


We hope all of you enjoyed the round! This round has been a long time in the making -- the oldest problem in it is H, which was actually originally proposed for the rounds that eventually became Codeforces Round 655 (Div. 2) and Codeforces Global Round 10.
The tutorial for E and implementations for all problems are now available.
A - Windblume Ode
B - Omkar and Heavenly Tree
C - Omkar and Determination
D - Omkar and the Meaning of Life
E - Moment of Bloom
F - Defender of Childhood Dreams
G - Omkar and Time Travel
H - Omkar and Tours
I - Omkar and Mosaic







Thanks for the great contest and fast editorial!
Thanks for the fun contest!
The bonus of D !
Asking $$$A=[1,1,\dots,k]$$$ in which $$$k=2,3,\dots $$$, when the first time get answer $$$0$$$, there is $$$p_n=n-k+1$$$ if this is the $$$k$$$-th query. What's more, if the answer to $$$u$$$-th query is $$$b_u$$$, then $$$p_{b_u}=p_n+u$$$. Now we get the position of $$$b_n,b_{n}+1,\dots n$$$ and only make $$$n-p_n$$$ queries.
Then asking $$$a_i=n$$$ if $$$p_i$$$ is determined, $$$a_i=k$$$ if else, from $$$k=1$$$ to $$$k=p_n-1$$$. If the answer to $$$u$$$-th query is $$$c_u$$$, then $$$p_{c_u}=p_n-u$$$.
Now we get the position of all numbers and only make $$$n$$$ queries.
And here is my solution
great solution! I used similar way to find A[n], but I performed another n — 1 queries to determine other elements.
The solution 1 of D can also be optimized to omit $$$n-1$$$ queries.
You can record for each $$$j$$$, the index $$$prev_j$$$ such that $$$p_{prev_j}=p_j-1$$$.
When you set $$$y\to next_x$$$, set $$$x\to prev_y$$$, and vice versa.
You can ask like the solution 1, but since queries only find smaller index of the two equal $$$s_j$$$, you can visit $$$j$$$ from $$$n$$$ to $$$1$$$. If the $$$next_j$$$ is determined by previous queries, you can omit the query of the first type(i.e. a query with all $$$1$$$s except that $$$p_j=2$$$). If the $$$prev_j$$$ is determined by previous queries, you can omit the query of the second type(i.e. a query with all $$$2$$$s except that $$$p_j=1$$$).
Since for each $$$x$$$ from $$$0$$$ to $$$n$$$, the relative position of $$$x$$$ and $$$x+1$$$only requires 1 query to determine(when $$$p_j=1$$$, we should also ask about $$$prev_j$$$(which shouldn't appear), we assume that there's an $$$0$$$ which is $$$prev_j$$$, and the same to the index j that $$$p_j=n$$$), you can solve the problem with $$$n+1$$$ queries.
My solution
(I only know a little English; sorry for that.)
Nice...
[deleted]
By the way, the girl is that "Hu Tao" in problem E.
Genshin is love
Really a tough contest.. waiting for rating to go down....
Nice problems! E and F should've been swapped imo. E was so tedious to formulate and code. Think F would have far more solves if it were in place of E. Took an hour on E and missed F by a whisker cause of one dumb typo ~>_<~
The editorial for problem D does not respect the requirement $$$1 \leq a_j \leq n$$$ on the queries. (But it is trivial to fix this.)
Problem G is somewhat similar to 1552F - Telepanting from a recent CF contest.
EDIT: They are not as similar as I at first thought. The processes are relatives, though.
Good catch, should be fixed now.
I am sorry but in problem E the editorial does proves only the fact that if every vertex appears even number of times, then answer is 0.
How to prove that ANY spanning tree works if we wanna find out the minimum number of queries to be added? This is the hard part.
Consider a second graph with $$$n$$$ vertices and $$$q$$$ edges, with each query represented by an edge between the two endpoints. Since each vertex appears an even number of times in the queries, each vertex in this second graph has even degree. Therefore, each connected component in this graph has an Eulerian cycle. Consider transversing a single cycle starting from some vertex on it. Each time we pass an edge of the cycle (on the second graph), increase the weights of the edges on the path (on the original graph's spanning tree). At the end, we will return to our starting point, both on the original graph and on the new graph. Then, each edge on the original graph's spanning tree is passed an equal number of times in each direction, and thus an even number of times. Adding more cycles still work, as the sum of any number of even numbers is even.
I think you just proved what the editorial proved. I was asking for the proof of the second part: when the answer is NO, and we have to find the minimum number of queries to be added. why does dp in any spanning tree work?
The editorial is indeed incomplete in the part when the answer is NO, but in my opinion it is much easier than when the answer is YES.
When the answer is NO, we just need to add queries so that all $$$f_v$$$ are even. The minimum such number is the number of values of $$$v$$$ such that $$$f_v$$$ is odd, divided by 2.
We need at least that many extra queries since each query added can change at most two $$$f_v$$$ values. On the other hand, we can achieve this number of queries by pairing up the odd $$$f_v$$$'s (there are an even number of them since the sum of all $$$f_v$$$ is even).
Wow, I didn't realise that there is no need for tree dp. Thanks a lot.
Thank you. That's way better than the editorial
Any (nonsimple) cycle in a tree visits every edge an even number of times.
If every vertex is the endpoint of an even number of paths, the paths can be arranged into cycles: to form a cycle, take any path, say from $$$a_1$$$ to $$$a_2$$$. Then take any path from $$$a_2$$$, say to $$$a_3$$$. Repeat until $$$a_t = a_1$$$. This must happen, as the only vertices that an odd amount of paths start after the first $$$j - 1$$$ edges are $$$a_1$$$ and $$$a_j$$$.
But this is the proof for YES case. I was talking about how to prove when the answer is NO, that is OK to take any spanning tree.
The spanning tree is only used for the YES case. Read the solution more carefully.
Actually in my solution, I used spanning tree for my NO case also. I did dp on that tree. So I was confused.
I am sorry for necroposting
Obviously, if we proof for the tree version(MST of the graph) of the problem, it gets visible. First let's assume that queries already satisfy requirement for Eulerian cycle. Let Eulerian cycle of the graph formed by adding edges between $$$a_i$$$ and $$$b_i$$$ be $$$v_1, v_2, v_3, ... v_k$$$, without considering $$$v_1$$$ in the end. I claim that if we add $$$1$$$ on the paths between adjacent nodes in the set $$$v$$$, the only set of edges that have odd number are on the path from $$$v_1 \to v_k$$$. Why? because consider any edge on the tree($$$(x, y)$$$ edge), it is trivial that if we remove this edge, the tree gets split into two components, let's call them $$$A$$$ and $$$B$$$. To make it easier, let's assume that we visited $$$(x, y)$$$ edge, it means in certain time we were at $$$B$$$. If $$$v_k$$$ is at component $$$A$$$ we will have to visit $$$(x, y)$$$ edge again, which means it is visited even times. If $$$v_k$$$ is at component $$$B$$$, $$$(x, y)$$$ edge lies on the path $$$v_1 \to v_k$$$, and considering exit and entry property, it will be visited odd times. Since we proved that only path from $$$v_1 \to v_k$$$ will be visited odd times, then in the end if we append $$$v_1$$$ we removed in the start(Eulerian cycle always starts and ends in the same node), $$$v_1 \to v_k$$$ path becomes even also. Which finishes proof that we can always do it if all of them are even. What if some of them aren't odd? Now this is trivial task if you are familiar with Eulerian cycle, we can just add edge between odd vertices in any order, let $$$cnt$$$ be number of odd degree nodes, then number of edges we should add is exactly $$$\frac{cnt}{2}$$$.
First of all, I assume that you have read first proof, because I will use same notations.
Let's assue for any $$$k$$$, set $$$S = v_1, v_2, v_3, ... v_k$$$ already satisfies the condition (The only odd times visited edges lie on the path $$$v_1 \to v_k$$$. Now we need to prove it for $$$v_1, v_2, v_3, ... v_k, v_{k + 1}$$$. Let's root tree at $$$v_1$$$, current set $$$S$$$ edges numbers look like this: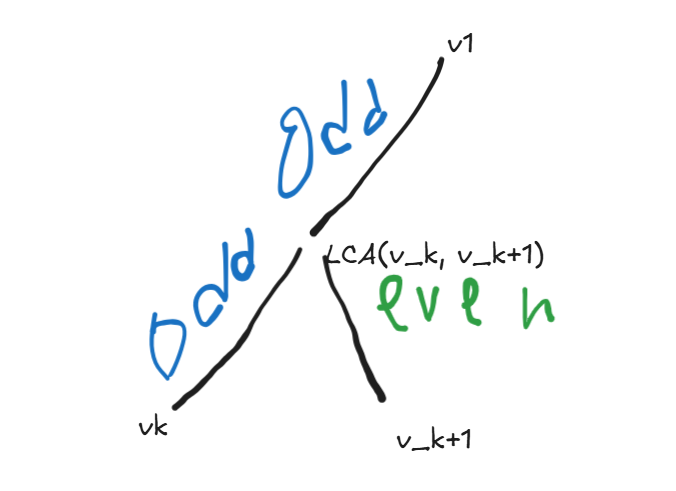
It is clear that $$$v_k \to v_{k+1}$$$ path is unique, and visites $$$LCA$$$. It is clear that $$$v_1 \to LCA$$$ path remains odd because we don't visit it, and $$$v_k \to LCA$$$ becomes even(odd+odd), and $$$LCA \to v_{k+1}$$$ becomes odd(even + odd). Consider this illustration:
So now conditions holds for set $$$v_1, v_2, v_3, ... v_k, v_{k + 1}$$$ as well, which finishes induction proof. Reamaining part must be clear after reading first proof.
I tried my best to explain, sorry for my bad English. If anything is unclear, you can ask questions.
can anyone help me with solution C 132264422
u only checked for indices which are "." but u should also check for "X" too a simple example is this XX XX your code will give YES for it but ans should be no as following will also produce same EN grid XX X.
My approach to F was different, and allows for a trivial lower bound proof.
Fix the number of colours $$$c$$$ you will be using. For every node $$$i$$$, define the array $$$LEN[i]$$$ such that $$$LEN[i][t]$$$ is the length of the longest monocoloured path of colour $$$t$$$ from node $$$i$$$. In a valid solution, we have $$$0 \leq LEN[i][t] \lt k$$$.
Take any optimal solution and consider these arrays. Let $$$t$$$ be the colour of the edge from $$$i$$$ to $$$j$$$. Then $$$LEN[i][t] \geq LEN[j][t] + 1$$$. This immediately shows that we must have $$$LEN[i] \neq LEN[j]$$$ for all $$$i \neq j$$$. Since there are $$$k^c$$$ different arrays, any valid solution must thus have $$$n \leq k^c$$$.
Also, given that $$$n \leq k^c$$$, we can construct a solution by assigning the possible arrays in lexicographically decreasing order.
Although I failed this contest, I really liked the originality of problem B !
Great contest! For those who prefer video explanations, I explain solutions to all problems except I and G at the end of my screencast here.
My first time to solve an interactive problem! Stuck at E and tried G but withdrew...
my solution to D is working in my device properly but when i submitted it showed TLE on permutation {1,2} anyone kindly help 132260554
The last (truncated) query would be "? 3 1". That violates constraint stated in the problem: $$$1 \le a_j \le n$$$.
oopssss got it
Here are the video solutions to the first 4 problems. solutions
My feedback on A-G:
UPD: added G
Another way to construct a coloring for F is to think about the indices $$$0$$$ to $$$n-1$$$ in base $$$k$$$. Color the edge from $$$a$$$ to $$$b$$$ by the position of the most significant digit that changes. There is no path of length $$$k$$$ with only one color as the most significant digit that changes can only increase $$$k-1$$$ times.
Wow, how beautiful the solution to F is!
Thanks for the interesting problems and +114 rating!
Can I asked for a solution in problem B if (m >= n)?
can think of m<2*n
Can you show your idea :D?
actually when i wrote that comment i thought the wrong way but after thinking a lot i concluded that for m>=n there exists such an input for which solution is not possible ex: suppose n=m=6 consider the following 6 constraints {(1,2,6),(1,3,6),(1,4,6),(1,5,6),(1,6,2),(2,1,6)} here considering first 4 no node can be between 1 and 6 so u are forced to connect 1-6 if done this u cannot add 2 to either side as it will always violate the either of the last 2 constraints,,,,, may be there is a solution for some special cases for m>=n
Here's a solution sketch for $$$m \leq n + 1$$$.
If there is some vertex $$$v$$$ which is not equal to some $$$b_i$$$, then a star with central vertex $$$v$$$ works. Otherwise, every vertex $$$v$$$ is equal to $$$b_i$$$ for exactly one $$$i$$$, since there are $$$n$$$ vertices and only $$$m = n$$$ constraints. So, the only obstruction to using $$$v$$$ as the center vertex in a star are these the vertices $$$a_i$$$ and $$$c_i$$$ for the same $$$i$$$. Call these two vertices $$$p_v$$$ and $$$q_v$$$, and write $$$v \hookrightarrow x$$$ to mean $$$x \in \{p_v, q_v\}$$$.
Since only the $$$p_v$$$-$$$v$$$-$$$q_v$$$ constraint is an issue for the star centered at $$$v$$$, a natural try to work around this is to just attack $$$p_v$$$ to $$$q_v$$$ or vice-versa, and the other vertices to $$$v$$$. The former will work unless $$$q_v \hookrightarrow p_v$$$, and the latter will work unless $$$p_q \hookrightarrow q_v$$$. Then, let $$$x_v$$$ be the vertex with $$$p_v \hookrightarrow x_v$$$ but $$$x_v \neq q_v$$$. By the above (but with $$$p_v$$$ in place of $$$v$$$), we may assume that $$$q_v \hookrightarrow x_v$$$ and $$$x_v \hookrightarrow q_v$$$. But then, by the same (but with $$$q_v$$$ in place of $$$v$$$), we may assume that $$$p_v \hookrightarrow x_v$$$ and $$$x_v \hookrightarrow p_v$$$.
So, in any solution, there must be a branching-point $$$y$$$ between the three vertices $$$p_v$$$, $$$q_v$$$, and $$$x_v$$$, and this branching-point cannot have $$$\{p_y, q_y\} \subseteq \{p_v, q_v, x_v\}$$$. If no such $$$y$$$ exists, then no tree can satisfy the given constraints. Otherwise, take a claw on the vertices $$$\{y, p_v, q_v, x_v\}$$$ and attach the remaining $$$n-4$$$ vertices all to $$$x_v$$$ to create a tree that satisfies every constraint.
Since there are now $$$n+1$$$ constraints, if no star graph is acceptable then there is exactly one vertex $$$t$$$ with $$$t=b_i$$$ for more than one value of $$$i$$$. Define $$$p_v$$$, $$$q_v$$$ and $$$v \hookrightarrow x$$$ as above for any $$$v \neq t$$$. It may be that $$$p_v = t$$$, in which case $$$x_v$$$ can be defined if necessary using $$$q_v$$$ instead of $$$p_v$$$. Then, as before, any solution must contain a branching point $$$y$$$ separating the vertices $$$p_v$$$, $$$q_v$$$, and $$$x_v$$$; and if any vertex $$$y$$$ exists that is allowed to be such a branching point, then a solution can be constructed by attaching the remaining $$$n-4$$$ vertices to the same leaf in the claw on the vertices $$$\{y, p_v, q_v, x_v\}$$$, as long as that leaf is not equal to $$$t$$$. But there are always at least two leaves that are not $$$t$$$, so this can always be done when $$$y$$$ exists.
It may be possible to push this idea a bit further, but it seems likely to get hairy fast.
Thanks, I can understand your idea. When I first saw this problem, I was confused before reading its constraint.
I'm curious about the special judge for problem B.How to check an output is valid or not quickly(I can only thought about a data structure which is O(n log^2 n))?
Notice that $$$b$$$ lie on the simple path between nodes $$$a$$$ and $$$c$$$ if and only if $$$dist(a,b)+dist(b,c)=dist(a,c)$$$.
So all you need is a method to get LCA of two nodes.
Thank you , Hutao , for this fantastic contest . The division degree is good.
In problem H,I have a different way on maintaining the information.
After off-line the queries,it requires us to find out the maximal toll on the road to the reachable cities with the maximum enjoyment value.And the maximum enjoyment could be saved on Link-Cut-tree with set maintaining the maximum value of each node subtree,while the maximal toll could be found at the same time.
Unfortunately,I would have thought that 3 seconds were enough for n log^2 n.It took me more an hour to get the program faster and faster.In the end,I control the size of each set no more than 3,because there is no edge cutting operation,with the time complexity O(n log n).
I have only solved A and H,and I have known I'm doing wrong.Now,I'm learning how to use binary search.
3 seconds are indeed enough for O(n log^2 n).
I just solved problem H (as practice), and I used DSU on tree to bruteforcely merge the cities with maximum enjoyment in two sets.
The time complexity is O(n log^2 n) with a big constant from vector operations, and it runs surprisingly fast (<500ms).
With set,maybe LCT has a larger constant and the complexity is more than O(97 n log n)(Top-Tree's complexity).I'll use these data structures more carefully next time.
And thanks for solving my puzzle.
A stupid $$$O((n+q) \log^2 (n+q))$$$ solution for H:
First find out the answer to the first question using dsu. Then do centroid decomposition to find out the second answer. Let $$$mx_u$$$ and $$$mi_u$$$ respectively be the maximum toll and minimum capacity from $$$u$$$ to centroid, and $$$bel_u$$$ be the subtree within which $$$u$$$ lies. Then, we just have to find out the following:
By maintaining a segtree independently for each $$$a_v$$$, the whole task can be solved in $$$O((n+q) \log^2 (n+q))$$$. (without any observation)
There's actually no need for the segment tree, a centroid tree data structure suffices.
Why is this giving TLE on 2nd test case whereas it runs just fine on other IDE
my solution
violating the condition that 1<=aj<=n i also did same mistake though
arre thanks a lot bhai..i have been struggling in this for a long time
however it should give wrong output format rather then TLE if so i would have done d too
exactly!!
How to solve B? if m may not be less than n
that,s mean the problem may not have solution if every node appeared at least one in B
I really like the way D was made. It was easy but little trick at the same time. Thanks for this
In problem C, I can not understand the meaning of "This includes the cell itself, so all filled in cells are not exitable".
I got WA cause' I misinterpreted this line, for a single column subgrid XXXX the output was supposed to be Yes but I was printing No.
I hope the authors would make the problem statement more easier to understand next time. For subgrid 2x2: [.X] [XX] I printed out YES, but the answer is NO
The thicken words for B is really useful! :)
I think the proof of F doesn't seem so right....How can the necessity be proved like that?
Maybe I didn't get the point
[solved]
The editorial of G is very long and I had to be patient enough to read it carefully. However, I didn't understand the sequence "Specifically, we can represent a valid set v as the set u of intervals that aren't implied to be in v by any other element of v" after reading it again, again, again, again, again and again. Though I asked many other people, I still found it hard to realize what it exactly mean... So is there any people who is good at English explain about it? Thanks. Sorry for my poor English:(
It was described earlier that if you have segments $$$[a_i, b_i]$$$ and $$$[a_j, b_j]$$$ such that $$$a_i \lt a_j$$$ and $$$b_i \lt b_j$$$ then the presence of $$$[a_j, b_j]$$$ in set $$$v$$$ "implies" the presence of $$$[a_i, b_i]$$$ in set $$$v$$$.
That's why, if $$$v$$$ has both $$$[a_i, b_i]$$$ and $$$[a_j, b_j]$$$ then you say that $$$u$$$ will contain only $$$[a_j, b_j]$$$. In other words, $$$u$$$ will contain only $$$[a_i, b_i]$$$ from $$$v$$$ that don't have any other $$$[a_j, b_j]$$$ in $$$v$$$ with $$$a_i \lt a_j$$$ and $$$b_i \lt b_j$$$.
Oh, what a great explanation! Thanks for your help!
How to solve B if number of restrictions is not necessarily less than n?
exactlyyyy, I also did the same.
Another way to think about the tree reduction for E. Thanks to SecondThread for the helpful explanation.
Suppose we have a cycle $$$C = c_1 c_2 \ldots c_m c_1$$$ and we remove an edge $$$e = (c_k,c_{k+1})$$$ from the graph. Now for each path that originally contained $$$e,$$$ say $$$P = v_1 v_2 \ldots v_i (c_k c_{k+1}) v_{i+3} \ldots v_j,$$$ we now remove $$$c_k c_{k+1}$$$ and reroute to the rest of the cycle, ie. the new path is $$$v_1 v_2 \ldots v_i (c_{k} c_{k-1} \ldots c_1 c_m \ldots c_{k+1}) v_{i+3}\ldots v_j.$$$ If we do this for every original path that contained $$$e,$$$ which is an even number of them* (see the note at the bottom), we see that the edge weight of $$$e$$$ goes to $$$0$$$ (even), and we add $$$e$$$'s original weight (an even number) to each of the other edges in $$$C \setminus e.$$$ Since all weights were originally even, the weights after rerouting all paths that originally contained $$$e$$$ are also all even. We can keep removing edges this way until we are left with a spanning tree.
However, the new path may no longer be simple (ie. it will repeat edges if $$$P$$$ contained any edges in $$$C \setminus e.$$$) But it turns out that having non-simple paths is fine at the end when we are left with a tree. Why is this true? Intuitively if we have a non-simple path in a tree, if we go down and visit a child and then come back up, we could just delete this because it cancels and the parity isn't changed, and we can turn it into a simple path.
Suppose we have a non-simple path from $$$a$$$ to $$$b$$$ in the tree where we visit some vertices twice. Then look at a closest such occurence, ie. we visit some vertex $$$v,$$$ then at some later point we visit $$$v$$$ again, but in between we don't repeat any vertices. (Such a vertex must exist: We can take any subpath from a vertex back to itself, and if it repeats some other vertex in between, then look at those two vertices and repeat.) It's easy to see that this subpath must be of the form $$$v \to u \to v,$$$ because once we leave $$$v$$$ if we don't immediately return to $$$v$$$ then we will visit some second point $$$w,$$$ and any (possibly not simple) path from $$$w$$$ that returns to $$$v$$$ necessarily visits $$$u$$$ again so once we visit $$$u$$$ we must immediately return to $$$v$$$ if we don't repeat any other vertices. Thus we can just delete this consecutive occurrence of the edge $$$e = (u,v)$$$ from the path, and the weight of $$$e$$$ decreases by $$$2,$$$ an even number so parity is still invariant. By doing this repeatedly, eventually we must get the unique simple path from $$$a$$$ to $$$b.$$$ Thus, we have further reduced the problem to simple paths on any spanning tree of the original graph.
Thus we have shown: If there is a valid solution with simple paths on $$$G,$$$ there is a valid solution using (possibly non-simple) paths on any spanning tree $$$T$$$ of $$$G,$$$ and further, any solution on a tree with non-simple paths is equivalent to a solution using the unique simple paths of $$$T,$$$ and the proof is complete.
When removing edges after the first one, there might be an odd number of paths (if they're non-simple) that contain that edge, but the total number of times that the edge shows up in the paths is still even, which is what matters. If a path contained an edge several times and we remove that edge, we'd re-route for every occurrence of that edge in the path.
F is amazing! Spent a whole day convinced that the answer was $$$\lceil \frac{n}{k} \rceil$$$ and stumbled upon the correct solution after repeatedly failing to prove it.
Simpler solution for problem G:
Firstly, like in editorial, we consider each task $$$p$$$ to be an interval $$$[a_p, b_p]$$$ on the number line. Now, passage of time and time travels can be visualized as okabe moving forward by 1 step and teleporting backwards on this number line.
Observation 1: Whenever okabe reaches some point $$$x$$$ on this number line, such that $$$b_p = x$$$ for some $$$p$$$, then at that moment of time, any task $$$q$$$ with $$$b_q \lt b_p$$$ will be completed. (easy to prove by contradiction, as existence of incomplete task $$$q$$$ with $$$b_q \lt b_p$$$ would imply we teleported forward at some point of time).
Now, let us consider some incomplete task $$$p$$$. When okabe reaches point $$$b_p$$$, he will teleport backwards, then travel for some time (with some intermediate teleports), and then finally reach $$$b_p$$$ again.
Let us define $$$dp_p$$$ to be the number of teleports which okabe needs to perform before first reaching $$$b_p$$$ again, after teleporting back from $$$b_p$$$ when $$$p$$$ was incomplete.
Observation 2: $$$dp_p$$$ (ie. the number of teleports to reach $$$b_p$$$ again), does not depend on the completion status of any other task. This is true because only some task $$$q$$$ with $$$b_q \lt b_p$$$ can affect $$$dp_p$$$ and any such task is always completed at any instance of us teleporting back from $$$b_p$$$ by observation 1. It does not matter whether any task $$$q$$$ with $$$b_q \gt b_p$$$ is completed or not, because we will reach $$$b_p$$$ before reaching $$$b_q$$$.
Now how do we calculate $$$dp_p$$$ for some $$$p$$$? Firstly, notice that we never go behind $$$a_p$$$ before reaching $$$b_p$$$ first. This is easy to show , because going behind $$$a_p$$$ would imply that there exists some incomplete task $$$q$$$ for which $$$a_q \lt a_p$$$ and $$$b_q \gt b_p$$$. But this is a contradiction to the fact that all such tasks were complete before teleporting back from $$$b_p$$$, and teleporting behind from $$$b_p$$$ only ever resets completion status of tasks $$$r$$$ with $$$a_p \lt a_r$$$ and $$$b_r \lt b_p$$$.
So this means that only tasks $$$q$$$ with $$$a_q \gt a_p$$$ and $$$b_q \lt b_q$$$ contributes to $$$dp_p$$$. As it turns out, $$$dp_p$$$ is simply $$$\sum{dp_q} \quad \forall q | (a_q \gt a_p, b_q \lt b_p)$$$.
Why is this valid? It's because this corresponds to only considering each task $$$q$$$'s contribution to be the number of intermediate teleports we make to reach $$$b_q$$$ after first teleporting back from $$$b_q$$$ (which is nothing but $$$dp_q$$$), and this is clearly a valid and complete formulation. $$$dp$$$ value for all tasks can be computed easily in $$$O(n\log{n})$$$ by using any point update range sum query structure.
Now, for the final part of the problem, we need to figure out the least time by which all the tasks in the given set of tasks $$$S$$$ are completed.
Let us define $$$opt_p$$$ to be the task $$$q$$$ with the maximum $$$b_q | (a_p \lt a_q, b_q \lt b_p)$$$.
Let $$$x$$$ be the task with the maximum value of $$$b_x \quad \forall x \in S$$$.
Now, consider why the answer is not simply $$$\sum{dp_q} \quad \forall q | (b_q \leq b_x)$$$
Notice that for task $$$x$$$, after we teleport back from $$$b_x$$$, do some intermediate teleports, and reach a state wherein $$$opt_x$$$ is completed, we do not need to travel forward anymore (ie. we do not need to reach $$$b_p$$$ again). So basically, if we consider the answer to be $$$\sum{dp_q} \quad \forall q | (b_q \leq b_x)$$$, then we need to subtract $$$dp_r$$$ from the answer for all $$$r$$$ such that $$$a_r \gt a_p, b_r \gt b_{opt_p}$$$. Now, similarly for $$$opt_p$$$, we do not need to reach $$$b_{opt_p}$$$ again, so we do not need to travel anymore after teleporting back once from $$$b_{opt_p}$$$, and $$$opt_{opt_p}$$$ getting completed. This is to be done recursively till we reach a task which has no task's interval lying within its own.
As $$${opt_p}^{x + 1} \lt {opt_p}^{x}$$$, we can simply use two pointers to do this final recursive procedure in $$$O(n)$$$ at the end.
Implementation: link