


I was solving a problem but I couldn't solve that problem.
Given an array of N elements, we have to answer Q queries in each query two number i and X will be given we have to find how many multiples of X will be there in the array after the ith (including i) index. The range of N, Q is 10^5 and same for the array elements.
Please help me out with the logic.
Thanks in advance.
→ Pay attention
Before contest
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
33:36:28
Register now »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
33:36:28
Register now »
*has extra registration
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2024 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Nov/22/2024 07:58:32 (l2).
Desktop version, switch to mobile version.
Supported by

Auto comment: topic has been updated by UnfilledDreams (previous revision, new revision, compare).
I'll just determine T = 105 to ease on writing, then we can say that Ai, N, Q ≤ T. What I currently have works in total time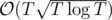 , if I'll find a better one I'll add it.
, if I'll find a better one I'll add it.
Since you're asking for "logic", I'll say how I think you should come up with this idea:
First, let's see that we can have multiple ways (though most of them are inefficient) to approach the queries, we'll focus on 2:
The point is that approach 1 is heavy on preprocessing and light on query time, while approach 2 is the opposite. We can merge them. Let's determine a constant K:
We want to pick a K for which the worst case between approach 1 and approach 2 is minimized. as K increases, approach 1 gets worse while approach 2 improves, so we would like to find a K for which approach 1 = approach 2:
Hopefully I didn't do too much :). This is pretty much sqrt-decomposition, but following only the idea and not the "sqrt" part.
Edit: one more thing to notice is that apporach 2 alone is worse than doing a simple brute force, but it's better in a sense because it can be easily improved using the constant K (which doesn't affect the brute force approach).
Here's a simpler solution that works in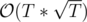 . I still think the above idea is good to know as it implies to a lot more problems.
. I still think the above idea is good to know as it implies to a lot more problems.
We'll make Ix be the vector of (sorted) indicies in the initial array, such that all the values in these indicies are multiples of x. We can preprocess all that in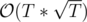 . Then for each query (x, i) we do binary search to find how many values in Ix are at least i. This is
. Then for each query (x, i) we do binary search to find how many values in Ix are at least i. This is 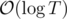 per query.
per query.
Though this is simpler and works in a better time complexity, I think the first approach I gave is good to know in general.
Thank you so much.
A simple solution here:
For each number precompute a vector of its divisors —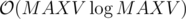 . Keep an array C[i] = number of multiples of i. Now we start from the end of the array and answer all queries such that their i is equal to the current index we are looking at. Answer will obviously be C[X]. Also before answering the queries add +1 to all divisors of a[i]. The complexity is
. Keep an array C[i] = number of multiples of i. Now we start from the end of the array and answer all queries such that their i is equal to the current index we are looking at. Answer will obviously be C[X]. Also before answering the queries add +1 to all divisors of a[i]. The complexity is 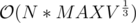 .
.
Thank you for helping me.
Scube96 Can you provide the link to the problem??
Sorry, I don't have the link of the problem this question appeared in an exam which was taken in proctored mode, so they didn't make that public.
How is total complexity calculated?
This should help you:
Number X has approximately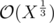 divisors.
divisors.
On this topic, why do a lot of people use that statement? The exponent isn't really a constant one, it depends on X and decreases as X increases. Like, I can also state that the average number of divisors for a natural number up to X is
isn't really a constant one, it depends on X and decreases as X increases. Like, I can also state that the average number of divisors for a natural number up to X is 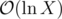 (and, I think that as X becomes much larger, the worstcase number of divisors for a value up to X might also be
(and, I think that as X becomes much larger, the worstcase number of divisors for a value up to X might also be 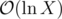 ).
).
As an example, here are a couple highly composite numbers:
Edit: maybe this term is used a lot because the values we work here with are up to 1018...? So just for smaller values it's around square root and for larger it's around cube root.