algorithm" of mine was taught to us in school and sadly no friend of mine would believe that I thought of it long back!
I "discovered" that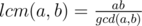 . More precisely, I forgot that the lcm concept exists and re-invented it, only to recall later that, well, this "discovery" was the least common multiple that I learnt at a very young age. The funny part is that I did it for a paper, and included a detailed proof. The professor who graded it did not make any special comment apart from "this is obvious and well-known".
. More precisely, I forgot that the lcm concept exists and re-invented it, only to recall later that, well, this "discovery" was the least common multiple that I learnt at a very young age. The funny part is that I did it for a paper, and included a detailed proof. The professor who graded it did not make any special comment apart from "this is obvious and well-known".
I also discovered it in 4-th grade and I thought it is new thing which is not known in science, so I decided to share it with my all classmates in math lesson, I told teacher that I found something new and I will share that at the lesson. So, I went to board and wrote LCM(A,B)*GCD(A,B)=A*B with big letters. All of my classmates checked that and kindly shocked, but my teacher showed us this theorem in our math book which was some pages later from lesson, so she thought I copied it from there and I got mark "2" :D (which is lowest mark in my country)
Old days, sweet old days...
looks like I am the only one who did not discover shit and was 24/7 messing with my little brother,you know fight club type fighting until one brother either gives up or loses one or two of his teeth,
now that I look back, I can understand why I am so fucking dumb >_<
I was literally searching for such kind of a comment...:)
Looking at other people's comments it sums up like they discovered some techniques or data-structures in their 7th or 8th grade (which I still don't know though :))....
How the hell they used to think like that...I used to pass my whole damn day by watching shows like Pokemon, Doraemon..:)
I discovered Rabin-Karp hashing. I was trying to figure out how to write a
std::map<std::string, int>equivalent in C, and I found out that you could represent a string as a base-26 number, and use that as an array subscript. However, I didn't know that it's possible to also take the string's hash modulo some prime p, so this approach only seemed efficient for strings with length smaller than 6.We'll talk about "well-known discoveries", also known as "independent discoveries", huh?) I'll start with silly childhood discoveries then (they're not stupidly ambitious at least).
At the age of four I've found a toy of my friend Savin (Savinov is his surname) by logical inference from the facts he was sure of (that's a simple trick). Also, I've convinced him that anyone willing to play with this toy could ask him do give it and he must give it for a certain amount of time. The second part of this venture wasn't as easy as the first one, but I remember it was based on my authority (I was sharing it with another guy Egor Chervov) and the fact that "you wouldn't've lost your most precious toy and you wouldn't've asked me to look for it". You won't believe, and that was a discovery, but since then I was in charge on finding the toys of a whole kindergarten group and ceasing the fights around them.
What I'm proud the most — I've never stolen a single one by hiding it somewhere only because the fact of losing the toy in natural way seemed "sacred" for me. This principle of deals and "losing sacracy" became tremendously important after the day when bad guys from middle school had started their assaults outside the building.
That was a hard time for a toy balance of our group, you know, but the only difference was that I, personally, couldn't get those toys back, but clearly I remained in charge for others, and I had to find a way out. I've started a policy of loan and barter (haha, the question was about whether you can take some toy with you when one of your parents will pick you up, so we had a daily stand-up on figuring out about the changes made, too bad we had no Kanban board xd), also, because of a bad balance (and a threat of crashing positive balance with Egor's authority), I had to escalate the interest of such relations by conducting specific games, I've used the characters from Wolfenstein 3D (we were repeating their behavior with minor changes, it was inappropriate to call someone "gestapo", "dr mengele" or smth) and rules from Need for Speed R&T (I was varying the importance of toy cars versus pistols and the toys that could be adopted as quest items). Too bad, but the problems become arose again: children love toys, but they still can have fun with a stick found on the floor or hide-and-seek games etc. so again I had to take a lead in another way.
That's a long story and now you can imagine what a mess had started when I've tried to conduct CP trainings and courses in university (plus semi-educational project practice) so I'll finish with well-known citiation: "The management problems arose right after you solve prevous ones", I took it from Evgeny Krasnickij fictional series. Weeeeell, I should add another citiation that would be an advice for CP trainings management: "You shouldn't be good at this point, you should be smart (do things in a simple way)", that one from Bobby Fischer, Chess World Champion, but he was telling about how chess messing up your approaches. Really, for now — there is no "good" way or even instructional material to prepare yourself (and most part of advices, including the thought that some "advice" can take place is a pure lie). It looks like Mayakovsky who was constantly thinking of how good his poetry is, the only way out here is to shoot yourself)) The only moment I've felt that we're doing the right thing is when I finally found my teammates in front of whiteboard (after a YEARS of our attempts to do things good) trying to build their micro-paradigm around how Grey code function
i ^ (i >> 1)and it's inverse works. That was the moment when I've discovered that we do pure algorithm analysis out of actual icpc semifinal, but it was kinda too late for our beautiful icpc career. Yeah, we were young and stupid in a places we should've been smart. But we were good in all senses, you may believe me, even out of limit of sickness.Oh, when developing my first board game, a minesweeper, I designed a function for uncovering all tiles that contains a 0 recursively (I was so proud), later I learned it was called DFS (I still have the code: https://github.com/AlexITC/Minesweeper-game-for-j2me/blob/master/src/Panel.java#L169).
In my first ICPC regional competition, I was fighting against a range query problem, I thought about splitting the array on several buckets of size M, guessing M and submitting for trying to get AC (10, 100, 1000), sadly it never passed the time limit, time later I learned that it was basically SQRT decomposition.
In the same regional, I was fighting against a straight forward trie problem, I had a crazy idea in my mind for representing the set of words using a Matrix with pointers, sadly I wasn't able to solve all bugs on time, time later I learned it was a trie representing using a matrix and it was simpler to just use objects.
Once I represented a kind of double linked list for solving a straight forward problem that didn't required it.
Once I had the idea of sorting an array in linear time using hashing.
One time I got the idea of hiding data inside images, using the least significant bit in each color, when I arrived home I was going to code a proof of concept, searched on google and discovered steganography.
Later, I started learning algorithms and my creativity went to the toilet.
He did not have enough imagination to become a mathematician. — David Hilbert upon hearing that one of his students had dropped out to study poetry.
Hilbert was one of the last who has studied all the existing mathematics. — Vladimir Arnold, 13th Hilbert Problem solver and MCCME director (until his death at 2010).
Ahhh probably I should stop citing too much, but this two perfectly fits to the contradictive connotation of your last sentence so I couldn't resist to post them.
Moreover, I don't think that your and mine creativity is any important in CF and ICPC problem solving and discovering something from algorithmic field unless you try to say that our creativity is somehow equal to those orange and red ones re-discoveries (I believe that it's exactly what is implicitly suggested to Div.2 users and what you've tried to do in your comment). You may call what those guys do (for example, Petr Mitrichev discovering Fenwick Tree after a day of upsolving IOI) as creativity too, but it's just a result, not a reason to itself existence, speaking less logically and more philosophically, let their creativity to be phenomenal for a second.
And one second after, let's remember that well-known causation of our creativity irrelevance is damn education/pedagogy, even in terms of upbringing, that we both simply haven't got (haha what a good topic for well-known discoveries). The most pleasant thing here is that we're free to ̶g̶e̶t̶ ̶b̶o̶g̶g̶e̶d̶ ̶d̶o̶w̶n̶ ̶i̶n̶ ̶d̶e̶b̶a̶u̶c̶h̶e̶r̶y̶ work on any programming- and computation-related subject in a way our ideas, awareness, originality, targets and results leads us (hahaha, that's really an advantage of amateurs and proletariate, discovery after discovery, what a perfect topic to become depressed :D).
I found out about Dijkstra's algorithm in the 7th grade and looked it up on the web and found a purely educational problem asking for the shortest path between a source node and a destination in a graph with positive edge costs. After reading that problem, I said that I can solve it on my own because it sounds very similar to BFS and after half an hour or so I got the idea, submitted and got AC. My teacher congratulated me for learning the algorithm but didn't see the source code and I had the illusion that I knew Dijkstra's algorithm until almost a year later, when one of my friends told me that I rediscovered SPFA and that Dijkstra's algorithm uses a priority queue instead.
Also, something that isn't as remarkable, I'd say is re-discovering Tarjan's dominance tree, after thinking a day or so about the problem Team rocket rises again after I made a bet with a friend that I can get AC in that time. I didn't really know it was called that way until my high-school coach told me that Tarjan discovered it first, as I didn't bother to check the editorial for the solution.
You must have gone (be going?) to a really nice high school for your teacher to know about dominator trees...
My teacher was also a competitive programmer :)
Next level luck
I discover a algorithm to solve k-th shortest path between two vertices x and y in directed graph in time complexity O(nlognlog(Possible Maximum length of k - th path)) with binary search length of k-th path.
But the best well-known algorithm have a better time complexity.
I discovered downvote button
Hope you discover sense of humor soon.
You too :))
Counting sort :))
I even named it.
Radix Sort (yesterday), Pseudodijkstra, D&C optimization using Segment Tree and others.
why the downvotes? What did I do wrong?
I rediscovered Vantage Point Trees and later realized that they are well known. However I still proud of implementing incremental search algorithm on VP Trees.
I discovered divisibility rules before I found them in the text book.
I discovered top-down segment tree, which led me to understand the link between recursion and top-down dynamic programming (just cached recursion but a completely new perspective for me at that time). Now I know it should be called lazy segment tree.
Last year, when I was 12 :P, I discovered formulas to generate pythagorean triples.
I later looked it up and found out they were generalizations of Euclid's formula.
The first formula can be obtained using $$$m=\frac{k\sqrt{2}}{2}$$$ and $$$n=\frac{\sqrt{2}}{2}$$$, while the second formula can be obtained using $$$m=\frac{k}{2}$$$ and $$$n=1$$$.
Back then I actually thought I had discovered something important...
Fun fact: I have used these formulas only once since then. It was a problem on codeforces.
i don't know any of this formula.
You won't believe me when I was child I did the same but for a^2-b^2,2ab,a^2+b^2, also I used this to find triplets.
During the contest today (the Chinese NOI Online, more exactly), there is a problem where a $$$n\times n$$$ matrix $$$T$$$ is given and for each of the $$$q$$$ given queries you need to print the sum of a row in the matrix $$$T^k$$$ where $$$k$$$ is given out. The constraints are $$$n,q\leq 100,k\leq 10^9$$$.
Obviously there is an easy algorithm: calculating $$$T^{2^p}$$$ for $$$0\leq p\leq 31$$$ and it takes $$$O(n^2\log n)$$$ each query since it only takes $$$O(n^2)$$$ to calculate the product of a vector and a matrix. But I only thought of the $$$O(n^3\log n)$$$ one and noticed that $$$O(n^3\log n)$$$ would get a TLE.
Then I came up with a rather awkward solution: let $$$x=\sqrt k$$$, I calculated $$$T^p$$$ and $$$T^{px}$$$ for all $$$p\leq x$$$, and then each query could be solved by two matrices multiplying.
That was not satisfying though, as it cost too much memory. Then I found a brilliant idea: why not choose a higher exponent $$$t$$$ and let $$$x=\sqrt [t]k$$$ instead? This worked quite well in $$$O(kqn^3+k\sqrt[k]{W}n^3)$$$ time and $$$O(k\sqrt[k]Wn^2)$$$ memory. Choosing $$$k$$$ to be $$$4,5$$$ is enough.
After chatting with mates it seems that this may not have been mentioned but not really practical, as it works slowly than the above one. All in all, still I am proud of myself!
So, in a way, you generalised square-root decomposition? Cool!! And in that way, binary exponentiation can be thought of as doing some sort of a segment tree on the exponent.
In fact notice that k*(n)^(1/k), as k tends to infinity, acts as kind of log(n)
because log(n) is basically the integral of 1/n, So, k*n^(1/k), if we consider, and take its derivative with respect to n, notice that it comes as k * (1/k) * n ^(1/k — 1) = n^(1/k — 1)
Notice that hence for large k, the derivative of log(n) with respect to n and your function k*n^(1/k) are similar, as n^(1/k — 1) becomes n^(-1) = 1 / n
Basically, we can think of log(n) as an extremely small degree polynomial in n, like n^(very small thing).
So, we can say, your complexity tends to the ideal log(n) complexity , as you make the exponent bigger!!
Meanwhile MikeMirzayanov:
I discovered dsu like not completely,but upto certain count I would compress the path.as I thought it would time out, due to not being familiar behind hidden ackermann complexity,but when editorial released they used similar thing with path compression with no limit.Could not solve the problem but was happy.
bubble sort it was :D
i do not know if it is good something to say or if it is something to be discovered but i was solving problems in windows sliding Technique since i started cp and after a while someone told me that this is a famous Technique
and i also discovered that the square of n is the summation of the the first (n+1)odd numbers
When I was 11 I "discovered" an algorithm to find the partitions of a positive integer $$$n$$$ as a sum of positive integers (different order = same partition) in $$$O(n^2)$$$. The dp is
$$$dp[1][1] = 1$$$
$$$dp[i][j] = (i \leq j)(dp[i - 1][j - 1] + dp[i][j - i])$$$
$$$partitions[x] = dp[x][2x]$$$
Later I wrote the algorithm in JavaScript, it was a complete mess.
A week ago I "discovered" that $$$\sum_{k \mid n}\varphi(k) = n$$$ while solving 839D - Winter is here, but that fact is quite unrelated to the actual solution to the problem.
A cyan here in the midst of orange and purples.
Anyhow, here I go. So I got really into programming around late January of this year and started with a website which is worse version of leetcode (Interviewbit).
I had no idea about multiplication under modulo and logarithmic exponentiation. The question was to find a^b%c. So discovered multiplication under modulo and faster exponentiation (to be fair I just found powers according to binary expansion of b). Later did I realize that it's a standard procedure.
When I was in 9th grade, I independently discovered a link between the pascal's triangle and the fibonacci series:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
Now if you see diagonally, you will see the fibonacci sequence. It is easy to prove using induction.
Where is the fibonacci sequence ?
mind = blown
I was solving this problem from CSES few days ago. I solve this using Fenwick Tree and Binary Search with co-ordinate compression — for finding $$$K^{th}$$$ largest element in $$$O(log^2n)$$$ time. So overall complexity was $$$O(nlog^2n)$$$. And just 1-2 days I found this post saying we can use $$$Order\, Statistic \,Tree$$$ for getting $$$K^{th}$$$ largest element in $$$O(log^2n)$$$ time. And finally from this post I realize that what I had implemented was $$$Order\, Statistic \,Tree$$$.
I discovered something similar to Mo's algorithm and Arpa's trick, also I discovered rerooting technique by myself. (I guess I also discovered some other techniques and algorithms by myself, but I haven't yet realize that they were discovered before)
I discovered Bipolar Orientation on my own, and we made a problem about it for NOI 2019. It turned out to be a known technique, which we only discovered after the end of the contest :(
Discovered Floyd-Warshall Algorithm while solving this task.
Problem
After solving that problem, I was scrolling some submissions and got Floyd-Warshall in a comment line, searched it and now I see I just discovered that. Feeling very proud.
I discovered a way to process subtree/path queries with updates by applying Segment tree over the tree flattening with Euler tours. At the time, I didn't know HLD and I was trying to solve the following problems from CSES:
When I solved them, I was impressed because that was not easy to see, and some of my friends who already knew HLD thought that was a good/creative solution. Turns out it was a basic tree skill.
Explained by SecondThread here.
I remember some night when I was 10yo I was laying down trying to sleep, I came up with the number of ways to pick up two items from a box, it was like this: if I had 3 items, there will be 3*3-3 ways to pick up 2 of thems, and if I had 4 items there will be 4*4-4 ways. I don't remember how I came up with this formula "x*x-x", but I remember being happy trying it on small number of items and getting the correct answers using it.
There were two I remember. In fourth grade I discovered how to add the numbers 1…n in O(1) by making pairs of them without ever knowing the trick.
Also when I first made some CP friends but I was still pretty trash at algorithms, one friend gave me a Mo’s problem when we went out for bbq back when nobody had taught me Mo’s. I figured out a solution which ended up being n^1.5 and in fact works for Mo’s in general, but was randomized and way more complex than it needed to be. It took about as long for me to come up with it as it did for the best programmer on the team at that point to prove the runtime was equivalent to Mo’s, but it was.