



Hi!
August 17, Aug/17/2018 17:35 (Moscow time), there will be a rated Codeforces round #504. Some of the problems will be from VK Cup 2018 finals, and awoo and vovuh have prepared other tasks for the full round.
The problems of this round are proposed, prepared and tested by: MikeMirzayanov, awoo, vovuh, Errichto, Lewin, Endagorion, Um_nik, YakutovDmitriy, budalnik, izban, Belonogov, scanhex, 300iq, qoo2p5, Livace.
There will be prizes from VK social network in this round as well! The participants who took the first 30 places of this round and the round #505, also partially based on the tasks of VK Cup 2018 Finals, will get GP30 points.
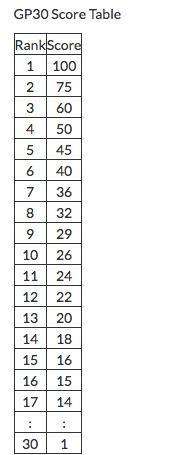
Participants are sorted by sum of points for both rounds (if the participant did not participate in one of the rounds, the points scored for it are assumed to be equal to zero), with the maximum time for both rounds from the beginning of the round to the last submission that passed the pretests as tie-break.
The top 10 participants will receive a plush Persik!

There is no country nor language restriction, everyone can win a prize. One don't have to have participated in VK Cup to receive the prize. Exact selection algorithm will be announced before the start of the round.
Good luck!






What if the said submission doesn't pass the system test? If it would be counted, it may cost you the price compared to the case where you don't make that submission.
http://mirror.codeforces.com/blog/entry/61285 Pls see this...getting some issue in contest 504 Question D
From what I see and understand, even contest 505 will be combiner round right?
Yes
Finally, 3 consecutive rated rounds!!!
Gateway Timeout Round
So basically combined contest with prizes. Nice
How many tasks will there be?
Participate in the CF round with my GIRLFRIEND-Coding( It is impossible for me to have a girlfriend.....:( )!
will it be 20% div2 + 80% div1??thriller one ....
You have to compete in all rounds. Not one, because you are a skillful contestant and you eat a garron of the big flute. You are in a state of temporal madness. You compete in all rounds, you solve all the problems, you hack all contestants in rooms, do I explain myself? You are inhackable brother. In 10 contests you are red.
https://www.youtube.com/watch?v=0vtLXNFdxJY
Best video ever!
Hope CF wont fall again in the middle of the contest)
Hope so!
Hope the pretest will be stronger. I got a failed system test last time.
+1
I pray for the codeforces hardware.
But Is It Contributed?
Are You Contributed?
Shall we need to use different languages to solve different problems?
You can if you want. :)
Are the questions in English or Russian? Thanks for the reply.
There will be both languages
perfect weekend, three consecutive rounds.
Wish it won't be a Gateway Timeout Round. Good Luck & High Rating!
How many tasks will be?
I have a strange felling I will do great today :D
We hope so ! Good Luck !
Scoring?
Let's start, good luck to everone and high rating. :D
Hackforces again.... Please, the huge difficulty increases are resulting in hackforces, try and prevent that, too easy A B C D then a E-bomb
How to solve D?
The key observation was that you cannot have an interval of large numbers split by an interval of smaller numbers, i.e, something of the form "...8778..." is not possible. You can use a segment tree to check whether this is violated and then also check whether the largest value is present (as no other value can mask it) and take care of the zeroes (by extending the values from either side).
Oh damn! I did a similar thing. Perhaps my implementation has a mistake :(
Thanks for the response
Exactly, but it is not necessary the segment tree:)
sure! there is no need to use segment tree. it can be solved with a simple brute force
I'm trying with your approach. But I'm getting TLE on TC 9. Can you please help me out?? MySol
What exactly are you doing? The complexity should be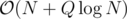
The complexity should be O(N + Q)
With a segment tree the complexity is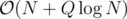 if I'm not mistaken.
if I'm not mistaken.
Don't use a segment tree then
Haha...Well it fits within the Time Limit so we can use it... And if you'll notice, the OP asked what the issue was with his code...and he is using a segment tree...
Segment tree is more complicated to code than O(N + Q)
Maybe so...but that's not the issue here... I was simply conveying the complexity of the OP's code.
Maybe we don't need segment trees. All we need is a monotonous stack.
You can refer to my code for more details.
Exactly a stack! I don't code it but I thought in it.
You can also see the solution of elnomada1996 :)
Numbers of ACs to E is basically one third of ACs to D. I wouldn't call that big jump in difficulty.
I don't think E was very hard for a div1C difficulty problem.
It even had 2 times higher query limit than it needed.
Interesting...i did get AC but my approach uses almost all the queries in worst case(no wonder am just blue)...How do you do that in half the query limit?
Edit : Now when i think about it, i realized that yeah...half of my queries are actually utter useless! lol...
Hacking process or the compilers have the big problem with RE. I wrote two tests on which the programs had had to get RE, but they'd got OK. That's really strange... :(
Compilers used in local machines and Codeforces servers might not be the same. So, next time, perhaps you should consider testing something through "Custom invocation" first.
In C++ programming mistakes won't necessarily behave like you expect them to. Entering undefined behavior means anything can happen, the program may crash, print an incorrect answer or even appear to "work".
i tried this hack attempt to a solution that gives "no" while it should be "yes" to problem A
2 3
a*
asd
why it failed ?
Which one failed? The hack, or the generator/validator/checker?
If it was the hack, show the submission you intended to hack, so we can have a brief overview.
my hack failed
I can't open the submission now but the username is ATS
You should see more about the
substrfunction here.As it said, exception is thrown only when pos is greater than the string' size, so it'd be not the case.
Furthermore, the "inner" condition (
S.substr(p + 1, N - 1 - p) == T.substr(M - (N - 1 - p), N - 1 - p)) was correct: two strings being compared were both empty strings (you can check the code yourself, or maybe run it through Custom invocation).P/s: ATS' solution for reference: Solution 41688303
Please say F can be done with HLD with range updates and point query...
If so, any cute way to get rid of HLD?
Also E needs just 2*n-2 queries right??
My solution for E also only need 2n - 2 query. The 4n query limit is probably to distract the contestant.
How to do it?
I saw 4*n and started thinking that I have to break the square into 4 squares and then do something?
If the problem has no condition that two cells in query must have mahhatan distance at least n - 1, from cell (x, y) one can try to go down and ask if there is a path from there to (n, n) (make a query with (x + 1, y) and (n, n)). If yes, go to cell (x + 1, y), otherwise go to cell (x, y + 1).
With the distance condition, split the process into two part: find a way to go from (1, 1) to some cell (x1, y1) in the sub-diagonal of the matrix, and find a way to go from that cell to (n, n). To do the later one, find a path from (n, n) to some cell (x2, y2) by asking the query with cell (1, 1), and then reverse the path.
If one prioritize going down in the first part, and prioritize going left in the second part, it can be proved that (x1, y1) will coincide with (x2, y2), thus the answer is found.
can you give a proof or an intuition as to why they would coincide
I think the best intuition for this one is: if you go from (1, 1) to (n, n) prioritize going down, and go from (n, n) to (1, 1) prioritize going left, these two path are the same. Otherwise, if the second path take some route below the first one, since the first one prioritize going down, it would have taken that route as well.
Think of it as lexicographicaly smallest path, where 'D' comes before 'R'. Trying to greedily put as many 'D'-s as possible at the begining is the same as trying to put as many 'R'-s at the end as possible(or 'L' if you reverse the direction).
With 4n you can be less efficient when finding the next cell to go to though (like trying both right and down although trying only one of them is enough). But yeah, this is probably to make the solution more obscure. xD
Yeah, my solution works in 2*n — 2 queries too
Technically, each query gives you a single instruction. So you don't need to make the last query -- 2n - 3 suffices.
I used simple set for F and I would probably get TLE. I used 2*n-2 queries for E too.
Actually set passes, but it's pretty tight (~2.7s / 3s): 41729054 41726211
This is probably the same way you did it, but here's a quick explanation anyways: you store in a set pairs {cost of edge, index of edge} for all edges, such that exactly one of its endpoints is in the subtree you're currently handling. Then the maximum value you can put for the edge going up from the subtree is the minimum value for any such edge. To maintain this, keep the aforementioned set, and merge them using the standard smaller-into-larger strategy, except that if you would insert a pair that already exists, delete it instead (both of that edge's endpoints are in the current subtree).
kllp told me this strategy after the contest. (fun story: During the contest he got memory limit exceeded because his arrays were of size 5e6, not 5e5. When he fixed that he got AC :Dd)
can you please explain the logic behind this part only "such that exactly one of its endpoints is in the subtree you're currently handling"?
In F, one can use path compression. 41719592
i didn't use hld but you can i guess, i changed updates to — minimize edges between a node x and an ancestor y of x with value val. I kept priority queue for each node, then added smaller queue to bigger one in dfs when traversing the tree. So i found the value of each edge offline.
I think I have a cute way to get rid of HLD!
We have some data of the type "All the edges in the path from u to v have to be at most x", and we want to find the upper bound for each edge. We can assume u is always an ancestor of v.
Build array bound[MAXN][LOG(MAXN)], which means the edges in the path from v and it's 2b-th parent must be at least bound[v][b]. And also we define par[v][b] as 2b-th parent of v. Then we can easily decompose paths to blocks that exist in bound array. And after all, we do the following:
and bound[v][0] is the upper bound for the edge between v and it's parent.
A way to get rid of HLD is to use union-find set.
Consider this process: for each i, mark all edges in the path between fai and fbi with value fwi on MST, if an edge has been marked, then skip. Because each edge will be marked at most once, we can optimize the complexity of finding next edge which hasn't been marked.
Use a union-find set to maintain all nodes, at the beginning all sets contain only one node. If we mark an edge (pi, i) (pi is the father of i on MST), merge i's set into pi's set. If we do this, at any time the representative element of i's set is a node j, while edge (pj, j) is the first edge from i to the root which hasn't been marked.
While marking all edges in the path between fai and fbi, let u = fai, v = fbi. Each step, let u, v be the representative element of its set, select the deeper node, find the first edge e using union-find set, and marked e with value fwi, until u = v.
Does anyone have any idea about how the grid was for pretest 6 in problem E?
I'm not sure because I didn't fail on that test but might it just be an empty grid? (of any size, probably >2) There's an edge case where if you don't change your preferred move on the second half then the paths might not line up.
Ohhh, it is not hackforces, it is F***forces
Yeah, Yeah, Yeah downvotes are proof for F***forces
How to solve E?
Problem D :
For input : 3 5 0 0 0
Output : YES 1 1 1
why is this wrong ?
The last query was with i = q, so q has to appear at least in one position.
There has to be at least one 5. 5 cannot be overwritten
because last query will affect atleast 1 value. there would be atleast one 5 in the final answer.
every query has to be applied on atleast one element of the array. So if the output is 1 1 1 that means you didnt apply 2 3 4 5 queries
because q = 5 should be in the final array
Should we (somehow, probably with some dp) calculate cut instead of flow (in G)?
Write Blogewoosh #3 about it
Or maybe Dilworth things?
What is Dilworth?
I replace your dinic algorithm with HLPP. It's more than 100 times faster now.
And it can finish in about 8 seconds on my own laptop. You dinic code is still running now. However, it can't finish in 10 seconds on the custom test.
Maybe we can squeeze it into the time limit by a faster flow algorithm/implementation or reducing the number of edges.
Sorry, what is HLPP? A quick google search turned up nothing.
Highest label preflow push algorithm / Highest label push relabel algorithm.
Whew. Boys and girls, my second CF round done on mobile internet. I mean dial-up connection through Ubuntu Network Manager, with help in detecting the phone as a modem from
ppputilities; transfer speed a few kilobytes per second. From a train to boot. I didn't know the meaning of stress and overload with tasks to check until now — the connection can randomly drop, the only moderately fast way of competing is throughlynxso I have to switch between terminals, all my browser tabs are terminal tabs, if lynx hangs then I have to log in again, I have to send files from the same directory where I open lynx.... I'm surprised I was able to write this comment at all, JS doesn't load very fast (if at all) and images are even worse.The round on Sunday will be the same, except not from a train, but with far worse connection. I'm masochistically looking forward to it.
From now, I will read first all tasks and see is something Interactive — IF (interactive) skipRound();
This sounds ridiculous. What this problem has done to you so that it activated so much hatred in you? It was cute and simple.
No, I do not hate this concrete task. Round was quite nice.
I do not like Interactive tasks in global — I think they are much more guessing and lucky than all other types of problems.
It is my opinion and I believe I won't change it soon.
"I do not like Interactive tasks in global — I think they are much more guessing and lucky than all other types of problems." — that part about guessing/luckiness is just BS. I guess this is just your unreasonable prejudice probably resulting from some fails on interactive tasks.
I won't say it is not my prejudice — but still I do not like them :P
I dont like output only problems too, cause I never actually solved one :).
"I do not like Interactive tasks in global — I think they are much more guessing and lucky than all other types of problems."
You haven't encountered any output-only problem in your life, right?
I think that guessing is actually an important part in solving problem. That's how you gain the idea and observation that are required to solve the problems. Experience is a kind of shortcut that allow you to make the observation faster.
Then why did you create interactive problem, if you hate them.
https://www.codechef.com/AUG18A/problems/INMAT
I knew someone will ask it :D
But I must disappointed you, both tasks used on the contests are not my tasks. They were on National Selection for IOI. As I am part of committee and was participating in preparation of the tasks I could take testcases and official solutions(I added some other testcases for this one too).
Normally people from Codechef knew that is not initially mine, we knew that may be some problems if anyone had seen it before, but I think everything was great during contest and you all got 2 new tasks.
Today Cook-off will have all my tasks and they are new for everyone I hope :)
Really hard to understand prob C. "Subsequence is a sequence that can be derived from another sequence by deleting some elements without changing the order of the remaining elements." What is elements,, order,, English is too hard....
Subsequence is a string that can be obtained after deleting some symbols from original string
G looks like problem C from the last World Finals. I guess it has a similar solution with merging sets or treaps.
F*** your pretests
is this the hardest div2A in the history of codeforces
No, 592A - PawnChess seems to be harder :)
You can check 200A - Cinema.
No , it was rather easy but some noobs made stupid mistakes
any idea about pretest 7 for problem D ?
Might be because of including 0's in range minimum.
Try this: 8 4 0 1 0 2 4 0 2 3
possible answer: YES 1 1 1 2 4 4 2 3
I had problems with test 7 too, but this test helped me.
3 3
0 1 3
YES
1 1 3 or 2 1 3
any idea about 10th pretest case. I failed on it. Could not figure out my mistake :/
Weak pretests = Never ending system testing !!
Can anyone see something wrong in here?
http://mirror.codeforces.com/contest/1023/submission/41722815
I noticed that the second lower_bound should be changed to upper_bound, but didnt have the time to submit it.....
Is it AC if I change to upper bound?
In E, as long as the distance from my current cell to the destination is at least n, then using one query I can know to which cell I should move such that it is allowed and it can reach the destination.
But when the distance from the current cell to the destination is n-1 or less (so the distance from the next cell to the destination is n-2 or less), what strategy should be followed then?
EDIT: Never mind. The answer to my question (which doesn't have to query such distances less than n-1) is here http://mirror.codeforces.com/blog/entry/61254?#comment-451801
How to solve C?
For each '(' find corresponding ')'. Delete these pairs from the string while its length is greater than k
Damn that's a simple solution. Thanks!
What does it mean "corresponding"? I was found pairs "()" on the beginning and on the end of string. If I can't find, I delete '(' from the beginning and ')' from the end. Can I claim, that I find corresponding chars? Or maybe, I must find nearest ')'? MySol
Sorry for poor english.
Make an empty stack. For each character in string, if it is '(' then put it on the stack, else remove the top '(' from the stack, and this ')' becomes corresponding to removed '('.
How to solve A?
your question is soo tough please wait Editorial like me!
t[:-len(v)].startswith(u) and t[len(u):].endswith(v)After a red bold number showed, I found this —
t[:-0].Maybe Python will help.
I tried Python's unfamiliar regular expression, found it didn't work, then waste a lot of time using C++'s strtok...
All I actually need is Python's split、startswith、endswith...
It was sarcasm dude
I have a solution using STL string functions xD
But you didn't lock any problems...
Hey noobs , how can you fail A? i can't understand you, noobs. it is rather easy task but you failed it. noobs.
really ez, just don't take the case s.size() > t.size() and s dosen't have the character *, but take the case s.size() — 1 > t.size() ans s does have the character *, REALLY EASY
noobs. how is it possible to forgot to check these easy cases??
Can someone please explain how to solve D ?
if there are three indices i < j < k such that ai = ak and ai > aj and aj > 0 then the answer is NO, it can be checked with segment tree. if there is no q in array and no 0 in array, then the answer is NO. otherwise the answer is YES. if there is no q in array and there is any zero in array, make it equal to q. for each zero , make it equal to any neighbour nonzero element.
That is too complicated. Let me introduce an easy one.
Iterate over a skipping 0's. There should be a increasing prefix, a sequence S full of maximum value and a decreasing suffix. Or a is invalid.
Consider a but not to skip 0's. If maximum value is less than q, try to find a
0surrounded by the elements in S and replace it with q. Or a is invalid. (Because q must appear in a according to the description.)Replace 0's with previous element in a iteratively (or replace it with 1 if there is no previous element).
5 3
1 2 1 3 1 is invalid?
Holy EFF! You should be rewarded with 100 points.
Oh here goes my rating
I thought the exact same solution but couldn't implement. Instead of using Segment Tree I was stuck on using Java TreeSet. Can you explain how segment tree would help here?
for each i from 1 to q if there is any i in array, I know when its first and last occurence in array. If the minimal element (except for zeroes) in range between its first and last occurence is less than i, then the answer is NO. Minimal element on range can be found using segment tree.
For the first check, I didn't use segment tree, I used an array of vectors
vector <int> v[N]that save in each vectorithe indeces where the numberiappears in the given array, and as it is known, each vector will be sorted automatically. Now, for eachiwhere1 <= i < nI will check for each indexjwhere0 <= j < v[i].size()ifv[nxt][0] <= v[i][j] <= v[nxt][lst]wherenxtis the next number afterithat appear at least once in the given array, andlstis the last index in the vector ofnxt.And if that condition is true then the answer is NO.
your solution says "YES" for test
4 3
2 3 1 3
Next time when you want to share your solution, please check if it is not wrong.
I commented after I had got AC, but you are right that this test hacks my solution, so it is wrong. Sorry about that. MikeMirzayanov, please, check this situation.
Applied the same, didn't know where I went wrong.
EDIT: Apparently I built segment tree without handling the case when the length of range is 1 and element is 0. It worked after that :(
Why is it optimal to always set 0 to q?
For example what if you have: (a < q) 0 a a a 0 and wouldn't [q a a a q] be invalid and we should set it to [q a a a a] instead?
i mean set 0 to q only once if there are no q in array.
First, there are a few nasty cases related to the last query: is there any
qin the input array, or else is there at least one zero to put it there...After that, I had another approach, somewhat technical yet trivial on the other hand. For each query from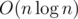 , we can just use a segment tree. Alternatively, a scanline-like approach would also work, treating first and last indices as "query started" and "query ended" events, and processing them from left to right. Finally, check that what we got corresponds to the non-zero entries of the given array.
, we can just use a segment tree. Alternatively, a scanline-like approach would also work, treating first and last indices as "query started" and "query ended" events, and processing them from left to right. Finally, check that what we got corresponds to the non-zero entries of the given array.
1toq, remember the first and the last index for this query. (For query1, let's say it covers the whole segment, just to get rid of zeroes.) Now process all queries in order; to do it ini thought about "segtree","priorityque",etc at the first glance,but the time limit 1 sec roared at me,"_stay away kid_"...
Consider the construction of a as follows: First, place 1's from the start to the end. Then, place the smallest possible segments for each number (so, for query q, go from the first instance of q to the last one). If there are no instances of q, place it where you will eventually place the last query (so, don't worry about it). If the last query is empty according to above setup, put it on a 1. If the last query is empty and there are no 1's, then the situation is impossible.
Of course, this is O(NQ). We want to do it a bit faster, so let's store the ends of each segment in some array. Then, go from the first position of a to the end, while maintaining a priority queue of the segments you are currently looking at. For each number in a, add it to the queue. Check if that number is the end of a segment, if so, remove it from the queue. If at any point the highest number in the segments is greater than the number in a, then it is impossible. When you come to a zero, just put whatever number is in the queue currently or 1 if there are none. But, if it is the last zero and there is no segment with the last queue value, then place the last queue number instead.
Gassa , WolfBlue Thank you..Finally got it !!
I did D with just a priority queue by constructing what the array has to look like after the queries (41700329).
You find the leftmost appearance for every number, and the rightmost appearance for every number. Then, with a priority_queue, you go left to right, doing the following:
This achieves the same as having query i fill between leftmost appearance of i to rightmost appearance of i.
After this, if the number q (from the last query) doesn't appear, put it at some zero. If q doesn't appear, and no zeroes exist, fail. This is since all intervals have nonzero length.
Then check that at all indexes that don't contain zeroes in the original array, your construction matches the original array. If it doesn't, fail.
Then fill all zeroes with arbitrary adjacent elements, and output the construction.
Problem C, D and E today are great.
In problemE ,I ask a wrong query. But why return me a TLE and MLE rather than WA or invalid input? As I know, every round in codeforces didn't return TLE and MLE in the past time. I'm very angry now, it wastes me too much time.
Answer "BAD" instead of "YES" or "NO" means that you made an invalid query. Exit immediately after receiving "BAD" and you will see Wrong answer verdict. Otherwise you can get an arbitrary verdict because your solution will continue to read from a closed stream.Maybe this?
Don't be angry, be careful.
"Answer "BAD" instead of "YES" or "NO" means that you made an invalid query. Exit immediately after receiving "BAD" and you will see Wrong answer verdict. Otherwise you can get an arbitrary verdict because your solution will continue to read from a closed stream." EDIT: I got ninja'd.
what a great contest!
Kudos to problemsetters :D
The problem set was balanced with fun tasks(specially D)
I think there is either a problem in the solution of A or the test cases are very weak.
For 7 7
abc*abc
abc!abc
the answer should be NO.
But codes that give YES are also getting accepted. I think the constraint that * can only be replaced by lowercase Latin letters has being ignored.
The third line contains string t of length m, which consists only of lowercase Latin letters.
...the string t consists of only lowercase Latin letters...
The test is invalid.
Problem the statement, "The third line contains string t of length m, which consists only of lowercase Latin letters."
Thank you for the contest!
Problem E is very nice.
I'm glad you liked it :)
How to view on which test case my solution was hacked?
You can see that after the contest is finished.
Freaking A again!
my E will fail. (
Editorials please!
Really weak pretests :(
tc 87 for problem A ??
Deadly problem A :D
Even less than B and C. be scared.
What were the problems that were taken from VK Cup finals 2018?
F was easier than A!
What is going on with my solution for problem E? I submit a query and, even though I never receive BAD as an answer, I do not receive an answer sometimes on test case 18 (see diagnostics). Does the interactive program print extra characters or whitespace?
Edit: Never mind, the diagnostics are just bogus.
when will be the solutions available?
How to solve problem B, please explain the logic of math behind it.
Imagine you have n=10, in how many ways can you make the sum 10?
1+9 = 2+8 = 3+7 = 4+6 = 10 (4 pairs)
Do you see the pattern?
Now, why is this surely the answer? Well, because it is stated that the pairs (a,b) and (b,a) are the same and because we have each number only once. Now, there are 3 cases to consider: 1. n>=k 2. k-n>n and 3. k-n <= n
Lets think about the first one together, then you can think about the other two:
n>=k means that we have numbers that are bigger than the sum k. You can't use such numbers because, well, they are already bigger than k. What is the biggest number you can use then? Its k-1, because you can pair it with 1 to sum k. So just assume n=k-1 and count the pairs like I did in the first example. You will end up with (k-1)/2 pairs.
Can anyone explain why this code gives TLE for Problem C . Link for the solution http://mirror.codeforces.com/contest/1023/submission/41695850
You allocate a new copy of the answer string on each iteration. Try
ans += '(';instead.Even better, just print the output directly to
cout.Use
a+=xinstead ofa=a+xfor strings. AC solution: 41731870CONFUSED BETWEEN PYPY2 AND PYTHON2
I have been using pypy2 for over a month and I shifted to pypy2 from python2 just because pypy2 is faster than python2, but today when I tried question C using pypy2, it gave TLE and when I submitted the same code with python2, it worked fine. Pypy2 solution: 41730885 -- verdict=TLE. Python2 solution: 41730897 -- verdict=Accepted Can someone tell me when to use python2 instead of pypy2 ?????? Thanks
https://pypy.readthedocs.io/en/latest/cpython_differences.html#performance-differences
wow thanks man collares that was exactly what I needed :)
Thanks A lot :)
Benq kept his promise to become a LGM :)
Congratulations !!
My mission is nearly done unless you win the IOI!
Since a lot of people seems to be using max segtree for D (my in contest idea was lazy max segtree but it would go against my morals to submit something like that), I thought I'd elaborate on the sweep/set technique.
Basically you store O(n) amount of start, and end events.
Here is how you calculate them:
for (int i = 1; i <= n; i++) if (leftV[arr[i]] == 0) { leftV[arr[i]] = i; st[i].push_back(arr[i]); } for (int i = n; i >= 1; i--) if (rightV[arr[i]] == 0) { rightV[arr[i]] = i; ed[i].push_back(arr[i]); }Then you can use this information to calculate, for a point, which values have hit their leftmost point but not yet their rightmost point. We call the maximum of these values "val", in my code I called it "maxcover".
This can be stored in set , or priority_queue (heap), because you only care about the maximum. (I think mango_lassi did this)
for (int i = 1; i <= n; i++) { for (auto e : st[i]) s.insert(e); //starting events (inclusive) maxcover[i] = (*s.rbegin()); for (auto e : ed[i]) s.erase(e); //ending events (inclusive) }Then using this information you can optimally assign any 0 values to val[i] described above.
C looked easier than A. Link for Editorial of C
I have also tried to explain A's approach. Link for Editorial of A
Thanks a lot buddy. A nice solution
My problem F got TLE because I didn't remove the "cerr" in my code. So my code printed 5e5 integers to stderr...... (It is interesting that "cerr" in my code was not executed for samples) I know this is a hilarious mistake and it is my own fault... Well, I expected this would get "WA", but I got "Pretest passed" instead... QAQ
Stderr is ignored when checking correctness, cerr can cause TLE only, it can't cause WA. In order to not worry about time it takes I suggest you do the following:
1) Compile with -DLOCAL flag locally
2) Add
#ifndef LOCAL#define cerr if(0)cout#endifto your templates.
Thank you! I'll try this next time XD
Problem C was easier than A...
Just remove n-k characters from the string. When you remove '(' from the string, remove ')' from it too. Where index of '(' is less than ')'.
Weak testcases in D
My solution gives NO for
When will the editorial be published? I'm so eager to see how problem G can be solved. (Because nobody has solved it yet :-)
In D shouldn't be the output of the following testcase YES but it's showing 'NO'. 3 3
2 1 3 Weak test cases.solution
Can anyone explain what is meant by the error or what does it mean in the following E problems solution?
Solution link is
Your text to link here...
Thanks in advance:)
Why have you done cout << dp[i][j] ?
Where's the editorial?
While I was looking through the top Accepted solutions for 1023D I found out that someone got his solution accepted on the following test case:
Answer his code produces is 'YES'.
According to me the answer should be 'NO'.
Can someone explain to me how this solution got accepted?
Also this test
Real answer is "YES", but his answer is "NO".
still waiting for editorail...
Can someone explain what I must to do in C?
Sorry for poor english.
Given a regular bracket sequence with size n, you have to find a subsequence of it with the size k, which is also a regular bracket sequence (answer guaranteed to exist).
A subsequence of a string is created by removing some (maybe none) characters of that string, and keeping the remaining characters by the original order (more details on that below).
A bracket sequence is a sequence/string consisting only of
(or).We can define the term "regular bracket sequence" recursively, like:
"" (empty string) is a regular bracket sequence (RBS).
If R is a RBS, then "(R)" (R being inside a pair of parentheses) or "R()" or "()R" (the string
"()"stands right before/after R) is also a RBS.Take the first sample test for example.
With the string
()(()), there are many subsequences with the length of 4, like()((,()(),())),(((),(()),)((),)()).Among them, only a few are regular bracket sequences, like
(())or()().You can choose any sequence among these — they are all valid answers.
Maintain a stack and traverse the string. If you encounter '(', push onto stack. If you encounter ')', pop from stack. This removes 2 elements from the final string. You need to pop (n — k) / 2 times. Print the contents of the stack.
Can anyone suggest what I am missing out in my submission for question D. 41737987
5 3
1 2 1 3 1
Your program answers NO while the answer exists.
Thank you for helping me figure out my mistake.
Can anybody tell the link of editorials for this contest?
Where is editorial?
Can someone please explain the stack or priority_queue method for solving D. I was able to solve it using Segment Trees but even after reading comments, I couldn't understand how to do it using stack or priority_queue.
Why does 4*n number of queries seem inefficient in problem E ?
https://mirror.codeforces.com/contest/1023/submission/41731400
Try this:
Your program correctly goes to r=5, c=5 and then asks
? 5 4 9 9which isYES(? 1 1 5 4would lead toNOif that query was allowed). Your program then stumbles around in that trap, querying some fields repeatedly, using up more than 4*9 = 36 queries...Can someone explain a solution with HLD for problem F?
I can explain the idea.
We can obtain a minimum spanning tree T of the graph by setting the weights on our edges to 0 and running any MST algorithm, since we know that we will eventually set the weights on our edges such that they will all be included in the MST.
The main observation is that given any edge e = (u, v, w), we know that the path from u to v in the minimum spanning tree T cannot contain any edge e' with weight w' > w. Otherwise, T - e + e' would be a lower cost MST.
We can use HLD to compile all such constraints imposed by our competitor's edges and determine the maximum possible weight for each edge in the MST.
However, I am not sure if it's an intended solution. I was barely able to squeeze my HLD implementation under the 3s time limit. To do it I had to make use of the fact that we update arbitrary paths but only query single edges, so we can use a segment tree without lazy propagation: http://mirror.codeforces.com/contest/1023/submission/41885123
Interestingly, you could modify it further using the fact that all of the queries come after all of the updates; it is not even necessary to use a segment tree at all.
can someone please provide a test case where this solution will fail http://mirror.codeforces.com/contest/1023/submission/41825727
Where can I find the editorial of this round?
http://mirror.codeforces.com/blog/entry/61356
editorial ???
http://mirror.codeforces.com/blog/entry/61356
For problem D of the contest following test case: 4 4 4 2 1 3 Some have answer: YES 4 2 1 3 But some solution printing "NO" instead are also accepted. Please include this test case.