


Hello, codeforces!
This time I've decided to choose a task from my own contest which took place last April and was known as the Grand Prix of Poland. If you want to write this contest virtually in the future, then consider not reading this blog. If you've participated in this contest and maybe even solved this task, then anyway I recommend reading it, cause this task has many very different solutions, each of them being very interesting (in my opinion). It's also a reason why this blog is longer than previous ones.
I'll write about task C "cutting tree" (not uploaded to the ejudge yet :/). The statement goes as follows:
You are given a tree with n vertices (1 ≤ n ≤ 2·105). The task is to calculate f(k) for each integer k from the range [1, n] where f(k) is defined as the maximum number of connected components of size k which we can "cut off" from the tree. A connected component of size k is a set of k vertices such that it's possible to traverse in the tree between any pair of these vertices using only vertices from this set. Chosen components are not allowed to intersect, so each vertex must belong to at most one component.
It's easier to think about this task with the knowledge that we can assume that we can choose components of size at least k instead of exactly k. If we have some solution (for some k) with some component having size greater than k, then we can erase some vertex from it and decrease its size (components in this problem are trees, so always we are able to remove some leaf).
O(n2)
Firstly, we have to understand how to calculate f(k) for some particular k in O(n). It turns out that the following greedy algorithm is correct: as long as there are at least k vertices in the tree, pick any rooted subtree of size at least k such that all subtrees rooted at children of its root are of size smaller than k, add it to the result, and remove it from the tree. Why is it correct? Take an optimal solution. If this vertex is not in this solution, we can add it with its subtree and improve the result. If it is in this solution, but in some differenct component, we can discard this component and add this vertex's subtree. This would be correct, as it would only make more free place above this vertex. No other component would block us below this vertex as it has no child with size at least k.
So, to solve the task in quadratic time, we have to write dfs which returns the information about "how many vertices in the subtree of this vertex still has no component assigned to them." If at some moment some vertex has at least k free vertices in its subtree, then we change this amount to zero and increase the global result by one. This solution is of course too slow.
O(n1.5·log(n))
The assumption about "at least k" instead of "exactly k" gives us a trivial observation: results are nonincreasing. We can notice more, the inequality k·f(k) ≤ n always holds. This implies that for k ≥  , f(k) will not exceed (so there are only possible values of f(k) for k greater than ). Of course there are only values of k smaller than , so there are only
, f(k) will not exceed (so there are only possible values of f(k) for k greater than ). Of course there are only values of k smaller than , so there are only  possible values of f in total!
possible values of f in total!
Let's assume that we already know values of f(k) for each k from interval [1, m] (at the beginning m is equal to 0). Let's ask our magical-blackbox function (from previous solution) about the value of f(m + 1). At this point, everybody should think about a binary search. So, let's use it to determine for how long doesn't the value of f change. After finding the greatest k with this same value of f(k), we increase m and keep doing more binary searches as long as m < n. The complexity is 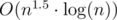 (O(n) because this is the time complexity of calculating the value of f,
(O(n) because this is the time complexity of calculating the value of f, 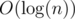 because of binary search and because this is how many times the binary search is used).
because of binary search and because this is how many times the binary search is used).
Unfortunately, this solution has a huge constant factor, but it's possible to speed it up. Firstly, it's possible to implement the blackbox (the function which calculates f(k) for some chosen k) iteratively instead of recursively, making it a few times faster. Secondly, our binary search isn't too smart if it's written straightforwardly. It doesn't use information from previous binary searches, which have already told us a lot. So, we need some good way to optimize it. Here comes the most interesting part of this solution. Let's write a recursive function solve(l, r, lower_bound, upper_bound) which has to calculate values of f(k) for each k in the range [l, r], knowing that f(l) = upper_bound and f(r) = lower_bound. How should this function work? If r - l ≤ 1, then we know everything about values in this (short) interval. In other cases, let's pick 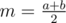 (rounded if necessary), ask for the value of f(m) and run functions solve(l, m, f(m), upper_bound) and solve(m, r, lower_bound, f(m)). Everything looks quadratic again, soooo, where is the optimization? If at some moment lower_bound = upper_bound, then there is no point in asking more questions in this the interval [l, r] — we know that every k from this range has this same value of f(k) and we already know this value.
(rounded if necessary), ask for the value of f(m) and run functions solve(l, m, f(m), upper_bound) and solve(m, r, lower_bound, f(m)). Everything looks quadratic again, soooo, where is the optimization? If at some moment lower_bound = upper_bound, then there is no point in asking more questions in this the interval [l, r] — we know that every k from this range has this same value of f(k) and we already know this value.
It turns out that this solution works in this same complexity but is substantially faster.
O(n1.5·log0.5(n))
Small optimization, but worth mentioning anyway. If we brutally calculate values of f(k) for each k up to  , then we have to do only
, then we have to do only 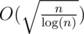 binary searches, so the formal complexity will decrease to
binary searches, so the formal complexity will decrease to 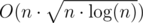 .
.
O(n1.5)
To completely get rid of the 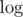 factor, we need to try a different approach. As we know that we are aiming at
factor, we need to try a different approach. As we know that we are aiming at 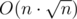 , the idea to calculate first values of f with our blackbox sounds good. For bigger values of k there will be at most components, so let's remember how exactly they look while calculating
, the idea to calculate first values of f with our blackbox sounds good. For bigger values of k there will be at most components, so let's remember how exactly they look while calculating 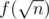 . In particular, we'll use colors to denote for each vertex in which component it is. Also, we need to remember for each color how many vertices are painted in this color and which vertex is the root of this component. Now, let's iterate over values of k greater than and try to fix each component if it's too small by moving it up. This solution needs some proofs to be sure that everything is OK, but I'll skip them.
. In particular, we'll use colors to denote for each vertex in which component it is. Also, we need to remember for each color how many vertices are painted in this color and which vertex is the root of this component. Now, let's iterate over values of k greater than and try to fix each component if it's too small by moving it up. This solution needs some proofs to be sure that everything is OK, but I'll skip them.
Let's write a function fix(color), which will try to fix this component if it's possible and let's fix them from the deepest ones. If the root of this component is the root of the whole tree, then it's impossible to fix it so we should just erase this color. To do this, a function recolor(vertex, from, to) will be useful. This function should recolor every vertex marked with the color from with new color to and run itself recursively, but it should stop when it reaches a vertex with a different color than from.
In a case when we want to erase some color we have to run it in this way: recolor(root, this_color, 0), where 0 denotes having no component assigned. Also, when the component we are trying to fix has no vertices assigned to it (because some other component has absorbed it), we should just forget about it. If some component has less than k vertices (when we are calculating the answer for some fixed k), then we should recolor the parent of the root of this component and update the information about which vertex is the root. As we don't want components to become disconnected, we cannot just recolor this one vertex, instead we have to use function recolor(new_root, color_of_higher_component, color_of_lower_component). This algorithm might look suspicious, but it turns out that in this way we won't do anything wrong. In case when some component absorbs some other one by moving up and recoloring its root, to save this second one from disappearing we have to push it up. It can be observed, that then we'd need to push it up so long that it will reach the root of next component above it. To save this next component we'd need to again push it and make it eat next component above it and so on to the top of the tree, where the last one (or maybe even more) would just disappear, so we can just forget about this absorbed color.
There is one more thing. There can be two components, let's say A and B, and we fix A before fixing B. Then it's possible that A will go above B (when we fix A) and after that B might eat some vertices from A, making it too small. For example, if the roots A and B have a common parent in the tree, A moves up at least two times and then B moves once, then A loses many vertices. This is possible even if we consider the components from the deepest one. In this case, after fixing some component, we should run our fix function on the component which is directly above it (if exists) to be sure that everything is OK.
So, why is it fast? For each k we look at every of components and also each vertex is recolored in each of the colors at most once, so everything amortizes to .
O(n·log2(n))
To solve this problem without factor in complexity we need to use again the fact that k·f(k) ≤ n holds. Of course, it means that 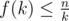 . Many of you may notice, that the sum of answers will be
. Many of you may notice, that the sum of answers will be 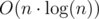 , so maybe it's possible to collect these components one by one? It turns out that it's possible, we'll grab each of them in complexity .
, so maybe it's possible to collect these components one by one? It turns out that it's possible, we'll grab each of them in complexity .
How to do it? Let's for a moment assume that our tree is a caterpillar and we are solving this problem for k > 1. With this assumption the following algorithm is trivially correct: let's do a binary search from the bottom of this caterpillar to find the lowest vertex where we can cut off the first component. After finding this place do next binary search to find next component and so on until even cutting the rest of the tree wouldn't give us enough vertices.
But unfortunately, the tree doesn't have to be a caterpillar. So, where can this algorithm fail? It fails on a test where some vertex has at least two subtrees with sizes at least k. If we tried to do the binary search starting somewhere in one of these subtrees, then we could take this vertex together with its second subtree while it could be possible to collect many more components in the second subtree, so we need to do second binary search in the second subtree.
But this case it's enough to describe what can go wrong and it's easy to fix it. We have to stop at vertices with at least two children with sizes at least k. How many such vertices can be there for some fixed k? Every such vertex in some way "merges" two sets of sizes at least k, so there can be at most 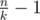 such merges. So, we can preprocess these vertices for each k and "extract" smaller tree which consists only of these vertices, root and some additional leaves. We need leaves cause we should start the binary search in them. Which leaves should we take? For each vertex in our set and each child of this vertex which has subtree of size at least k let's "dive" down going always into the biggest subtree. Why into the biggest? It's clear, each vertex that we are passing by must have at most one child with size at least k, so it's definitely the biggest one.
such merges. So, we can preprocess these vertices for each k and "extract" smaller tree which consists only of these vertices, root and some additional leaves. We need leaves cause we should start the binary search in them. Which leaves should we take? For each vertex in our set and each child of this vertex which has subtree of size at least k let's "dive" down going always into the biggest subtree. Why into the biggest? It's clear, each vertex that we are passing by must have at most one child with size at least k, so it's definitely the biggest one.
When we know the set of vertices, we should construct this extracted tree. How to do it? Let's preprocess preorders and postorders for each vertex. Having these arrays, we can consider vertices by increasing preorder and keep a stack, which will behave like a recursion stack. When we consider new vertex, we should pop vertices from this stack as long as the vertex on the top of the stack isn't an ancestor of vertex we are currently considering. Then, the vertex which is on the top of the stack is a new parent of vertex which we are currently considering. In this way, we can construct the extracted tree in linear time (linear of its size).
Then just run dfs on this extracted tree. In every vertex (starting from leaves) let's do the binary searches as long as we won't reach our parent (parent in the extracted tree). When it happens, we should give him information about how many vertices remained in the subtree of his child (child from old tree) in which we currently are (vertices from old tree). This information is enough for him to know how many vertices he should want to cut doing the binary search.
The last thing is how to do this binary search. This part is easy. We need jump-pointers. I won't describe this part as it's known how to do this binsearch in instead of 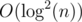 .
.
O(n·log(n))
During mental preparation to writing this blog I've figured out how to solve this task with one factor, which is very surprising even for me, so please, if something's wrong with this solution, take it easy and let me know in the comments. :D
We can observe that whenever we do the binary search, we follow one heavy path in the tree (if we'd imagine heavy-light decomposition). Here comes my freshest observation: in each heavy path we can store something with size O(size_of_subtree_of_highest_vertex_on_this_heavy_path) and it will amortize to ! Why? You've probably heard about "smaller to bigger" trick. It uses the fact that in each vertex of a tree we can have sizes of each of its children except the one with the biggest subtree in complexity and it will amortize. And here we're doing this same thing, but to build a data structure, not to calculate something. So let's for each heavy path store a vector which for each i denotes the lowest vertex with size at least i. In previous solution we were using a binary search to find the lowest vertex which has subtree of size at least x. With this data structure, we are able to do "binary search" in constant time.
Wombo Combo (O(0))
You may have noticed that solutions which work in complexities and 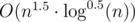 focus on calculating less values of f, while O(n·log2(n)) and O(n·log(n)) focus on calculating these values faster. So, it's possible to combine these solutions and achieve negative times!
focus on calculating less values of f, while O(n·log2(n)) and O(n·log(n)) focus on calculating these values faster. So, it's possible to combine these solutions and achieve negative times!
So, this is the end, sorry that you had to wait a little bit longer, but I've also had my private things, and this blog will probably be one of the longest ones. What do you think about this task? How much have you learned? And of course, which solution is your favorite one? Let me know in the comments. See you next time! :D







Here comes the contribution whore. Tourist will always be number one in contribution list in our eyes. It's all a matter of him writing one blog and he will overtake you.
And I was wondering how is it possible that after definitely too short time to read the whole blog after posting it I already have downvotes XD
Who cares about tourist when we have a new legend in this era called Radewoosh!!!!!
Wow, good lesson for me.
Unbelievable!I knew nothing about this before.It's very good!
"For each vertex in our set and each child of this vertex which has subtree of size at least k let's "dive" down going always into the biggest subtree."
I thought we can dive down going in any subtree (it don't have to be the biggest one)? Because for each vertex in our set and each child of this vertex, we only need one leaf vertex inside the subtree of the child.
Also, if do this part naively, will the complexity stay in the allowed limit?
limit?
Consider a caterpillar, in my opinion if you’d in some moment stay in a leaf in the middle of the tree instead of going down along the path then you won’t get the best possible result.
No, you have to preprocess array “dive” and calculate it with dp.
Where we able to submit this problem?
Here: 1039D - You Are Given a Tree