


Всем привет! Сегодня, 13 марта в 21:00 MSK пройдет второй отборочный раунд Яндекс.Алгоритм 2018. Перетий в контест можно с сайта Алгоритма.
Задачи подготовлены мной, Михаилом Тихомировым. Я благодарю за помощь с подготовкой задач Глеба GlebsHP Евстропова, а также ifsmirnov, halyavin, kuzmichev_dima, scorpion за тестирование задач.
Всем удачи, увидимся на контесте!






Auto comment: topic has been translated by Endagorion (original revision, translated revision, compare)
Is it rated?
Sorry, it was my classmate
No!
Are you sure you don't want some downvotes? Maybe just one?
No thanks!
i have a lot of them :(
I don't think this round is on codeforces.
The qualifying round and the first round wasn't on here either, but it was moved to gym.
This contest is not a codeforces round at all.
I only solved problems as a participant.
Best of luck, guys!
Сложные задачи =(
Неприятная дифференциация по сложности
How to solve D, A and E?
E: note that the trees are equal if and only if the sequences of depths in Euler tour order are equal. Now, with one operation you can erase any number from any of these sequence by attaching it to the next/previous vertex of the same depth or deleting. Now just find the largest common subsequence of these two sequences.
Awesome problem, thanks Endagorion!
Nice! Thanks
The doesn't sound right, although it gets AC. Let's consider tree
This has Euler tour
How do you remove a 2?
In this case you should also remove the following 3 as well, so we can delete them one by one. Though I don't have a complete proof now.
The preorder traversal sequence of depths D can be characterised by the following property:
Removing 2 from the above sequence violates this, but removing either of 1 2 or 2 3 preserves it. Your claim now seems to be true — removing 1 2 can be performed by tying branches together (in this order), removing 2 3 can be performed by cutting leaves (in reverse order).
Seems we can just do it on pre-order traversal of the tree.
D : The probability of a permutation being fair is given by generating function:
This can be proved using inclusion exclusion. This can be solved in O(N logN ) using polynomial inverse.
BTW, I got TLE as in my code (which I copied from some other problem), I was using naive polynomial multiplication if product of sizes >= 1e6, or in this case, always. But still it was running in 0.25 s locally.
You solved that in and got TLE? I think something is fishy here. Haven't you forgotten some k in complexity or something xd?
and got TLE? I think something is fishy here. Haven't you forgotten some k in complexity or something xd?
No, I copied the code, and overlooked the line
if(a.size() * 1ll * b.size() <= 1000000) return naive_mul(a, b);, which I had used in the other code for some optimization in case of highly imbalanced sizes.Moreover, I was not using the N logN method, as it is harder to implement. In my mind I was doing O(N2logN), but actually it was O(N3). The N2logN code actually passes in 232ms
And can you get NlogN time complexity? From what I could think during the contest, I could only obtain Nlog^2 in best case (which fortunately wasn't needed)
Yes, you just use GP sum to get the answer as the coefficient of xn in , where
, where 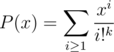
But what is GP?
He meant geometric progression.
Ah, yes, lol. My first solution was O(n2k) which I was able to speed up to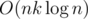 using FFT but decided to drop that approach since so many people solved it so fast and this would probably TLE. Then I came up with tricky incl-excl solution and did O(n2) solution but it can be speed up to
using FFT but decided to drop that approach since so many people solved it so fast and this would probably TLE. Then I came up with tricky incl-excl solution and did O(n2) solution but it can be speed up to  in exactly the same way as my previous solution :P.
in exactly the same way as my previous solution :P.
Can you please explain your solution a bit more? Some steps would do.
We have to exclude the probability that there is atleast one i, such that i + 1 has higher score than i in each stage. We have to do inclusion exclusion over subsets of {1, ..., n-1}. Note that every subset of size n - r partitions {1,..,n} into r chunks. In a chunk of size x the probability of scores being strictly increasing in all stages is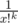 . And then you convert to generating function.
. And then you convert to generating function.
If you don't want to use generating functions, you can also keep a dp state as parity and length to get O(n2) complexity.
I had all of these during the contest. But I raised the multinomials to power K - 1 instead of K — because that's what happened in the denominator and I somehow convinced myself that it makes sense. Of course, the PIE didn't work on samples, so I abandoned this. Then, few hours later in the shower, I realised that 1203 - 4·603 is very close to those 966 thousand something and finishing the PIE will probably arrive to the correct number.
Also, since A,D,E were difficult, I didn't bother to read F at all, only to solve it in about 30 minutes after the contest.
Why am I like this!
Sorry, I don't get it. In a single chunk we don't need all the scores to be strictly increasing in all the stages right? We just want one of the comparison between i and i+1 to be non increasing. If we knew the length of increasing sequence length in all the stages we could do something like product of 1/l_i! Where l_i is the increasing sequence length in ith stage.
Lets say we choose a subset s of {1, 2, ..,n-1}. Consider a graph with edge i connecting i, i + 1, and the edges from s divide the graph into chunks. We are including/excluding the cases where for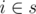 , i + 1 has higher score than i in all stages. If we consider connected components(chunks), it is equivalent to saying that, in a single chunk, all the scores are strictly increasing in all the stages. Then we include/exclude such ways.
, i + 1 has higher score than i in all stages. If we consider connected components(chunks), it is equivalent to saying that, in a single chunk, all the scores are strictly increasing in all the stages. Then we include/exclude such ways.
На таких задачах финал бы проводить.
А еще было бы удобно в объявлении давать ссылку на раунд. И вообще как-то позволять перемещаться между раундами.
И общие результаты смотреть.
It seems Yandex servers are 4-5x slower than my computer. D with N = K = 1000 runs in 1.4 seconds on the testing problem, 0.3 seconds locally.
And how long on CodeForces?
I also had similar problems, my N log N algorithm for F TLE until the last minute, I had to optimize it.
1.2 seconds. Also 4x slower than my computer.
Well, seems like you have a nice computer!
Apparently. Work computer, pretty new, intended to handle anything normal, but it's no supercomputer. Intel Core i7 2.9GHZ.
I'm used to expecting a performance boost on any testing server, not a drop...
Could you please describe how to solve F?
First note that this is always possible: take two NE-lattice path that only differ in two consecutive instructions — one has NE (we call this one upper) and the second has EN (we call it lower). Selecting both paths changes the colour of exactly one cell. For each cell, there is also a pair of such paths. The answer is thus at most 2K.
Note that sometimes, we may fix multiple black cells using two paths. We want to minimise the amount of such pairs. We can do this using the following greedy algorithm:
Note that there are cases where multiple black cells in one column may be fixed using the same path pair — it should be relatively easy to list all the necessary conditions for both the upper and lower path be a NE-lattice path.
The answer is at most 2 * P, where P is the amount of the paths. When the bottom-right cell is black, we can see that the lower path of the corresponding path pair is just EEEE...ENN....NNN. This path does not change colour of any cell, so it can be omitted. The answer is 2 * P - 1 in this case.
Wow, great! Thank you for the detailed explanation!
It's equivalent to the maximum number of color changes in any path from the NW SQUARE to the SE SQUARE (not point) only going south and east.
Как тут 256 дизлайков поставить?
По какому принцыпу роздают майки на Яндекс.Алгоритм?
.
Интересно, будут ли футболки тех, кто получил их в нескольких треках, переходить следующим по рейтингу участникам?
Как определяют топ 256 Алгоритмического трека? Сумма результатов по всем отборочным раундам или как?
https://contest.yandex.com/algorithm2018/algo-results/
Interesting problems but very poor choice of time limit in several problems and wrong and very misleading clarification in D ruined it for some people for sure
Very nice problems! So sad that I finished E in last minute and it didn't work, because I used vertex depths and forgot to calculate them in dfs. :(
My ideas on A in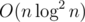 :
:
String is good if we can make it empty by sequential removing two consecutive equal characters. But we can also prove by some case-analysis that we can also remove first and last character if they are the same.
We will do divide-and-conquer: each recursive call solve the problem on (L, S, R), where L is 'reduced' prefix we cannot touch, R is 'reduced' suffix we cannot touch and we want to calculate number of ways to swap two different characters in S such that L+S'+R is good. Reducing prefix and suffix is the following: delete two consecutive equal characters in one of them while you can, and delete first character in L and last character in R if they are equal while you can. It is easy to show that characters in L and R can match only with characters in S' so if |L| + |R| > |S| then there is no solution. Now we want to split S in two equal (by length) parts, do recursive calls if we want both swapped characters to be in the same half, and then somehow solve the problem if swapped characters are in different halves. If we will do it in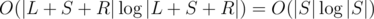 time, then we will solve the problem in
time, then we will solve the problem in 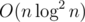 time.
time.
Now we have L+P+Q+R which should be transformed to L+P'+Q'+R (and the transform should be consistent, but this can be handled by trying all possible variants of transform as there are only 6 of them). The idea is the following: for each character of P that can be changed with this type of transform I want to calculate hash of reduce(L+P'). L+P'=(L+V)+changed(c)+(U). We can maintain reduced form of L+V going from left to right and maintain reduced form of U going from right to left. All the operations we do are push_back(char) or pop_back(), so all this can be done by persistent stack which is a trie. Also we want to maintain binary lifts in this trie + hash and hash of reversed string of corresponding binary lift. Then reduce(L+P') can be done like that: we already have reduce(L+V+change(c)) and reduce(U), now all we have to do is find the largest suffix of reduce(L+V+change(c)) which is reversed prefix of reduce(U). This can be done by binary search + hashing, for binary search we will use our binary lifts. Then do the same for right part and calculate the answer (reduced(L+P') should be reverse of reduced(Q'+R)).
problem B can be solved with dp?
You dont really need DP for this problem. It has greedy solution.
Find positions of first and last maximums in array A, first maximum in array B. And solution is:
1. Move A to first maximum
2. Move B to first maximum
3. Move A to last maximum
4. Move B to end
5. Move A to end
i understand,thanks
I guess today was the first time in my life when I was really angry after seeing "OK" next to my submission. I wanted to submit D blindly because this was unlikely to get it wrong after passing samples, but accidentally submitted it as open and expected "accepted for testing" verdict but got "OK" :(. Took 27th place instead of 20th.
Why the hell are people downvoting this? Sure, it looks like a humble brag at first glance, but I think that the concept of a stupid yet costly mistake would be relatable to many.
Endagorion, will the editorial be posted?
How to solve B and C
B : Comment some inches above this one
C: Notice that order of operations does not matter, Only number of operations does. You can simulate the whole process, since there can only be 100 * 100 different combinations of spell 1 and spell 2.
For each such simulation, proceed greedily,sorting the monsters by strength, and decreasing all of them by NumberOfTimesSecondSpell * DecrementViaSecondSpell.
Now for all monsters still having some strength left we apply the first spell till that monster is vanquished(in which case we proceed to next monster) or we run out of first spells. Notice since we sorted them by their strengths, the one most likely to be killed gets killed first.
Eventually we count numbers which are <= 0 after the process is over.
It’s starting to become very non-trivial to attend contests, especially when they’re announced in the same day. Too bad.
To be fair, the schedule for the Yandex contest has been up for ages. Endagorion's post was just a friendly remainder.
How to solve F?
Перетий. Новый элемент, открытый Яндекс контестом xD