


As part of the graduation requirements for my school, I have to complete a simple research project, so I decided to do something related to data structure and algorithms. I believe I have come out with a data structure that maintains the basis of vectors in $$$(\mathbb{Z}/m\mathbb{Z})^d$$$, where $$$m$$$ may not be prime. Since this was related to competitive programming, I think it is a good idea to share it here. Hopefully, this algorithm is actually novel :P
I would like to thank:
- icypiggy for being my research mentor and tolerating my dumb questions
- rama_pang and adamant for their helpful suggestions and comments
Please comment under the blog or message me on codeforces if any parts are unclear or wrong. Also, I hope that some LGMs can help solve the open problems in this blog.
Introduction
Maintaining the basis of vectors in $$$(\mathbb{Z}/2 \mathbb{Z})^d$$$, also known as the xor basis algorithm is a well-studied algorithm in competitive programming. The standard xor basis algorithm supports $$$2$$$ operations. Given a set $$$S$$$ that is initially empty, you can add a vector to $$$S$$$ or query whether a vector is representable as a linear combination of vectors in $$$S$$$. Using the word RAM model, the basis can be maintained in $$$O(nd)$$$ as the addition of vectors in $$$(\mathbb{Z}/2 \mathbb{Z})^d$$$ can be done in $$$O(1)$$$ time, where $$$n$$$ is the number of vectors we add. This algorithm can also be easily modified to handle $$$2$$$ additional queries: the lexicographically largest representable vector and the number of representable vectors. This data structure is used in various problems such as AGC45A, UER3C, 1299D - Around the World, 1336E1 - Chiori and Doll Picking (easy version),1427E - Xum and 1466F - Euclid's nightmare.
An extended version of the xor basis algorithm allows for querying the basis set of vectors for a given subarray of an array of vectors. More formally, given an array $$$A$$$ where $$$A_i \in (\mathbb{Z}/2 \mathbb{Z})^d$$$, we can check if a vector is representable as a linear combination of vectors in $$$A_l,A_{l+1},\ldots,A_r$$$. It has appeared in 1100F - Ivan and Burgers and ABC223H which can be solved in $$$O(nd)$$$ offline or $$$O(nd \log n)$$$ online.
Another known extension of the xor basis algorithm allows one to maintain the basis of vectors in $$$(\mathbb{Z}/p\mathbb{Z})^d$$$ where $$$p$$$ is prime. It is used in XXII Opencup GP of Siberia F with $$$p=7$$$.
In this blog, we will propose an algorithm that can maintain the basis for a set of vectors in $$$(\mathbb{Z}/m\mathbb{Z})^d$$$.
GIANT DISCLAIMER: In this blog, the words "vector'' and "basis'' are used very loosely. The word vector is used to refer to an element of a module as $$$(\mathbb{Z}/m\mathbb{Z})^d$$$ is not necessarily a vector space. Furthermore, the notion of linear independence is not very well-defined when we are considering a ring. Consider the ring $$$\mathbb{Z}/4\mathbb{Z}$$$, then the set $$$\{2\}$$$ is not linearly independent because $$$\lambda=2$$$ satisfies $$$\lambda \cdot 2 = 0$$$ but $$$\lambda \neq 0$$$. But the term basis is used because after some restrictions to the set of scalars that are applied to the vectors we store, each set of scalars correspond to a unique "vector'', a fact that will be proven in theorem 5.
More specifically, given an initially empty set $$$S$$$ of vectors in $$$(\mathbb{Z}/m\mathbb{Z})^d$$$, we can add $$$n$$$ vectors with $$$O(n \cdot d^2 + \Omega(m) \cdot d^3 + d \cdot \log(m))$$$ pre-processing, where $$$\Omega(m)$$$ is the prime omega function that counts the total prime factors of $$$m$$$ and check if some vector in $$$(\mathbb{Z}/m\mathbb{Z})^d$$$ is can be represented by some linear combination of vectors in $$$S$$$ in $$$O(d^2)$$$ time online. Additionally, we can also query other things such as the number of distinct vectors we that can be represented as the sum of vectors in $$$S$$$ and the lexicographical largest vector that can be represented.
Later, we will extend this idea to handle elements of an arbitrary finite abelian group $$$G$$$.
The Algorithm
The main idea of constructing the linear basis is an extension of the xor basis algorithm where we maintain a set of $$$d$$$ vectors whose span is equal to the span of the basis. Similar to the xor basis algorithm we impose an additional constraint over our vectors such that the $$$i$$$-th vector we store will have the first $$$i-1$$$ dimensions to be $$$0$$$.
Although this problem may seem like a trivial extension to the xor basis algorithm, it is not. Consider the ring $$$(\mathbb{Z}/6\mathbb{Z})^2$$$ and the vector $$$(3~1)$$$. In the xor basis algorithm, checking if a vector is representable is done greedily by doing Gaussian elimination and greedily scalars to multiply to the vectors. So we would expect our basis to store $$$\begin{pmatrix} 3 & 1 \\ 0 & 0 \end{pmatrix}$$$. However, if we were to check if the vector $$$(0~2)$$$ is in the set, we would fail to produce it.
The way that the linear basis algorithm handles this is to allow a single vector to be propagated down to multiple rows. In the example mentioned above, we would realize that $$$(3~1) \cdot 2 = (0~2)$$$. So we would store $$$\begin{pmatrix} 3 & 1 \\ 0 & 2 \end{pmatrix}$$$ as our matrix. It should be noted that the row space of the matrix we store may not be linearly independent.
Another notable case to consider is on $$$\mathbb{Z}/6\mathbb{Z}$$$. With vectors $$$(2)$$$ and $$$(3)$$$, it actually spans the entire ring since $$$\gcd(2,3)=1$$$.
It should be noted that in the case where $$$m$$$ is prime, the algorithm behaves exactly like the generalized version of the xor basis algorithm that works on prime numbers.
Define $$$V,W$$$ as $$$1 \times d$$$ vectors of elements in $$$\mathbb{Z}/m\mathbb{Z}$$$ and $$$A$$$ as a $$$d \times d$$$ matrix of elements in $$$\mathbb{Z}/m\mathbb{Z}$$$ where initially all elements are set to $$$0$$$.

With such a construction of the basis, we can easily check if a vector is representable using a simple greedy algorithm.

Note that in the above $$$2$$$ algorithms, we are doing all operations modulo $$$m$$$ with the exception of $$$\frac{a}{b}$$$ and $$$a \% b$$$. In the above $$$2$$$ pseudo-codes and our proofs below, $$$\frac{a}{b}$$$ is used to denote integer division, it is always guaranteed that $$$b|a$$$ when $$$\frac{a}{b}$$$ is written. $$$a \% b$$$ is also used to denote the remainder after integer division of $$$a$$$ by $$$b$$$. We will also use the notation $$$a \lt b$$$ for elements in $$$\mathbb{Z}/m\mathbb{Z}$$$, this should be understood as comparing the integer values of the elements.
Let us first list out some properties of $$$A$$$ and $$$V$$$.
Lemma 1: Consider the vector $$$V$$$ after the $$$i$$$-th iteration of the loop at line 5 of Algorithm 1, then for all $$$1 \leq j \leq i$$$, $$$V_j=0$$$.
Lemma 2: $$$A_{i,j}=0$$$ if $$$i \gt j$$$
Lemma 3: If $$$A_{i,i}=0$$$, then $$$A_{i,j}=0$$$.
Lemma 4: If $$$A_{i,i} \neq 0$$$, then $$$\gcd(A_{i,i},m)=A_{i,i}$$$.
Let $$$S$$$ be a set of vectors in $$$(\mathbb{Z}/m\mathbb{Z})^d$$$. Then $$$span(S)$$$ is the set of vectors that can be formed by a linear combination of vectors in $$$S$$$. More formally, let $$$S={s_1,s_2, \ldots, s_w}$$$. Then $$$V \in span(S)$$$ iff there exists $$$\lambda_1, \lambda_2, \ldots,\lambda_w \in (\mathbb{Z}/m\mathbb{Z})$$$ such that $$$V=\sum\limits_{k=1}^w \lambda_i s_i$$$.
Theorem 1: Suppose there exists $$$\mu_1, \mu_2, \ldots,\mu_d \in (\mathbb{Z}/m\mathbb{Z})$$$ such that $$$V=\sum\limits_{k=1}^w \mu_ks_k$$$ then there exists $$$\lambda_1, \lambda_2, \ldots, \lambda_d \in (\mathbb{Z}/m\mathbb{Z})$$$ such that $$$V=\sum\limits_{k=1}^d \lambda_k A_k$$$ i.e. the rows of $$$A$$$ spans $$$S$$$.
Corollary 1: Suppose for some vector $$$W$$$, $$$V=W$$$ at the $$$i$$$-th iteration of the for loop. Then there exists $$$\lambda_i,\lambda_{i+1}, \ldots,\lambda_d \in (\mathbb{Z}/m\mathbb{Z})$$$ such that $$$W=\sum\limits_{k=i}^d \lambda_k A_k$$$ after $$$\texttt{Add-Vector}$$$ has returned.
Theorem 2: After each call to $$$\texttt{Add-Vector}$$$, the following holds: for all $$$i$$$ such that $$$A_{i,i} \neq 0$$$, there exists $$$\mu_{i+1}',\mu_{i+2}',\ldots,\mu_d' \in (\mathbb{Z}/m\mathbb{Z})$$$ such that $$$\frac{m}{A_{i,i}} A_i = \sum\limits_{k=i+1}^d \mu_k' A_k$$$.
Theorem 3: Suppose for all $$$V \in span(S)$$$ there exists $$$V=\sum\limits_{k=1}^d \mu_kd_k$$$ where $$$\mu_1, \mu_2, \ldots,\mu_d \in (\mathbb{Z}/m\mathbb{Z})$$$ then for all $$$V' \in span(S)$$$ there exists $$$\lambda_1, \lambda_2, \ldots, \lambda_d \in (\mathbb{Z}/m\mathbb{Z})$$$ that satisfies $$$V=\sum\limits_{k=1}^d \lambda_k A_k$$$ and $$$\lambda_i=0 $$$ if $$$A_{i,i}=0$$$ and $$$0 \leq \lambda_i \lt \frac{m}{A_{i,i}}$$$ otherwise.
Theorem 4: $$$\texttt{Inside-Basis}(V)$$$ is returns true iff $$$V \in S$$$.
It is also straightforward to adapt the algorithm $$$\texttt{Inside-Basis}$$$ to find the lexicographically largest vector. We will now show that the matrix $$$A$$$ also maintains the number of representable vectors.
Define a function $$$c(z)=\begin{cases} \frac{m}{z}, & \text{if } z \neq 0 \\ 1, & \text{otherwise} \end{cases}$$$
Theorem 5: The number of representable vectors is $$$\prod\limits_{k=1}^d c(A_{k,k})$$$.
Complexity
Suppose there are $$$n$$$ vectors being added into the basis. We will consider the number of times $$$\texttt{Add-Vector}$$$ is called. In 15 to 23 $$$\texttt{Add-Vector}$$$ is called twice, let us show that the number of times lines 15 to 23 is executed by bounded by $$$O(\Omega(m))$$$.
Let $$$A_i$$$ and $$$A_i'$$$ be the values of $$$A_i$$$ before and after the execution of lines 15 to 23. $$$A_{i,i}'=\gcd(V_i,A_{i,i})$$$ so it is easy to see that $$$A_{i,i}'|A_{i,i}$$$. Yet, $$$A_{i,i}' \neq A_{i,i}$$$ since that will only happen if $$$V_i = kA_{i,i}$$$ for some $$$k$$$ and lines 12 to 14 will be executed instead. Therefore, we can conclude that $$$A_{i,i}'|A_{i,i}$$$ and $$$A_{i,i}' \neq A_{i,i}$$$ implying that $$$\Omega(A_{i,i}') \lt \Omega(A_{i,i})$$$. Since $$$\Omega(A_{i,i})$$$ can only decrease at most $$$O(\Omega(m))$$$ times, the number of times that lines 15 to 23 is executed by bounded by $$$O(\Omega(m))$$$.
Therefore, there will only be $$$O(n+\Omega(m) \cdot d)$$$ calls to $$$\texttt{Add-Vector}$$$. It is easy to see that the time complexity excluding the calls to $$$\texttt{Extended-Euclidean}$$$ is $$$O(n \cdot d^2+\Omega(m) \cdot d^3)$$$.
It is easy to see that the total calls to $$$\texttt{Extended-Euclidean}$$$ will take $$$O(d \log (m))$$$, so the total complexity is $$$O(n \cdot d^2 + \Omega(m) \cdot d^3 + d \cdot \log(m))$$$.
The complexity of $$$\texttt{Inside-Basis}$$$ is trivially $$$O(d^2)$$$.
Extension to Handling Elements of Arbitrary Finite Abelian Group
First, let us consider maintaining the basis for vectors in $$$G=\mathbb{Z}/m_1\mathbb{Z} \times \mathbb{Z}/m_2\mathbb{Z} \times \ldots \times \mathbb{Z}/m_d\mathbb{Z}$$$.
Let $$$L=lcm(m_1,m_2,\ldots,m_d)$$$. It is clear that the above group is a subset of $$$(\mathbb{Z}/L\mathbb{Z})^d$$$, so we can maintain the basis of $$$G$$$ using this algorithm.
Upon analysis of the time complexity, it is easy to see that the time complexity is actually $$$O((n + \sum\limits_{k=1}^d \Omega(m_k)) \cdot d^2 + \sum\limits_{k=1}^d \log(m_k))$$$ assuming addition and multiplication under $$$\mathbb{Z}/L\mathbb{Z}$$$ can be done in $$$O(1)$$$.
By the fundamental theorem of finite abelian groups, every finite abelian group $$$G$$$ is an internal group direct product of cyclic groups whose orders are prime powers. So, $$$G=\mathbb{Z}/p_1^{k_1}\mathbb{Z} \times \mathbb{Z}/p_2^{k_2}\mathbb{Z} \times \ldots \times \mathbb{Z}/p_d^{k_d}\mathbb{Z}$$$ which can be handled easily.
Generalization to Euclidean Domains
Big thanks to adamant for discussing this with me.
It turns out that we can generalize this algorithm to work for any euclidean domain given that we are able to:
- Do division and the extended euclidean algorithm quickly
- Determine the size of the ideal $$$(r)$$$ generated by some element $$$r \in R$$$
We obviously have to do division quickly or else we will have a horrible time with things like $$$\mathbb{Z}[X]$$$.
As adamant suspected, this algorithm works also on $$$\mathbb{Z}[i]/p\mathbb{Z}[i]$$$ since similar to the case of integers, the extended euclidean algorithm works in $$$O(\log \max(N(a),N(b))$$$, which does not hold for the general euclidean domain, where $$$N(a+bi)=a^2+b^2$$$.
Now, we just have to show that we can compute the size of the ideal generated by $$$a+bi$$$ quickly. In the normal linear basis algorithm, it is intuitive to see that the size of the ideal generated by $$$a$$$ is $$$\frac{m}{\gcd(a,m)}$$$. It seems that this intuition actually carries over to $$$\mathbb{Z}[i]$$$ i.e. the size of the ideal is $$$\frac{N(p)}{N(\gcd(p,a+bi))}$$$.
I don't really have a good proof of this but I think I have some intuition on why this should work. A proof sketch would probably be looking at these things as groups and considering the size of the coset.
The size of the ideal generated by $$$a+bi$$$ is intuitively the same as the ideal generated by $$$\gcd(p,a+bi)$$$. Since $$$\gcd(p,a+bi) \cdot k_1 = a+bi$$$ for some $$$k_1$$$ and $$$(a+bi) \cdot k_2 = \gcd(p,a+bi)$$$ since the extended euclidean had found some $$$(s,t)$$$ such that $$$s \cdot (a+bi)+ p \cdot t=\gcd(p,a+bi)$$$.
Now, I will just ask you to appeal to geometric intuition for this part. Suppose we tile the plane with $$$pZ[i]$$$. Let's use $$$p=5+5i$$$ here.
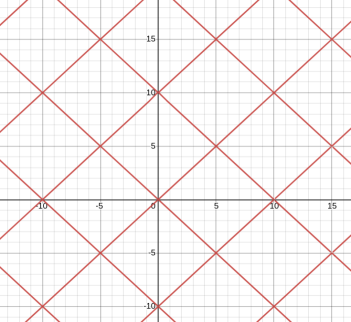
Now, I claim that if $$$\gcd(g,p)=g$$$, then each "tile" will look the same.
Here are some examples:
$$$g=1+2i$$$
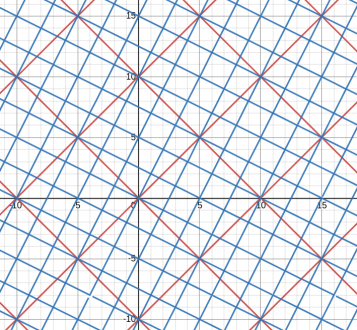
$$$g=3+i$$$
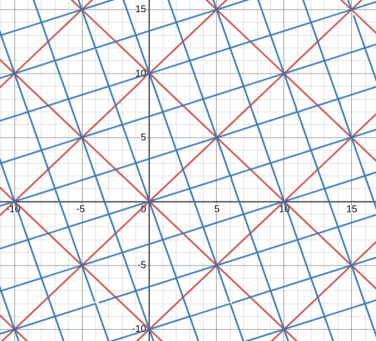
Some examples of $$$g$$$ that are not divisors of $$$p$$$ are $$$g=2+3i$$$.
Here is what it looks like.
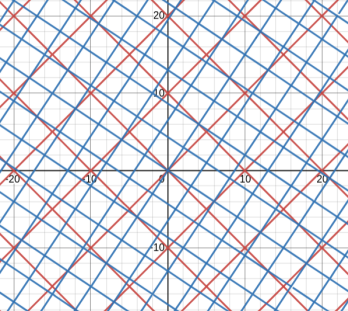
Anyways, we can see that each blue tile takes up $$$N(g)$$$ squares. And since the blue tiles are a repeated pattern in the red tiles, we can only look at a single tile. Therefore, we can see that the size of the ideal is $$$\frac{N(p)}{N(g)}$$$, which was what we wanted.
It is probably better if you just tried these things yourself so here is the desmos graphs that I used to get the intuitions.
Open Problems
- (SOLVED) In line 22 of Algorithm 1, $$$\texttt{Add-Vector}(\frac{m}{A_{i,i}}A_i)$$$ is called. This fact is used only in case 3 of theorem 2. Is the algorithm correct without this line? We have not found a set of vectors that causes the resulting matrix $$$A$$$ to be different when that line is removed.
- Is there a fast (offline) algorithm for linear basis that allows for range query similar to 1100F - Ivan and Burgers and ABC223H when the vectors are in $$$(\mathbb{Z}/m\mathbb{Z})^d$$$?
- What is the most general ring on which this algorithm works?
Implementation
Of course, this is a competitive programming site, so I will also provide a sample implementation in C++. I have also created an example problem in a mashup if you would like to submit (although testcases may not be super strong, if you want to provide stronger testcases please message me and I don't mind adding you on polygon).







The algorithm should work correctly without line 22. In particular, theorem 2 still holds.
Let $$$U$$$ be the result of line 18 and $$$g = U_i$$$. Then $$$W = A_i - kU$$$ where $$$k = \frac{A_{ii}}{g}$$$.
By induction, $$$\frac{m}{A_{ii}}A_i$$$ is in the span of $$$A_{i+1},\ldots, A_d$$$. After inserting $$$W$$$, $$$W$$$ is also in the span of $$$A_{i+1},\ldots, A_d$$$.
Now, note that $$$\frac{m}{A_{ii}} W = \frac{m}{A_{ii}}{A_i} - \frac{m}{g}U$$$, so $$$\frac{m}{g}U$$$ is also in the span of $$$A_{i+1},\ldots, A_d$$$, as required.
As such, line 22 does not change the matrix — the insertion of $$$\frac{m}{g} U$$$ does not do anything as the condition on line 12 will always be true.
Thanks
Looks somewhat similar to how Hermite normal form is construed, but... Does it really have to be recursive? After all, constructing basis in problems like this one is usually just modified Gaussian elimination in which you simply use extended Euclidean algorithm instead of division.
By the way, you can also do it in $$$(\mathbb Z[i] / p \mathbb Z[i])^n$$$ where $$$\mathbb Z[i]$$$ is a ring of Gaussian integers and $$$p \in \mathbb Z[i]$$$. There is actually a problem from 2010 in which this is exactly what you have to do (calculate the determinant of Gaussian integer matrix modulo given Gaussian integer $$$p$$$).
Thank you very much for this article! I tried my best to reproduce these results in a somewhat more direct way with Gaussian elimination and found out that it is way harder than it seemed to be after my experience with simply calculating the determinant of a matrix on arbitrary modulo $$$m$$$.
I couldn't even solve your example problem yet despite trying to figure it out for hours. There are so much things from linear algebra that you expect would work here, but just don't, that's fascinating.
And pivoting breaks as well, so you need to be extra careful when trying to maintain echelon form in the basis... That's a bit insane.
I suspect some variant would work in all principal ideal rings: — jus modify and use smith normal forms and it suffices i believe (or apply some form of zariski samuel)
if we add on the assumption our ring is noetherian, then {all matrices has SNF}=R is principal ideal ring
How to construct Smith normal form without Euclid algorithm?
r.e. computation id assume youll need some form of "computable PID" here, in the sense given a,b you have an algorithm to return n such that (n)=(a,b)
Is there an example of such PID which is not Euclidean domain?
I finally solved the problem in mashup. Here's my take on this.
Let $$$a$$$ and $$$b$$$ be the elements of $$$\mathbb Z_m^d$$$ such that $$$a_i = b_i = 0$$$ for all $$$i \lt k$$$ and either $$$a_k$$$ or $$$b_k$$$ is non-zero. If we do Euclidean algorithm on $$$a_k$$$ and $$$b_k$$$, while also doing same transforms on $$$a$$$ and $$$b$$$, $$$b_k$$$ will become $$$\gcd(a_k, b_k)$$$ and $$$a_k$$$ will become $$$0$$$, while $$$a_i = b_i = 0$$$ for $$$i \lt k$$$ will still hold.
It won't affect the span of $$${a, b}$$$, because swapping vectors and subtracting one vector from the other with some coefficient are invertible operations (also sometimes referred to as elementary operations).
The procedure is implemented as follows:
We should note that there may be torsion elements in module, when it is possible to nullify elements lead coefficient without nullifying the whole element. It happens when the leading coefficient of the element is a non-trivial divisor of $$$0$$$.
It is possible to find the "earliest" such vector that is obtained by multiplying $$$a$$$ with some scalar to nullify the leading coefficient of $$$a$$$. The procedure to find it is as follows:
Now we can introduce a function
advancethat takes a vector $$$a$$$ and eliminates its leading coefficients in a Gaussian-like process. Herebase[t]is either a basis vector with non-zero coefficient $$$t$$$ or a zero vector if it wasn't initialized (in this case,reducewould putainbase[t]).Finally, the whole process of adding new vector to the basis, if implemented iteratively, will look like this:
For every base vector that is changed within
advance, we would need to also try inserting its lift in the basis.From the group theoretic perspective what we construct here is somewhat similar to the strong generating set of permutation group. It can be formally introduced and explained as a sequence of coset representatives in a subgroup series where every "basis" prefix $$$\langle e_1, e_2, \dots, e_k \rangle$$$ corresponds to a specific subgroup of $$$(\mathbb Z / m \mathbb Z)^d$$$.
Now that I saw this correspondence between this algorithm and permutation groups, I'm thinking about writing an article about Schreier-Sims algorithm to solve similar tasks on a group spanned on the given set of permutations. I hope, this particular problem could be a meaningful model example for the procedure used there!
Thanks for the blog! I found we can simplify the algorithm a bit.
Consider Case $$$3$$$. Let $$$g=gcd(V_i,W_i)$$$. If we let $$$V:=W_i/g \times V_i - V_i/g \times W_i$$$ in the line 19, we don't need any recursions. With this modification, we don't have to handle Case 2 and 3 separately (we can even handle Case 1 in the same way), and we can also eliminate the $$$O(\Omega(m) d^3)$$$ term from the complexity.
Code: 141774058
Interestingly, this seems like the exact transform used in Smith Normal Form in step II. Maybe this algorithm is more closely related to linear basis than I expected.
Wow, that's interesting. It wasn't obvious to me at first what would be the equivalent change in my version of solution, as my
reduceessentially leads to the same result.After looking closely on your code and discussing it with errorgorn I found out that equivalent change would be
if(b[i] == 0) b[i] = m;inreduce.Then I don't need
touchedorliftas well and it is enough to make a singleadvancecall onainstead. So, the most important part for me was treating $$$0$$$ as $$$m$$$...So, basically this reduces my whole implementation to something as simple as
where
subtract(a, b, k)performsa -= b * k. It works in $$$O(d^2 \log m)$$$ worst case per single addition, but $$$O(nd^2 + d^2 \log m)$$$ per a series of $$$n$$$ additions, so it is $$$O(d^2)$$$ amortized.My current shortest submission (141779662) is, imo, very clean and readable (not using macros, etc), and almost as short good old code for the xor basis. That's very neat that it is still possible to keep it very short and concise, though mod $$$m$$$ seemed to be a big deal at first.
If instead of doing this transform directly on vectors, we would calculate coefficients $$$s,t,x,y$$$ such that transform is equivalent to $$$a \to s \cdot a + t \cdot b_i$$$ and $$$b_i \to x \cdot a + y \cdot b_i$$$, it would be $$$O(d^2 + \log m)$$$ worst case per addition.
Correctness proof. We need to prove the following assumptions on $$$b_i$$$ before the $$$i$$$-th iteration and after
addis executed completely:This assumption holds initially when $$$b_i=0$$$. For it to hold generally after $$$i$$$-th iteration, second statement should still hold and $$$lift(x \cdot a + y \cdot b_i)$$$ should be in the span of $$$\{s \cdot a + t \cdot b_i,b_{i+1}, b_{i+2}, \dots, b_{d-1}\}$$$.
Note that changing $$$b_{ii}$$$ to $$$m$$$ when $$$b_{ii}=0$$$, under these assumptions, effectively means that $$$b_{ii}$$$ is always replaced with $$$\gcd(b_{ii}, m)$$$ for the purpose of Euclidean algorithm.
After the transform, $$$b_i$$$ is replaced with $$$x \cdot a + y \cdot b_i$$$ in such way that
thus
In this expression, $$$lift(b_i)$$$ is assumed to be in the span of $$$\{b_{i+1}, b_{i+2}, \dots, b_{d-1}\}$$$. Only thing left to prove is that $$$\frac{\gcd(a_i,m)}{\gcd(a_i,b_{ii}, m)}lift(a)$$$ is in the span of $$$\{s \cdot a + t \cdot b_i, b_{i+1}, \dots, b_{d-1}\}$$$, where
If we exactly follow the Euclidean algorithm, we will notice that
where $$$k$$$ is determined by the number of swaps within algorithm.
This means that
If we multiply this expression by $$$\frac{m}{\gcd(b_{ii},m)}$$$, we get
therefore $$$\frac{\gcd(a_i,m)}{\gcd(a_i,b_{ii},m)} lift(a)$$$ is expressible as linear combination of $$$s \cdot a + t \cdot b_i$$$ and $$$lift(b_i)$$$, which in turn is expressible as linear combination of $$$\{b_{i+1}, b_{i+2}, \dots, b_{d-1}\}$$$, q.e.d.
It should probably be mentioned that the basis constructed in this post is also called the Howell normal form of a matrix formed by the vectors for which we construct a basis.