


Here's the link: https://ranking.ioi18.net/Ranking.html
How excited is everyone?
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
Here's the link: https://ranking.ioi18.net/Ranking.html
How excited is everyone?







I am literally shivering with excitement!!
It's not loading anymore. Kinda expected more from Japan.
It's back up now!
Oh yeah it is. :) Still, they haven't released the tasks as promised lol.
Is it down again?
mine doesn't work
The rank doesn't work! Why?
It's working now
livestream & rank : http://live2.nicovideo.jp/watch/lv314346295
Are there public statements available?
yes,it is available. https://ioi2018.jp/competition/tasks/
What? In 30 minutes all problems all solved by Benq
No, he solved all problems in 4:14:25
Let's discuss problems. Who has any idea?
B: Consider conditions for some non-empty point subset to be a rectangle. Let points inside this subset be black, white otherwise. It turns out the condition is: (number of black points with white points on left and up sides + number of white points with at least two adjacent black points) = 1 (The latter ensures rectangles, the former ensures connecitivity). Also this value is always >= 1. Maintain this value for every prefix (sorted by number on points) point subset and count the number of minimum (if it's 1) using segment tree.
Why you don't in China IOI team?
Mainly grade. You need to be senior high school student to qualify in China. Anyway I'm not sure if I would qualify.
how suck the system is
So even fateice wasn't allowed to qualify because he is not in 12th grade?
No, he was unlucky :(
Oh, ok. So next year you and FizzyDavid will be allowed to participate?
Yes. Anyway there're selections.
all-mighty zzq
And zzq will do great next year.
No,I got 16th in a match which was used to select top 15 competitors.
Oh, ok. Next year dude!
It's a pity that I don't have the next year.
Oh damn it. Sad how competitors like you don't make it but others like babin do. :))
Qualifying to IOI (and ACM ICPC World Final) can be surprisingly easy or next to impossible, depend on where you were born.
Qualifying to top companies can be surprisingly easy or next to impossible, depend on where you were born.
Pretty sure qualifying to top companies doesn't depend on where you were born. When there are a lot of applicants from some country, there aren't any country-wide selections of a small number of people that will get interviewed.
Actually it's not about born in a better competitive programmer country but born in better country.
That's not a problem we can discuss in these comments anyway. Don't wanna be a bitch about it, but even at the visa phase you can fail because of that shit.
Well of course it's not about how many guys applied in a specific country.
Yeah, bureaucratic bullshit or some asshole on a power trip setting your life back is something that happens. I guarantee it's not only in your country.
At least unlike olympiads, you can always try again until it works.
That's not completely true. Read this maybe https://www.quora.com/Is-20-hours-of-competitive-programming-per-week-enough-to-get-to-IOI-Im-from-India-and-the-competition-here-isnt-as-serious-as-it-is-in-China-or-USA/answer/Pushkar-Mishra
wow, i'm Benq fan!!
choose the first character using 2 moves atmost. Now choose each pair of characters at a time. after the currently determined prefix, take AA and AB and BA after it. if delta_coins = 0 then next char is X, if delta_coins = 2 then determine using AA(handle the three cases). IF delta_coins is 1 then determine using BB(again handle the three cases.)So we do 2 operations to get a pair each time.
You can get first character using at most 2 moves :D
Yes i figured it out too :P
It's really excited. But Is It Rated?
Another fighter for the last on the contribution standings!
How to solve werewolf?
I had a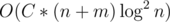 in time and
in time and 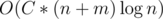 in memory (C is a small constant ~= 8) solution which unfortunately MLE on the last subtask (it was able to get the 34 p. one). The idea uses a couple of small to large tricks and DSUs but it's quite long (and it doesn't pass for 100), so I won't explain it here. Did you have some similar solutions or the idea is very different?
in memory (C is a small constant ~= 8) solution which unfortunately MLE on the last subtask (it was able to get the 34 p. one). The idea uses a couple of small to large tricks and DSUs but it's quite long (and it doesn't pass for 100), so I won't explain it here. Did you have some similar solutions or the idea is very different?
where do you submit ? can i have the mirror?
He was an official participant. There is no mirror that I am aware of.
Yandex has a Day 1 mirror.
Did you reduce to check if two subarrays of two permutations have common element? If so, a simple Mo's algorithm with a tricky technique may pass.
Note: There's no mirror so I couldn't test this.
If a and b are the permutations, then checking if al, ..., ar and bL, ..., bR share an element is equivalent to having points (i, b - 1(ai)) for i = 1... n (where b - 1(ai) is the index of ai in b) and checking if there is point in the rectangle [l, r] × [L, R]. Counting the number of such points can be done offline with sweepline + fenwick tree in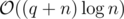 time and
time and 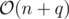 memory.
memory.
I got AC with this in analysis session.
Can you explain the reduction in more detail?
I assume you mean "check if two subtrees share a node" on the DFS order of each tree. We can just do DSU on tree on the first tree, keeping a set S that holds the positions of all children in the DFS order of the second tree. Checking if subtree u1 intersects with subtree v2 is now equivalent to checking if there's an element in u1's set in the range that represents v2's subtree in the DFS order, which is a simple
lower_boundquery.Mine is of similar complexity (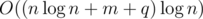 time,
time, 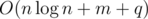 memory if I remember correctly)
memory if I remember correctly)
can you share your code..
My solution that passed actually uses 2 DSUs with 2 small-to-large.
My dear friend, GFY
I don't know if my solution is correct but what i do is compute the smallest i can go for each Si with one DSU in offline fashion for all queries (ordered by L decreasing). Then I process the queries (ordered by R increasing) and use another DSU to check if that smallest node is reachable from each Ei. This is a total complexity of O(QlogQ + Nα(N)) runtime and O(N + Q) memory.
I may have understood you wrong, but I think the meeting point shouldn't necessarily be the smallest / largest valued node reachable from Si, because some other nodes unreachable from Ei may be blocking it off.
I think you are right
Second place the georgia!!! georgia for the win! georgia will got first place in one year, and in two years too.
where I can see the problems?
How to solve A?
Determine the first letter with 2 queries ( First query two letters like AX, so you can discard two letters, and then query just one ) Then, for every letter from 2 to N-1 do the following ( Assume the first letter of S is ‘A’. For the other cases its the same process but different letters )
Let s be the prefix of S that you already know.
Ask s + ‘B’ + s + ‘XB’ + s + ‘XX’ + s + ‘XY’
If the next character is ‘B’, then the query returns | s | + 1. If it is ‘X’ then | s | + 2 is returned. If it is ‘Y’, then | s | is returned. Then just get the last letter with two queries similarlly to the first letter
This works in N+2 queries and it is enough to get 100 points
Sorry , misunderstanding was my bed.
'C' isn't an allowed character in the input -_-
I actually have another solution very similar to Diegogrc's.
Similarly to his solution, define s and the prefix of S we know so far, and assume A is the first character in the string. Also, the first letter can be obtain in two queries as described in that solution.
We will look at two consecutive indices at a time, appending onto s. In order to maintain 2 queries per 2 indices, we will split the cases into two groups as follows:
Group 1: sXB, sXX, sYY Group 2: sYB, sYX, sXY
First, append all elements of Group 1 together to make sXBsXXsYY. If we query and get |s| as the return value, we know that neither X or Y can be appended to s, therefore we know that B must come after s. In this case, we just move on to the next index. The cost for this case is 1 query per 1 index.
On the other hand, if we have |s| + 2 as the return value, then we query for the string sXX. If we get |s|, then YY must be appended to s. If we get |s| + 1, then XB must be appended to s. If we get |s| + 2, then XX must be appended to s. We can then jump two indices to the right. Notice that we only used two queries per two indices for this case (one to determine that there is an answer within this group, and one to determine which of the ones in this group is the right answer).
The other case is when we have |s| + 1 initially. We know that the first letter after s must be either X or Y, but the second letter after s makes the answer not within the first group. Therefore, our answer is contained in the second group. We use a similar method of determining the correct answer in the second group as in the previous case (|s| + 2). We also spend two queries per two indices.
Since we spend two queries every two indices (or one query every index, as in the first case we described) and risk overshooting N-1 by one, the worst case number of queries is N. We also need 2 queries for finding the first element. Therefore, the solution runs in N+2 queries.
For A, couldn't you just build the known prefix by trying out all characters from {A, B, X, Y} for the next unknown position? The score if it matches will be 1 + length of known prefix. Number of queries will be 4n, which since n = 2000 and max queries is 8000 will just fit.
You need to find a solution with <= n + 2 queries to get 100 points
In hindsight, I should have realized such a simple solution would never have been expected at the IOI.
IOI 2018 day 2 live streaming
The scoreboard is updated with day 2 tasks!
What wonderful news! I am literally quivering with anticipation!
How much participants will have a medal ?
A 12th gets gold, a 6th gets silver, a 4th gets bronze. So I think there are 340 participants so about 28 gold, 56 silver, and 85 bronze, as Fayaz pointed out
thanks very much for your answer I_love_sqrtdecompton
That would be 28 gold, 56 silver and 85 bronze right?
Can somebody make a graph "CF rating vs IOI score"? And the same graph for only blue+, violet+, orange+.
How to solve meeting and highway?
If N+1 is a power of 2 we can create a full binary tree with (N+1)/2 leaves such that each leaf is connected to the triggers with the corresponding values (we assume that A[N+1] = 0) and each switch is connected to the root of the tree.
When N+1 is not a perfect power of two, we will build the same tree but for that size and then cut some subtrees of sizes equal to the powers of 2 not present in the binary representation of N+1.
First we find length of the smallest path between S and T when you set all edges light. Call it D.
Let B(a) be permutation of vertices that are sorted by the shortest distance to a. And let F(X[]) be the first vertex v in X such that if we set all edges that connect vertices that come before v in the array light, then the shortest distance between S and T will be D. This is equivalent to finding first v such that there exists shortest path from S to T that only passes through vertices that come before v in X.
Let V = F({0, 1, 2, ..., N - 1}). V will be on the shortest path from S to T. Then we can prove that answer is
S = F(B(V))
T = F(B(S)).
We can find F(X) using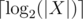 queries with binary search. So the solution uses
queries with binary search. So the solution uses 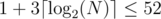 queries.
queries.
In your solution, when finding V, we can consider edges instead of vertices. Let e0 be the first edge such that setting 0, ..., e0 to light results in distance D. Then e0 is on some shortest path from S to T. We can find e0 in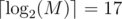 queries. This still needs 52 queries in total.
queries. This still needs 52 queries in total.
We can improve this by grouping the edges in pairs that share a vertex, as we then don't need to distinguish edges in the same pair, as we can just use the vertex they share as V. The pairing can be found as a matching on the line graph (in linear time with dfs, one edge might not be matched). This reduces the first step to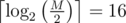 queries, so 51 queries in total.
queries, so 51 queries in total.
I might have squeezed this solution to 50 queries on Yandex with some randomization and pruning, but I'm not sure as the scoring is broken.
Actually we can reduce this to 50 queries using the fact tha T will be before S in B(V) so in the last step we search T only between vertices that are before S in B(V). When finding S in the first step of binary search instead of dividing the array in half, we divide it into two segments [1, 216] and [216 + 1, N]. if the answer is in left segment then we can find S in 17 queries in total, but we can find T in 16 queries because we know it is in first 216 vertices. And if the answer is in right segment then we can find S in only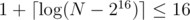 queries.
queries.
I described my solution to meeting point on the day 2 blog. If someone has a simpler solution, I'd love to hear it.
Can you share your code ?
congratulations Benq for winning IOI 2018!