


Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
int main(){
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int n;
cin >> n;
int mn = 1e9, mx = 0;
for (int i = 1; i <= n; i++){
int x;
cin >> x;
mn = min(mn, x);
mx = max(mx, x);
}
cout << max(0, (mx-mn)-n+1);
}
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(){
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
ll a, b, c, d;
cin >> a >> b >> c >> d;
ll gc = __gcd(c, d);
c /= gc;
d /= gc;
cout << min(a/c, b/d);
}
Разбор
Tutorial is loading...
Решение
#include <bits/stdc++.h>
using namespace std;
const int N = 200100;
set<pair<int, int> > q;
int ans[N], n, a[N], m, k;
int main(){
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> n >> m >> k;
for (int i = 1; i <= n; i++){
cin >> a[i];
q.insert({a[i], i});
}
int cnt = 0;
while(!q.empty()){
++cnt;
int pos = q.begin()->second;
ans[pos] = cnt;
q.erase(q.begin());
while(true){
auto it = q.lower_bound({a[pos]+1+k, 0});
if (it == q.end())
break;
pos = it->second;
q.erase(it);
ans[pos] = cnt;
}
}
cout << cnt << "\n";
for (int i = 1; i <= n; i++)
cout << ans[i] << ' ';
}
Разбор
Tutorial is loading...
Решение
#include<bits/stdc++.h>
using namespace std;
#define fore(i, l, r) for(int i = int(l); i < int(r); i++)
#define x first
#define y second
typedef long long li;
typedef long double ld;
typedef pair<int, int> pt;
const int INF = int(1e9);
const li INF64 = li(1e18);
const ld EPS = 1e-9;
const int N = 200 * 1000 + 555;
int n, h;
pt a[N];
inline bool read() {
if(!(cin >> n >> h))
return false;
fore(i, 0, n)
assert(scanf("%d%d", &a[i].x, &a[i].y) == 2);
sort(a, a + n);
return true;
}
int ps[N];
int getH(int lf, int rg) {
int l = int(lower_bound(a, a + n, pt(lf, -1)) - a);
int r = int(lower_bound(a, a + n, pt(rg, -1)) - a);
int sum = ps[r] - ps[l];
if(l > 0)
sum += max(0, a[l - 1].y - lf);
assert(rg - lf - sum >= 0);
return rg - lf - sum;
}
inline void solve() {
ps[0] = 0;
fore(i, 0, n)
ps[i + 1] = ps[i] + (a[i].y - a[i].x);
int ans = 0;
fore(i, 0, n) {
int lx = a[i].y + 1;
int lf = -(h + 1), rg = lx;
while(rg - lf > 1) {
int mid = (lf + rg) / 2;
if(getH(mid, lx) > h)
lf = mid;
else
rg = mid;
}
assert(getH(rg, lx) == h);
ans = max(ans, lx - rg);
}
cout << ans << endl;
}
int main() {
if(read()) {
solve();
}
return 0;
}
Разбор
Tutorial is loading...
Решение
#include<bits/stdc++.h>
using namespace std;
const int N = 200043;
int cnt[N];
int main()
{
int n;
scanf("%d", &n);
for(int i = 0; i < n - 1; i++)
{
int x, y;
scanf("%d %d", &x, &y);
if(y != n)
{
puts("NO");
return 0;
}
cnt[x]++;
}
int cur = 0;
for(int i = 1; i < n; i++)
{
cur += cnt[i];
if(cur > i)
{
puts("NO");
return 0;
}
}
int last = -1;
puts("YES");
set<int> unused;
for(int i = 1; i < n; i++)
unused.insert(i);
for(int i = 1; i < n; i++)
{
if(cnt[i] > 0)
{
unused.erase(i);
if(last != -1)
printf("%d %d\n", last, i);
last = i;
cnt[i]--;
}
while(cnt[i] > 0)
{
printf("%d %d\n", last, *unused.begin());
last = *unused.begin();
cnt[i]--;
unused.erase(unused.begin());
}
}
printf("%d %d\n", last, n);
}
Разбор
Tutorial is loading...
Решение
#include<bits/stdc++.h>
using namespace std;
#define fore(i, l, r) for(int i = int(l); i < int(r); i++)
#define sz(a) int((a).size())
#define all(a) (a).begin(), (a).end()
typedef long long li;
typedef long double ld;
typedef pair<int, int> pt;
const int INF = int(1e9);
const li INF64 = li(1e18);
const ld EPS = 1e-9;
const int N = 100 * 1000 + 555;
int n[2], y[2];
int x[2][N];
inline bool read() {
fore(k, 0, 2) {
if(!(cin >> n[k] >> y[k]))
return false;
fore(i, 0, n[k])
assert(scanf("%d", &x[k][i]) == 1);
}
return true;
}
inline void solve() {
int ans = 2;
for(int dx = 1; dx < int(1e9); dx *= 2) {
int mod = 2 * dx;
map<int, int> cnt;
int add[2] = {0, dx};
fore(k, 0, 2) {
fore(i, 0, n[k])
cnt[(x[k][i] + add[k]) & (mod - 1)]++;
}
for(auto curAns : cnt)
ans = max(ans, curAns.second);
}
cout << ans << endl;
}
int main() {
if(read()) {
solve();
}
return 0;
}






quickest editorial posted ever! well done!
Thank you for giving editorials that fast ...contest was really good ..hope this will continue in future
The hack test of "1041F Ray in the tube" is: 1 0 1 1 0 1
The right answer is 2, but you may print 1.
Shouldn't y1 be smaller than y2?
Take this case
1 1
1
1 2
1
The main corner case is including points with same x coordinate on the same ray
thanks Roms for the editoriel
Kudos to the organizers for posting the editorial so quickly
thanks you :>
The tutorial of C seems like a greedy algorithm. I'm wondering how to prove it and need help. During the contest, I'm unsure and I wrote a binary search algorithm with complexity of O(n(logn)^2).
I'm not sure, but maybe it goes something like this. Let a be the element you've just picked. Now, for any element greater than a+k, the smallest(a1) is the optimum via greedy. Let's assume it's not and let a2 be the element we pick. Now, the sequence of elements which you pick after a2 will also be valid if you had picked a1 initially. However, picking a1 might have let you take more elements which you might not have been able to take had you picked a2, which potentially reduces the number of days and thus may give a better answer.
What's your binary search solution?
Thanks, but there're some confusions. When considering using more coffee breaks in one day, choosing a1 is of course better than a2 because we have more potential elements. But how can this way make the number of days least?
As for my own solution, I guess an answer in range of [1,n] and make checks. When checking I used priority_queue to remember the best choice among these days. While picking a new element, if difference of the element and the top of the queue is not more than d, the answer is too small.
This is my code-> http://mirror.codeforces.com/contest/1041/submission/42932521
Oh, I am silly to use priority_queue… It's easier to memorize the best choice… Maybe my solution is same as Adibov's.
I don't think greedy works for C. The following input:
is possible in two days (1 6 on first day, 5 9 on second day). Greedy will give 1 5 on first day, 6 on second day, 9 on third day. Unless I misunderstood something, which is not improbable :-)
Greedy will give 1,5,9 on the first day and 6 on the second day. So while your partition works, so does the greedy solution's.
great work ! fast editorials do help!
Thanks guys for the quick editorial post!
In F, I don't understand why choose dx is power of 2, not power of 3 or power of 100? And how to prove that choose power of 2 is optimal?
If you choose dx as power of 3 or 4 or 100, you will find some situations cannot be represented. Assume d=m*dx^l, sometimes using dx cannot hit all points using d.
I think we can always represent in base 3, example: 5 = 5 * 3^0. Hmm, maybe I need a prove why we choose power of 2
Suppose that the ray is emitted from the point Ax, and d is a positive number that can be divided by some prime p such that p ≠ 2. Then if we choose dx = d, we will visit Ax + d, Ax + 3d, Ax + 5d... on the opposite side of the tube and Ax, Ax + 2d, Ax + 4d... on the same side of the tube where we started the ray.
Then let's choose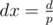 . On the opposite side of the tube, the ray will pass through
. On the opposite side of the tube, the ray will pass through 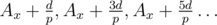 , and since p is odd, then Ax + d, Ax + 3d, Ax + 5d... is a subsequence of this sequence! The same applies for the positions we visit on ''our'' side of the tube.
, and since p is odd, then Ax + d, Ax + 3d, Ax + 5d... is a subsequence of this sequence! The same applies for the positions we visit on ''our'' side of the tube.
So, if dx is divisible by some odd prime p, then dividing it by p doesn't make the answer less, and we can eliminate all odd prime divisors of dx one-by-one.
Very clear, I understand. Thank you so much!
Why the problem E's constraints too small. It just confusing.
It's confusing for me too. E's complexity is a mere O(N), which should have gotten N <= 10 ^ 5 or something. I even thought my algorithm was wrong (didn't have any proof of correctness), but the tutorial did exactly what I did.
In fact, my solution for this problem (which is in the editorial) is , but I've decided to give n ≤ 1000 for one reason: as for me, the core of this problem is the idea how we check if the tree can be reconstructed and how we actually reconstruct it. Changing the constraints to n ≤ 2·105 doesn't add anything to the idea of the problem. Yes, it changes the implementation, but I personally don't like to enforce some implementation-wise constraints on problems with constructive algorithms, if they don't enforce a solution with completely different idea.
, but I've decided to give n ≤ 1000 for one reason: as for me, the core of this problem is the idea how we check if the tree can be reconstructed and how we actually reconstruct it. Changing the constraints to n ≤ 2·105 doesn't add anything to the idea of the problem. Yes, it changes the implementation, but I personally don't like to enforce some implementation-wise constraints on problems with constructive algorithms, if they don't enforce a solution with completely different idea.
Perhaps it's also because it's more convenient to implement an O(n2) algorithm than an O(n) one when checking whether an answer is valid.
Well I mean for people like me who was only able to come up with an O(n) solution we look at the limit and will start thinking that our algorithm is wrong, while in fact, it is correct. And I feel the O(n) solution's implementation is pretty simple, I did about 50 lines of code only.
Same...
Actually I mean it's harder for problem setters to implement the checker in O(n) time than in O(n2).
Lol nah, for O(n) you just gotta use an array f[i] and get maximum from all its children. For O(n ^ 2) you gotta re — dfs into the subtree which is lotta work.
Emm you are right. I forgot we can fix the maximum to be the root and calculating 1 maximum value instead of 2. My original thoughts were too complicated.
Can anyone help me figure out why my solution is giving me TLE verdict. My approach is similar to that of editorial. Link to my solution http://mirror.codeforces.com/contest/1041/submission/42951879
You got the same problem as I, the lower_bound from standard "algorithm" library won't run in O(logN) time complexity with the set data structure (I guess it is O(n)?), so you should use the one from "set" library which is s.lower_bound(...);
Thanks. Got accepted.
Today I learned that using regular lower/upper_bound from "algorithm" library on a set is not as same as the one from "set" library, which took me a TLE in problem C.
Lol lower_bound upper_bound in the standard library can't access set elements directly as opposed to the set library's lower_bound. So their access takes actually O(n), which is pretty expensive.
Yeah but while i was coding i didn't know that :(. But why it is not an error when you call that kind of function on a set?
Well because it's still a valid call. The compiler isn't responsible for your poor life choices :)
:( such a life lesson.
Me, too. I think they should fix this problem. If the compiler smarter it will use set::lower_bound automatically.
I have a different approach for problem F, and also a different proof for the distance "2l" in the tutorial.
Let A and B be the set of points from the first and second lines respectively. Let's split A into 2 sets, Aodd — the set that contains odd points — and Aeven — the set that contains even points. Do the same for B.
So here are some observations:
From here we have 2 subproblems that are very similar to the initial problem:
We can solve these 2 recursively. Let's deal with the first one. We can safely, divide all the number from Aeven and Beven by 2. By doing so, we are now turned back to the initial problem, with new A is new Aeven and new B is new Beven. With the odd ones, first we subtract all the numbers by 1, and then divide them by 2. So, the problem is solved.
We can see that after dividing step, the distance between numbers is also divided by 2. That way, if we keep taking dx = 1, we are actually taking dx = 2, 22, ..., 2l where l is the recursion's level.
I implemented the solution with recursion, but I got MLE. So I do some tricks and optimized it with Trie. Sadly, I fail at test 79, where the first and second line contains the same number. :(
Cool solution!!!
I tried your approach and it worked even without optimizing memory. I think the issue in your case might have been less base-cases in the recursion.
Without memory optimization: 43012783
With memory optimization: 43012648
For memory optimization, I just free the arrays/vectors as soon as there is no further use of them.
Nice implementation!
I think you are absolutely right, I was bad at handling cases. Your implementation is very clean! And thank you for reading my comment! I thought I was alone here :)
Now I know std::set::lower_bound is much more faster than std::lower_bound(set).
the problem is NOT lower bound! the problem is erasing the first element of a vector! deleting the first value in a vector is in O(n) since all values need to be moved by one position your first solution is therefore in O(n^2)
I use set, not vector.
https://mirror.codeforces.com/contest/1041/submission/42956788 line 17: vector<pair<int, int>> A; line 25: A.erase(A.begin());
the std::lower_bound function on a vector is normally much faster than set.lower_bound... (and if you use std::lower_bound on a set its time complexity is also O(n^2) since a set has no random access)
I submit that question over 20 times. https://mirror.codeforces.com/contest/1041/submission/42934245 And this is one of those, which using set and std::low. And also this is in the contest, while 42956788 is not.
Initially, I use vector and get TLE on pretest 10. But when I change vector to set, it become TLE on pretest 9! So I keep using vector after that.
as i said in that submission you use std::lower_bound on a set. a set has NO random access! even the documentation tells you that the complexity of this is O(n^2)
but still std::lower_bound on a data structure with random access is much quicker than the set!
so in other words: you did not get TLE because std::lower_bound is to slow but because you used it on a data structure which does not fit the requirements!
Yes, what I mean is what you said. And I have fixed the first comment.
if you want to delete first element from
vector<int>, you can usedeque<int>instead.yeah but he is not only deleting the first element ^^
I have another solution for problem C: after sorting array consider the largest block that first element and last element of the block can't be in one day. We claim that answer is size of that block and if block start from L to R, we start writing 1 to R-L+1 from L to R and continue from each side. for example if n = 8 and L = 3 and R = 6, we make new array like this:
3 4 1 2 3 4 1 2
Oh I got this. No need for explanation. Pretty cool solution!
Thanks.
OKay leave it I understood now
Is it everyone constructed a path in problem E? It came to my mind, but I was all tried to find counter-case. I wasn't sure. Towards the end, I tried to construct the answer from the initial case which was star with vertex n in the center. Then appending path's to one another. Leaving all vertices i such that cnti = 1 as leaves. Didn't complete though.
I tried problem D using sliding window technique, the glider can jump from left of any block or till the right of any block, but got wrong answer on test 11. Please anyone can look into my code and point out the mistake. https://mirror.codeforces.com/contest/1041/submission/42958431
can someone please explain the runtime difference between this and this code? The only difference between them is that in one pair is of data type <long long, long long> and in other it's <int, int>.
problem is not due to
long longbut because you didn't includeif(cur > m) cur = 1, ans++;in your TLE'd code. I submiited your code after including that and got AC.My bad. thanks!
Can someone explain D. I'm not getting it. If sorting is done, the order of airflows change. Also shouldn't more priority be given for longest airflows?
You don't sort in problem D, instead take prefix sums which is increasing, so already sorted. Then do lowerbound on that prefix sum.
The problem E has a O(n) solution.Why the limit is n<=1000?Does this problem has a solution with O(n^2)?
The reason for n <= 1000 limit is given in this comment.
Thx.My bad.
Can anyone tell why i am getting runtime error: http://mirror.codeforces.com/contest/1041/submission/42953329
You are getting a TLE, not a runtime error. It is because std::lower_bound has complexity O(N) for containers that do not have random-access iterators. However, std::set::lower_bound has O(log(N)) complexity, which you can use. You can read more about them here and here.
How exactly can we do Problem D using two pointers ?
The first pointer is the place we choose to start flying,and the second pointer is the place we will reach the ground.It is obvious that it's better for us to start flying at the start of an ascending air flows.
Oh my English is so poor!
But we don't know where we will reach on the ground. Do we ?
So, how do we place the second pointer ? How to scan to get the job done ?
To be honest,I don't know how to tell you in English...
Got it !!! Many thanks ! That was really helpful.
In problem F I found test 51 has n = 12000 and m = 32000 and the answer is 24000, I thought the answer is at least 32000
I can choose the laser start at a side of the tube, and let it go straight.
The problem didn't said line AB cannot parallel with the side of tube.
Also , I may choose B out of tube
For example, if y1=0 and y2=1 I choose A(1,0) and B(2,2) and It would reflect at point (1.5,1) then return to (2,0)
In this way I can also get all the point with one single line.
My submission 43065546
In problm D, why answer to test 5 10 3 4 10 11 12 13 14 16 18 20 is 16? If he starts his flight at (3,10) th answer is 17.
If he will start at (3,10) then at X=18 H will be equal to 0, and he can't fly with H=0.
Understood, thanks
Quick Solution of Problem D using two pointers 43088242
can anyone help me identify what is wrong with my algorithm and what are the cases that i am missing
prob : 1041C — Coffee Break
https://mirror.codeforces.com/contest/1041/submission/43109819
At problem D, why is the complexity o(n*log(n)*log(10^9))? Isn't it essentially binary searching 10^9 numbers for every n? Shouldn't it just be n*log(10^9)?
Can someone please help what's issue with this submission, failing in case 9 Your text to link here...
i'm same as you. do you find out the bug?
my submission, failing in case 9
oh, i konw it. here is sample: