


We will hold AtCoder Beginner Contest 167.
- Contest URL: https://atcoder.jp/contests/abc167
- Start Time: http://www.timeanddate.com/worldclock/fixedtime.html?iso=20200510T2100&p1=248
- Duration: 100 minutes
- Number of Tasks: 6
- Writer: gazelle, kort0n, kyopro_friends, potetisensei, sheyasutaka, tempura0224
- Rated range: ~ 1999
The point values will be 100-200-300-400-500-600.
We are looking forward to your participation!






No Comments on this blog . This is strange I guess
The contest will start in 2 mins!
It already started!
Thanks!
I wonder where I can find the tutorial after this contest. I am a beginner this is my first time to participate in this atcoder contest
In the
Contest Pageitself , after the contestAtCoderprovides Tutorials for each problem in well descriptive way.Sometimes editorial in English is not provided promptly after the contest. It is better to have a look in this discussion post after it ends. Many people will share their ideas.
can u send me the link to the atcoder tutorial (at least the Japanese one so that I can use google translate).
In the contest page you will get a tab called "Editorial" whenever its available.
Finally!
Full sweep of the problem set (after some annoying debugging on F).
F is interesting! get AC at the very last minute!
How to solve D? I was getting WA for last 4 test cases.
you have to get length of cycle in component containing 1
Can you tell me what's wrong here? submission
its not always the case that you have to travel cycle atleast once
What's wrong with my submission? Code link
Shouldnt this be
path[k+i]Can you please check this solution of mine?
https://atcoder.jp/contests/abc167/submissions/13089636
Well, the TLEs are caused by
find(hello.begin(), hello.end(), aaa);find the beginning of the cycle in the created graph (or linked list), as well as the length of the cycle. Then, roughly speaking, take K % (cycle of length) and just traverse the list one more to find the final index.
Do it for 2 different cases k<=n and k>n. Check manually for k<=n and use the idea of cycle for k> n!
Here is the code
Hint : After a point towns start to repeat themselves periodically and king starts travelling in a cycle. https://atcoder.jp/contests/abc167/submissions/13059179
Simulate the teleportation until you find repetition. Then go and find the first occurrence of the repeated value. The answer will be to travel to the first occurrence and then going in a loop from the first occurrence to last occurrence, for which the answer can be calculated using modulo.
Let $$$f_k(i)$$$ be the town we end up at if we start at town $$$i$$$ and teleport $$$k$$$ times. Then note that for positive $$$p$$$,
The input corresponds to $f_1$. So compute $$$f_2, f_4, f_8, \dots$$$ using this DP. Then divide $$$k$$$ into powers of 2 and apply the $$$f_i$$$ that correspond to those powers.
Here's a short implemenation.
I did it using binary lifting...as it was what i got in my mind first but finding cycle length is a great idea(and easier i guess).
Here is my submission: Code
I have observed most people used std::set and messy implementations to find the starting point of the cycle but you can use a very easy floyd warshall cycle detection algorithm to find it. you can learn about it on the internet it very easy to understand
Here is my implementation I have heavily commented it at so that you can understand easily
Because there are n towns, accoriding to pigen hole theroy, after n moves, there must be repeated visited towns. So the solutions is: (1) if k <= n, just simulate k moves; (2) if k > n, simulate n moves. If the n-th visited town is x, then the cycle length is n-last[x]. last[x] is the last time x is visited before the n-th move. Decompose k moves into three parts. First n moves, then (k-n)/(n-last[x]) cycles, then (k-n)%(n-last[x]) moves. After the cycles part the king returns to x. So the answer is move from x for (k-n)%(n-last[x]) moves.
For 2nd case(k>n) why I have to simulate n moves? I have to simulate just till I got a city(say X) which has already appeared. so just find previous occurrence of X say it's I. so I should subtract I from k. k=k-i; now take mod. k=k%length_of_cycle; and then traverse from i till k.
What is wrong with idea?? Can you please point out. I am getting RE for some case because of zero length_of_cycle. Because when i am taking separate case i.e. return if cycle_length is zero then i getting wrong answer instead of RE. But length of cycle can never be zero. I am
I have been stuck. Please help anyone.my submission
There must be some of by one error... What if k==l.length()?
For k>= l.length()
You can see in the code{line 45,46,47} I am finding previous occurrence of X (since this is the town which got repeated for the 1st time). say it's index is 'i' then cycle_length= l.length()-i-1; Since cycle/looping start from i so we should subtract the steps before i so k=k-i; and now we will take the mod with cycle_length and then traverse from i till k.
If I am wrong somewhere please tell.
test your code with: 1 10000 1
first find the length of cycle then using bisection you can get the solution one think you have to consider when cycle length is 2e5 overflow can occure because 2e5*1e18 cross long long range ..
How to Solve E ?
Why?
explanation below
c(n-1,k1) part is straight forward: find k1 points to split the whole row.
In each of k1 + 1 segments, colors must be different. The 2 blocks at either side of each splitting point have same color.
m is for the first block of first segment, it can choose from all m colors. for the rest blocks of first segment, each one can only choose from m-1 colors since its color must be different from adjacent blocks.
for the first block of other segment, it has only 1 choice: the same as the last one of previous segment. the rest blocks of other segment are like that in the first segment, each has m-1 choices.
Hence the algorithm.
why c(n-1,k1)?? ... why not c(n,k1)??
We are looking for the number of ways to choose k1 pairs of adjacent/consecutive blocks out of the total number of n-1 such pairs.
Ohh ... Thanks!
pandastic is right about it below.
Initially, we want to split the array into (k1+ 1) non-empty segments, so we are selecting elements from first n-1 elements and each selected element represents right borderline of the segment. We will get an empty segment if we allow n elements. See the problem with c(n,k1) :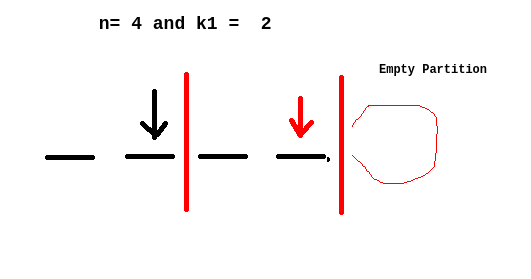
Bhai ye picture kaise banai?
Online Ms paint, then upload that picture on some image hosting website and finally link that in the comment.
I understand the idea but keep hitting TLEs. How can you computer "n-1 choose k1" efficiently?
use c(n,m)=n!/m!/(n-m)! and precompute and cache x!.
don't use c(n,m)=c(n-1,m)+c(n-1,m-1)
shouldn't it be (m — 1)^(k -1) instead ??
After choosing k1 pairs, merge them and the problem reduce to: paint these segments such that adjacent segments having a different color. click here
merge with next element
I am sorry i still don't get why are you merging the two things. Dont they need to have different colors. So like first 2 will have same colors m ways and rest 2 will have m — 1 choices , so m*(m — 1)*(m — 1)
Can you please explain what's wrong with my submission, I have done exactly the same thing https://atcoder.jp/contests/abc167/submissions/13111548
count /= x -> WA
count *= inv(x) -> AC
where inv(x) is modular inverse of x
And consider the case when x = 0
AC thx mate.
(m-1)^(n-1-k1) bro why you do this ans how do you know say you have done k partitions then the multiplications in each block ?
for certain k1, the total ways of coloring equals to the multiplication of ways of coloring in each segment.
Denote b[i] be the number of blocks in ith segment, thus sum(b[i])=n. 1<=i<=k1+1.
As I mentioned above, for the first segment, the first block has m colors to choose and each of rest blocks has m-1 colors to choose. thus for the first segment the total ways of coloring is s[1]=m*(m-1)^(b[1]-1).
for the second segment, the first block has only 1 choice, which is the same as the last block of previous segment. each of rest block in second segment has m-1 colors to choose. Thus for the second segment the total ways of coloring is s[2]=1*(m-1)^(b[2]-1).
Similarly, s[3]=1*(m-1)^(b[3]-1)...s[k1+1]=1*(m-1)^(b[k1+1]-1).
So the total ways of coloring for k1 is:
Here is my approach: Consider we divide the n blocks into p sets of partitions and label them as n1,n2,n3,...,np. We could do it in (n-1)c(p-1) ways.
Another constraint is the total pairs of contiguous blocks with same color <=k. It means that (n1-1)+(n2-1)+....+(np-1)<=k which implies n1+n2+...+np-p<=k which implies n-p<=k thus we get p>=n-k
Now for coloring part of p sets can be done in m*((m-1)^(p-1)) ways.
So simply iterate p from n-k to n and add ((n-1)c(p-1)) * (m*((m-1)^(p-1))) to the answer.
Thanks ajit. Nicely explained. Now I am feeling sad that I was not able to solve it during contest .
could you explain why (n1-1)+(n2-1)+....+(np-1)<=k more?:)
Because a set(subarray) of x elements of same color have x-1 pairs of contiguous elements of same color like if [1,2,...x] is a set of elements of same color then we have the pairs (1,2) (2,3) ... (x-1,x) to count which in total is x-1
I have a small doubt in problem statement
For n=6 m=2 k=2
2 2 2 1 2 2
Is this a valid combination?
No, because we have 3 pairs of contiguous blocks of same colour with indices (1,2) (2,3) (5,6) which is greater than k=2
Okay thanks!
now I got it, Thank you for your help
Can you please explain the m*((m-1)^(p-1)) part ?
Also ,since we are choosing p segments out of total n-1 segments then shouldn't it be c(n-1,p) ?
We have 'p' partitions where the blocks inside each partition are colored the same with some color. For eg: 1 1 1 | 2 2 | 3 3 (3 partitions and 3 colors with n=7). First partition can be colored with 'm' colors and remaining (p-1) partitions can be colored with (m-1) colors each, as colors between adjacent partitions must be different.
Also, it's C(n-1,p-1) as we have to choose (p-1) bars (to get 'p' segments) from a total of (n-1) bars .
Now I am even more confused. :(
Which part is confusing ?
Got it now, thanks :)
Nicely explained,can you please explain, (n-1)C(p-1) part like how you get this relation. UPD: Got it.
F was 1203F1 - Complete the Projects (easy version) in disguise..
Exact same problem: https://mirror.codeforces.com/gym/101341/problem/A
EDIT: link to the editorial for this problem: https://mirror.codeforces.com/blog/entry/51445?#comment-393777
What sorting method works for F?
difference of opening and closing brackets in non-decreasing order
how are you taking care of these cases
)(
(
)
Put all the Open braces at first, and closing braces at last. For )( cases, sort them by https://mirror.codeforces.com/blog/entry/77148?#comment-619238 and put in between open and closed braces. If everything works out, put Yes.
Can we re arrange some string ? where is it written in statement?
No, we can't re-arrange a particular string.
can someone explain why this works?
My idea was to sort according to the minimum of opening-closing bracket at any point for each string. Then to use segment tree to get the string which gives maximum opening-closing brackets in a certain range. I don't know why this code doesn't work. Is the idea correct?
Try this.
3
(((((
))
))))(
Your method gives No. But the answer is Yes
Thanks!!
Every string has a balance of open/close, and a min value, which is the minimum balance where the string can be used.
ie it looks like '))((((....', then the balance must be 2 before we can use it. We need to consider both properties.
I think this algo is wrong. Consider the following case:
Here your algo will give answer "No", but the correct answer is "Yes".
Right! That's why we need some hacking phase (and crowdsource some more test cases) :D Thanks for pointing out.
(A.openCount-A.closeCount) - (B.openCount-B.closeCount)What are the difficulties of todays' problems in terms of codeforces ratings?
A,B,C < 1000
D : 1200/1300
E : 1500/1600
F : 2000/2100
My best estimate:
A — 600 B — 900 C — 1100 D — 1400 E — 1700 F — 2000
Roughly, the gap in difficulty between the problems was the same.
How to solve E?
At most K adjacent pairs can be same. So at least n-1-k pairs have to be different. Let we need to make p pairs different. So it can be done in C(n-1,p)*M*(M-1)^p. Do this for all p from n-1-k to n-1.
Can you explain, how you got the formula?
Choosing p pairs from n-1 is C(n-1,p). If p adjacent pairs are different,there are p+1 parts,where each part has same color. Now,there are M ways to color the first part, all other parts have (M-1) ways.
Hey! Am still not clear with your intuition. Choosing p pairs is fine. But how did you arrive at them being adjacent? Can you please explain your idea?
I try to break it down
C(n-1,p) => number of ways to pick p items so that it has the same color as the item left to it
Consider the case of p = 0, all items are distinct then there are N blocks with different color When p = 1, one item has same color with block on left, so number of continuous block with same color becomes N-1. ... go on until p = k so there can be N-p number of continuous block with the same color
Now to choose the color: First continuous block can be any color M Second until last continuous block segment can only be one of the M-1 color
Thus, total ways to color block segment = M*(M-1)^(N-p-1)
Putting it together=> total of ways to color * total of ways to select p items = C(n-1,p)*M*(M-1)^(N-p-1)
thanks for your explanation
How to solve E ? Can someone hint me ?
Can anyone explain approach for problem C.
You can bruteforce for all 2^n possibilies since n<=12.
hey, please tell how could one do it if the constraints are large ?
https://atcoder.jp/contests/abc167/submissions/13121855
Look at the backtrack function, it generates all possible subsets, and then the solve() function checks if the books in the subset satisfy the condition
understood , thanks for the help !!
abi gang :)
recursion approch. check all posibilities, cauz constraint is very less(2^12)*12.
do it look like 2d knapsack?
its just all subsequences problem; its rucursion approch u can solve by iterative method using bitmask;
here is two possibilities either i can take that book or i can leave that book, if i take then dp[j(0 to m]]-=ar[i][j] (after subtracting dp[j] would be the required value).if all required value <=0 that mean we have achieved the question requirment so i just compare with ans in base case
Thanks for the help Ritesh but if the constraint were big then should we use knapsack
no bro cauz this problem does not depend only on x and n, it depend on value of every book algorithm and cost of book and x and k value.so so i think we cant fill dp like knapsack;
M and N were very small, so you were able to brute force and test every possible combination of books bought vs cost.
Use bitmask to consider all possibilities and update the minimum cost if it's valid.
Submission
With only $$$N = 12$$$ books, you can brute force all possible sets of them ($$$2^N = 4096$$$) and find the minimal cost. An easy way to work with it is to have an integer where $$$i$$$-th bit is set if you take $$$i$$$-th book.
Just a brute force for all 2^N combinations. My solution
I just used brute force. Try all possible subset of rows using bitmasks. The constraints imply this will fit within time.
Video Tutorials for E and F
My Discord Server
Thanks for your solution but can I solve E with dp ?
There is a O(nk) DP solution but it's not fast enough.
Can u please explain the O(n*k) solution?? I tried solving using dp with segment tree but got WA. I used dp[i] =(i<=k+1?power(m,i):(m-1)* summation(dp[i-k-1] to dp[i-1])
Hey! ujju_sucks I used the similar approach. But instead of using segment tree. I stored sum of previous k+1 elements. But couldn't get it working. Can you please check the approach
https://mirror.codeforces.com/blog/entry/77148?#comment-619369
Hey! I think we misunderstood the problem. The question is asking for adjacent colour pairs across the entire colouring to be less than K. And not for any segment.
Holy shit!!!! I am such a fool
The reaction to realization of truth ..
Hey can you please explain in brief what is wrong with this dp? I am unable to follow your conclusion.
N=8 K=1 aabccdee This is invalid. As total pairs are 3.
I'd been losing my mind for over a day trying to find an example that didn't work.. thank you for posting this lmao
just as a curiosity, here's an O(n) dp solution to the way we initially understood the problem. I'm not fully confident it's correct, but hey it might be!
Hey! stefdasca You can optimised the DP solution by storing previous k+1 sums. Can you please check the approach
https://mirror.codeforces.com/blog/entry/77148?#comment-619369
I tried to do it with dp but could not reduce states. If somebody has done it using dp, please share the approach. Thanks
My dp complexity is O(n ^ 3), how about you ?
Hey, for choosing x components from n elements, there should be (n-1)C(x-1) ways, right? Then why did you multiply each m*(m-1)^(x-1) element by (n-1)C(x)? UPD: I understood my mistake.
When are the editorials posted for these contests?
The Japanese tutorials are usually posted quite early after the contest ends. You might have to wait a day maybe for the english editorial sometimes. But you can always use Google Translate :).
A difficult version of D is here: https://cses.fi/problemset/task/1750
Instead of starting at 1, start at a given X and solve the problem.
Use binary lifting.
Why doesn't the relative sorting of strings work?
Solution (Wrong on only 1 case)
(
)((
()))
If a string looks like '))(((((...' you cannot use it everywhere. Each string has a balance and a min value of needed balance before that string.
Lol, read k adjacent pairs will have the same colors in E.
same :-( still around half of all test cases passed.
How did you generate all the permutations for C? What I did is, I looped from 0-2^n-1, convert the value to binary, Wherever the bit is set, I push it to a temporary vector and send that vector to fun for solve. Here is what I did. Overcomplicated code How to simplify this?
To check if a bit is set or not, you don't need to convert it to string.
For example to check if
jthbit in X is set or not, you can simple check the value of(x & (1<<j))This might help
For F: let's say some blocks have been placed giving total sum ( by total sum, I mean number of '(' minus number of ')' ), equal to prev. Now for all the blocks left, which have a minimum value of prefix sum greater than or equal to prev , select a block having a maximum total sum.This can be done by using binary search and seg-tree.
Is it wrong ? since I am getting WA verdict , not sure if the implementation is wrong or the logic is wrong.
My ideas was also exactly this. It doesn't work for me too :( Can someone give a counter example for this idea?
Try the following test case :
["(((", ")", ")))("]
The correct answer is yes
EDIT : Formatting
This approach will fail for the following case:
After taking first string, you should take the third one, but according to your algo, you will take the second one.
Why "equal to prev"?
We can use a string at a position if the current balance of open/close is bigger than the needed open brackets before that string.
To greedyly find a seq we can use all strings with above property, and would use the one with the biggest balance. Since that one gives most oportunities for the next step.
On each step we need to check if balance is smaller/bigger than needed open brackets.
But I do not get how to implement this in O(n logn)
Edit: Ok, did not see that: Every string has a third property, the number of closing brackets which must occour after it. We need to consider this, too.
Three test cases are not possible for ques2? what is wrong in my code...
include <bits/stdc++.h>
using namespace std;
define int long long
int32_t main() { int a,b,c,k; cin>>a>>b>>c>>k;
int ans=0; ans+=a*1; int x=k-a; if(x>0){ ans+=b*0; x=x-b; } if(x>0){ ans+=x*(-1); } cout<<ans<<endl; return 0;}
you missed the case when k<a. In that case answer is just 'k' but your code prints 'a'
Hints and Solutions for problems A-D
Very nicely written pls make of codeforces as well.
Can someOne explain me this solution for D
https://atcoder.jp/contests/abc167/submissions/13028277
Read about Binary Lifting.
How to do problem C (Skill Up) using DP if the constraints are slightly bigger(like n,m<=50).. Any kind of suggestion is appreciated. Link to the problem is -> https://atcoder.jp/contests/abc167/tasks/abc167_c
Using min-cost max-flow, take n nodes to the left side ( represents books), m nodes to the right side ( represents algorithms), connect a source to all the n nodes in the left with capacity = total understanding it provides for all algorithms, and cost = cost of the ith book. connect sink with all the m nodes to the right with capacity x and cost 0, also for all the n nodes in the left, connect to each of the m nodes with a capacity equal to a[i][j] and cost 0. Now perform min cost maxflow algorithm and for the maximum flow calculate the minimum cost, if the maximum flow is not equal to m*x, then the answer is -1.(maximum flow cannot be greater than m*x since the capacity of all the edges to sink is x).
Is there a way to see test cases for Atcoder? My F submission failed on two test cases only, and I wanted to check what the case is. Here is my submission. Algorithm described in short:
Make Pair of elements for each string, (required, total), required saying how many opening brackets are required before this string (based on the minimum of the running total), and total telling what the end total is. Each opening bracket is +1, closing is -1.
Sort the Pairs based on required in ascending order.
In a loop, pick all the pairs which have their required less than the current_sum (initally 0), put it in the priority queue, sorted by decreasing total.
if queue was empty, print "No" else poll one element from the queue.
https://www.dropbox.com/sh/nx3tnilzqz7df8a/AAAYlTq2tiEHl5hsESw6-yfLa?dl=0 ,but the testcases of this round have not been added. Check again after few hours.
https://mirror.codeforces.com/blog/entry/77148?#comment-619315
I checked and it passes that case.
It was my first contest in ATcoder, In the telporter problem I had 51 AC testcases and wondering if I can access the failed testcases? sub1_21.txt and files like that!
Testcases are available at this link after some days https://www.dropbox.com/sh/arnpe0ef5wds8cv/AAAk_SECQ2Nc6SVGii3rHX6Fa?dl=0
Can anyone help me with problem C (Skill Up). Problem
Use brute force over all 2^n possibilities. I use bitmask to do so. https://atcoder.jp/contests/abc167/submissions/13070747
0/1 knapsake also works
For problem E, am using following dp approach. Need help in finding the issue with it.
dp[N] = dp[N-0] * nWays + ... dp[n-i] * nWays + ... dp[n-(k+1)] * nWaysSo at any point, I need to maintain sum of previous k+1 dp elements.
Here's the code
Can someone please point out where am I going wrong?
Did you misunderstand the question? your dp formula seems to be implying that for each contiguous block there can not be more than K adjacent colors. The question is asking for adjacent color pairs across the entire coloring to be less than K.
So as far as I understood the question, maximum amount of contiguous blocks having same colour can not be more than K+1? Am I still interpreting it wrong?
Thanks for pointing out. I think misunderstood the problem.
I am very new to atcoder (given only 4 contests). Can someone give me an estimate as to what are the equivalent atcoder ratings wrt codeforces ratings??
Maybe atcoder+300 == codeforces
Hello. Can anyone give ideas on how to write a choose function that computes large values of C(c,r)%m quickly? Thanks.
To calculate C(n, r)%m and if m is prime its always better to compute factorial and their inverses in O(nlogm) and then use them to calculate C(n, r)%m in O(1) time. Here is the link to my submission: https://atcoder.jp/contests/abc167/submissions/13084560
https://cp-algorithms.com/combinatorics/binomial-coefficients.html
What is wrong with my approach? Here is my submission link: https://atcoder.jp/contests/abc167/submissions/13095279. I divide both the strings into pos(total difference positive) and neg(total difference negative). In a greedy approach you place all pos strings before neg strings. Moreover in pos strings you place all strings in non-increasing order of minimal difference. You place all neg strings non-decreasing order of minimal difference. In case of ties you take the one with larger total difference.
Most of the times the E or the F problem of the ABC is always related to combinatorics and I am not good at it.So can anyone suggest where can I find problems related to Combinatorics for practice.
please explain what is the error in my code for problem F? https://atcoder.jp/contests/abc167/submissions/13096927
what I did is I remove all the perfect strings such as (()),()(). now if the sum of all the string +1 for ( and -1 for ) is not equal to zero the answer is No. else sorted it according to the difference of (open-close) in decreasing order and then traverse the whole string if the sum gets negative at any point then I output NO else yes.
My solution for F: is to separate strings into 3 categories that resultant is
(,),)(. Then putting all opening at front, all closing in end, and sorting)(according toopen_count-close_countin decreasing order and putting in middle. My solution gotACon atcoder but failing on following testcase by giving answerNobut it's actual answer isYes. Here is my solution.Each one of those strings has a property 'leading opening brakets'. It cannot be used at positions where the balance is less than that number.
So, we cannot simply sort by
open_count-close_count, but we need to build a subset of strings with the leading opening brakets less than current balance, and then choose the one from those by using the sorting.If you have solutions then please share link to your code.
Update: aren't you suggesting O(n^2) solution?
This one looks good https://mirror.codeforces.com/blog/entry/77148?#comment-619641
Please see this . I think it is correct .
how to solve A ?
Learn FFT
Testcase for F was very weak. AC code: https://atcoder.jp/contests/abc167/submissions/13063944 which fails on the TC:
5
(
)((
)((
))((((
)))))
Answer should be Yes but AC solution gives No.
can anybody tell me what is wrong in my submission of d . It is just failing for some testcases
Ah, How can we know whats wrong in your code if you will not give the link
ur name should be kunal kamra
My approach for problem F:
If after this CURSUM is not 0 we return no else return yes.
This gives WA. Can any one give a counter test?
My code
try this
3 (((( ))) ))(got it. thanks!
Edit : My solution got AC but is not correct (see example below) . I have modified the approach little bit (see my comment below) and now it is giving correct answer for the example below as well.
solution for F : We need to assign each string a weight , sort them in descending order according to the weight and finally combine the strings in that order . Now how to assign the weight ? Let us call number of occurrences of $$$($$$ as $$$O$$$ and number of occurrences of $$$)$$$ as $$$c$$$ . We calculate these numbers for each string individually and then we do following :
Reason :we want as may characters of type $$$($$$ in initial part of final string and as many character of type $$$)$$$ in final part. we want strings of type $$$((((($$$ to occur first and strings of type $$$))))$$$ to occur last. Now for string in which $$$o>c$$$ , we put that string first which has least number of $$$c$$$ .Example : we will put $$$))(((((($$$ before $$$)))(((((((((($$$ because let $$$(($$$ occurs before both of them then if we put $$$)))(((((((((($$$ just after it , then there will be unbalance .
Case for strings in which $$$c>o$$$ is symmetric to the case $$$o>c$$$ if we look from right side .
Now for strings in which $$$o==c$$$ , they don't contribute any extra '(' or ')' and thus we put them in the middle . Else they can cause problem . We can build the final string by combining all other strings after sorting and check if it is balanced .
submission : link
Shouldn't the following test case output "Yes"? (by arranging them in the given order)
I got "No" from your code
Thanks for providing counter example . I have redefined the weights as following : we find number of '$$$($$$' not balanced by '$$$)$$$' and call it o1 and number of '$$$)$$$' not balanced by '$$$($$$' as c1 .For example in $$$)((())))$$$ c1 = 2 .
Now we want the strings having more number of unbalanced '(' on the left part of final string and the strings having more number of unbalanced ')' on the right part of the final string .The idea is similar to the above comment ,except o1 and o2 are calculated differently.Also for the case in which unbalanced '$$$($$$' are more than unbalanced '$$$)$$$' , we will put those first in which number of unbalanced '$$$)$$$' are less . For example $$$))(((($$$ will be placed before $$$))))(((((((((($$$ . Also $$$))((((($$$ will be placed before $$$))((($$$ . All other cases are symmetric if we see from right side.
We do that and we check if final string is balanced or not.
submission
It got AC as well as it is working on above example given by geeky.ass . I will be very happy if some one provides further any counter example .It also got accepted in almost same problem with better test cases .
problem F , need a counter example why my code fails=>https://atcoder.jp/contests/abc167/submissions/13105666
Detail explanation and code for C D and E
Solution for F.
There are no good explanation in the comments. Also some of the wrong solution are getting accepted with some heuristics link . So I thought I would explain how I did it after 3 hours of struggling. And if anyone can counter my solution you are welcome. I will try to explain form the basics.
Let us first see the representation
For a single String i
1 ≤ i ≤ NLet an
a[N][2]array representing count of -For String i
a[i][0]denotes the maximum value count)incount ) - count (brackets can reach while we are sweeping from left to right anda[i][1]denote the same for maximum(while sweeping form right to left that is maxcount ( - count )For example
(())->a[i][0]anda[i][1]will both be 0 ,())->a[i][0]will be 1 anda[i][1]will be 0.(((->a[i][0]will be 0 anda[i][1]will be 3If the final string formed after rearranging is
Tthen for it to be perfect for any pos1 ≤ pos ≤ Nwe should never encounter difference of count(and count)less than zeroThen make two sets of
a[N][2]First set containing
a[i][1]-a[i][0] ≥ 0let us denote it asS1Second set containing the remaining elements that is
a[i][1] - a[i][0] < 0let us denote it asS2Sort
S1according to the value ofa[i][0]in increasing order SortS2according to the value ofa[i][1]in decreasing orderAppend the second set at the back of the first set
Initial let us denote the difference of
(and)bracket bySthen initiallyS=0Sweep right form 1 to NSubtract
a[i][0]formScheck if
Sis less than zero then printNoand returnadd
a[i][1]toSIf finally
Sis zero printYesNow why this works ?? I'm not sorting according to some difference of value of
a[i][0] - a[i][1].Explanation.
1 ) As you can see in the sorting order of
S1the value ofSkeeps on increasing it never decreases. This proves the fact that at any point we are using the maximum possibleS - a[i][0]to be checked as less than 0 . Becausea[i][0]is sorted in increasing order.2 ) The second part is not that intuitive like why to sort
S2based ona[i][1]in decreasing order. To get the feel of it try imagining doing the same thing we did in the first part form backwards like taking the mirror image of the string we will have to do the same thing we did in the first part forS1. That is why it is sorted in decreasing order ofarr[i][1]. I don't have any other way to explain what's going on in my mind other than this for the second part.3) The
Svalue should be equal to zero I mean that is but obvious .Well, I don't know what the editorial will say or if this approach is actually correct or not, but I just couldn't stop myself from commenting here that how simple yet beautiful this approach is (with your lucid explanation). My implementation for this approach: https://atcoder.jp/contests/abc167/submissions/13118554.
Can anyone explain why this code works for problem F?
can Anyone please explain to me the 2nd condition of problem E using an Example?. (adjacent pairs blah blah) I find it confusing.
what is the solution for D?
For D,you got to find a cycle(the cycle may not start from town 1) For example, if the given array is 6 5 2 5 3 2, then the cycle starts from town 2 ( 5-->3-->2). So first of all find the starting point of the cycle, and subtract the required number of steps to reach this starting point from k. Now you'll only move within the cycle. Since k can be large, take (k modulo cycle length). Lets say k modulo cycle length is x. Then obviously x<cycle length. So simply perform x steps. The town you land on is your answer.
Here's my code!
For F, I have taken array of pair and for each string given I keep in the array count of left and right braces which are unbalanced , and Then I sort the array considering the count of opening bracket and then considering the closing bracket. And then i took two variables l and r keeping track of opening bracket from starting and closing bracket from ending respectively. I started two fill the l and r from respective two sorted arrays and I think the approach is right because I Have tried almost all the test cases available in this blog for that question but not a single one has failed and also I am getting RE in few cases only not WA so the problem might be of implementation.. Can any one help.. Submission
Can someone give me a counterexample to problem F? I tried all the counter examples in the comments, but they were all correct, thank you very much! https://atcoder.jp/contests/abc167/submissions/13121322
I still can't find a counter example, I've tried all the cases the comments gave that could be wrong
I got it !
I think the test data is weak in problem F, many solutions got accepted are printing "No" in this case while the answer is "Yes". The test case:
This is problem F with stronger tests: 101341A - Streets of Working Lanterns - 2, enjoy
my code got AC on atcoder
But WA on test 71 in this problem
any idea what test 71 looks like ?
Test 71
Thanks got AC now on both
it turns out that what I have commented was the right xD
Is it possible to allow access to all cases?
I already got AC, but I have a code that fails on case 45 and I couldn't figure out the bug in that code.
Test 45
BTW, the generator is very stupid for this problem:
then swap / don't swap two random characters, then randomly cut the string to pieces.
So you can easily stress it locally.
If someone needs other tests, tell me your Polygon account.
Thanks for the generator, I tried stress testing too, my generator couldn't find the case. Now I will try with this one.
I got AC in both versions with the following wrong greedy: repeatedly append to the whole string the unused string which doesn't make the whole string irrecoverably unbalanced (too many unmatched closed parens), and with the highest number of unmatched open parens among all valid choices.
I added your test and some more against your solution
i am not able to find what is wrong with my code 4. Teleporter link of my soln is: https://atcoder.jp/contests/abc167/submissions/13078515 please mention testcase at which my code is wrong
First of all you exceed the limited size of your array by one.
when will the editorial be published?
chokudai, is there any chance some day there is different time for any of the AtCoder contest? That is so sad that in our time zone atcoder contests starts at 5am. AtCoder is becoming more popular with the community, so some time rotation would be amazing.
Too weak pretests in problem F, you can solve this problem by len(s) ^ 2.
Guys urgent...I think 168 clashes with kickstart!!!
Atcoder Beginner Contest 168 is clashing with Google kickstart Round C. Please look into this matter.