


Hello, codeforces!
All signs in the sky and on the ground indicate that you've enjoyed my first blog, so here is the second one. I've decided to choose a Polish task again, as there are plenty of interesting ones. This time we'll take a look at the "plot purchase" (you can submit here), which is a bit easier, but a few years ago I was very proud of myself when I solved it. The statement goes as follows:
You are given a square n × n grid (1 ≤ n ≤ 2000). In every cell, there is a number from the range [1, 2·109]. You are also given an integer k (1 ≤ k ≤ 109). A task is to find a subrectangle of this grid such that the sum of values in this subrectangle lies in the range [k, 2·k] (or report that there is no such subrectangle). Just print coordinates of its opposite corners.
If the problem would be more difficult, and we'd be asked to find a subrectangle with some given sum of values, then it'd be possible to find it in O(n3) time, just by fixing lower and upper sides and then using two pointers to find for every possible right side the proper left side (if existing). O(n3) is too much, so we have to use the fact that we don't have to achieve the exact sum, which looks really interesting, because many known problems become easier/possible to solve when we change the exact requirement to the range one (knapsack comes to my mind).
Let's firstly look at the sum of all numbers in the grid. If it's smaller than k, then we are sure that there is no proper rectangle (because all numbers in the input are positive). If it already lies in the desired range, then we can end and print the answer. If it's bigger than 2·k, then we need to try a smaller one. Here comes idea which most of the people would go through while solving this problem: let's divide this rectangle into two smaller ones. No matter how, possibly somewhere in the middle, because it looks the most natural (but probably it's a bit easier to implement cutting off rows/columns one by one). Also, the dimension which we'd decrease doesn't matter. After this cut, the sum of numbers in the rectangle with greater sum won't be less than the sum of all numbers divided by 2. So, if the sum was greater than 2·k, then it won't be smaller than k.
Sooo, is it the end? Can we just cut the rectangle as long as it has the sum greater than 2·k and then print what's left? Unfortunately, the answer is no. Let's consider a test case with only one 1 in the corner and 1000 in the rest of the grid. If k is equal to 1, then the only correct answer is to print only this corner. In our algorithm, we could lose it quickly if we'd stay in the wrong half (which is more likely as it has greater sum).
So we need some improvements. Firstly: all cells with values strictly greater than 2·k are definitely forbidden, so we can mark them as infinity. Among all rectangles with no forbidden cells we need to find one with the sum of elements not smaller than k — if we'd have it, then we'll run our algorithm on it. Here we'll again use the fact about only positive numbers: if some rectangle is a subrectangle of some bigger rectangle and the smaller one has sum not smaller than k — then, the bigger one also has such sum. This fact implies that it's enough to look only at rectangles maximal by inclusion, which turns out to be a well know task, but I'll describe it anyway.
We'll need some preprocessing. Firstly, prefix sums for each subrectangle with one corner in cell (1, 1). Secondly, for each cell, we know how far can we go down until we meet either a forbidden cell or an edge of the whole grid.
Let's fix an upper side of the rectangle that we want to find and build an array which indicates how far can we go to the down in each of the columns. Then, if we have some interval of columns corresponding to a rectangle, then it's optimal to go as far to the down as the minimum of values in the array (in this interval). It makes sense, cause it means exatly that when we know left, right and upper side, there is only one reasonable bottom side. Let's iterate over possible right ends of an interval and keep track of places on the left where interval's minimum changes. Why only these places? It's clear that if some interval [i, j] has this same minimum as interval [i - 1, j], then it makes no point to consider [i, j], so we are only interested in intervals whose minimums change after extending that interval to the left (we assume that before and after the array there are values equal to - ∞). So we can keep these places using a stack. When new value comes, we pop out of the stack values greater than the new one and we consider intervals which start at them and end right before the column in which currently we are. It turns out that the number of considered intervals amortizes to O(n) with a fixed upper side of a rectangle (because we consider something only when we remove it from the stack), so in total there are O(n2) considered rectangles. Complexity is the same, cause when we find any rectangle with the sum not less than k, then we can run our partition-algorithm with the knowledge that for sure it'll find the desired rectangle.
What do you think about this task? Was it interesting or maybe too easy? Let me know what you think about it. See you next time! :D







Can you post the links to the problems here and in future blogs? It would help a lot.
As you wish :)
This one is kup.
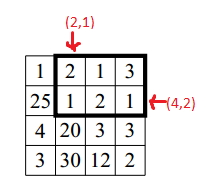
Why in the second tc:
The answer is 2 1 4 2..would the sum will be: (25 + 1 +4 + 20 + 3 + 30) > 16..?
format is (column, row):
Thank you :D
Me looking at top contributors:
The fun fact is that both described problems have way better editorials in Polish (for example without any issues that Swistakk mentioned in a previous entry).
So you just need to translate some article from Polish and gain easy contribution.
haters gonna hate
translating an article in other language which more people can understand is a kind of contribution in community, isn't it??
Come on, I wrote it by myself ;_;
you got what you deserve, about 2000 people think that your posts are helpful, and about 2 people think its not, 1000/1... also i didn't said that you did not wrote it by yourself, i just said even if you didn't, its ok for you to gain +contribution, the other fact is, you are LGM so you are kind of master of this topics, so you don't need to copy from somewhere else
You are right, but I'd rather see some new, original texts.
As you wish, THE GREATEST POLISH TASK EVER has to wait cause it's already described in some magazine where nobody has seen it :/
I highly doubt that Furniture is the greatest Polish task ever. (If anyone is interested, we are doing this only because we want even bigger hype around Blogewoosh #3.)
Somebody tries to be nice for others, write some useful blogs, help people to learn something, but no, every time somebody has to come and write "asmdiksandujnasd, hype hype, asndjasndasj, I'm from Wrocław, saddasddsadas" ;_;
Kostka is from Lubin not Wrocław. So please don't insult Wrocław.
Maybe. But people who take their time to translate things like this are contributors regardless; and he wrote the solution himself, in an understandable way for us. I, for one, would write blogs like this to share, not to "gain easy contribution". And you can always ignore tasks you have already solve :D
Don't be such a drag. If you are willing to, then you can translate all few thousands pages of bluebooks to English (to get EASY CONTRIBUTION). I think people here will be happy.
I've heard that Errichto have such plans (also: this is not a joke).
What's blue book?
Book published every year with solutions to all problems from last POI.
Interesting. Are they available in some page as pdf?
https://oi.edu.pl/l/40/ (there are also tests and model solutions for some of the POIs)
THANKS FOR THE FREE RESOURCE OF EASY CONTRIBUTION™
How about do exactly that (translate Polish pro tricks or whatever) instead of demotivating someone trying to do something for the community. No one gives a fuck whether it's original they just want to learn something new and cool.
I hate you blog. Please go away. //BTS one love
1st in contribution.
congrats...
One request or suggestion:
You may add example(s) in your blogs to explain how the algorithm is working. Example makes things more clear.
In case anyone is interested in test data (I/O files) and solution(code) of this problem, here it is...
Are you going to make a post about problem "Daybeds"? When it comes to polish tasks, this is definitely one of the best.
Thanks for sharing your experience in solving this interesting problem. The following is a simple solution for the problem based on cumulative partial sums as well. The initial results of this solution were accepted at SZKOput, and the execution time of solving thousands of randomly generated test cases did not exceed a few hundreds milliseconds per each test case.
"The initial results of this solution were accepted at SZKOput, and the execution time of solving thousands of randomly generated test cases did not exceed a few hundreds milliseconds per each test case." — nice description for "I wrote a brut with breaks" xD
Thanks for the considerate critique. Actually, the self-test long-time run of 100,000 random test cases has just ended a few minutes ago, and the maximum Execution Time reached about 9 seconds for some random test case.
Yes, that's right. The simple solution is augmenting brute-force search for sub-rectangles starting at cell(x1,y1) with skip when ai, j > 2k and with break point when the cumulative partial sum of a sub-rectangle exceeds 2k.
In both cases, it is guaranteed that no sub-rectangle whose upper-left corner is located at such cell exists with sum that does not exceed 2k. It appears though that this simple augmentation is not sufficient to pass a 5 seconds time-limit for some test cases.
Great! How about a case where n = 2000, k = 108, a[i][j] = 1 for all i,j except a[n][n] = 2k + 1.
Thanks for sharing such case.
It should be clear that no claim was made in the previous posts about the time-complexity for large n and k.
UPDATE: Further checking is necessary for validating the bounding rule so as to avoid incorrect solutions.
Alright. Now change a[n][n] = 2k - 1.
Please read the last statement in the previous post. And again, no claim was made about the time-complexity for large n and k. Thank you.
"Thanks for the considerate critique" nigga u Shakespeare or somethin?
Those who studied history should know that William Shakespeare, the great talented poet, passed away more than 400 years ago. On the other hand, striving to improve your English language vocabulary may not only be much better for your communication skills and professional career than trying to humiliate and insult any of your fellows with racist and vulgar offensive comments, but also compliant with The ACM Code of Ethics and Professional Conduct.
Respecting and appreciating others' right and efforts to experiment with computer programming problems and share results which may sometimes include wrong answers and/or do not satisfy the required Execution Time and Memory limits, and refraining from picking some phrase out of context to promote injustice and hatred should help you to be much more humble and merciful human being in an unfair life.
"To be, or not to be, the choice is yours", a joint quote from William Shakespeare's legendary tragic novel "Hamlet", and Whitney Houston's legendary lyrics, "Miracle". You may check the announcement of "Codeforces Round #502 (in memory of Leopoldo Taravilse, Div. 1 + Div. 2)" if you are not sure that those who are not afraid to help their fellows and cooperate with them decently and respectfully in "Dolphin Song" spirit like Leopoldo Taravilse are often remembered gratefully even after they had passed away.
"cause when we find any rectangle with the sum not less than k, then we can run our partition-algorithm with the knowledge that for sure it'll find the desired rectangle." How do we know that?
For each found rectangle we know it contains no forbidden cells. We can easily prove that for any such rectangle, if its sum is not smaller than k, there is a subrectangle in it, which has desired sum. If the rectangle consists of just one cell, it's not forbidden so we have the answer. Else, if its sum is not greater than 2 * k, we also have the answer. Otherwise we can somehow divide the rectangle into two parts, we choose the part with bigger sum (so at least k) and repeat the same reasoning for chosen rectangle by induction.
I like the blog but I also understand kostka's opinion.
IMO, Radewoosh can beat MikeMirzayanov in contribution and that's fine if he indeed produces good-quality blogs and they are useful for the community. I'm also sure that Mike will be happy about it. That being said, it's terrible that there are so many resources nowadays. There are hundreds of tutorials about common topics, and there are thousands of problems with an editorial. This series of blogs makes sense because there aren't many organized places with hard not-well-known tricks (while most of the "hundreds" and "thousands" are about easier topics) and people don't know Polish. A bad thing is that people from Poland won't find them that useful of course.
But kostka touched on some particular issue: an editorial in Polish was better. The "haters gonna hate" isn't a perfect response for that. Instead, Radewoosh should read a corresponding thing in Polish first and try to produce something of same or better quality (btw. it's fine and even better IMO to make it short). I'm sure a readable code with comments would be of much use. If possible, the drawings might also help (I don't know if they are needed in the first two blogs). He apparently has a huge reach, so maybe in the next few years his blogs will be a recommended thing for yellow/red competitive programmers — but only if he really focuses on the quality, maybe producing fewer blogs because of that. That being said, the current format/version/quality is fine.
Radewoosh isn't driven only by the contribution and he really wants to show others some cool new (new for them) tricks, but EVEN IF he just wanted relatively easy contribution, that would be fine by me. Whatever helps people.
I didn't know these tasks before, so I found both blogs quite useful. Not everyone from Poland follows POI problems, not to mention ONTAK problems.
I also can't agree that the Polish editorial was better. It was different. It was more organized and contained all required proofs, so yeah, it was in some sense better. But the blogs take these tasks from another point of view — how to arrive at the solution. So editorial was better for those who want to know the solution, while blog was better for those who want to learn how to approach problems.
Since we have plenty of editorials in the form of presenting a solution, and not too many descriptions of thought processes, I find Radewoosh's blogs very useful and don't consider them worse resource than the blue book.
Can someone elaborate on the last part of the blog, about finding the maximal rectangle in O(N^2)? I didn't understand the algorithm... Puting that aside, thanks for the post and the problem Radewoosh :)!
Need some pictorial description or Pseudo code... unable to pick the end..
Great blog Radewoosh! If you could add more tags to your blog than just
blogewooshlike which topic this blog is about then it would be great!