


Codeforces now has 342281 testcases. But how many of these are actually relevant?
Let's call a test redundant if nobody has ever submitted a solution that failed on that test. Here's a graph showing what percentage of testcases are redundant over all rounds.
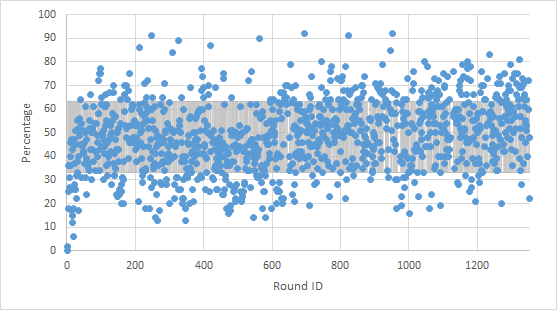
Turns out to be that 173195 tests out of the 342281 tests are actually redundant — no verdict would change if these tests were never there. That's around 50%. I actually expected more, but still, a lot of testcases are redundant.
Here is another representation of data, where the y-axis shows how many problems of each percentage of redundancy.
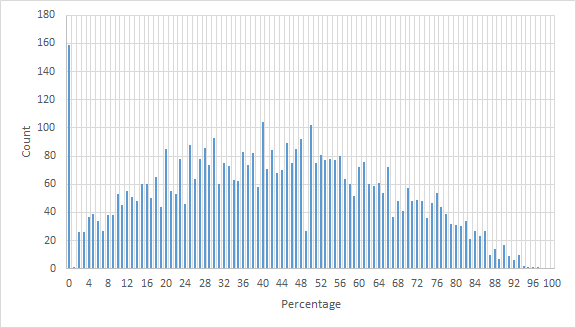
Codeforces can take advantage of this and save resources by not running these tests at all. But how long should we wait before deciding that the current non-redundant testcases are enough?
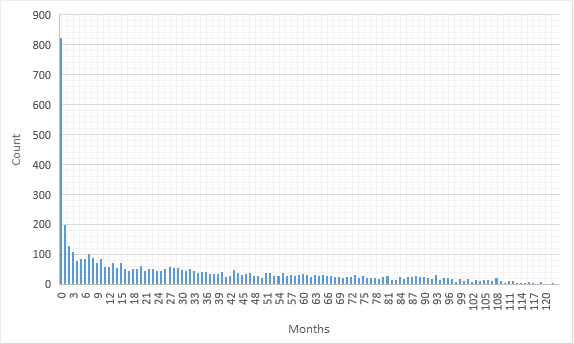
As you can see a lot of problems get saturated in the first month. But many others don't; however, don't treat these non-redundant testcases as absolutely essential because a solution failing at one of them doesn't mean that it passes all others (for example, all problems have solutions failing at the first testcase).
How many testcases, do you think, does a problem need on average if we were to pick them the most optimal way?
Thanks zoooma13 for sharing ideas and helping collecting the data.







I don't think the test cases are initially too many. Imagine that you already generated test cases and know that 50% of them are redundant, but don't know which ones they are. If you decide to remove only one test case, the probability of it being non-redundant is 50%, which is too high. But on the other hand as you said, maybe if some non-redundant test is removed, another one that was initially redundant will do its job. To analyze that, it'll be needed to get for each solution the set of test cases that it fails.
I think your idea of removing redundant test cases after like a few months or something makes sense.
Or maybe we can have something like a priority_queue, which sorts test cases by number of solutions that have failed on them. Or better if a person submits a solution that fails on some test, then his next solution has a high probability of WA on the same test case.
I had a similar idea do to during the contest itself. I saw most of the submissions fail on particular test case, and sometimes these cases are at the very end, which means we are running all other tests uselessly.
I wrote a blog on this a while ago, but no actions were taken -> https://mirror.codeforces.com/blog/entry/74487
I could easily write a solution to any problem that fails only on any one the "redundant" test case.
Let's not make CF = Leetcode
I can easily write a solution to any problem that fails a non-existing test, so we need to include that test too.
Yes sure if CF has enough resources, it should add that test too.
My point is let's not reduce tests such that, non-intentional wrong solutions pass on CF.
It would be cool to make a competition out of this issue, like how to order/remove some test cases in order to minimize time of judgement and minimize potential worng solutions getting ACs. Making this a public competition would be something like the heuristic types of competition like Google Hash Code.
While the findings are definitely interesting, they don't seem to lead to a universally applicable recipe.
How many cases a problem needs? It depends greatly on the problem, and on whether it allows multiple test cases in one test.
Purging test cases after a few months of a problem's existence doesn't address the bottleneck, which is testing solutions during a live contest.
In my opinion, there are just too many similar test cases. Many test cases with identical answers, with almost identical input data, this actually has struck me several times before.
Take this problem: https://mirror.codeforces.com/contest/1077/problem/F2. There are 9 test cases with $$$n = k = x = 1$$$... I mean, I cannot understand how it is possible to pass one of them and fail the others. And there are 11 other test cases with $$$n = x$$$, which (if you've read the problem) is a rather simple case, definitely not worth 11 cases.
Educational rounds seem to be soooo much better in this respect. True, the tests are sometimes weak (spoiler: most of the hacks target TL, not WA), but there are some pretty decent rounds made up of problems with only ten or so tests.
Just take this problem: https://mirror.codeforces.com/contest/1359/problem/C. Every possible test case for sufficiently small input values is in the set, plus several big ones to counter TL solutions. And it seems to me, there were either no successful WA hacks on this one (excluding cheaters) or there are very little.
So maybe the problemsetters could use this model? Or just generate tests randomly + add some corner cases instead of just producing identical data as far as the algorithm is concerned?
The thing is problem testers can't really think of every small mistake possible in a code and so they make a lot of random cases. Yeah this leads to excess computation but I don't really think it is easy to avoid.
Many times you need large no of test cases to fail a randomised soln with fail probability 0.01 removing a lot of test cases from those problems will just help people pass problem easily with inefficient soln. One such example
I think you are stating the obvious, but what he is suggesting is that we get rid of some of the test cases after the problem has been out for a month or so so that we cam judge better which from the randomized test cases are actually needed. If done correctly, I’m sure that it would not affect many future veredicts.
You understood me wrong. What I'm saying is problems with randomised soln as expected soln needs a large no of test cases to fail soln with bad failing percentage. Reducing no of test cases in those problems is a bad idea.
E.g. I mentioned that a soln fails with probability 0.01 on a test case. Probability for that soln to get a non AC verdict -
100 test cases — pow(0.99,100)=0.36
200 test cases — pow(0.99,200)=0.13
300 test cases — pow(0.99,300)=0.05
400 test cases — pow(0.99,400)=0.02
500 test cases — pow(0.99,500)=0.007
Authors will choose ~300-500 test cases if they have a much better model soln. Simply reducing no of test cases won't help.
This is the case with the problem I linked above. Only method to fail the soln I linked above is by increasing no of test cases. Nothing special about a particular test case for that soln. It just needs a lot of test cases over this random test case is good or bad.
Oh, my bad. My comment would be better directed to the comment from Pred above yours. You are correct, sorry. But I suppose that in this types of problems, all test cases would be considered non redundant, but it is worth paying attention to this indeed.
Why the fuck everyone wants to change something at Codeforces?
__ There are winds of revolution flowing around the world. Everyone now wants the world to change for the better. __
Removing redundant test cases only save resources in terms of storage. Think about it there are not many submissions once the problem gets saturated after a month or so and as you stated we need to wait till the problem gets saturated to know about these redundant test cases. So major compute resources are already wasted on these redundant test cases.
I am unaware of how costly storage resources are. Will this be worth the grind?
Have a look at status. I just queried the last 1000 submissions and about 70% of them are submissions to problems created more than 4 months ago. Of course, this rate would change during a contest, but there are a lot of problems that are already saturated in Codeforces.
Oh, I did not have this insight. It is worth implementing this then.