


Hello, Codeforces!
I think many of you know about Mo's algorithm. For those, who don't know, please read this blog.
Here, I consider an alternative (and faster) approach of sorting queries in Mo's algorithm.
Table of contents
Canonical version of the algorithm
The canonical version of this algorithm has 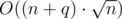 time complexity if insertions and deletions work in O(1).
time complexity if insertions and deletions work in O(1).
Usually, the two comparators for query sorting are used. The slowest one:
struct Query {
int l, r, idx;
inline pair<int, int> toPair() const {
return make_pair(l / block, r);
}
};
inline bool operator<(const Query &a, const Query &b) {
return a.toPair() < b.toPair();
}
We know it can be optimized a little if for even blocks we use the reverse order for the right boundary:
struct Query {
int l, r, idx;
inline pair<int, int> toPair() const {
return make_pair(l / block, ((l / block) & 1) ? -r : +r);
}
};
inline bool operator<(const Query &a, const Query &b) {
return a.toPair() < b.toPair();
}
Achieving a better time complexity
We can achieve 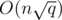 complexity for Mo's algorithm (still assuming that insertions and deletions are O(1)). Note that
complexity for Mo's algorithm (still assuming that insertions and deletions are O(1)). Note that 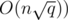 is always better than
is always better than 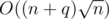 . We can prove it as follows:
. We can prove it as follows:
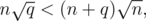
n2q < n(n + q)2,
nq < n2 + 2nq + q2,
n2 + nq + q2 > 0
But how this complexity can be achieved?
Relation to TSP
At first, notice that changing the segment (l1;r1) to (l2;r2) will take |l1 - l2| + |r1 - r2| insertions and deletions.
Denote the queries as (l1;r1), (l2;r2), ..., (lq;rq). We need to permute them to minimize the number of operations, i. e. to find a permutation p1, p2, ... pq such that total number of operations
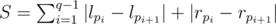
is minimal possible.
Now we can see the relationship between Mo's algorithm and TSP on Manhattan metrics. Boundaries of queries can be represented as points on 2D plane. And we need to find an optimal route to visit all these points (process all the queries).
But TSP is NP-complete, so it cannot help us to find the optimal query sorting order. Instead, we should use a fast heuristic approach. A good approach would be the use of recursive curves. Wikipedia says about using Sierpiński curve as a basis to find a good TSP solution.
But Sierpiński curve is not very convenient in implementation for integer point coordinates, so we will use another recursive curve: Hilbert curve.
Hilbert curve
Let's build a Hilbert curve on a 2k × 2k matrix and visit all the cells on the matrix according to this curve. Denote ord(i, j, k) as the number of cells visited before the cell (i, j) in order of Hilbert curve on the 2k × 2k matrix. The following picture shows ord(i, j) for each cell on the 8 × 8 matrix:
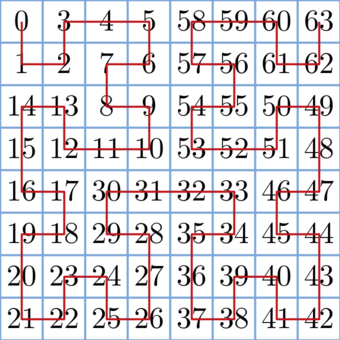
Now we can write a function to determine ord(i, j, k). It will do the following:
- Divide the matrix onto four parts (as Hilbert curve is built recursively, each part is a rotated Hilbert curve).
- Determine, in which of the four parts the cell (i, j) is located.
- Add all the cells in the previous parts. There are 4n - 1·k or them, where k is the number of parts visited before the current one.
- Recursively go into the selected part (do not forget that it can be rotated).
The code looks in the following way:
inline int64_t hilbertOrder(int x, int y, int pow, int rotate) {
if (pow == 0) {
return 0;
}
int hpow = 1 << (pow-1);
int seg = (x < hpow) ? (
(y < hpow) ? 0 : 3
) : (
(y < hpow) ? 1 : 2
);
seg = (seg + rotate) & 3;
const int rotateDelta[4] = {3, 0, 0, 1};
int nx = x & (x ^ hpow), ny = y & (y ^ hpow);
int nrot = (rotate + rotateDelta[seg]) & 3;
int64_t subSquareSize = int64_t(1) << (2*pow - 2);
int64_t ans = seg * subSquareSize;
int64_t add = hilbertOrder(nx, ny, pow-1, nrot);
ans += (seg == 1 || seg == 2) ? add : (subSquareSize - add - 1);
return ans;
}
Assume the matrix has size 2k × 2k, where 2k ≥ n (you can take k = 20 for most cases or find minimal such k that 2k ≥ n). Now denote oi as ord(li, ri, k) on this matrix. Then sort the queries according to their oi.
Here is the proof why this works in time. Suppose we have n = 2k and q = 4l, where k and l are some integers. (If n and q are not powers of 2 and 4 respectively, we increase them, it don't have any effect on asymptotic). Now divide the matrix onto squares with size 2k - l × 2k - l. To travel between a pair of adjacent squares, we need O(2k - l) time, so we can travel between all the squares in 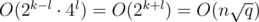 time. Now consider the groups of queries inside a 2k - l × 2k - l square. Here we can travel from one query to another in O(2k - l), so we process all such groups of queries in
time. Now consider the groups of queries inside a 2k - l × 2k - l square. Here we can travel from one query to another in O(2k - l), so we process all such groups of queries in 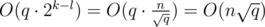 . So the total time to process all the queries in , which was to be proved.
. So the total time to process all the queries in , which was to be proved.
Benchmarks
Let's compare the canonical version of Mo's algorithm and the version with Hilbert order. To do this, we will use the problem 617E - XOR and Favorite Number with different constraints for n and q. The implementations are here:
To reduce the amount of input and output, the generators are built into the code and the output is hashed.
For benchmarks I used Polygon. The results are here:
| n | q |  | Standard Mo time | Mo+Hilbert time | Time ratio |
|---|---|---|---|---|---|
| 400000 | 400000 | 1 | 2730 ms | 2698 ms | 1.012 |
| 1000000 | 1000000 | 1 | 13602 ms | 10841 ms | 1.255 |
| 500000 | 250000 | 2 | 3369 ms | 2730 ms | 1.234 |
| 1000000 | 500000 | 2 | 10077 ms | 7644 ms | 1.318 |
| 600000 | 200000 | 3 | 4134 ms | 2901 ms | 1.425 |
| 1000000 | 333333 | 3 | 8767 ms | 6240 ms | 1.405 |
| 600000 | 150000 | 4 | 4851 ms | 2496 ms | 1.944 |
| 1000000 | 250000 | 4 | 8672 ms | 5553 ms | 1.561 |
| 700000 | 140000 | 5 | 6255 ms | 2854 ms | 2.192 |
| 1000000 | 200000 | 5 | 8423 ms | 5100 ms | 1.652 |
| 750000 | 100000 | 7.5 | 5116 ms | 2667 ms | 1.918 |
| 1000000 | 333333 | 7.5 | 7924 ms | 4009 ms | 1.976 |
| 1000000 | 100000 | 10 | 7425 ms | 3977 ms | 1.866 |
| 1000000 | 40000 | 25 | 9671 ms | 2355 ms | 4.107 |
| 1000000 | 20000 | 50 | 9016 ms | 1590 ms | 5.670 |
| 1000000 | 10000 | 100 | 6879 ms | 1185 ms | 5.805 |
| 1000000 | 5000 | 200 | 5802 ms | 857 ms | 6.770 |
| 1000000 | 2500 | 400 | 4897 ms | 639 ms | 7.664 |
What is interesting, when I ran these codes locally even on the test with n = q (e. g. n = q = 400000), Hilbert version worked about three times faster.
Applicability
As you can see, such sorting order doesn't make Mo's algorithm work slower, and when q is significantly less than n, it works much faster than the classical version. So it is ideal for problems with n = 106 and q = 104. For smaller q solutions with naive query processing can pass.
Thanks to everyone who read this article! I hope it will be useful for someone.
If something is unclear in the post or the post contains bugs, feel free to write in comments.







Without a doubt that technic is musthave if you wanna squeeze your MO into TL)
Do you have any idea about the worst case for your solution?
I actually wrote a post asking about this problem a while ago: http://mirror.codeforces.com/blog/entry/57681. In the comments, a way to make this algorithm run just as fast as Mo's algorithm for O(n) queries is described, by setting l, r for all queries to multiples of .
.
In the phrase "find minimum such k that 2k ≤ n" do you mean maximum such k? Or even 2k ≥ n?
I meant "find minimum such k that 2k ≥ n". This is fixed now, thanks for reporting.
Auto comment: topic has been updated by gepardo (previous revision, new revision, compare).
The canonical version of Mo's also works in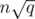 provided you choose the right block size.
provided you choose the right block size.
Why? Let's fix some (yet unknown) block size M and recall what we do inside each block after standard sort (first by block, then by right border). Assume that qi is the number of queries inside i-th block. So:
Here we have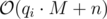 operations per block. In general that will be
operations per block. In general that will be 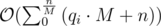 , which turns into
, which turns into 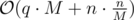 as soon as we remember that the
as soon as we remember that the 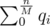 is simply q.
is simply q.
The final step is to average these two addends; this happens when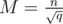 .
.
Voila!
Interesting idea :)
Just tried it and compared with the other versions. The results of the benchmark are here:
(the test order is the same as in the benchmark in the post)
Code
Must definitely try Hilbert curves next time since the outperformance is quite significant in most cases! Thank you for sharing this :)
This is not True. If the queries are of type — (a1 + 1, b1 + 1), (a1 + 2, b1 + 2), ..., (a1 + q, b1 + q), its easy to see the optimal time complexity would be O(q) (i.e. obviously assuming insertions and deletions are O(1)).
You are assuming that all the queries would be of type (aS, bS) and a, b will be integers. But that doesn't represent all the possible pairs of points unless q = n*2.
Note: The reason I am necroposting here is to point a mistake in the above comment.
Wow this is cool. I put the
gilbertOrdercode in existing AC solution and it halfed my runtime.If you are intrigued by the Hilbert Curve, I recommend that you watch this video by 3Blue1Brown.
Hilbert curve is also used by Google S2 for spatial indexing that is used by Google Maps.
Wonder how other space-filling curves, such as Peano curve or Moore curve, would fare?
Also these curves fill square spaces, but queries have L < R so the area in concern is actually triangular. Would a triangle-filling curve work better?
"Suppose n = 2k and q = 4l. Now divide the matrix onto squares with size 2l × 2l."
The sizes here are not 2l × 2l, they're actually 2k - l × 2k - l (i.e.,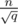 ), for the proof to work. Not surprisingly, the same proof applies for the regular Mo's sorting criterion, therefore its complexity (see above comment).
), for the proof to work. Not surprisingly, the same proof applies for the regular Mo's sorting criterion, therefore its complexity (see above comment).
This however seems like a more general approach, that doesn't have some "magic" constants, and might even work fast enough for 3-dimensional queries as well (as long as we can design a space-filling curve for 3D). (original Mo's complexity here is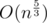 , if n = q)
, if n = q)
A good thing to experiment with is trying different space-filling curves for different sets of range queries, and comparing the TSP candidates. This can be done without actually adding the extra overhead of implementing an algorithm that solves some problem after the sorting; the total number of expected operations is all we need.
Thanks,
I'll fix it soonfixed.3D Hilbert curves? (By the way, Hilbert curves are good enough to be generalized to more dimensions)
For 3D case, if we use a 3D Hilbert curve, the time complexity will be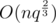 .
.
Generalizing this to more dimensions, we get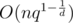 , where d is the number of dimensions.
, where d is the number of dimensions.
My simpler and slightly faster implementation based on the code from Wikipedia:
Your code is wrong, just look at order of cells in $$$4 \times 4$$$ matrix. Here is the working one:
Wtf, why there are so many dislikes and 0 reasons behind it? I just tested both codes, and it's true — jef's code is wrong and 2147483648's correct. Why this community is so toxic?
The coordinates of cells are 1-based or 0-based?
So cool idea. Thanks for the Great work!
can anyone help me understanding the time complexity if MO's algo?? new to this,thanks in advance.
Perhaps you should read the article first.
U mean this article?? I mean to say with normal sorting technique,cant understand the complexity of it per query.
No I think in this article, he mentions a more basic tutorial for people that haven't learnt Mo's Algorithm yet.
I have just tried to put the hilbert order code in my accepted solution but it gets TLE:120575777. Can anybody tell me why?
You obviously copied and pasted the code without understanding C++ syntax and the logic that was explained in this blog.
You made 2 mistakes:
The above means that you did not actually use hilbert ordering and your solution is same as brute force. Of course you would get TLE.
I have corrected your mistakes and got AC. See 127408237.
Hi! Sorry for necroposting jeje
I'm learning Mo's algorithm and the TSP optimization (in this case, Hilbert curve optimization). Therefore, i read But Sierpiński curve is not very convenient in implementation for integer point coordinates but why? Because it uses doubles? For the presicion error?
Pd.: thanks for the useful blog. It's amazing
I guess it's not that Sierpiński curve is unsuitable for integer coordinates. It's more that Hilbert curve suits so well in case of grid coordinates.
I can sense some potential issues with Sierpiński curve (I'm not experienced, so take them with giant grain of salt):
difficulty with selecting fractalization level in general case
it might also lose some efficiency as movements on Sierpiński curve don't follow [+1] [-1] actions we can make
(shouldn't be a problem) a bit slower computation of nodes order
But it should still work perfectly fine. Wikipedia has an implementation of inverse for right isosceles triangle that can be extended to our square case. Someone might try it and post their findings in a CodeForces post : )
hey, i tried to solve this (https://mirror.codeforces.com/contest/703/problem/D) problem using MO's algo and MO's+Hilbert. here are the results:
MO's:(https://mirror.codeforces.com/contest/703/submission/240280389) -> 2651ms
MO's+Hilbert: (https://mirror.codeforces.com/contest/703/submission/240280310) -> 2989ms
did i do anything wrong in MO's+hilbert? plz, help.
Found this post very interesting, and did some research.
Below is the implementation of the Sierpinski index based on
Tried a few test cases myself, didn't see big difference with the Hilbert index.