


As we all know, the C++ standard library class std::bitset is a very powerful tool for solving all kinds of problems [1].
Due to how it is implemented and how C++ works, it is not possible to create a bitset whose size is a run-time variable. However, if the exact size is not a requirement — which is often the case, there is a way to use bitsets that are only slightly larger than required, using template metaprogramming. See the example below. To compile, C++17 or newer is required.
#include <bits/stdc++.h>
using namespace std;
struct Solver {
int n;
template<int N>
void solve() {
bitset<N> bs;
std::cout << "Solving with bitset, N=" << N << '\n';
// do something...
}
template<int N>
void choose_size() {
if constexpr (N >= 1'000'000) {
solve<N>();
} else {
if (n <= N) {
return solve<N>();
}
choose_size<2*N>();
}
}
};
int main() {
int n;
cin >> n;
Solver s{n};
s.choose_size<32>();
}
If the goal is to optimize further, a tighter constraint can be placed on the relative size of the bitset compared to the argument by modifying the expression in the templated function call choose_size<2*N>(). For example, we can use 5*N/4 to guarantee that the used bitset is at most 25 percent larger than required.
Keep in mind that the number of different sizes used should be a reasonable number. In any case, the compiler must generate a function for each possible template parameter N. If this rule is not respected, it is possible that the compiler will crash or outright refuse to compile the code.
Edit:
Unbeknownst to me, Golovanov399 and clyring have previously written on this exact topic in their comments [2].
Thanks to everyone for sharing additional ideas!






 such sequences, in time
such sequences, in time 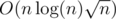 — perhaps there is a better algorithm but this was good enough for my problem. The final complexity is
— perhaps there is a better algorithm but this was good enough for my problem. The final complexity is 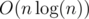 .
.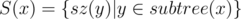 for all
for all  . I used class templates to save some memory — this is another interesting idea and a topic on its own.
. I used class templates to save some memory — this is another interesting idea and a topic on its own.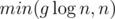 new nodes and take
new nodes and take 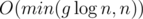 time. To understand this, think of what happens when one of the sets has 1, 2, or 3 elements.
time. To understand this, think of what happens when one of the sets has 1, 2, or 3 elements. . You now have access to all the sets, for each node.
. You now have access to all the sets, for each node.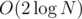 of them. We may also visit some others but we will exit immediately as their total is
of them. We may also visit some others but we will exit immediately as their total is 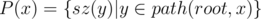 , and also
, and also 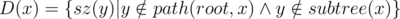 . Also, I wanted to try a new approach and see if it's efficient enough. And as it turns out, it is! :)
. Also, I wanted to try a new approach and see if it's efficient enough. And as it turns out, it is! :)