


Привет, Codeforces!
В 27.08.2018 19:35 (Московское время) состоится AIM Tech Codeforces Round 5.
Раунд подготовили сотрудники компании AIM Tech: Kostroma, riadwaw, Edvard, yarrr, zemen, Errichto, malcolm, gchebanov, VadymKa и zeliboba.
Раунд пройдет во время Петрозаводских сборов, спонсором которых является наша компания.
Благодарим Михаила Мирзаянова (MikeMirzayanov) за замечательные платформы Polygon и Codeforces, и координатора задач Codeforces Николая Калинина (KAN) за помощь в подготовке раунда. Огромное спасибо Golovanov399, Arterm, winger за ценные замечания и прорешивание раунда!
Наша компания занимается алгоритмической торговлей на бирже, ключевыми понятиями для нас являются low latency и high frequency trading. Перед ребятами в нашей компании стоят разнообразные задачи: написание стратегий для торговли, оптимизация торговых систем для достижения минимально возможной скорости реакции на биржевые события, сохранение и обработка больших объемов исторических данных. Умение писать эффективный C++ код, алгоритмическое мышление и математическая интуиция очень полезны в нашей работе, поэтому большая часть наших сотрудников — олимпиадники по программированию и математике. У нас работает несколько финалистов ACM ICPC, три золотых медалиста и чемпион мира (и золотой медалист). В свободное от работы время мы участвуем в разных соревнованиях по программированию и не только, испытываем себя на прочность в походах и покоряем горные вершины.
Узнать о нас больше можно на сайте aimtech.com, в facebook и instagram. Можно отправить нам резюме через эту форму, даже если вы не участвуете в раунде.
Участникам совмещенного раунда будет предложено 8 задач и 2:15 на их решение.
Обратите внимание, что последние три задачи отличаются по сложности меньше, чем обычно, поэтому рекомендуем прочитать их все.
Призы с 502 раунда в память о Leopoldo Taravilse будут разыграны в этом раунде.
Топ-25 получат 100$ каждый, 26-71 места получат по 50$ каждый.
Разбалловка 500-750-1250-2000-2500-3250-3250-3500
Всем удачи и высокого рейтинга!
Спасибо за участие, поздравляем победителей!
Информация о получении призов и будет опубликованы позднее.







Last year AIM Tech round 4 was my first ever round on CF
I didn't do too well then D:
hi neko_nyaa
could you please tell us what you do to improve your skills in competitive programming and get this level (rating) in only one year ? please don't just say practice . tell us what kind and type and of practice
you need a lot of luck
Luck?
It's not about luck. It's about hard work.
when going from 1400 to 2000 it is about luck and some work. hard work begins from 2000
4 years of green ..
that's because you did't learn anything while solving contests and reading editorials.
Wow that's unnecessarily harsh.
1) harsh but true 2) you also don't have any progress
3) You're an asshole.
Solving a lot of problems that you can't solve initially, of course.
i doesn't help. if you don't know how to solve a problem, there is no profit. if you know how to solve a problem, there is still no profit. maybe there are some problems that can help you, but they are not frequent, maybe 1 or 2 of 100
try solving 100+ questions on spoj in users sort mode.. I bet u would definitely gain something. best of luck!
Heck, how far have you been for a year. I'm pretty much jealous if you ask. :D
I think got some trouble in recent rounds. With many small mistakes and feel very tired then coding. Maybe I should rest for a while? Or are there any way to improve skills to prevent such small mistakes?
I hope I can promote fastly like you,you are brilliant!
And we people thought only vovuh used the copy pasted part... knock..knock
This round is special for me as last AIM Tech Round was the highest rating change for me ever!
Wow! Didn't expect that! Very very interesting! Perhaps you could tell us a bit more about that? I'm sure everyone's eager to know!
You know how when you get rating increase on CF it asks you if you want to share it? They should make it so there's an option to auto-generate a blog post about your huge gains
I never meant to boast about it (Its not even worth boasting anyways). Just felt good to share it.
Agreed that it doesnt make much sense.
That's exactly why we need it!
Just curious, why prizes for Top-71? (i.e. why 71 people?)
I meant, if all winners got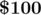 , so the winner count would be 48 people — ain't that number be nicer? :D
, so the winner count would be 48 people — ain't that number be nicer? :D
(Or at least my perspective in pretty numbers has been weird all the time :D )
LOL
Oh, you got upvotes for the lol and he got downvotes for what makes you lol .. weired community T_T
That's why I rethink 10 times before commenting anything on Codeforces.
P.S.: I didn't think twice before commenting this.
Thinking implies there actually is logic.
Welcome to the club :D
LOL
Well I expected my downvote storm :D
Still, don't even think that made one of the setters LOL :D Like, my jokes have been ill all the time :D
UPD: Got upvoted a lot, while the upvote counts of most other comments have barely increased. Okay what logic is behind this... :D
it is coming back up now, i guess someone had to say it :p
Perhaps they noticed majk's comment. It got quite a bit of upvotes.
Initially we wanted to award $100 to the top 25 and $50 to the following 50, but the contributions in the campaign weren't enough so we made it the following 46.
"We"? Weren't you in the same room as mine, as a participant? :D
(I'm just curious :D )
By "We" I mean me and Leo's friends, not the contest organizers. I have nothing to do with organizing the contest itself, and didn't know any info more than what everyone else knew before the contest.
Anyway, I was sure that I have no chance being in the top 71. :)
Well, still good to know then. ;)
Tried to hack your solutions twice, and both failed miserably. Shame on me. :D
=A=
I want to become expert this year as well :)
What is good in not being hacked?) It's better to be hacked with a chance to resolve then to fail the system testing
it is better to solve task without mistakes so no one can hack you
Sure, I just claimed that hacks are not what we should be afraid of: incorrect solutions are.
Unless it is a hash collision hack
it is too late in China this round. half past midnight makes me give up this round.
And maybe lose the chance to win a prize :)
compare to health, prize is nothing.
(Actually I didn't register for this round for the same reason either) Good night.
What if someone can't afford healthcare?
codeforcescare
I thought you were a student
Interesting terms of agreement this round... XD
Thanks, fixed.
@MikeMirzayanov since rated and $, i have to ask about server stability issues?
I hope this round won't be like that
How will the prizes be distributed? Is it bitcoin like round 502?
http://mirror.codeforces.com/blog/entry/61450?#comment-454399
Its my first aim round. Apparently there will be a lot of hacking. Good luck)
Me,too. hope so!
a short note :
unfortunately because of u.e.e (university entrance exam) in Iran i can't participate in contests for almost 10 months !
It's very upsetting and i'm very sad because of it Right now !
i hope that i'll participate in the first contest after u.e.e. in july 2019 !
btw i'll prepare a round when i'm back :)
bye bye codeforces, until july !
Does the exam last 10 months?
Many countries has very harsh university entrance exams as the most important or even the only criterion for entering good universities. High school students must intensively review and practice for a long period to prepare for it. For example, that is also the case in China, Japan and Korea.
you forgot india
Just list some countries I know. There are definitely many more. I don't know how it goes in India.
Good luck!
Tnx :)
Really Interesting problemset
Why the strange and unusual bounds?
We tried hide reason why restriction in G is unusual
Note to self for next year's AIM Tech Round: do not go into hacking :D
Problem C
No.
Yes.
Exactly this one, only in 2D.
I'm wondering whether round coordinators were different for these 2 rounds otherwise it's hard to explain why they didn't notice 99% match of these problems.
lol, I was wondering why it was taking me so long to solve
xd indeed
the drawback from different coordinators
Hi, so to me seems like a notorious coincidence.
To be serious, it's a pity nobody from authors' team is regularly solving Div. 3 contests. Probably next time we would check several previous contests to avoid such inconvenient situations. Sorry for that.
I went with that method as well. Unfortunately, problem C wasn't enough. There was/is some point important to note, without which it will throw WA as it did with my case.
what the hell is test 8 on problem C >_< ?!
I think it is something like this:
3
0 1 3 2
1 0 2 3
4 4 5 5
How do you solve C? I used amortized search for n log n but it seems highly suspicious
What's wrong with just doing it in n log n? It's simple and works.
well, it uses randoms, therefore I am suspicious
UPDATE: it passed
Oh, my n log n doesn't use randoms, It just splits the intervals like a segment tree (the code is pretty self-explanatory): 42165548.
How do you get a randomized solution to this problem? :Dd
idk but apparently it's blazing fast:
https://mirror.codeforces.com/contest/1028/submission/42169784
155ms pretests
Only thing I'm worried about is correctness
Basically I aim to find two disjoint rectangles because we know that the points in one of them will have the answer. To do this I just search until I reach a disjoint area in the sequence, then I know that the pair must be in the first X rectangles, where the X rectangle given causes them to be disjoint. Then I randomize and continue searching. Hopefully most of the time each random ends up discarding a lot of rectangles.
Then I just exclude one of these rectangles at a time and get the answer
I think that's randomized O(n) right? There's a 25% chance that both end up in the first half of the prefix, so even if you only halved the prefix when both were in the first half, you'd get:
Which means:
Which is O(n). (shuffling a prefix takes linear time to its length).
Thank you for your insight! I'm not good with complexity so I'm going to have to do more reading lol
O(n) solution: precalculate intersections of all prefixes/suffixes of rectangles. If the intersection doesn't actually exist, then you have a rectangle with a low x/y higher than its high x/y, which you can easily check for. You can then brute force all possible n-1 rectangle combinations.
42180099
Our programs are uncannily similar :O
42167537
I don't know why you're using nlogn or randomization. Isn't it enough to just find intersection of first i rect and last n-i-1 rect and see if it's not empty
In problem D, how to deal with ADD orders after the last ACCEPT?
It's just 'count of them + 1', because all the numbers are different.
if they're in between the clamps (confirmed buy/sell offers), multiply by the number of adds + 1
Thanks all.
How to solve problem D?Can someone explain?
Observe that if there are no "ACCEPTS" then answer is simply #("ADD") + 1 since you can partition the prices at any point. Also note that "ACCEPT" only restricts the segment where you can partition. This should be easy to implement. Take care of cases where once you "ACCEPT" your value you know that minimum and maximum of your restricted segment is in which direction.
Thank you.
What is pretest 17 in G? I get TLE in the test, even though my code precalculates everything, so the runtime should be the same for every test. 42181918
Locally everything takes like 0.05 seconds so I'm rather baffled.
EDIT: The pretest is just the value M. I had a indexing mistake that caused the code to ask more than 5 queries sometimes. Fixing it gives AC: 42189394
How to solve E?
Find any point where val[i] < val[i+1]. Set ans[i+1] = val[i+1]. Then, for j = i, i-1, ..., i+2, set ans[j] = ans[j+1] + val[j]. Then, in order to ensure the value is large enough, if ans[j] < 1e9, set ans[j] = ans[j] + 1e9 * ans[j+1].
It's easy to verify that this works. 42175007
Special cases are val[i] = val[j] != 0 for all i && j, in which case you answer NO, and val[i] = 0 for all i, in which case you just print a bunch of 1's.
If all elements of b equal, then there are two cases: b0 = 0 and b0 ≠ 0. b0 = 0 is trivial. For b0 ≠ 0, it can be proved that answer does not exist.
Otherwise, find any position k in b such that bk > bk - 1. Assign ak = bk. Then, construct the array a backward from k - 1 to k + 1. For position i, we need to find ai such that:
ai = x * ai + 1 + bi with x can be any non-negative integer.
ai > bi - 1.
Since ak + 1 > bk, it followed that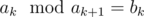 .
.
I wonder why should we find the position that $b_k>b_{k-1}$?Could you please explain it?Thanks a lot!
We choose such a position so that we can assign ak = bk and having the condition ak > bk - 1 satisfied.
O...I understand it!Thanks!
In B.I submitted a wrong code got WA in pretest 1.When I checked the Correct Answer.It was like this. 55555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555....
4444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...
Then got AC.I think it is not right to give correct logic corresponding answers
Maybe, for the constructive problems, the admins should implement the system specifically for those to show the checker logs only (Yup, that means the checker should only answer if the outputted answer suits the criteria and not give any clues to the model solution).
Or to show the examples as usual...so you don't need to check answer...as usual
I quite doubt that idea to be possible, as the output in the sample is force-shown by a feature in Polygon, and I don't think it'd synchronize well with the judging protocol.
I think we should stop showing answers for pretests during the contest, just show your output and checker log.
Yeah we've also noticed this during the contest and for new submissions only the answer same as in the statements (with no hints) is shown. I think it is sometimes useful to show correct answer and checker comment, we just forgot to check that in the system it shows the same answer as in the statements.
How to solve C?
read maximal intersection 506div.3
We need to find any point which lies in n-1 rectangles out of the given n rectangles. There can now be n cases. The first case will be considering all rectangles except 1, second case will be all rectangles except 2 and so on until index n. We can now create two arrays. First array will store the intersection area start and end of all the rectangles before an index. Second array will store the intersection area start and end of all the rectangles after that index. This can be done by: arr1[1]={start[1],end[1]}; for i=2:n arr1[i]=intersection(arr1[i-1], start[i], end[i]); /// Intersection returns both start and end area // of intersection region. arr2[i]={start[n], end[n]}; for i=n-1:1 arr2[i]=intersection(arr2[i+1], start[i], end[i]);
We can now for all rectangles check whether rectangles on left and right intersect or not.
can we store Negative Numbers in a mutliset?
Yes
http://mirror.codeforces.com/blog/entry/61450?#comment-454356
Statement of problem D was so annoying -_-
especially capitals
I noticed that it's possible to see output of the author's solution and verdict of the checker for tests from the statement during previous rounds and at the time I already thought that it's pretty strange.
In the round today it actually gives an obvious clue of the solution. The algorithm might be — send a solution with hardcoded answers to the tests from the statement, look at the output of the author's solution, get the idea and implement a similar solution yourself.
What do you think about this? Seems like Test Protocol should be hidden in order not to give such a clue to contestants.
I think it should hide jury's answer and showing contestant's output only.
I think even this is unnecessary. You can see the output for a given sample by running your solution on this sample on your machine.
Sometimes, the output on local machine is different from the output on Codeforces judge (because of different compiling environment or buggy code lead to undefined behavior).
Then you can see it in the "Custom Invocation" tab :)
But KAN already answered above that "I think it is sometimes useful to show correct answer and checker comment" so it seems like admins have the same opinion as yours.
See my answer here. It was just a bug that an answer different from one in the statements is shown.
quickforces
That moment when the last problem was made just for you.
In problem C, for pretest 4, it showed correct output on my IDE and on some online IDEs also. But I got WA on that pretest. Can anyone please let me know what error did I do?
Code : http://mirror.codeforces.com/contest/1028/submission/42181202
1) check your computer's power 2) try restarting
But online IDEs also give correct output -_- You can run it on your device to check it -_-
Looks like in some compilers (like ideone)
sortdoesn't work correctly in your case for some reason...Sorry, of course
sortalways work correctly...Maybe I've found the problem. It's with
idx: it's "-1" on Codeforces and "4" on ideone before the lasterase. I believe this happens because in the secondfor(i = 1; i < n; i++)you take both p2[i-1].first and p2[i+1].first.Then p2[n].first and undefined behaviour. Ideone say !f(...p1[n].first, p2[n].first, ...) is true and Codeforces say it's false.
looks like the 'guy' 000000 cheated again. If it was a normal round, then i wouldn't care, but this round has prizes for top contestants, and this account is on top!
Again? (like he did something before?)
Can you clarify yourself?
Click here...
I Can't see how he cheated, can you explain more?
I can see one guy used C and the other used C++. I think there is also another guy
Codeforces Show the answer of problem A During the contest !
When you get a wrong answer, The jury answer is the Write answer and it's different from the answer included in the problem statement...
when i got pretest passed, The jury's answer became the same as the problem statement !
ops !
Yeah.The issue is addressed by KAN
Yes, i checked the comments above. thanks!
H can be solved in O((27 + log(N)) * 7 * N + Q * log(N)), where 7 is just the max number of distinct prime factors of a number in the given range, right? 7 seconds seems like a huge time limit for that.
You can do preprocessing in O(n·7·27) and then answer queries in O(7).
The preprocessing should give you all the information about answers for all intervals. So, for every left end L of an interval, and every possible answer a (0 ≤ a ≤ 14), find minimum possible R such that [L, R] has answer a. Then you don't need trees or binary searches.
Yeah, this is way better than what In had in mind. I was thinking about iterating over L in reverse and updating answer for <= 14 suffixes using lazy propagation, which is really silly.
To my surprise, this solution for B passed system test!
How weak test data!
How is it weak? Maximum is 1129, and your least sum is 1200
My solution for B was very complicated. Probably this is the distance from masters and me.
It is right!
The test data is not weak. It's just your solution that is correct :-)
I don't think it's strange.
the problem itself is weak, not the test data
Wow never expected my solution to be posted by others for whatever reason
It is my honor
How to solve E? Is there any theory to it?
It's more of a joke rather than an actual problem xD. Basic idea is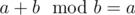 if 0 ≤ a < b, so with a little bit of care we can make work something like ai = ai + 1 + bi for most values of i.
if 0 ≤ a < b, so with a little bit of care we can make work something like ai = ai + 1 + bi for most values of i.
Why do you think that it's a bad problem? Isn't the solution required clever observation?
I do not necessarily claim it is a bad problem. What I tried to say is that once somebody starts dealing with this problem, based on general impression and its points value, he thinks it should be some complicated number theory, but it turns out it is just naive construction based on simple trick. I definitely felt trolled hard when I came up with the actual solution.
If they're all equal, then it's impossible (unless they are all 0, in which case a constant sequence works).
Otherwise, find some i where b[i]>b[i-1]. Set a[i]=b[i], and then work backwards — set a[j]=b[j]+ka[j+1], for the smallest k that makes this expression bigger than b[j-1]. Make sure you're careful with the wraparound, and that's all.
What is the thought process to reach this solution? I find that there are some problems where the solution seems so simple but before I see it I feel stuck in a fog.
One idea that might be helpful to get this solution (it was for us): if not all the numbers were equal initially, then at least one of them didn't change (e.g minimal number)
If we start from the maximum value, we can set k=2 first time and k=1 everywhere else
What do you mean here? Can you please elaborate?
I mean the solution from the editorial.
Thx!
So I have to ask: are all strange input numbers just an elaborate setup for M bounds in problem G?
zeliboba answered here that yes.
How to solve F?
Let
Obe the origin. For each queryA(x,y)we want to calculate a) number of points which lie on lineOAand b) number of pair of points which are symmetrical with respect toOA. The first one is easy. To calculate the second, two pointsBandCare symmetrical toOAiffOB = OCandAB = AC. If the first condition is already satisfied, letDbe the (unique) point such thatOBDCis a rhombus, thenAB = ACiffO, A, Dis collinear.After that we only care about pairs of points that have the same distance to
O. For each pair, we add the correspondingD, then for each queryAwe want to know the number of pointsDwhich lie onOA(which is easy). The whole problem can solved just by bruting those points, as the number of integer solutions forx*x + y*y = ris not that large (based on some results which I didn't remember).Some useful link:
Integral points on a circle
Pi hiding in prime regularities
In summary, if the prime factorization of r is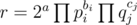 with
with 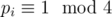 and
and 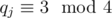 , then the number of positive integer point with distance
, then the number of positive integer point with distance 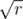 to the origin is
to the origin is 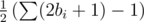 .
.
I don't know what is the worst case with the given constraint (r ≤ 2 * 1129042 ≈ 2.6 * 1010, but as you said, it won't be large.
I think this becomes clearer if you think about it in terms of Gaussian integers rather than Pythagorean triples. If you use that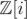 is a UFD, has a multiplicative norm N(x + iy) = x2 + y2, and the classification of Gaussian primes, you should find that the number of arbitrary integer solutions to x2 + y2 = r (r ≠ 0) is either 0 or
is a UFD, has a multiplicative norm N(x + iy) = x2 + y2, and the classification of Gaussian primes, you should find that the number of arbitrary integer solutions to x2 + y2 = r (r ≠ 0) is either 0 or 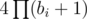 , where bi are the exponents in r of primes of form 4k + 1. (Here 4 is the number of units, i.e. 1, i, - 1, - i, and bi + 1 comes from the fact that there are two Gaussian primes with norm pi, and you need their exponents in x + iy to add up to bi, so there are bi + 1 choices.)
, where bi are the exponents in r of primes of form 4k + 1. (Here 4 is the number of units, i.e. 1, i, - 1, - i, and bi + 1 comes from the fact that there are two Gaussian primes with norm pi, and you need their exponents in x + iy to add up to bi, so there are bi + 1 choices.)
The formula with the sum seems weird to me, since it doesn't always give integer values, and even for r = 5 it gives 1 instead of 2.
Does anyone know what D's fourth sets of data are?
Anybody knows what the 14th test in A can be? It seems tat a lot of sources failed there...
Input:
1 89Answer:
1 45I wrote
ninstead ofmat one point =(Can someone explain to me why this submission fits TL in 982ms but this submission don't (>2000ms)
They look same for me.
And with same compilers.
maybe slow io speed
Maybe one of: optimization pragmas, fast reading, fluctuation, cool 9-wheel fidget spinner drawn as a comment.
I ran dkirienko's solution 4 times and here're the results:
42183675 — GNU C++14, without IO speed-up: 1715 ms;
42183758 — GNU C++17, without IO speed-up: 1731 ms;
42183820 — GNU C++14, with IO speed-up: 920 ms;
42183861 — GNU C++17, with IO speed-up: 950 ms.
By IO speed-up I mean these 2 lines:
Takeaways:
Always write these 2 lines when using std::cin.
GNU C++14 is faster than GNU C++17.
The amount of slow down for the same code seems to be very small, 16 msec and 30 msec for without and with IO speed up, respectively. However, if a new C++17 feature is used, then the performance comparison is simply unfeasible.
The slowdown of 16ms and 30ms is for GNU C++14 vs. GNU C++17.
The difference between solutions with and without IO speed-up is almost 2X.
Yes, that's right. But, I am not sure if this 2X slow down factor will be the same for another code or not, even though the absolute maximum difference did not exceed 30msec.
On the other hand, some of the GNU C++17 new language features that were mentioned in that blog few months ago may be worth using in competitive programming, provided that the slow down is tolerable if it exists persistently.
My solution for D, is giving TLE on pretest 4
It seems to me that it is QlogQ. Can anyone check? I've inserted/erased each element O(1) times in a set
On problem C, after implementing rocket science for an hour, realised that solution is just one those four points: let x1, x2, and y1, y2 be the maximum two values of left x-coordinates and bottom y-coordinates of rectangles. Just checking these four combinations suffice.
sad reacts only :(
Codeforces should provide facility to react on comments
Wait a minute, for problem D:
"At every moment of time, every SELL offer has higher price than every BUY offer."
Does that count for BUY and SELL offer that is accepted (removed from the order book)?
No, only for alive offers.
No, see sample test 1 for example.
sadly, I find that 2014CAIS01 's solution to problem C 42167254 and D 42181490 is very similar to applese 's solution. C: 42162949 D: 42177578 . only template changes. C and D in this round is not easy to be such same. Please check it. @ zeliboba
I agree.
Write a blog, it will gain more exposure.
sadly, when I come to see http://codeforce[user:cubercsl]s.com/blog/entry/8790 to check the detail, I find such a user cubercsl and his comment http://mirror.codeforces.com/blog/entry/8790#comment-452899 Both cubercsl and user 2014CAIS01 are using same picture as head portrait. So I think they are exactly one person and cheat in 2 nearly rounds.. skip him please. zeliboba
write a blog please
Oh no, he is rated... why?? Where is the administrator? MikeMirzayanov ??? KAN ????
last prize wowoowoooowow
i don't know if i do it intentionally or not :p
At least I haven't taken 72 place. (my place is 73) :(
Look at some sexy numbers ;p
Err calm down Satan, you're too much involved with the mortal realm :D
flibia is also 6 letter word...hmmmmmmmmmmm...........
But now I see you are 72 place exactly :p, and muratt is not the last prize.
In prob D, what is answer for this test:
2
I'm really surprised my C solution passed 42175706
Hey guys, looks like the C checker mistakenly rejected my solution (42172602) with a weird error:
The answer
6053 7212seems to be correct, see 42163884 for example.I think that line of output might be the judge's answer?
Oh damn...indeed, thanks, sorry for that
You didn't output anything.
Regarding Problem C, I searched the net for answer for the problem, "Intersection of N axis aligned rectangles", and all I found was stuff on BSTs and KD Trees. But it was easily done using 4 multisets, 2 for lower x vertices and lower y vertices, sorted in descending order, and 2 for higher x and y vertices, sorted in ascending order. After making all multisets, the intersection can simply be given by top element of all multisets. Is this implementation different than the ones using KD tree structure, or the same as multisets are also basically Red Black trees?
Intersections of rectangles with coordinates((x1,y1),(x2,y2)) is rectangle ((max(x1),min(x2)),(max(y1), min(y2))). So you just need to calculate prefix and suffix mimimums/maximums for this problem.
I was wondering if maximum intersection area of n-1 rectangles from given n rectangles could also be done by the same method. I think it would be max area after removing any of the rectangle which have a max(x1) or a max(y1) or a min(x2) or a min(y2), right?
You just need to calculate prefix and suffix mimimums/maximums for this problem and you can easily try to remove every rectangle. Because we can compute the intersection of first x and last n-x-1 rectangles.
What are prefix and suffix mimimums/maximums?
I got TLE in C by using cin/cout instead of scanf/printf :ccc
ios::sync_with_stdio(false);is your friend.ios::sync_with_stdio(false); cin.tie(nullptr); cout.tie(nullptr);
add these code and don't use scanf/printf/getchar/putchar/puts, if you want to use cin/cout and also want them as fast as possible.
Add #define endl '\n'too
Мне кажется, или сегодняшняя задача 1028C - Прямоугольники очень похожа на задачу 1029C - Максимальное пересечение с прошлого раунда?
В любом случае, мне знание решения задачи с прошлого раунда помогло решить задачу с текущего.
any suggestion on how to improve coding skills please??
Upsolve previous codeforces contests, not kidding, thats how I improved my coding skills. The first three questions of any Div 2 contest must be done, either by self, or by learning from the editorial after you've given up. The first three problems for a number of previous cf contests, and your skills will improve greatly.
and how did you cope up with the new algo learnt??
its too tough to implement on harder problems
I know some problems can be hard to implement even after studying the editorial or the solution code. But the first three problems of Div 2 contest are doable. And the community is here to help you out if you dont understand. And regarding coping up with the new algo learnt, that just comes after practice. You dont need to cram the new concept, just try implementing it yourself after studying the algo, and look for problems on similar concept, and thats it, now that concept is engrained in your brain. For instance those who had solved Problem C of #506 were easily able to solve today's problem C. So you would automatically realize problems with similar algo if you had solved a similar problem before. So keep practicing and Best of luck :)
Personal experience: I did like, hardcore coding all the time, killing off every problem I could from the Codeforces problemset (even the easiest ones).
Of course, just solving problem is not enough — still it helps a lot in making your typing speed and typing instincts increase, and also make yourself familiar with some methods, styles, and also avoid some kind of bugs you might frequently jump into before.
Along with solving problems, I read other books as well. For international's sake, I'll recommend two competitive programming books only: one from NUS' Halim, and one from CSES (Finland)'s Antti Laaksonen. I do read a lot from a local algorithm wiki as well (it is quite helpful for me, yet it's in Vietnamese only, so I can't recommend that one :D ).
Congratulations to all the winners! As mentioned in the post, each of the top 25 contestants will receive $100, and the following 46 contestants will receive $50. The prizes will be delivered using Amazon gift cards or Bitcoin. I'll contact each of the top 71 contestants through Codeforces to coordinate the prizes delivery.
The prizes in this round are in memory of Leopoldo Taravilse (ltaravilse).
http://mirror.codeforces.com/blog/entry/60157
https://www.gofundme.com/in-memory-of-leopoldo-taravilse
wow i have 211 rating now
I have a small piece of advice to those using set/multiset in C++.
When looking at submissions to the problem C today and in previous div. 3 round I noticed that the following pattern happens quite often:
Instead of writing this code, you can use a reverse iterator. In short, there's an iterator which points to the last element of the set (i.e. the biggest one):
Nice, didn't know that. But I can share another tip — prev and next functions. We can access last element through
but usages of these functions extend of course to more than this. I used them in D, where I needed to take previous and next element in set.
Of course, not if it needs to be compared with a forward iterator. Then you can still shorten the notation to
*(--end(my_set)).Can someone explain the solution of Problem G?
Let f(q, l) be the largest value h such that if you know the answer is in [l, h) then it can be guessed within q queries. If q=0 then h=l. Otherwise, we can use k=min(l, 10000) in the first guess a_1, a_2, ..., a_k. We need a_1 <= f(q-1, l), then a_2 <= f(q-1, a_1 + 1) and so on. To get h as high as possible, we should of course make these equalities. Finally, h = f(q-1, a_k + 1). Some optimisations are needed to allow f(5, 1) to be evaluated quickly (hint: if l >= 10000 then it is just 10001-ary search, and q = 1 has a simple closed form), but you end up with f(5, 1) being exactly M+1.
You can use basically the same procedure as above to actually construct each guess.
Just out of curiosity, why were all the constraints on this contests not round numbers ? :)
When the Editorial will be published?
Can someone provide an editorial?
Here's my short version:
A: Run through rows from the top until you find one with at least one 'B'. Do the same for the bottom. Average the two row numbers to get the middle row. Now find the last and last 'B' in that row, average them to the get the middle column.
B: There are lots of constructions that will work. I used a=999...999, b=999...999000...001 so that a+b is a power of 10.
C: I had an overly complicated solution, but as many others have pointed out, all you need to is incrementally compute the intersection of the first i rectangles (for every i) and the last i rectangles (for every i), and then you can combine a prefix and suffix to get the intersection of all but the ith rectangle for any i. As soon as you find such an intersection that isn't empty, output a corner of it.
D: Keep track of a lower bound for the best sell and an upper bound for the best buy. If an ACCEPT is for more than the best sell or less than the best buy, it's a contradiction. If it's for a value between the bounds, multiply by 2 because it could be either. After an ACCEPT, the price above it is the new best sell and the price below it the new best buy. If you get to the end and there are G prices which could be buy or sell, multiply by G+1.
E: This one has been discussed quite a lot in previous comments so I'll skip it.
F: The trick is to notice that two points can only be mirror images if they have the same distance from the origin, and for any given distance there aren't very many points at that distance. So we keep the points bucketed by distance. Also keep track for each possible line (identified by the ratio x:y in lowest form) of how many points don't need to be duplicated. That's going to be 1 for each point on the line, and 2 for each pair of points symmetric about the line. Adding or removing a point takes time proportional to the size of the bucket.
G: See http://mirror.codeforces.com/blog/entry/61450?#comment-454479
H: Firstly, we can divided out all squares from the a_i, since they make no different. Thus, each a_i is then a product of unique primes. If we want to transform a_i and a_j so that their product becomes a square, the cost is the number of primes that appear in one but not the other. Each a_i can have at most 7 primes (2*3*5*7*11*13*17*19 is too big), so at most 128 factors. Sweeping left to right, keep track of dp[f][k], the rightmost a_i so far that can be expressed as f times exactly k other primes. To add a new a_i, consider each factor f it has and the number d of primes in a_i/f; then consider pairing it with dp[f][k] for each k to get a potential solution. That's probably not that clear, but see my solution (http://mirror.codeforces.com/contest/1028/submission/42197383) for more.
Thank you!
Hey bmerry , I am unable to understand your H, please help me and elaborate more... especially this line , " the rightmost a_i so far that can be expressed as f times exactly k other primes"
I think it's exactly the same DP array as in the official editorial. Does that help?
Editorial also did not explained that thing in detail. Please explain just that one thing... What does states of dp denotes..
Let's say the array values we've processed so far are 3, 42, 210, 70, 100, 14. What is dp[7][2]? It is the rightmost position which contains 7 times 2 other primes. 42=7*2*3, 70=7*2*5 are the candidates, and 70 is the rightmost, so dp[7][2] is the position of the 70. 210=7*2*3*5 and 14=7*2 are not candidates because they have the wrong number of primes, and 3 and 100 are not candidates because they're not divisible by 7.
Thanks man for precious time. Got that.. People like you keeps coding alive.. Thank you very much.
any editorials is there ??
http://mirror.codeforces.com/blog/entry/61493
Why did you change points for the round? (it was + 121 became + 120) ( Sorry for my english, I just was not in England)
Maybe because of some cheat issues?
I mean,two persons’ solutions are very similar.So they unrated.The”rating changes ”changes.
Huh, but why then so quickly issue a rating?
Same thing happened to me. Checking for cheaters is usually done before the rating change is issued, so I don't think that's the reason. It would be nice if the administrators told us if the copying system is failing, or if it was updated in some way. At least let us know if we should expect more random rating drops.
Yes, I totally agree with you
hj
I think he just tried hard.
What's about prizes?
https://mirror.codeforces.com/blog/entry/61450?#comment-454399
ahmed_aly contacted all the winners.