


Hello again,
Thank you for participating. It was a great experience for me and I learned a lot. Hope you learned something as well! I'll try to avoid the issues some of you complained about, next time.
The tutorial of problems [A-C] was written by Motarack, [D-E] by Dark, and all were reviewed by Reem. Thank you guys!
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Solution: https://ideone.com/EEORpR






I have a question on C consider the input 2 4 2 3 by the algorithm we go to x=2 first, then the first interval would be [0,2], however this won't produce the best answer where we choose [0,3] and the output is 0 0
Initially, we create the group [0,2]. But when we face the color 3, we check the colors before and find that we can extend the group [0,2] to be [0,3].
Can you please tell me the answer for test case: 2 3 9 5?
Shouldn't it be 10 3 rather than 7 3 as 10 is lexicographically smaller than 7?
Compare them as numbers, not strings. So 9 is lexicographically smaller than 10.
Thanks a lot for your prompt reply.
But I got really confused after reading the word 'lexicographically' because it means dictionary order which is not the same as that of numbers ( that you just mentioned ). Am I missing something here?
Lexicographical order applies to arrays (vectors) or any container in the same way it applies to strings. So if you have a vector a and b,
a < bwill compare them index by index as values and return true if a is lexicographically smaller than b.I should have mentioned how they are compared in the statement.
I get it now! Also can you please explain the run time, how is it O(n+k) I am getting it to be O(nk). Link to my solution. Thanks in advance!
Actually it is O(n+c), where c is 256.
The first for loop is O(n), inside it you loop from v[i] back until you find an assigned color, then you assign all colors in the range.
As each color will get assigned once, the total number of operations in the third loop is O(c). Note that you move back on the unassigned colors then assign them, so the second loop move only on unassigned colors, so it is also O(c).
I really liked these problems! Thank you for writing!
I think problem E is the most wonderful problem in this round. The greedy is obvious, and there exist many different O(nlogn) implementation which are acceptable, e.g. binary lifting, heavy-light decomposition and BIT...
Check my solution, it gets low execution time and it's different than anyone else's I've seen.38076021
a good solution. maybe you didn't learn those algorithms, learn more and do better. :)
I'm sorry to say that this solution is actually O(n^2), which should not pass. Indeed, the broomstick will cause it to TLE (I don't know what that type of tree is actually called).
How to prove mathematically that solution of problem B Merlin will work for all input and never give answer "NO". I know it is pretty obvious to observe carefully and make assumption on that.
I think we can prove it by using symmetry
So it means answer "NO" is also possible if n is even (by symmetry). That is if n is even then the relation is no longer symmetric hence there may be a case where "NO" is also possible if k is odd
We'll never have 'NO' cause if n is odd we can always build symmetric picture. Maybe my code will help you understand how i get answer: 38052171
For problem D, may anyone please link me to an article or tell me about how can we efficiently tell the number of distinct elements in a subarray? I see some approaches on web, but they differ from what most of the participants have used to do this problem.
We can do it by using compressing data, some code:
sort(b.begin(), b.end()); b.erase(unique(b.begin(), b.end()), b.end()); for (int i = 0; i < n; i++) c[i] = (int)(lower_bound(b.begin(), b.end(), a[i]) - b.begin());A is original array, B — copy of A, C — position of A[i] in sorted array B[i]. There is my solution: 38065300Thanks a lot for your reply, actually I should have updated my comment because I already understood this due to courtesy of step_by_step. Here you can see his nice response.
In C editorial, it's written that:
"If the size will exceed k or such y was not found, we create a new group with key equals to max(0, x−k+1) and assign all colors in the range to it."
But, If the size of the previous group "y" will exceed k after extending it, we should create a new group with key equals max(y.lastElement +1, x-k+1), shouldn't we?
Yes you're right. Fixed it, thank you!
Thanks :D
In fact, in problem D we can find that, if a*b=k1^2 and b*c=k2^2, then a*c=k3^2, k1,k2,k3 are non-zero integers.So the Solution Complexity could be O(n^2). Here is my code: http://mirror.codeforces.com/contest/980/submission/38062477
This assumes that sqrt(x) works in O(1). I think this is slower than factorizing the numbers.
The complexity of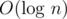 .
.
sqrtis actually implementation dependent. Usually, it is implemented using Newton's or similar methods which areIn problem c why is the key of new group equals to max(y+1,x-k+1)
Because y + 1 is the first unassigned color that you can use in the new group, and x - k + 1 is the minimum color you can include in the group without having more than k colors in the group.
38063984 this passed
Thank you for sharing this. The brute force solutions I tried passed all random tests. I had to write different generators for similar cases but my focus was on solutions that go up counting the number of ancestors that are not included yet. I'll check this solution again and see if I can update tests for practice.
Can someone please explain the test case 1 of C problem 'Posterized'..
Given the test case — 4 3 2 14 3 4 We need to find the lexicographically smallest possible array after applying the posterization. Now, firstly we encounter 2, we assign 0,1,2 to the group key -> 0, then 12,13,14 -> 12. Now when we encounter 3, since 0,1,2 are already assigned 3,4,5 -> 3 Hence the answer 0 12 3 3
why this code is TLE 38045885
and this one is Accepted 38070326
though they are the same logic and the the same complexity
the deference is that the TLE code is badly implemented and uses up to 8 seconds
while the Accepted code is 0.1 seconds
can anyone tell what was slowing the code in the bad implementation ?
I had the same issue: 38055867 I couldn't figure it out.
Another solution for B:
Fill columns from left to right until there are k hotels. If k is odd, fill the last partially filled column and clear one of the cells in the column before, that will block paths for both villages.
Handle k = 1 and k = 3 by placing k cells in the middle of row 2.
how can this be proven. I upsolved using symmetry as mentioned in editorial but no other proof can be found out.
All of the following grids have the same number of shortest paths:
Because entering that one empty cell won't lead you to any of the targets and moving back from that cell will increase the length of the path.
Now since filling that cell or leaving it won't affect the number of shortest paths, assume that it is filled. Now we have symmetry around the horizontal axis.
lol that is easier Thanks Hasan0540
Absolutely true. And it feels like the checker does not accept asymmetrical solutions... Please tell me if coding such a solution worked for you !
Actually this is the solution used to generate jury's answer so it must be accepted.
The checker counts the number of shortest paths between opposite corners, and if they are equal, your solution is accepted.
Well in that case I must have forgotten some limit case ! :) I already considered the "3-width" case apart. It is a bit particular.
BTW I generate solutions like that :
Which are clearly also right !
Check this case (test #5): 49 1.
Thanks for the awesome problems! I wish there was a explanation for a example though. :)
I think the editorial for D mentioned this, but I didn't quite understand it. Why cannot we use a set to count the number of distinct elements? It seems to me that we are only doing O(n2) insertions, each only takes time. Why is this too slow? Also can someone explain how to use frequency array to solve this? It seems simple but I don't get it.
time. Why is this too slow? Also can someone explain how to use frequency array to solve this? It seems simple but I don't get it.
My TLE: 38081525
Because nesting set operations in N2 code means the total complexity becomes N2log(n) which is nearly 3×10^9. (Normally we suppose 10^9 iterations take 1 second)
While you can map each elements into another array access time of which is O(1). To do that, prepare map < int, int > and int[5000]mapped. Now in input phase, you can map each elements into single index of mapped.
eg) 28 -> 7. Find if 7 exists in a map. If not, map[7] = nextidx + + . now mapped[i] = map[7].
Thanks so much for your help. From your comment and looking at some other people's code I implemented the map and frequency table. However, I am still getting TLE and not sure entirely why, as it is pretty similar to some other people's code. Could you look at my code and point out why it is still so slow? Is it my factoring that is taking too long? I mean I think I implemented the array correctly? Thanks a lot.
my code: 38084465
Your implementation of the mapping is correct, but you're still accessing the map in the O(n2) part of code which is O(logn) per operation.
Instead, you can simply replace the line
A[i] = ai;with the lineA[i] = mapp[ai];and using A[i] in the code below.Hope this clears it up.
No your factorization code looks fine. The problem is, your code still has NlogN complexity. operator [] of
mapis basically same withmap.findwhich takes logN time. You have to maintain an another array that "maps" each element into another. The reason whystd::mapis used is to mark which index of mapping array should be mapped for each element. In short,mapping[A[i]]should be accessed in O(1) somappingvariable is just an int array. We usestd;;mapto fill this array.Thanks, now I understand why it was so slow and fixed it. I actually didn't realize accessing the map took logarithmic time.
@orange4glace, can u help me for D problem, actually i am using unordered_map instead of set in N^2 code but still it is giving TLE.
Here is my code :
38425925
Although unordered_map has constant time complexity, that
constant timeis not the same with trivial operations such asaccess of array. So the actual time complexity of your code is αN2 where α is the constant value of unordered_map operation. This value can easily exceed over 10^8 where α ≥ 4I think this would be helpful to explain it more. :)
Firstly, unordered_map with default settings has a pretty large constant. It can be decreased a lot by calling reserve and max_load_factor methods as explained at the end of this blog. I think without this unordered_map is slightly faster than map, with this it should be much faster — assuming random input.B solution by filling from center using regex (all answers have vertical symmetry axis) — perl: 38089563
in problem C i get wrong answer in test 9:
My answer 33 236 236 149 89 24 123 130 66 53 16 60 130 107 96 75 247 198 156 107 89 181 5 221 139 146 96 40 75 12 107 89 139 191 123 181 0 181 205 24 181 205 60 146 96 75 156 191 24 96 66 123 156 156 149 53 0 114 107 123 16 188 173 139 236 44 205 205 107 243 40 53 181 12 188 243 156 221 114 198 82 181 209 173 198 66 75 44 24 31 236 254 75 60 173 123 149 118 33 33
Juri answer 33 236 236 149 89 24 123 130 66 53 16 60 130 107 96 75 247 198 156 107 89 181 5 221 139 146 96 40 75 12 107 89 139 191 123 181 0 181 205 24 181 205 60 146 96 75 156 191 24 96 66 123 156 156 149 53 0 114 107 123 16 188 173 139 236 44 205 205 107 243 40 53 181 12 188 243 156 221 114 198 82 181 209 173 198 66 75 44 24 31 236 254 75 60 173 123 149 120 33 33
wrong answer 98th words differ — expected: '120', found: '118'
And i don't understand where is my mistake? 118 better than 120, and it correct number for input 121
Notice that 119 turns into 114 which means range [114, 119] is mapped to 114. so 121 cannot be mapped to such value lower than 119 since K = 7
Thank you, orange4glace
Does problem F require a concept other than BFS or DFS?
If you have a way to solve the problem under the picture (solved using prefix sums and a heap), no. It is just DFS (for finding bridges and cycles) and BFS (for finding shortest paths).
The time limit on D is way too low, is it possible update the problem to increase it? Lots of solutions with ok time complexity are failing
Hi Guys, can I solve problem E in this way?
pair(x,y) where x is the degree of node labeled y sort(pairs) x in increasing order and if x is equal then by increasing y. remove the least pair from the set and modify the pairs accordingly(decrease the degree of neighbour of that pair)
In other words,I am trying to remove the node which is a leaf having least label.
No, here is a test case :
6 3
1 4
4 6
1 5
5 2
3 6
Your answer will be : 2 3 5
Correct answer : 1 2 5
I tried to solve it this way, and it gave me WA7. If you go to status page you will find plenty of WA7 for the very same reason
38078719
Let's take into account that, in the end, the problem is asking us for the smallest lexicographical subsequence of 1..N consisting of k elements we can get, given the conditions imposed by the problem. The main problem with your idea is that it has no notion of this concept.
Let's draw the test
The answer you get by removing leaves is {2, 3, 5}, while the optimal is {1, 2, 5}. This is due to the impossibility to know what sequences you can get if you follow some path up instead of only looking at the leaves.
Following the previous idea, if you have the smallest lexicographical sequence of k elements, you also have the elements of the greatest lexicographical sequence of n - k elements. You can build it for sure by trying to add the greatest nodes first whenever it is possible, which is what the editorial does.
Such a nice contest. Can you give few words about finding nearest path from given vertex to the subtree in E?
Can anyone explain C question better than what Hasan discuss in editorial.I really didn't get this question.Plz Thank you...
You can pick contiguous range, [a1, a2, ...an] where an - a1 ≤ K, ai ≤ 255, as many as you want. Each element must belong to exactly 1 group(range). Now you are given a sequence. For each element, find a group it belongs. replace the original element with the first element of that group. After replacing all elements, the result sequence should be the lexicographically smallest among all possible results.
Anyone plz explain this example .. 3 7 39 242 238 Ans-? ? ?
I hope it helps me better if u explain with an example.Thank you.
[33,34,35,36,37,38,39] , [236,237,238,239,240,241,242] Other numbers are 'don't care'.
Ans: 33 236 236
Can you explain the second test case in the problem C? If k is 2 how come ans is: 0 1 1 255 254 and not 0 2 0 254 254
Thank you but please see this: If i put [0,1] in one group with key =0 and [2,3] in other with key =2; Then is it wrong just because it is not lexographical? as the answer would be 0 2 0 254 254 in that case....
Ok. I'm back with my laptop. Because 0 2 0 254 254 is lexicographically greater than 0 1 1 255 254.
ok thank you
can you please explain this test case: n=100 k=7
39 242 238 155 95 30 129 132 72 59 22 61 133 113 99 81 253 204 160 109 92 187 11 227 145 148 100 42 78 14 113 91 140 197 123 182 4 185 208 27 182 207 63 146 102 79 159 195 26 100 72 127 157 159 152 53 0 117 111 125 19 188 179 145 240 50 205 207 113 246 42 56 181 13 188 244 159 222 119 204 87 182 212 175 199 69 81 45 30 32 238 255 81 61 177 125 149 121 35 38
Here for 67th(205) and 68th(207) entry the answer is 205 then for the 83rd(212) entry also the answer can be 205? However the judge is showing 209 as correct answer.
since [205-208] is mapped to 205. if [205-212] is mapped to 205, it is illegal to condition since there are 8 values between 205 and 212 (205,206,207,208,209,210,211,212)
Thank you very much...
I got TLE on problem E, and here's my doubt: Binary lifting is used for LCA problem which means to find 2 nodes's ancestor, but I iterate the node from n to 1, each iteration there's only one node so where's the other and what's the motivation about this? If anyone could help, thanks so much!
It's like binary search, you need to find the first ancestor which is in our current answer, so binary lifting can be used.
You can actually avoid binary lifting altogether by keeping track of nodes that are too far away when you try to get to n from them. If you terminate your search and make updates when you hit one of these nodes while backtracking towards node n you can speed up the basic approach enough to pass. 38135125
Is 0 a perfect square in this problem? I searched on web but I found that some think it is, others it isnt. So it depends on this problem.
I have WA on test 18 in D. I think D is first test with zeroes, but I cant see whats my mistake. I didnt solve even similar to editorial, I didnt use primes at all. Can someone help me find mistake?
Nvm, I think I found mistake.
Anyone had problems with time limit on E? I literally solved it like in editorial, but I had tle on test 66. then i changed CONSTANT in for loop from 25 to 24 and it worked. wtf?
Can someone explain me the question — DIV 2 D
Can someone please explain problem D along with its examples? In the example, it says Input: 2 5 5 Output: 3 0 Why the output is 3 and 0? Thank you.
Same. Weird question.
Is this solution for the test case (7, 2) given in the problem B wrong
. . . . . . .
. # . . . # .
. . . . . . .
. . . . . . .