


Background
During Facebook Hacker Cup Round 2 today, Problem D caught my attention. It reminded me of a particular data structure called a kinetic tournament, which is not very well known in this community. However, it offers an extremely clean and slick solution to the problem, in my opinion.
I first learned about this data structure from dragonslayerintraining, who described a variant of it in this Codeforces blog comment. Since the data structure is so interesting, I feel like it deserves a longer explanation, some template code, and more examples. That's why I am writing this blog post.
Kinetic Tournaments
Briefly, the functionality of the data structure is a mix between a line container, i.e., "convex hull trick", and a segment tree.
Suppose that you have an array containing pairs of nonnegative integers, $$$A[i]$$$ and $$$B[i]$$$. You also have a global parameter $$$T$$$, corresponding to the "temperature" of the data structure. Your goal is to support the following queries on this data:
- update(i, a, b): set $$$A[i] = \text a$$$ and $$$B[i] = \text b$$$
- query(s, e): return $$$\displaystyle \min_{s \leq i \leq e} A[i] * T + B[i]$$$
- heaten(new_temp): set $$$T = \text{new_temp}$$$
- [precondition: new_temp >= current value of T]
(For simplicity, we set A[i] = 0 and B[i] = LLONG_MAX for uninitialized entries, which should not change the query results.)
This allows you to essentially do arbitrary lower convex hull queries on a collection of lines, as well as any contiguous subcollection of those lines. This is more powerful than standard convex hull tricks and related data structures (Li-Chao Segment Tree) for three reasons:
- You can arbitrarily remove/edit lines, not just add them.
- Dynamic access to any subinterval of lines, which lets you avoid costly merge small-to-large operations in some cases.
- Easy to reason about and implement from scratch, unlike dynamic CHT.
The tradeoff is that you can only query sequential values (temperature is only allowed to increase) for amortization reasons, but this happens to be a fairly common case in many problems.
Here's the kicker. If you implement the data structure correctly, you get the following time complexities:
- query: $$$O(\log n)$$$
- update: $$$O(\log n)$$$
- heaten: $$$O(\log^2 n)$$$ [amortized]
(The runtime complexity might actually be $$$O(m \alpha(m) \log^2 n)$$$ instead of $$$O(m \log^2 n)$$$ if your updates include both adding and removing lines, and you're also very careful about constructing an example. See the discussion below from Elegia about Davenport-Schinzel sequences.)
Implementation
How does it work? With kinetic tournaments, you essentially build a min segtree as usual, but you add a global priority queue that stores whenever a "contract" breaks. We can put this in the analogy of increasing temperature. For every node, you store the temperatures at which that node "melts", meaning that the minimum value changes from one child to the other. Then, you can just keep popping events from this priority queue as your data structure heats up.
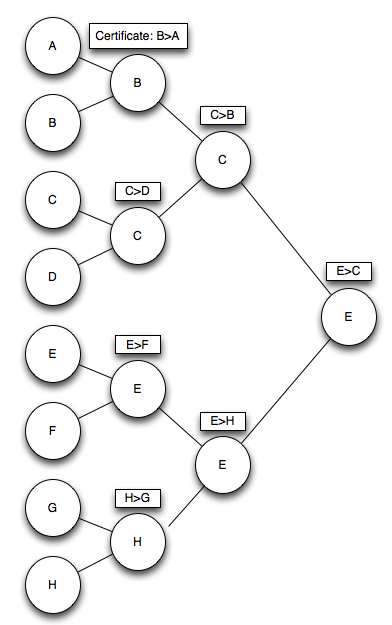
However, this unfortunately can be slow if you're not careful, which isn't good enough, especially if you have many concurrent lines (might give you quadratic runtime, depending on implementation of priority queue). Luckily, there's a neat implementation trick that circumvents the priority queue and prevents this possible quadratic runtime. In every node of the segment tree, you store the minimum temperature at which any part of its subtree could melt. This fits in naturally with the segment tree definition.
To optimize the data structure, you do not recompute at every certificate failure. Instead, whenever the user calls heaten(), you batch all of the recompute operations and recursively rebuild only the parts of the segment tree that changed, once.
The runtime analysis follows from comparing the data structure to computing a convex hull by divide-and-conquer (thanks dragonslayerintraining!). The number of times each node "melts" is bounded at most by the number of leaves in its subtree. This is because you can never have two lines, $$$A$$$ and $$$B$$$, such that $$$A(x_1) \lt B(x_1)$$$, $$$A(x_2) \gt B(x_2)$$$, and $$$A(x_3) \lt B(x_3)$$$, where $$$x_1 \lt x_2 \lt x_3$$$. In other words, as you increase temperature, the number of recalculations is at most $$$O(n \log n)$$$. Combining this with the fact that we have to walk down the segment tree, which has logarithmic depth, every time we do a recalculation, this yields a final amortized time complexity of $$$O(\log^2 n)$$$ for each "heaten" operation.
Code
You can find my implementation of a modified kinetic tournament here:
https://ekzlib.netlify.app/view/kinetic_tournament.cpp
It defines a single struct with template type (~100 LoC), which has a plug-and-play interface that you can use in your own solutions, and no global variable pollution. Example usage:
int N = 2;
kinetic_tournament<long long> kt(N);
kt.update(0, 2, 10); // 2t + 10
kt.update(1, 4, 1); // 4t + 1
kt.heaten(1); // t = 1
kt.query(0, 0); // => 2*1 + 10 = 12
kt.query(1, 1); // => 4*1 + 1 = 5
kt.query(0, 1); // => min(2*1 + 10, 4*1 + 1) = 5
kt.heaten(5); // t = 5
kt.query(0, 0); // => 2*5 + 10 = 20
kt.query(1, 1); // => 4*5 + 1 = 21
kt.query(0, 1); // => min(2*5 + 10, 4*5 + 1) = 20
I've verified this implementation on Problem D from Facebook Hacker Cup Round 2, titled "Log Drivin' Hirin'". In this problem, you can simply sort the queries and nodes in order of increasing "carelessness", and the kinetic tournament finishes the task. Full solution is available below. It runs in less than 5 seconds on the entire test input.
Conclusion
I hope to see more of this interesting data structure pop up in competitive programming! Hopefully this explanatory blog post is useful for you, and please let me know if you find any errors.







Auto comment: topic has been updated by ekzhang (previous revision, new revision, compare).
Is the complexity still $$$O(n\log^2n)$$$ with updating? I can only get an $$$O(n(\log^2 n) \alpha(n))$$$ bound from the analysis of Davenport Schinzel sequence of 3-rd order.
BTW, This DS also appeared in SN Team Selection 2020 Range Sum: you are given a sequence $$$a_n$$$, and we have two kinds of modification:
given $$$l, r, x$$$, let $$$\forall l\le i\le r, a_i \leftarrow \max(a_i, x)$$$
given $$$l, r$$$, ask $$$\max(0, \max_{l\le u\le v\le r} (\sum_{i=u}^v a_i))$$$
For this problem, we have an upper bound of $$$O(n\log^3n)$$$. And there is a conjecture: will it be actually $$$O(n\log ^2n)$$$ or $$$O(n\log^2 n \alpha(n))$$$?
I'm not sure, but I think it's still $$$O(\log^2 n)$$$ with single leaf updates? I could be wrong, as I haven't written down a rigorous argument. But I also can't think of a counterexample.
I think it's certainly $$$O(\log^2 n)$$$ when your only updates are adding lines, or decreasing the values of lines, such as in the FBHC problem. Just the annoying case is when you might need to remove lines (i.e., update that increases $$$A[i]$$$ or $$$B[i]$$$).
Thinking about it from the divide-and-conquer hull perspective again, removing a line might expose more intersection points at combined hulls that are closer to the root of the tree. But does this matter? The total number of intersection points in all subtree hulls is still always bounded by $$$O(n \log n)$$$... so I don't see how you could get $$$O(\log^3 n)$$$ runtime.
Thanks for sending the cool team selection problem, I will think about it tomorrow :)
Well I made a mistake, the $$$O(\log^3 n)$$$ bound appeared in an analysis of range updating...(Though I still confused whether this bound could be improved)
According to this article, there exists a construction of giving $$$n$$$ segments which have $$$\Theta(n\alpha(n))$$$ changing points on the upper envelope of them. So I think the bound of $$$O(n\log^2 n)$$$ is not very clear because we can construct $$$n$$$ segments through $$$2n$$$ updating?
Wow, that's really cool. I didn't make the connection between updating lines and thinking of them as line segments. Let me try to summarize the Wikipedia page:
That seems kind of crazy. I'm really surprised that you can construct this. Thanks for sharing!
Auto comment: topic has been updated by ekzhang (previous revision, new revision, compare).