


This contest was held on October 22nd, but no solutions have been posted. Any ideas for FGH?
→ Pay attention
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | Radewoosh | 3415 |
| 8 | Um_nik | 3376 |
| 9 | maroonrk | 3361 |
| 10 | XVIII | 3345 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 133 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2026 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: May/21/2026 01:32:59 (g1).
Desktop version, switch to mobile version.
Supported by

Why the fuck are you minusing this post? It is a NP-Hard problem to understand CF Community. LOL.
http://mirror.codeforces.com/blog/entry/55503 this similar blog gets +20 while this got -4...
To be honest, much more than the community itself, I'm sick of people complaining about it...
I am sick about people complaining about people complaining about it.
I am sick about people complaining about people complaining about people complaining about it.
Ahhh... Not this again :/
For problem G (the complexity is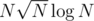 , not sure if it fits the time limit):
, not sure if it fits the time limit):
The x and y coordinates are completely independent, therefore we just have to solve the same problem twice.
To process the queries we use Mo's algorithm. At each step of the algorithm we keep a balanced tree of the values currently in the range (the balanced tree must also keep the sum on a subtree) (a treap seems perfect).
When we add (or delete) a new value to the balanced tree , we also update the answer accordingly. Indeed the new answer differs from the previous one by s - 2p - (t - 2c)v (where v is the new value, p is the prefix sum, s is the total sum, c is the position in the balanced tree, t is the total number of elements in the tree).
I tried doing something like that here, but I think it's too slow.
Compressing coordinates and using a Fenwick tree instead of a treap might speed it up a lot.
Ideas for F:
The coloring always exists and is always unique.
Assume for now that no line is vertical. Let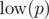 be the number of lines below a point p. Then the color of p is given by
be the number of lines below a point p. Then the color of p is given by 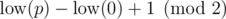 .
.
Hence we want to compute the number of lines below a query point. This can be done with the Bentley-Ottmann sweepline algorithm. As the algorithm maintains the relative position of the lines in a BST, we can do a binary search to count the number of lines below the point. The time complexity is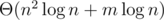 .
.
To improve the runtime, split the lines into k blocks of size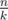 . Run the above algorithm for each block. This takes
. Run the above algorithm for each block. This takes  time, which is
time, which is 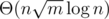 for
for 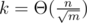 .
.
In order to account for vertical lines, add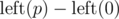 to the color of each point where
to the color of each point where 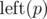 is the number of lines to the left of p.
is the number of lines to the left of p. 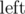 can be computed easily in
can be computed easily in 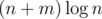 .
.
Ideas for H:
For each segment, consider the line thought the segment and for each endpoint of the segment the line thought that point perpendicular to the segment. Construct the arrangement of the lines. This takes Θ(n2) time and space.
For every segment, look at the arrangement-edges from it's line and mark all edges that are part of the segment. (By construction all edges are either part of the segment or contain no common interior with the segment). For every edge not marked this way, connect the two faces sharing this edge. Then sum over all faces that are not connected to the infinite face. The total runtime is Θ(n2), as the arrangement has size Θ(n2) and every line gets split into edges.
edges.
There might also be a solution based on random sampling, as the required precision is quite low.