


Привет!
Совсем скоро начнется отборочный этап. Он состоит из трех раундов, которые пройдут:
Отборочный раунд 1 — 14 июля 2013, 21:00 MSK; Материалы раунда; Разбор
Отборочный раунд 2 — 18 июля 2013, 13:00 MSK; Материалы раунда
Отборочный раунд 3 — 22 июля 2013, 05:00 MSK; Материалы раунда
Каждый раунд продлится 100 минут. Ссылки для входа в раунды доступны по нажатию на название раунда.
Каждый раунд оценивается по системе гран-при 30. Чтобы пройти в финальный раунд не обязательно участвовать во всех отборочных раундах, вам нужно попасть в одну из этих категорий:
топ-4 лучших в одном из раундов;
топ-9 лучших (из тех, кто еще не прошел в финал) по суммарному рейтингу 2 из 3 раундов;
топ-4 лучших (из тех, кто еще не прошел в финал) по суммарному рейтингу всех отборочных раундов.
Все финалисты, 75 лучших участников отборочного этапа, не прошедших в финал и 75 случайно выбранных среди решивших в отборочном этапе хотя бы одну задачу участников получат футболки Яндекс.Алгоритма!
Расписание раундов и подробные правила можно найти на сайте чемпионата.
Удачи! Санкт-Петербург уже совсем близко!
UPD: Результаты первого раунда признаны официальными, мы поздравляем Kenny_HORROR с блестящим выступлением и убедительной победой с тактикой "все в открытую".
В финальный раунд приглашаются Kenny_HORROR, Petr, tourist, eatmore.
UPD2: Мы поздравляем tourist с победой во втором раунде и приглашаем vepifanov, yeputons, ivan.popelyshev, peter50216 принять участие в финальном раунде!
UPD3: По результатам третьего раунда в финал приглашаются winger, KADR, ainu7, s-quark. Поздравляем!
Кроме того, заслуженное место в финальном раунде занимают
по сумме двух раундов: burunduk3, misof, niyaznigmatul, cerealguy, Mimino, liympanda, romanandreev, watashi, RAVEman;
по сумме всего отборочного этапа: Nerevar, ilyakor, dreamoon_love_AA, pparys.
Уважаемые финалисты! Мы поздравляем вас с отличным выступлением и проходом в финальный раунд. Я свяжусь с вами в ближайшее время для того, чтобы уладить формальности. Пожалуйста, не игнорируйте мои письма =)
UPD4 Доступны материалы второго тестового раунда: Тестовый раунд 2; Материалы







В чём смысл давать очки лучшим 4-ём участникам раунда, если они всё равно в финал пройдут?
Чтобы была меньше разница (а значит и больше борьба) между следующими позициями. Если выдать пятому месту 100 очков, то его отрыв будет 20, а значит догнать очень сложно. Сейчас занявший пятое место получит 45 и будет всего в 5 баллах от шестого места.
Если я правильно понял, alexyz писал о том, что бессмысленно считать очки занявших 1-4 места, можно было давать баллы участникам, занявшим 5+ место, например, оставив эту же систему, вычеркнув в ней первые 4 места, в них можно записать что-то вроде "проход в следующий раунд" или "Infinitive". Взяв вашу систему за основу можно получить что-то вроде этого Мой вариант таблицы
А как же составить общую таблицу результатов всех участников отборочного этапа? Финалисты вполне заслуживают место в общем рейтинге =)
Из правил:
Лидеры первого и второго раундов могут продолжить участие в отборочном этапе,но их результаты уже не учитываются при определении остальных финалистов.Это значит, что они не получают очки за участие по системе гран-при 30 или все равно получают, но это ни на что не влияет?
Это значит, что все участники, занявшие в любом из раундов отборочного этапа места с 1 по 30 получат очки (по ГП 30). Однако из второго и третьего раунда приглашения в финал получат 4 лучших из еще не приглашенных в финал.
Т.е. есть смысл продолжать участвовать, пройдя в финал чтобы кому-то помешать набрать баллы? :)
Фу, зачем так грубо. Конечно потому, что хочется порешать задачки в соревновательной обстановке ;)
да и отстоять свое отличное место в общем зачете отборочного этапа!
Из поста:
Все финалисты, 75 лучших участников отборочного этапа, не прошедших в финали 75 случайно выбранных среди решивших в отборочном этапе хотя бы одну задачу участников получат футболки Яндекс.Алгоритма!В то время как в правилах:
Все участники финального раунда получат футболки с символикой конкурса.Их также получат 75 не прошедших в финал участников с лучшими результатами по сумме всех раундов отборочного этапа.Я так понимаю, что организаторы решили увеличить кол-во подарочных футболок с 100 до 175.
Если мое предположение верно, то возникает еще один вопрос:
и 75 случайно выбранных среди решивших в отборочном этапе хотя бы одну задачу участников получат футболки Яндекс.Алгоритма!Следовательно, 75 дополнительных футболок будут рандомно распределятся среди тех, кто решил хотя бы одну задачу во всех отборочных раундах (за исключением финалистов и 75 лучших отборочного этапа) или же хотя бы одну задачу в одном из отборочных раундов? Как я понимаю, отборочный этап охватывает все отборочные раунды, поэтому, более логичен второй вариант. Все верно?
Все верно, в одном из прошлых анонсов было также написано, что количество призовых футболок увеличено.
75 футболок будут распределяться среди тех, кто решил хотя бы одну задачу в отборочном этапе (раунд 1 + раунд 2 + раунд 3), но еще не получил футболку.
пытаюсь отправить задачу
пытаюсь написать по этому поводу жюри
и такое во всех браузерах
Аналогично.
И у меня.
+1. Великолепно, да..
Аналогично.
Аналогично. И как же донести это до организаторов?
Мы работаем над проблемой, спасибо
И у меня.
Приношу свои извинения. Используйте
http://contest.yandex.ru/contest/Contest.html?contestId=308&tab=submit
До сих пор(
I apologize for the problem with the submission link.
If you receive the decline response from server use the link below
http://contest.yandex.com/contest/Contest.html?contestId=308&tab=submit
There was also a problem with sending questions to jury. I wasn't able to send it: 'There was an error. Pleaes try to send your question once again.'
Ну и гадость эти яндексовские тестирующие сервера... Код, залетающий на моем старом ноуте 2009 года выпуска в секунду, ТЛится при таймлимите в 2с.
Круто вам, у вас тесты есть.
Задача C, решение за O(cnt^2 * k), где cnt — количество делителей n. Макстест — очевидно,
901800900 50(это число есть произведение квадратов первых 6 простых чисел).Наибольшее число делителей у числа
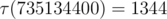
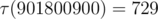
735134400:Разница почти в два раза.
Я вынужден признать свою неправоту :).
Моё решение этой задачки говорит, что макс тест это 735134400 15. P.S. Упс, опередили.
Самое обидное, что макс тест у меня летает. Но на контесте все равно был ТЛ 21
Если делители проверяются перебором всех чисел, то для случая когда остался один делитель (k=1) нужно проверять является ли квадратом оставшееся частное.
Потому что у меня тоже был TL на 21-ом тесте. И был он из-за того что в случае k=1 мое решение проверяло в качестве делителя все числа до n, хотя достаточно просто проверить что n не является квадратом.
Пример теста на котором TL 1 1000000000 1
upd. по условию k>1, но можно взять 1 1000000000 2
Will it be unrated?
it is unrated initially
what a comedy
Some participants can't submit problems for first 30 minutes.
I'm trying to submit a problem after the contest (for practice). I get the error message "You can send only UPSOLVING submission after contest end". Anyone know what I'm doing wrong?
You should submit using the new interface to get upsolving, so if it doesn't work as it doesn't for me — you're out of luck :)
petr i love you :*
Why does this comment have so many upvotes? :P
Because of everyone loves Petr :*
Как решать задачи С и В ?
В C ответ YES тогда и только тогда, когда выполнены оба условия:
Правка
n оба раза не является степенью простого.
А, не понял сначала, что n — это n из условия, а не новое обозначение. Спасибо.
Задача B: надо просто перебрать клетки змейкой: первый ряд слева направо, второй справа налево, и так далее. И первую клетку отправить в первое герцогство, следующие две — во второе, следующие три — в третье, и т.д.
А у кого-нибудь с таким же алгоритмом было WA12? Лень тестов ждать)
Было. Хз почему=(
Попробуй тест "2 4"
Может быть, непорядок с цветами? Я просто для каждого герцогства выбирал минимальный цвет, который ещё не использован в предыдущих герцогствах, граничащих с ним.
Я так же...По крайней мере, если багов нету
Ты это делал дфсом или циклом? Дфсом точно правильно, а циклом не уверен.
у меня в итоге было как чуть ниже говорят. Не очень вижу разницу между дфс и циклом, если нужно всего лишь пробежать заданное число клеток и проверить 4-х соседей.
Может быть буквы у соседей совпадают? Попробуй, например, тест 351 2, там в первом ряду все буквы от A до Z.
Возможно не учитывали, когда в конце осталось меньше буковок, чем нам надо, их необходимо добавить в последнее герцогство?
Тогда бы и первый тест не прошел...)
Есть забавный тест "1 2".
О, ниже говорят про WA12 при попытке использовать 2 цвета.
у меня wa 12 был из-за того, что когда я выбирал цвет(просматривал все граничащие клетки), я не учёл максимально k (k*(k-1))/2- вот это k, что оно не доходит до последней клетки поля (угла), ещё остается добавить клетки, и я не проверял до конца, смежные с ними. извиняюсь, если криво объяснил)
У меня выдавало такое WA 49. Посчитал, что не учел всякие случаи вроде 2 200 (нижний ряд А-шек соприкасается с верхним рядом А-шек). Но учет этого не помог. У вас прошло без всяких впихиваний и я просто где-то набагал?
А если у нас осталось N клеток, а начиная со следующей мы хотим покрасить M клеток, то ведь надо проверять, что M+M+1<N. Тогда надо красить уже не M следующих клеток, а "до упора"?
Ну да, естественно.
В B ответ — максимальное k, такое что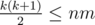 . Чтобы построить пример, развернём поле так, чтобы высота была не меньше ширины, затем нарисуем на нём спускающийся зигзаг (по первой строке вправо, по второй влево, по третьей вправо и т. д.) и будем заполнять его по порядку: 1, k, 2, k-1, 3, k-2, и т. д. Буквы назначать по циклу, четырёх букв должно хватить.
. Чтобы построить пример, развернём поле так, чтобы высота была не меньше ширины, затем нарисуем на нём спускающийся зигзаг (по первой строке вправо, по второй влево, по третьей вправо и т. д.) и будем заполнять его по порядку: 1, k, 2, k-1, 3, k-2, и т. д. Буквы назначать по циклу, четырёх букв должно хватить.
Есть ли у вас доказательство, что четырех букв должно хватить? Я не могу это доказать даже для 26 букв :)
Доказательство теоремы о 4 красках длинное :)
Для конкретного случая можно попробовать построить. В первую строку ставим только A и B (кроме, возможно, последнего в строке), во вторую (и хвост первой) — только С и D, дальше опять A и B, и так далее. Как-то так. Должно быть так, но мои решения при этом почему-то используют 5 букв :)
Вот такое ваше доказательство не пропустит?
Какое мое доказательство?
Мое построение будет рассматривать всех по очереди и ставить каждый раз минимальное из невстречавшихся среди соседей. И ничего такого не пропустит. При этом про 6 букв я могу именно что доказать (в каждой строке достаточно использовать не больше трех), про 5 — я верю, а 4 почему-то у моего решения не получается.
Ну я про попытку построения для 4. В общем, не важно.
Трех хватило. Двух нет — WA-12
B: 1) Распределим земли: 1, 2, 3, ... k. Останется некоторый хвостик, меньший k+1. Откусим от этого хвостика по единице и дадим ее с конца другим. Например nm = 12, то 1,2,3,4,[2] => 1,2,3+1,4+1. Назовем полученный массив partSize[k]. 2) Перемешаем partSize следующим образом: [0][k-1][1][k-2].. и т.д. Для примера выше получим 1,5,2,4. 3) Заполним прямоугольник змейкой, буква = partIndex % 26, согласно рассчитанным размерам. Если n < m, то заполняем вертикально, иначе — горизонтально. Строго доказать не могу, но тесты проходит.
Могу сказать идею доказательства. Заметим, что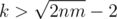 , если n ≤ m, то
, если n ≤ m, то 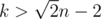 . Теперь заметим, что сумма двух соседних длин не меньше k + 1, значит, если между двумя элементами хотя бы 4 элемента, то они точно разделены.
. Теперь заметим, что сумма двух соседних длин не меньше k + 1, значит, если между двумя элементами хотя бы 4 элемента, то они точно разделены.
Альтернативное решение C: динамика dp[k][p] — можно ли набрать k чисел, не являющихся квадратами, p — сколько каких простых делителей N при этом использовано (маска, по сути число от 0 до кол-во делителей N). Переход — перебираем какое будет следующее число. Работает 0.380 с.
http://likecode.ru/code/51e3ba7620adb/ Вот такой перебор на Java работает 0.143 с.
Кто-нибудь сталкивался с проблемами в 4-м тесте в B?
Спасибо Petr'у. "1 2" помогло
Кто-нибудь понял, где можно дорешивать?
Также снизу у задачи есть кнопка "Отправить"
Дорешивание возможно только с использованием нового интерфейса. Мы сейчас решаем проблему с тем, что у некоторых пользователей новый интерфейс ведет себя некорректно. Приношу извинения за неудобства
Может будет полезно: в Опере 11.10 получается отправить в новом интерфейс, а в Firefox 22.0 — нет.
я так понимаю, что дорешивание вообще не работает сейчас?
Попробуйте сейчас в новом интерфейсе.
У меня получилось отправить через старый интерфейс изменив возможные варианты выбора в дропдауне "submission type" через Chrome Developer Tools. Вместо usual я сделал опцию с value="UPSOLVING"
Попробуйте сейчас в новом интерфейсе.
Можете подсказать по B: локально моя программа на python на самом большом тесте 1000 х 1000 у меня работает 1.7 секунды, но на сервере валится по TL на 49 тесте. Может быть есть какой-то хитрый тест?
Всего тестов может быть 1000 * 1000, в чем проблема их сгенерировать и сразу по запускать?:)
Сервер может медленнее работать.
Тогда выбор python был ошибочным. Печально, раньше задачи не очень зависили от выбора языка программрования.
Да, в квалификации все задачи сдавались на всех языках. В первом раунде — уже, скорее всего, нет. К сожалению, представленные языки слишком разные, и не для всех задач можно гарантировать, что разумные решения на всех языках проходят, а лобовые — нет.
Обычно гарантируется существование решений на основных языках (нынче это C++ и Java), успевающих отработать за половину отведённого времени.
Если уж говорить про гарантии, то я очень сомневаюсь, что для вчерашней задачи Е гарантируется существование решения на Java, укладывающегося в ТЛ 5 секунд.
Откуда инфа? А оттуда, что я сейчас мучаюсь с проталкиванием чистого O(n * log n).
Я готов поспорить, что решение на самом деле O(n sqrt(n) log n)
Это достоверная информация, или Вы тупо меня сейчас троллите?
Информация к размышлению — dfs работает за число ребер, а не число вершин
Я не имею доступа к решениям этого контеста (по крайней мере на данный момент — меня забыли зарегистрировать как judge'а)
На что Вы намекаете первой частью? На то, что я написал лобовое решение с ДФСом и думаю, что оно работает за n * log n?
Ок, признаю, один я такой дебил. Можно тогда на решение посмотреть?
Пожалуйста. Здесь монструозная штука, работающая за O((q + sum_k) * log q). Здесь дебильное решение за O(q * log q * log n + sum_k * log n), которое на первых семи тестах работает быстрее первого.
Написал на Java за O(Q * log Q * log N), пропихнулось за 4.99 сек (код).
А как решать за n log n?
Да, библиотека хорошо реализованных стандартных алгоритмов решает :).
Решение за O(Q * log Q) есть модификация решения за O(Q * log Q * log N). Забудем вообще про DSU, и для запросов на отрезке [l; r], передаваемых в рекурсивную функцию, будем хранить не вершины, а компоненты связности, в которых они лежат. При спуске в половинки отрезка добавляем нужные ребра в наш уже сжатый до компонент связности граф, после добавления всех ребер проходимся ДФСом по затронутым компонентам и помечаем, в какую результирующую компоненту они сожмутся (по ходу дела также вычисляем ее размер). Далее проходим по отрезку, в который мы спускаемся, и поправляем номера компонент (в соответствии с тем, как мы все сжали). Разумеется, после возврата из рекурсивного вызова все откатываем.
Ссылка на такое решение, разумеется, криво реализованное :), есть чуть выше.
P.S. Эту идею я очень кратко услышал от Нияза, а потом домыслил до вышеописанного.
Круто. Авторское решение такое — сопоставим каждому ребру случайное число. Тогда для каждой вершины будем хранить xor всех инцидентных ребер. Проверка на условие — xor всех значений вершин — 0
Интересное решение :).
Кстати, если не секрет, кто автор?
Zobrist :)
На Java у меня совсем впритык прошло, 3.32 с. с 64битным Зобристом. http://likecode.ru/code/51e4312c105de/
Это потому, что ввод медленный
Да, спасибо, замена получения случайного 64-битного на Random.nextLong() дает 0.2 секунды выигрыша, и StreamTokenizer еще почти секунду, итого с двукратным запасом по времени — 2.17 с.
Вот код по B на Python2, который работает менее секунды.
Как решалась D? Я писал следующие: заведем 3 массива g[], s[], t[]. g[i] — кол-во золотых на уровне i, s[i] — серебряных, t[i] — кол-во стопок высоты i. Далее для i=0,1,..,MAXN выполним g[i] = min(g[i], g[i-1]), s[i] = min(s[i], s[i-1]). В тех i, где s[i] != s[i-1], можно говорить что существует s[i-1]-s[i] серебряных стопок высоты i (которые сверху возможно имеют что-то ещё). Аналогично для золота. Кинем эту информацию в map: высота -> количество. Теперь перебираем высоты исходных столбиков t[i], для каждого столбика ищем в map наименьшую подходящую стопку. Это ВА 5 ( P.S. Это решение зашло ( Напутал с индексами немного.
Я перебирал с самых длинных строчек, если можно сделать золотой делаем золотой, иначе если можно серебряной. Хранил просто кол-во. g[i], s[i], — количества на высоте i
Так такое решение работает за O(nlogn). У меня на JAVA TL за такое решение (
Зачем n * logn? Можно же предпосчитать минимум на префиксах и хранить кол-во уже собранных столбиков.
"Я перебирал с самых длинных строчек..." — это значит, что столбцы сортировались по длине, что и есть nlogn
Нам же важно сколько S/G на каждом уровне суммарно и сколько столбцов заданной длины. Ничего не нужно сортировать.
Я понимаю, что существует решение за O(n), и которое не использует сортировку. Но в данной ветке речь идет о решении, которое предложил riadwaw, и я предполагаю, что в нем использовалась сортировка.
Длины <= 1000000. Видимо их можно сортировать подсчётом.
У меня на Java сортировка длин стандартным Arrays.sort никаких проблем не вызвала.
делал так: Arrays.sort(s, new Comparator() { public int compare(String a, String b) { return a.length() — b.length(); } }); потом все линейно
Merge-sort + постоянные вызовы функций длин строки сильно портят константу.
Даже создание миллиона объектов String может занимать существенное время, не говоря уже о том, что при чтении могли создаваться дополнительные объекты. Кроме того, при сортировке массивов объектов sort создаёт дополнительные массивы. Я сразу записывал в массивы количество монет на различных уровнях, а длины держал (и сортировал) в массиве int'ов.
Как ты избежал создания строк? Читал все побайтово из стрима?
Да, обычное дело — создать BufferedReader (или BufferedInputStream) и читать посимвольно.
Отправил на Java 7 — AC Во время соревнований отправлял на Java 6 Обидно (
Да, я в тупую сортировал строки на Java. Решение
Отправлял на Java 7?
Да.
Из-за отстойных компиляторов не хватило 2 минуты. Как заставить работать конструкцию (С++)
Добавить в начале программы:
?
Думаю, что тут могут быть две проблемы:
1) В scanf не надо писать & перед s, так как s — это как раз указатель на место, куда положить считываемую строку.
2) Массив s лучше делать глобальным, так как может не хватить стековой памяти.
В общем дело точно не в отстойных компиляторах, а именно в отстойном коде, который ты пытаешься им скормить :)
Можно написать & перед s — это никак не повлияет на результат.
Это приведет к undefined behaviour и потенциальным новым жалобам на компиляторы.
Ну и к тому же, вот с такой конструкцией уже повлияет
UPD: Хотя о том, что написал rinigan, я раньше не догадывался и до этого никогда не пробовал :)
Для начала неплохо было бы изучить, что такое массивы, указатели и C-строки.
Компиляторы — они такие. Компилируют не то, что решает задачу, а то, что написано.
(По теме уже ответили: нужно писать
scanf("%s", s);вместоscanf("%s", &s);.)Yesterday I wait for the start at http://contest.yandex.com/contest/ContestList.html site, I was logged in and this site was in english. After the start the problems appear in russian, I looking for a button to switch english, but I didn't find.. So I went to the codeforces site and find a link http://algorithm.contest.yandex.com/contest/308/problems/ , it works fine, and here is a button what I looking for to switch english..
Is there any option to switch in english in the first site? Why do you have two different site? I'm just courious :)
That's old interface, it is not supported
Thank you!
Подскажите, когда материалы и тесты по раунду будут доступны? Спасибо.
Материалы раунда теперь доступны для скачивания (осторожно, 200 МБ)
http://yadi.sk/d/LKa4GSI36uPtf
Под предлогом того, что с моего IP-адреса или из моей сети осуществлялись массовые нарушения пользовательского соглашения, Яндекс не дает мне скачать архив и выпрашивает у меня мой номер телефона.
Сделал логаут — все сразу скачалось.
Какими словами стоит это называть? :)
I wonder how to decide another 75 best participants. Grand Prix 30 only affect top 30 , so only 30*3=90 top participants can get positive score at most. Therefore this system is not enough to decide top 100 who get T-shirt.
There are also another two scoring criteria: number of solved problems and penalty time.
Well, there is a flaw in this scheme :). I mean that these criteria are incomparable when applied to different contests.
UPD. Yes, I've made a mistake. We don't compare them directly, but their sum.
А что означают красные крестики напротив участников в таблице результатов?
несовершеннолетние участники или участники, отказавшиеся от участия в финальном раунде.
Is this contest for public???
Yes, you are welcome to participate. Page http://algorithm.contest.yandex.ru/contest/319/enter/ will guide you through registration process
"Чтобы убедиться, что новый интерфейс ведет себя правильно, мы приглашаем всех желающих принять участие в тестовом раунде 2, который начнется сегодня, 16 июля в 19:40 и закончится в 21:00"
Можно ссылку на раунд, или она будет потом? Просто тут ее нет.
Ссылка на тестовый раунд 2 теперь доступна
http://algorithm.contest.yandex.ru/contest/319/enter/
Спасибо, но мне пишут:"You aren't allowed to view this page".
прошу прощения, теперь должно работать
Работает. Спасибо.
У меня появилось небольшое замечание. У вас два места из которых можно попробовать получить обртную связь, но одно, похоже, по системе, а второе уже по контесту. Мне кажется, что стоит как-то их обозначить. Просто я читал условие, читал тесты; у меня появился вопрос. Смотрю, а там рядом снизу "обратная связь". Ну я на радостях туда и задал вопрос, потому что это было рядом с условием) Потом только увидел и сверху вкладку сообщения, из которой, оказывается, тоже можно задать вопрос. Вот такие пироги.
Мы собираемся доделать возможность задать вопрос прямо со страницы задачи, на которой вы читаете условие.
А можете сделать, чтобы вместо дефолтной явы, язык изначально не был выбран?
Может быть последнее отправленное решение (возможно в прошлом туре) было на яве?
Я каждый тур на питоне писал и в этом туре у меня сразу питон был выбран.
нет, не было
Как делать новые Неквадраты?
Особенно случай, когда N=a^b, где a — простое.
Меня больше волнует почему для n=7 и к=2 ответ YES. Я видимо неправильно понял условие)
Там же написано — целых чисел. А не "целых положительных". (-1)*(-7).
Ахах, неожиданно:)
Тогда там NO тогда и только тогда, когда n квадрат, а k нечетно?
UPD Ошибся.
Ответ НЕТ только если n = 1 и k — нечетное или k = 1 и n — квадрат.
Сейчас проверил. Как раз последнее условие не учел во время решения...
Да. Я уже понял =)
Только k != 1 по условию
Заметим, что если тест имеет вид 1 2k+1, то ответ NO (количество сомножителей нечётно, и все -1 не пройдут).
В остальных случаях ответ YES.
Если тест имеет вид n 2k, то представляем в виде произведения 2k отрицательных чисел.
Если тест имеет вид x 2k+1, где x — неквадрат, то представляем в виде произведения x и 2k по -1.
Наконец, в случае n^2 2k+1 находим наименьший простой делитель n^2 — p, представляем в виде p*-(n^2/p)*-1, далее 2(k-1) по -1.
Блин. Просто же. Спасибо.
Задача на внимательное чтение условия. Попробуйте с этим хинтом подумать еще)
UPD. Не успел
В новых неквадратах нет ограничения на знак множителей. А отрицательное число не является квадратом целого числа. Поэтому нельзя представить в виде произведения только в одном случае. k-нечетное и n=1. Если k четное возьмем первый множитель равный -n, а остальные равные -1. Если k нечетное, то первый множитель любой простой делитель n если n>1 (простое число не может быть квадратом), второй — минус n деленное на этот делитель, остальные -1.
Я в последнее мгновение тоже догадался до этого, но смутила одна вещь. Что если n — полный квадрат, а k — нечетное? Попробуйте числа n = 256, k = 3. По вашему алгоритму выйдет -1 -1 256, а это не ок. Причем, если начать брать корень из 256 — тоже ничего хорошего не получится (-16 -16 1, -16 16 -1, -16 -4 4 и т.д. не подходят). Зато подходит 32 -8 -1.
В любом случае, if (n == 1) return k % 2 == 0; return true; проходит тесты, но вот с обоснованием корректности в случае квадратного n не все так тривиально.
По моему алгоритму 2, -128, -1
Ответ НЕТ только если n = 1 и k — нечетное или k = 1 и n — квадрат.
Сейчас проверил. Как раз последнее условие не учел во время решения...
По условию k>1 Если k четное и n==1, то все множители равны -1. Правильное решение — "NO" если k нечетное и n==1
Постараюсь объяснить еще раз. У любого числа большего единицы есть простой делитель. Обозначим его p. Простое число не может быть квадратом. Значит в ряду множителей p, -n/p, -1, .... нет ни одного квадрата, так как отрицательное число так-же квадратом быть не может. Их произведение равно n. Это для нечетных k.
Для четных возьмем просто -n,-1,... Их произведение тоже равно n, и так как все множители отрицательные — они не являются квадратом.
В задаче Стикеры со второго тестового раунда написано, что TL — 2 секунды, хотя у меня на джаве решение получило AC со временем работы 2,56с, а до этого решения ТЛились после 4с работы. Для джавы отдельно выставляются ТЛ (о которых не пишут в условии задачи) или это просто забыли в условии изменить ТЛ на такой, который стоит в системе (4 секунды)?
TL стоял 2с, для Java6 и Java7 — 4с. В частности, это было сделано для того, чтобы оттестировать раздельные таймилимиты. Соответствующая информация (о том, что о наличии таймлимитов по отдельным языкам система не сообщает участникам) доведена до разработчиков.
Внимание! Примерно через 35 минут начинается раунд 2!
Решил написать, так как мне, например, не приходило письмо с напоминанием
Уточните, пожалуйста, приходило ли вам напоминание о отборочном этапе?
Приходило про отборочный этап в целом и про первый отборочный раунд.
У меня такая же ситуация.
Это всё, что пришло: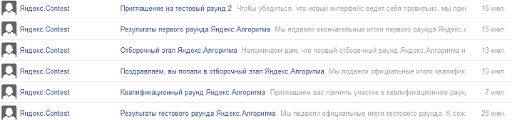
Папка спам пуста.
Вам кажется предпочтительным получить около 7 писем (об отборочном этапе, 1 раунде, результатах 1 раунда, 2 раунде, результатах 2 раунда, 3 раунде, результатах 3 раунда + результатах всего этапа) для трех раундов за 8 дней?
Ну если приходило письмо о каждом раунде до этого, то вполне логично ожидать, что придет и про следущий.
А зачем присылать результаты после каждого раунда? Люди которые прошли в финал (а их всего 4 человека) и так это понимают. Мне кажется, что достаточно письма про результаты всего отбора.
[Удалено]
Нужно читать правила внимательнее
Как решалась А из раунда 2? Я предположил , ответа Multiple быть не может, но ва 13 так и не смог преодолеть
На 13-ом тесте как раз первый раз нужно ответить Multiple.
А вот я словил WA 62. Я один такой?)
нет....
Этот тест мне помог от WA62:
10
3 3 3 3 1 1 1 1 1 1
Ответ : Multiple
Ответ Unique тогда и только тогда, когда:
Естественно, это описан выбор между unique и multiple, еще надо сумму проверить, чтобы не было none
Странно, что в задаче такие ограничения. Авторы не придумали это решение?
На tc часто бывают задачи с полиномиальным решением и ограничением порядка 10. Наверное, чтобы запутать.
Или чтобы любое разумное полиномиальное заходило независимо от степени. Не всегда хочется выжимать из задачи "а вы вот только обязательно все соптимизируйте насмерть"
На одном из моих раундов в одной из задач ограничения были умышленно снижены для того, чтобы усложнить задачу.
Я в начале пытался выводить какие-то явные условия и получал ВА 62. Потом забил и сгенерил 20 рандомных деревьев, посчитал от них хеши и если есть хотя бы 2 различных — выдавал Multiple, иначе Unique.
А как по степеням вершин генерить рандомные деревья?
Берем листок, цепляем за случайную вершину степени больше 1, после чего удаляем этот листок и уменьшаем степень той вершины. Повторяем до тех пор, пока не останется всего 2 вершины.
Спасибо) А как потом хеш считать от неподвешаного дерева? Или вешать за оба центра, и сравнивать нормализованную пару хешей?
Я делал так. Изначально поставим хеши всех вершин равными их степеням. Потом N раз повторим такое. Берем каждую вершину, дфсим от нее и записываем в вектор пары (хеш, расстояние) до всех остальных вершин. Потом сортим этот вектор и как-то пересчитываем хеш для текущей вершины (только заносим это в новый массив). В конце итерации заменяем старые хеши новыми. В самом конце сортируем массив хешей и считаем один хеш для всего дерева.
Как решалась F? сначала попробовал взять остатки от деления на 2 но потом понял что будет WA на тест 2 1 0 RBG
Я сказал, что больше трех не надо, оставил максимальное с такой четностью, не большее трех. И перебрал все.
Идея с остатками от деления на 2 правильная. Просто надо брать не прямо остаток, а достаточно большое число (при этом не более изначального, естественно) с тем же остатком, но при этом чтобы заходила кубическая динамика. 50 хватает точно, скорее всего хватает гораздо меньшего числа
Спасибо, а можете код показать?
Ну я взял почти остатки по модулю 2 — если оно <20, оставить как есть, иначе взять 18 + x mod 2. Прокатило :) Во время контеста не доказывал, но должно быть несложно.
Если хоть один шар не на своем месте, и с его местом нет обменов — то ответ No Если хоть один шар на своем месте, и с его местом ровно один обмен — то ответ No Теперь если четность перестановки шаров совпадает с четностью суммарного количества обменов, то ответ Yes, Иначе no.
Только что зашло перебором, без динамики. Брал остаток от деления на 6 для всех (подозреваю, что можно было и на 4).
Вам просто повезло, вот анти-тест:
1 0 6
BGR
Ответ — Yes
А если бы Вы взяли остаток от деления на 4, то получили бы WA на 133-м тесте
Да, спасибо, туплю.
Где можно посмотреть тесты для 2-го раунда?
Их опубликуют позже.
Не стыдно такой махровый баян давать? (Это я про C)
Утверждение про махровость бояна без ссылок не засчитывается
Тимус. То же самое, разве что на тимусе требуют посчитать минимальную сумму высот, а здесь — сумму всех площадей треугольников (грубо говоря, на константу домножить).
Я пока не умею переводить одну задачу в другую, если честно
Да вроде бы одно и тоже.
Будем перебирать основание треугольника (яндекс) или искомую прямую (тимус). Фиксируем одну точку, остальные сортируем по углу и крутим сканирующую прямую. Формула для высоты, как известно, — abs(ax + by + c) / sqrt(a*a + b*b). Площадь — то же самое, но еще домножить на основание. Чтобы найти сумму всех высот, вместо того, чтобы суммировать по всем вершинам этой формулой, можно предпросчитать суммы x и y, зная, что все, что с одной стороны от прямой надо брать с плюсом, все, что с другой — с минусом.
Я помню такую задачу на ПТЗ. Вроде даже не один раз.
Было как минимум на одном ПТЗ и на одном Opencup, мне не очень хочется в 4 утра перебирать архивы чтобы найти точную ссылку :)
http://acm.math.spbu.ru/~snark/files/oc6/gp1/problems-e.pdf Problem B
Да, вот это уже точно она. Извините, не нашли.
Тем не менее, не думаю, что это сильно повлияло на результаты. Ветераны, участвующие в соревнованиях уровня Opencup как минимум с 2009 года, скорее всего, в любом случае решают такую задачу не очень долго.
Решают быстро, упихивают долго :-)
Наверное. Я на Питоне даже не пытался.
Я правильно понял из этого коммента, что fetetriste упихивал задачу на питоне?
По-моему 106 операций (да еще и помноженное на логарифм) в принципе не может упихаться на питоне.
Видимо, из этого коммента надо было понять, что Gassa писал авторские решения к другим задачам на питоне, а вот к этой не писал. Как я понял, тут честное решение (в BigInt) многим на яве-то упихивать пришлось, какой там питон!
Да, всё так.
А как его нормально сдавать? Я с трудом упихнул за 1.4 сек на Java
Я забил и на плюсы переписал
У меня 1.02с
Эээ, а чего тогда ТЛ 2с, а не 3? Или там есть другие решения жюри на Java?
Я думаю, что есть — я именно прорешивал в боевом режиме, а не писал авторские решения к задачам
Посмотрел своё — 1.92с , лол :)
Отдельные лучи ярости авторам за то, что мне так и не удалось пропихнуть правильное решение с BigInteger, и задача сдалась только после того, как ответ стал вычислять в даблах.
При этом это, очевидно, падает по точности на тесте вроде
но у авторов такого теста не было.
Вроде не должно падать.
Ответ приблизительно 10^18, дабл хранит 15 знаков, поэтому ошибка < 10^4 и относительная ошибка < 10^4 / 10^18 = 10 ^ (-14).
P.S. Я ступил.
Ответ на этом тесте 0.5, а абсолютная погрешность в вычислениях с числами порядка 10^18 несколько больше.
Тогда интересно есть ли у авторов решение, какое проходит этот тест и пропихивается в ТЛ.
Почему-то мне кажется, что если бы авторы задумывались о погрешностях в решении, то они бы и тест такой добавили.
Скорее всего, имеет место классическая комбинация "неверное авторское+слабые тесты"
Да, стоило сделать, например, координаты до 10^6 для одинаковой сдаваемости на C++ и Java. Приношу извинения, вовремя не дошло.
Тут речь идет не о преимуществах языков, а о том, что авторы зачем-то позаботились о том, чтобы пришлось заниматься пропихом, но при этом не сделали тестов против действительно неправильного решения.
У меня есть подозрения, что такой баг есть у значительной доли сдавших задачу.
Совершенно понятно, зачем авторы установили столь жесткие ограничения — чтобы не прошел куб. Плохо, что при этом была допущена такая ошибка
Как ограничения на координаты отсекают куб?
Сорри, я имел ввиду ограничения на n естественно
Да, ты прав :( . Я завалил своё тестерское решение по точности. Провозился некоторое время, потому что именно в таком виде завал не происходит: единственную проблемную строку
res += a[j].y * sumx - a[j].x * sumy;компилятор GCC втихаря вычисляет в long double. При этомlong double, конечно, хватает.В авторском решении на C++ то же самое: точно такое же выражение неявно считается в
long double, а потом записывается в типdouble.А аналогичное решение на Java проходит уже именно из-за отсутствия тестов на точность.
:(
Ограничение 106 или 105 на координаты бы, тем не менее, помогло.
Ага-ага, да ещё и не упихивающийся на джаве, если писать не очень аккуратно :(
Я нашёл только две похожие задачи (минимальная и максимальная площадь треугольника), каждую в двух инкарнациях. Именно суммы или математического ожидания площадей не видел. Кроме того, в моём решении векторные произведения, а не высоты — которые, казалось бы, нужны в задаче с Тимуса по указанной в комментариях ссылке.
В общем, действительно было много задач с похожим набором идей (выберем точку, отсортируем по углу, сделаем ), но, как мне кажется,
), но, как мне кажется,  не настолько простая часть, чтобы эту из-за них не давать.
не настолько простая часть, чтобы эту из-за них не давать.
Выше дали ссылку на задачу с opencup, в которой ответ будет такой же с точностью до константы (зависящей от n).
Расскажите, пожалуйста, решение C.Зеленый треугольник. А то я спать не буду((
Нам надо посчитать сумму площадей всех треугольников. Будем брать каждый раз самую левую точку, сортировать по углу относительно нее, после чего можно избавится от модуля в формуле площади треугольника. Осталось пройтись, подсчитывая сумму x и y сверху вниз
Спасибо, помогло, классная задачка :)
I submitted only 1 problem of blind type in Round 1, it failed by int overflow.
Today, I also submitted only 1 problem of blind type in Round 2. Guess what? It failed by long long overflow. (problem C: if we sum the areas up, it will exceed long long) :(
Maybe only "All open" strategy is good for me.
Помогите разобраться в задаче F, закинул следующий код http://ideone.com/mYsNhN, на втором тесте естественно выкинул TLE, но дошел до 123 и выкинул WA. В чем моя ошибка? (Кроме той, что надо числа сокращать).
Расскажу, как решается B. Решение мне показалось достаточно простым.
Заметим, что последовательность высот кочек имеет период p - 1. Также заметим, что функция "номер кочки -> усталость лягушки на этой кочке" одинаковая для всех лягушек, а остаток от её деления на m имеет период (p - 1)m. Составим вектор "номер кочки -> 1, если прыжок лягушки с этой кочки приведёт к прыжку следующей по счёту лягушки, иначе 0" и посчитаем его частичные суммы. Теперь мы можем вычислять функцию "лягушка сделала i прыжков с начального положения, сколько прыжков сделала следующая по счёту лягушка" за O(1). Соответственно, по координате первой лягушки определяем координату k-й за O(k). Осталось сделать двоичный поиск по ответу.
А если лягушка не прыгала, и осталось на %m-ой координате, то следующая прыгает или нет?
Если лягушка не прыгала, то и следующие тоже не прыгали. Это непонятно из условия, но понятно из семпла.
Ну вот кривое условие :) Так бы сдал.
И объясни почему в первом сэмпле не 13. Вроде бы функция просто X/2 , и 13/2/2 = 3. что вполне подходит
Начальная усталость равна 1, поэтому функция на самом деле ⌈ X / 2⌉.
Bug Report. Я субмитил задачу F и получал по ней TL на семпле. Система вела себя так. Она тестировала задачу на всех тестах пока не упадет где-то не на семпле. Когда, она падала на таком тесте, мне отображалось TL2. Но когда я нажимал отчет, то было видно, что был еще WA на каком-то большом тесте.
Просьба: или сделать запуск, или тестировать на семпле, а если падает, то не считать это попыткой.
Спасибо за сообщение! Будем чинить.
I want to know where I can find the solution to a problem.Some question I have not thought.
Will you make editorial for these rounds, or possible to see other contestants solution?
Когда будут доступны материалы 2-го раунда? Третий уже завтра, а я так и не знаю где накосячил в халявках. (F & D)
UPD: Спасибо за помощь, сплошные описки.
В D у вас деление целочисленное, а в условии про это жирным написали.
z — целое, значит x делится на y, и при делении нацело получается z. Или я что-то не так понял?
Да ошибся, у вас там еще одна проверка.
В D лишний else, тест
1 0 1В F числа на входе в порядке p,q,r, а не p,r,q.
В задаче A формула такая ans=sum_of_negatives/(number_of_negatives)+sum_of_positives/2 ? У меня WA 3 все время, думаю из-за точности.
Те кто минусуют, может подскажете формулу?
Сумма ряда кол_неотрицательных/кол_всего + кол_неотрицательных/кол_всего * (кол_неотрицательных-1)/(кол_всего-1) + кол_неотрицательных/кол_всего * (кол_неотрицательных-1)/(кол_всего-1) * (кол_неотрицательных-2)/(кол_всего-2)... Умноженное на среднее неотрицательное, и к этому прибавить среднее отрицательное.
спасибо
О мой бог, нет!
Это же просто (сумма_положительных)/(кол-во_отрицательных+1) + среднее_отрицательное. Если нет ни одного отрицательного, то их среднее считается нулём.
Это ты сумму ряда посчитал.
Нет, я сразу вывел такую формулу, именно так, как снизу написал Petr.
Это как раз понятно. Выводить из ряда — смысла ноль, проще цикл написать.
Да, это верно.
Кстати логично. Каждое положительное будет съедено с вероятностью 1/(кол-во отрицательных+1) (это вероятность того, что оно окажется первым из него и всех отрицательных).
Спасибо. Я думал так. Если есть N положительных чисел, то из них можно составить 2^n subset-ов, включая нулевой. Сумма всех этих subset-ов = 2^(n-1)*(сумма положительных), тогда для каждого негативного числа(последней сьеденной конфеты) среднее арифметическое всех возможных последовательностей = (сумма положительных)/2+a. Тогда формула будет ((число отрицательных)*(сумма положительных)/2+(сумма отрицательных))/(число отрицательных) то есть (сумма положительных)/2+(сумма отрицательных)/(число отрицательных).
PS: Знаю что есть ошибка. Кто-то скажет где?
Неверно, что все подмножества равновероятны.
Да, точно. Спасибо.
It was 5 seconds too late to submit E (and get accepted). See you next time, Russia :(
Правда ли, что 47 тест в D (3ий раунд) — это тест против хешей mod 2k?
Неправда, мое решение в хешах mod 2^64 зашло.
Похоже не все я этими строками покрыл.
Да. У нас были споры по поводу делать его или нет, но большинство проголосовала за "добавить".
Как тогда прошло мое решение?
У тебя половина не хешами, видимо валили только первую половину :)
Да, так и получилось.
Интересно, вот я делал хеш по модулю 2^64, но вместо суммы брал xor. Всегда считал, что оно не валится тестом, который валит полиномиальный хеш. А здесь оно все равно упало на 47 тесте. Против этого специально генерировался кусок теста или этот способ валится на том же самом?
Специально против такого приема ничего не делалось.
Казалось бы, что это вообще не должно работать. Даже если у нас есть ксор-суммы h[] на префиксах, то не совсем понятно, как можно сравнить две подстроки на равенство: если взять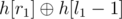 и
и 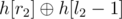 , то мы не можем их сравнивать — они домножены на разные степени p (pl1 и pl2 соответственно), а с ксором мы не можем привести их к одной степени путем домножения, как в случае со сложением — одинаковые подстроки могут иметь разные хеши.
, то мы не можем их сравнивать — они домножены на разные степени p (pl1 и pl2 соответственно), а с ксором мы не можем привести их к одной степени путем домножения, как в случае со сложением — одинаковые подстроки могут иметь разные хеши.
Ну разумеется, это не работает для случаев, когда нам надо быстро хеш подстроки получать. Этот прием можно использовать только когда нам надо считать хеш всей строки целиком или, например, только хеши префиксов некоторых строк.
Как решается F в 3-м раунде? Я брала минимум из сумм радиусов и суммы пути по меньшей из дуг и модуля разности радиусов. Учитывая случай, когда точки на одном луче радиуса. Это ловит ВА 18.
Так и решается. Точность?
PS. > Учитывая случай, когда точки на одном луче радиуса.
Зачем этот случай рассматривать отдельно?
Сравнивала полярные углы в целых числах, а для дуг косинус и арккосинус вычисляла, выводила с 10 знаками. Разве что-то не то?
У арккосинуса проблемы с точностью в окрестности 1. Предпочтительно считать углы с помощью arctan2: http://pastebin.com/ahUG1ynr.
Зачем косинус? Длина дуги это радиус умноженный на угол. upd. Понял зачем косинус, уже подсказали — atan2() Даже в голову не пришло что угол можно считать как-то иначе.
я так по-кривому считаю угол — косинус между векторами, а потом его арккосинус(
разницу углов к интервалу [-PI,PI] привела?
Упс, а я не приводил и все равно AC. Мое решение падает на тесте
Вот а почему когда я не привел, это привело к wa15?
Цвет не тот?
Это компенсация вот за это. Теперь все с точностью до наоборот).
То чувство, когда забыл реализовать интерфейс Comparable у элементов приоритетной очереди, а решение компилируется и не падает с ошибкой на семплах.
Это как оно компилируется?
Просто ничего не проверяется на этапе компиляции.
Оу, действительно. Это видимо сделано чтобы поддержать конструктор, принимающий Comparator.
Спасибо за турнир, было интересно! Жалко, что не получилось поучаствовать во всех отборах.
EF с третьего отбора (сEF может и обоснованно, чтобы не подсказывать решение, хотя какое-то double-число, наверное, сильно бы не подсказало).E или F?
Да, конечно, F.
Можно послать втёмную, выводя заведомо неправильный ответ на тесте из условия.
Точно, спасибо. Да, так можно было сделать. Конечно, это хак, да и в правилах я не был уверен, что это безшрафно.
В задаче F были примеры на оба варианта — и на путь через центр, и на путь по кольцу. А вот давать разные радиусы не очень хотелось — всё же подсказывать ещё и идею, что нужно использовать дугу меньшего радиуса, как-то неправильно. И так "содержательная" часть задачи практически вырождена...
Btw, если вы не в топ-100, то ваши шансы на футболку примерно 1 из 7.5
Удачи!
Чуть больше, примерно 1 к 6.29. По крайней мере одну задачу в отборочном этапе решили 633 человека. Исключив топ-100 (25 финалистов и 75 лучших помимо финалистов) и 61 несовершеннолетних участников, получаем: 75/(633-100-61) = 75/472 => 15,89 %, — вероятность получения футболки участником, сделавшим по крайней мере одну задачу в отборочном этапе, за исключением тех, кто ее получит в любом случае.
А разве несовершеннолетние не претендуют на футболку?
Разумеется, несовершеннолетние могут получить футболку!
У меня, может быть, дурацкий вопрос: почему в результатах строчки не пронумерованы? Это же неудобно. Я хочу знать, какое место я занял, и для этого мне надо считать, сколько человек выше меня и полагаться, что моя интуиция меня не обманывает, говоря, что на каждой странице по 50 человек.
Добавили в список TODO. Спасибо!
А когда будут результаты вероятностной викторины?
Как решать B из 3-го раунда?
Перепутал задачу.
Я сделал предположение, что если мы удаляем только одну клетку, то в итоге мы можем получить ровно половину перестановок (какой-то одной четности). Если же мы удаляем хотя бы 2 клетки, тогда в конце мы можем получить любую перестановку оставшихся клеток. Ну и разумеется, это еще домножается на количество способов расположить эти клетки на таблице. Это оказалось верным, но точного доказательства я не знаю.
Следует еще учесть, что если поле 1xN, то мы вообще не можем менять клетки местами.
А я вот не понимаю, почему на поле размера, скажем, 3 × 3, нельзя в любом порядке расставить 8 шариков? Если поле чётного размера, то понятно: свиг по горизонтали не меняет перестановку, сдвиг по вертикали делает чётный цикл, поэтому чётность перестановки никогда не меняется. А если поле нечётное × нечётное, то вертикальный сдвиг даёт нечётный цикл и чётность перестановки меняется.
Если поле 3х3, то при сдвиге по вертикали меняется четность перестановки, а также четность номера строки пустой клетки. Выходит, что у нас всегда поддерживается инвариант (четность перестановки + четность строки пустой клетки).
И впрямь, спасибо.
Заметим, что можно оставить от начального поля любые шары на их исходных местах. Тогда оставить все есть только один вариант. Если убрать ровно один(можно сделать n*m способами) то можем получить ровно половину позиций расстановок всех шариков из за четности/нечетности переставноки(пятнашки на поле произвольного размера). Если убираем больше одного шарика, то можем расставить оставшиеся шарики как хотим. http://pastie.org/8163404
Хорошее объяснение :) Из-за чётности/нечётности мы можем получить не более половины всех перестановок. А что можно получить ровно половину — жестянейшая жестяная жесть, ЕМНИП.
Ну это вызывает у меня сомнения только для поля 2*n и 3*3 :) Для больших размеров думаю можно пользоваться тем, что в решении для пятнашек вроде на подполе 3*4 все делается после того, как первый ряд построен.
Точнее даже ясно, что для поля 2*2 это неверно — можно не все перестановки той же четности получить.
Вот кстати, пусть мы начинаем с
12 34
Разве можно как-то получить
41 2.
?
А четность у неё вроде какая надо.
Вопросы, вопросы :)
Хотя нет, перебор показывает, что как-то можно все 137 получить. Значит вопросы только ко мне.
Да, я понял в чем было мое непонимание — "прокручивание" квадратика 2 на 2 на полный круг меняет его содержимое.
Вы прослушали разговор с самим собой.
Похожие рассуждения были у меня, когда я придумал эту задачу. И да, "прокручивание" не так просто, как кажется на первый взгляд.
А прошли-то все те же, кто и проходил просто по сумме трех раундов.
Очень понравилась задачка А, не ожидал такой простой и интерпретируемой формулы.
Очень не понравилось, что в трех задачах из четырех, где я успел хоть что-то сделать, пришлось использовать C(n,k). Не то что бы C(n,k) — это плохо, но почему бы не запихнуть одну из задач B или C в другой раунд? Я между ними вообще разницы не заметил кроме того, что доказать правильность в B на контесте вряд ли возможно.
До сих пор не покидает ощущение, что поучаствовал в какой-то тематической олимпиаде по не очень сложной комбинаторике, хотя может быть только потому, что я не умею её достаточно быстро сдавать.
Upd: Судя по тому, что можно было решить A и C другими методами, наверное, это исключительно моя проблема в избыточности C(n,k) для одного контеста.
Ну я в C даже не подумал, что 10! c С(n,k) в принципе может зайти, и написал честную динамику за 1000 * 10 * 2^10. И мне она совершенно не показалась похожей на B.
10! — это же три миллиона.
Для каждой перестановки надо из n вычесть что-то типа 9 разниц высот соседних элементов, и для каждой перестановки всего лишь один раз добавить C[n-сумма разниц][k], получается что-то типа 30млн. операций простых вычитаний и 3млн. операций обращений к массиву c[n][k].
Такое разве что на python'е может не зайти :)?
Upd: На C++, если не использовать деление с остатком, то работает 0.05c, я в своей посылке использовал его зачем-то дважды в одной и той же формуле, получилось 0.38c.
Upd2: Ошибся, в обоих случаях около 0.4.
Была написана чушь.
Это сейчас 10! — три миллиона, а в 3 часа ночи 10! — это ж много :) Хотя работает оно на таких ограничениях быстрее динамики :)
А как это делается динамикой?
Откуда берутся 2^10?
Upd: Уже понял, 1000 — текущий ряд, 10 — кто на нем стоит, 2^10 — кто, стоит ниже.
Можно подробней про динамику. Нам же вроде мало информации, кто стоит ниже.
Просто далее мы будем пытаться ставить только вверх от текущего ряда. Соответственно, зная кто стоит на текущем ряде, мы знаем минимальную высоту, на которую можно ставить оставшихся зрителей.
can anybody explain the solution of Problem A on Online round 3? getting a lots of wa .
Looking through years:
Yes, my hobby is extrapolation :)
SN*S rounds are from the future:)
Забавно, в финале ни одного оранжевого)
Зато фиолетовые повылазили (с) !
Хотел бы я быть таким фиолетовым
Re-comment in English Version can anybody explain the solution of Problem A on Online round 3? getting a lots of wa .
I will try to explain my solution.
By the linearity of expectation, the expectation of the sum is equal to the sum of expectations. (i.e, the sum of the value of each candy multiplied by probability that you will eat it).
There are two types of candies.
For bad candies, you know that you will eat exactly one or zero of them(the latter is true if there are no bad candies at all). So, if there is at least one bad candy, you will eat each of them with equal probability of
The corresponding expectation coming from bad candies is the sum of the values of bad candies multiplied by p_bad.
Another part of the expected sum is the sum for good candies. Let's iterate over all the good candies we have and calculate the appropriate expectation (the value of the candy multiplied by the probability that you will eat it).
For i-th good candy, consider all possible numbers p of candies you can eat before it. It is clear that all candies you can eat before the i-th good candy must be good (otherwise you had to stop before). Therefore, the probability that you will eat it after eating other p candies is equal to the number of arrangemens of all candies of the form
[good_candy1] ... [good_candyp][good_candyp + 1][all others]
divided by the number of all possible arrangements with ith good candy sitting on (p + 1)st place.
The number is equal to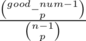 , where good_num is the total number of good candies.
, where good_num is the total number of good candies.
By summing over all possible p, and multiplying the sum by 1/n (the probability that the i-th candy will be at place p+1) you get the expectation that you will eat candy i.
You need to be careful with special cases when p is greater than good_num, when there are no bad candies, etc.
Here is the code: http://pastie.org/8165899
Материалы раундов 2 и 3 опубликованы!
А разборы отборочных раундов будут?
Будут.
Пока нет официального разбора, могу, если нужно, разобрать задачи А и F с первого раунда (решения четырех остальных в этой теме есть).
Оставшиеся два раунда я пока не решал.
И когда будет анонсирован список выигравших футболки случайным образом?
Случайные люди, которые получат футболку, будут отобраны Почтой России!
Any news about T-shirts? :)
Still in progress -- we're waiting for finalists to make sure that T-shirt distribution will be correct. You will get an update shortly.
Still waiting for news :)
You can find info here (http://algorithm.contest.yandex.ru/?lang=en#post-10).
"Double check your mailing information and t-shirt size in your profile!"
Which profile, Codeforces or Yandex? I didn't found anything in Yandex profile.
Go to http://algorithm.contest.yandex.ru/ and click "registration"
Когда все-таки появится информация о футболках?
Информация появилась http://algorithm.contest.yandex.ru/#post-10.
Для меня остается загадкой, почему мой никнейм в этом сообщении совпадает с никнеймом в общих результатах, но не совпадает с никнеймом, указанным в профиле. В результатах отдельных контестов я указан, как lebronua2013, а в общей таблице такого пользователя нету, зато есть LeBron, у которого, как ни странно, результаты совпадают с результатами lebronua2013 в отдельных контестах.
Э, а почему меня нету? У меня, вроде бы, 72 место...
Насколько я понимаю, в посте указаны именно те, кто получил рандомные футболки, а те, кто получил топ100 футболки, должны найти себя в таблице.
Аа, видимо, да, спасибо.
У меня два вопроса: 1) Когда следует ожидать футболку? 2) Будет ли работать дорешивание задач на сайте algorithm.contest.yandex.ru? (в данный момент на отправку задачи пишет "Ваше решение отправить не удалось")
футболки должны быть уже на пути к вам.
Спасибо за замечание по поводу невозможности отправки, сейчас разберемся
Спасибо за ответы!
Возможно, имеет смысл сделать рассылку идентификаторов почтовых отправлений, чтобы участники могли отслеживать их статус? К примеру, футболка с Russian Code Cup, как оказалось, где-то полторы недели валялась на почте без оформления извещения.
Кому-то уже пришла?
Так как на сайт algorithm.contest.yandex.ru не поддерживается дорешивание, возможно имеет смысл добавить раунды yandex algorithm в CF тренеровки?
http://contest.yandex.ru/contest/ContestList.html Здесь вроде бы можно дорешать.
А как там отправить решение? На все мои попытки пишет "Error. You can send only UPSOLVING submission after contest end."
Да, что-то там не так. У меня сабмит работает только в контестах, в которых я не участвовал. (После Register можно начать Virtual Contest)
Воспользуйтесь новым интерфейсом (algorithm.contest.yandex.ru). Если возникнут какие-то сложности, то вы можете задать вопросы мне или в форму обратной связи
И всё-таки, какова судьба обещанной футболки? Её вообще до почтового отделения-то довезли? :)
Я разбираюсь с этим вопросом, прошу прощения за задержку.
Футболки непременно доберутся до всех заслуживших их участников (если участники, конечно, указали размер и адрес при регистрации ;) )
Правильно ли я понимаю, что футболки еще ни до кого не дошли?
да. Приношу свои извинения за долгое ожидание.