


Recently, I was asked to help flesh out a problem for the NAIPC 2019 contest whose problems are also used every year as the "Grand Prix of America." Although I didn't create or invent the problem, I helped write a solution and created some of the test data for Problem C, Cost Of Living.
From the problem setter's perspective, this was intended to be an easy, A-level problem: suppose you have a table of values ay, c that meet the condition that: 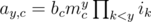 for some mc > 0.
for some mc > 0.
If you are given a subset of the values in this table, and a subset of the values for ik, determine whether a set of queried values ay', c' is uniquely determined or not. Note that a0, c = bc.
Most contestants immediately realized that above product can be written as a linear combination/sum by taking the logarithm on both sides:
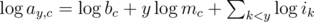
Each given value thus represents a linear equation in unknowns 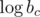 ,
, 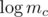 , and
, and 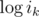 (plus some trivial equations for the subset of ik that may be given.) On the right hand side of the system appear the logarithms of the given table values. The left hand side of the system has only integer coefficients. Each row contains y + 1 1's and one coefficient with value y.
(plus some trivial equations for the subset of ik that may be given.) On the right hand side of the system appear the logarithms of the given table values. The left hand side of the system has only integer coefficients. Each row contains y + 1 1's and one coefficient with value y.
Each query, in turn, can also be written as a linear equation by introducing a variable 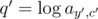 :
:
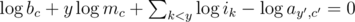
Now, all that is left is to solve for the query variables using a traditional method (Gaussian Elimination with partial pivoting) and report the results — or so we thought.
While top teams disposed of this problem quickly, there was a great deal of uncertainty among some contestants whether this approach would work. One team attempted to solve the problem with a homegrown variant of Gaussian elimination, but got WA because their answer was too far off the requested answer (the answer had to be given with 1e-4 rel tolerance in this problem).
When they downloaded the judge data generator scripts, they observed that the amount of error in their implementation changed when they printed the input data with higher precision, which was very confusing to them.
For this problem, the input data was not given with full precision because it involves products with up to 20 factors. For instance, if bc = mc = ik = 1.1 than a10, c = 6.72749994932560009201 (exactly) but the input data would be rounded to 6.7274999493. If they changed this and printed instead 6.72749994932561090621 (which is what is computed when double precision floating point is used), their solution would be much closer to the expected answer. Their result became even better when they used a floating point number type that uses more bits internally, such as quad-precision floats or java.math.BigDecimal. Thus, they concluded, they were doomed to begin with because the input data was "broken".
What could account for this phenomenon?
The answer lies in a property of numerical algorithm called stability. Stability means that an algorithm does not magnify errors (approximations) in the input data; instead, the error in the output is dampened and can be bounded by some factor. The illustration below shows a simplified example:
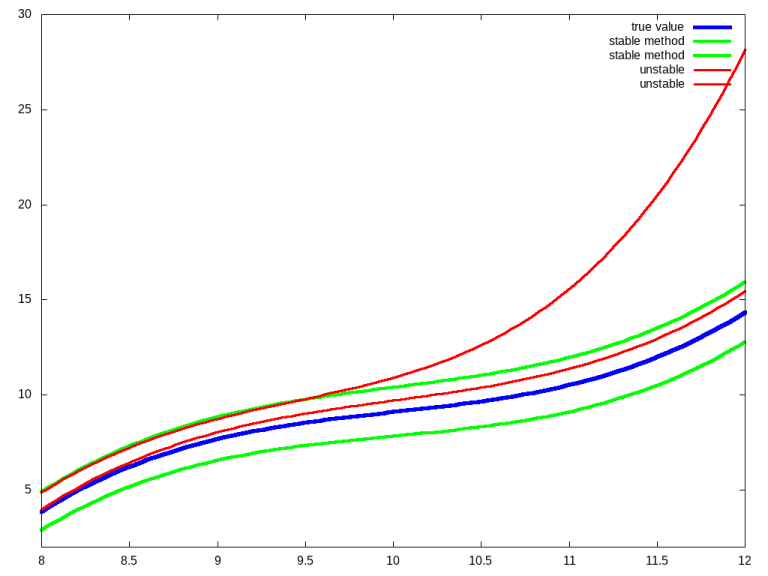
A stable algorithm will produce a bounded error even when starting with approximated input, whereas an unstable method will produce a small output error only for very small input errors.
The particular homegrown variant of Gaussian elimination they had attempted to implement avoided division on the left-hand side, keeping all coefficients in integers, which meant that the coefficients could grow large. On the right hand side, this led to an explosive growth in cancellation which increased the relative error in the input manifold — in some cases, so large that transformation back via exp produced values outside of what can be represented with double precision (i.e., positive infinity). It was particularly perplexing to them because they had used integers intentionally in an attempt to produce a better and more accurate solution.
Naturally, the question then arose: how could the problem setters be confident that the problem they posed could be solved with standard methods in a numerically stable fashion?
In the course of the discussion, several points of view came to light. Some contestants believed that there's a "95% percent chance" that Gaussian elimination is unstable for at least one problem input, some believed that the risk of instability had increased because the problem required a transform into the log domain and back, some believed that Gaussian problems shouldn't be posed if they involve more than 50 variables, and some contestants thought that Gaussian elimination with partial pivoting was a "randomly" chosen method.
In short, there was a great deal of fear and uncertainty, even among otherwise experienced contestants (based on the CF ratings).
Here are a few facts regarding Gaussian elimination with partial pivoting contestants should know:
Gaussian elimination (with partial pivoting) is almost always stable in practice, according to standard textbooks. For instance, Trefethen and Bau write:
(...) Gaussian elimination with partial pivoting is utterly stable in practice. (...) In fifty years of computing, no matrix problems that excite an explosive instability are known to have arisen under natural circumstances.
Another textbook, Golub and van Loan, writes: (...) the consensus is that serious element growth in Gaussian elimination with partial pivoting is extremely rare. The method can be used with confidence. (emphasis in the original text)The stability of Gaussian elimination depends solely on the elements in the coefficient matrix (it does not depends on any transformations performed on the right-hand side). Different bounds are known, a commonly cited bounds due to Wilkinson states that if Gaussian solves the system (A + E)y = b (which implies a bound on the backward error), then ||E||∞ ≤ 8n3G||A||∞u + O(u2) where ||E||∞ denotes the maximum absolute row sum norm. G is the growth factor, defined as the maximum value for the elements |ui, j| ≤ G arising in the upper-triangular matrix of the decomposition PA = LU induced by the algorithm. u is the machine precision, or machine round-off error (sometimes referred to as ε.)
Intuitively, this means that Gaussian is stable unless ||A||∞ is very large or serious growth occurs in the divisors used in the algorithm.
The growth factor G can be as large as 2n - 1, leading to potentially explosive instability. In fact, such matrices can be constructed (there's even a Matlab package for it, gfpp)However, it was not until ca. 1994 that matrices that arose in some actual problems were found for which Gaussian with partial pivoting was found to be unstable. See Foster 1994 and Wright 1994. Perhaps unsurprisingly, those matrices look (superficially at least) similar to the classic case pointed out by Wilkinson earlier: lower triangular matrices with negative coefficients below the diagonals.
What does this mean for programming contests?
First, your primary intuition should be that Gaussian elimination with partial pivoting will solve the problem, not that it won't.
Second, focus on what matters: the coefficients/structure of the matrix, not the values on the right-hand side.
Third, make sure you do use partial pivoting. There are numerous implementations out there in various teams' hackpacks. For instance, Stanford ICPC or e-maxx.ru.
Do not try to be clever and roll your own.
Overall, this graphic sums it up: when faced with a linear system of equations, you should








Auto comment: topic has been updated by godmar (previous revision, new revision, compare).
Auto comment: topic has been updated by godmar (previous revision, new revision, compare).
Thanks for the article! I was unaware of much of this and learned some new things from this problem. I'm glad you were one of the people handling this problem :)
I had a concern though. I believe the point about these worst-case matrices not appearing in practice, but I'm not entirely sure if this point applies to contest problems. In particular, test data can be generated in an artificial manner that could lead to some of these worst-case matrices. I don't think this concern necessarily applies to the NAIPC problem (since it seems the worst case matrices don't seem like they can arise in that problem), so I'm wondering in general.
In particular, I'm wondering if there are examples of previous contest problems that had test cases that were these worst-case matrices that are bad for partial pivoting. If so, then I think some of these fears and uncertainty are warranted, and I'm not sure how we would go about resolving these. As contestants, when would we start worrying about precision? As problem setters, when would it be safe to set a Gaussian elimination problem on doubles and be confident that some worst-case matrix can't be constructed?
As problem setters, when would it be safe to set a Gaussian elimination problem on doubles and be confident that some worst-case matrix can't be constructed?
There's an interaction here between problem solvers and setters as far as the growth factor component of the bound is concerned. The setter determines the variables (implicitly) and coefficients (explicitly), but they do not determine the column order (that depends on how the problem solver assigns variables to columns.) In this sense, the problem setter does not fully "construct" the coefficient matrix, just restricts its possible structure and values.
In the — so far, theoretical — case that a problem could lead to explosive growth in partial pivoting it might do so for one variable ordering chosen by a problem solver — but not for another. Certainly, there exists a variable ordering for which partial pivoting and complete pivoting leads to the same answer — using an oracle that sorts columns in the order complete pivoting would choose them. The observed growth factors for full pivoting are much lower, at some point they were believed to be as low as $$$n$$$ (though this was disproven in 1992 when matrices where found for which complete pivoting produces a growth factor slightly larger than n).
Also, note that I don't discuss the case where the matrix is ill-conditioned in the first place (if the condition number $$$\kappa(A) = ||A|| ||A^{-1}||$$$ is large, for instance, because $$$||A||_{\infty}$$$ is already large, or there are other reasons why the matrix could be close to being singular.) In those cases, no numerical algorithm will produce a good solution, and such problems would be clearly flawed to set. Those might be problems where the coefficient values themselves are part of a large possible input space from which the problem setter could choose (which was not true for our problem here.)
To answer the question more concretely, would it safe to say something like if the matrix can't be ill-conditioned from input bounds (i.e. from some criteria you've given), then it's fine to use or set problems with guassian elimination? This still leaves the open question about whether or not there can be some order that is bad, but I think it might not be necessary to rigorously address since it seems more of a theoretical exercise.
To answer the question more concretely, would it safe to say something like if the matrix can't be ill-conditioned from input bounds (i.e. from some criteria you've given), then it's fine to use or set problems with gaussian elimination?
I would lean towards yes, based on what we know about this algorithm.
The contestants lack experience in real contests. I don't know whether the implementation I use is good, but I don't remember it failing me because of precision and that's why I use it.
Is Gaussian Elimination with full pivoting better or one with partial pivoting? Also of the two Stanford implementations (GaussJordan.cc and ReducedRowEchelonForm.cc), which should I use? The former uses full pivoting and the latter uses partial pivoting.
Full pivoting avoids the issue of potential growth altogether, but it's much more expensive because an $$$O(n^2)$$$ search for the pivot has to be done at every step. The point of the research I am citing is that it is very rare for full pivoting to be needed; partial pivoting is usually enough. Full pivoting would be needed only if you had one of those coefficient matrices that induce large growth for partial pivoting, like the gfpp ("growth factor for partial pivoting") matrices linked to above.
From what I know, both the methods have a complexity of $$$O(n^3)$$$ for solving a system of $$$n$$$ equations with $$$n$$$ variables. So is it not always better to use full pivoting?
It's a constant factor increase. The $$$O(n^2)$$$ search needs to be done every time you find a pivot, which you need to do n times.
So it's a meaningful difference in speed.
I tested two programs, one with full pivoting and one with partial pivoting. The full pivoting takes about 9s and the partial pivoting takes 6s. I ran this on a $$$1000$$$ $$$\times$$$ $$$1000$$$ variable system. So in practice, there is only a 1.5 constant factor difference between the two. I feel that having the assurance of a correct answer outweighs the speed improvement in this case.
You're right that it's the same overall algorithmic complexity, although it's worse algorithmic complexity for the pivoting step, which add to the overall factor.
Keep in mind, however, that well-conditioned matrices for which full pivoting works and partial pivoting does not are very rare. It's unlikely that a problem setter would have even benchmarked a full pivoting implementation, so if you do full pivoting you're risking an avoidable TLE, especially in a slower language. This is particularly true with the tighter time limits nowadays on sites such as CodeForces.
Tests failing hashes modulo $$$2^{64}$$$ are also rare, so let's use them to avoid TL on sites such as codeforces.
I think fakerman was asking for actual advice, not ironic commentary.
His benchmarks indicate that full pivoting is 50% slower. Unless the problem setter specifically budgeted for full pivoting, it's possible that a full pivoting solution would time out.
This is different from using weak hash functions. If you find an input that breaks a weak hash function, few people will be surprised.
If you can craft a problem with a well-conditioned matrix that requires full pivoting (as opposed to partial pivoting) then you can publish a research paper like the references my post cites; based on my research so far, I'd say it's unlikely you would see this in a programming contest first.
But, maybe you're right and problem setters implement and budget for full pivoting every time when deciding on time limits. And maybe there are some as of now unpublished problem classes that are well-conditioned, yet require full as opposed to partial pivoting. The future will tell.
Is this post a propaganda
of submitting unproved solutions for contestants and
of not trying to prove their solutions and to create various tests, including corner cases in some senses, for problemsetters?
Or a piece of helpful advice to avoid NAIPC problems
TL;DR Gaussian elimination has problems with stability.
I haven’t given the post too mich time to read, but it seems that you’re asking for a precision of $$$1e-5$$$ in the normal domain whereas Gaussian elimination is actually done in the log-domain. So I can’t help but ask. How does, say $$$1e-7$$$ error in the logarithm of the answer impact the error on the answer?
To me, this kind of tricky analysis during a contest kind of defeats the purpose of solving the problem, and is just a technicality that very few people actually know how to handle (especially that we’re talking about a supposedly easy problem).
Moreover, the argument that partial pivoting is ‘precise in practice’, while I understand its meaningfullness, has no place in reasoning about the correctness of an intended solution for a CP problem (and it feels to me that it’s just a way of covering up for your mistakes, which is irritating).
In my opinion, a problem where thinking about precision is the main difficulty is not an easy problem, and not a fun one. Deal with it.
Gaussian elimination is actually done in the log-domain.
What do you mean by "done in the log-domain"? The stability of Gaussian elimination does not depend on any pre- or post- transformations done to the right-hand side. In other words, the system $$$A x = b$$$ and the system $$$A x = \log b$$$ have exactly the same stability properties. (Read the literature I cited above for more details.)
The relative error that is added by having to take a log when computing $$$\log b_i$$$ and the relative error that is added by having to transform the answer back before printing it depends on the language you're using. As a representative example, in Java, both are required to be accurate to within 1 ulp — I would expect similar guarantees in C/C++. In addition, in this specific problem there was the additional guarantee that the answer was within 1 and 1e6 so we're not talking about having to take the log of very small or very large values.
a problem where thinking about precision is the main difficulty is not an easy problem
That statement is true, but this problem didn't require thinking about precision very much, if at all. All you needed to have is a bit of basic intuition and not try to create a maximally unstable version of Gaussian like (really only one) team did.
Ok, say the true logarithm of an answer is $$$x$$$, and your algorithm outputs $$$x + 10^{-7}$$$. Then the true answer would be $$$e^x$$$, whereas you will output $$$e^{x + 10^{-7}}$$$. Now, if $$$x$$$ gets big, I would expect the error to grow considerably bigger.
The whole point is that the actual error would be $$$e^{x + 10^{-7}} - e^x$$$, which can be a lot bigger than the naively-assumed $$$10^{-7}$$$.
In this problem $$$x < 13.815510557964274$$$ so it doesn't get big.
Ok, I think I understand your question now. You're asking how big the absolute error in terms of the solved-for $$$x$$$ can be and still meet the problem's asked-for relative error? Let's see if we can do the math here.
Let $$$\hat{x}$$$ be the computed value and $$$x$$$ be the true value. Then the absolute error is $$$a = \hat{x} - x$$$. We want to bound the relative error of $$$\frac{e^{\hat{x}} - e^x}{e^x}$$$.
Then $$$\frac{e^{\hat{x}} - e^x}{e^x} = \frac{e^{\hat{x}}}{e^x} - 1 = \frac{e^{a + x}}{e^x} - 1 = e^{a} - 1$$$. Thus, if we're aiming for a relative error of $$$10^{-4}$$$, the absolute error (before performing exponentiation) cannot exceed $$$\ln{(1 + 10^{-4})}$$$, which is about $$$10^{-4}$$$.
I don't have proof that it won't (other than empirical proof), but I have to say that if I were a contestant the chance of losing $$$6$$$ decimal digits when performing Gaussian with partial pivoting on an apparently well-conditioned matrix would not preclude me from attempting this problem, considering that the input data was given with $$$10^{-10}$$$ precision.