


There are a lot of programming problems where a collection of intervals comes up, either directly or indirectly. In this tutorial, I want to present a nice way to visualize a collection of intervals, and how you can solve problems with it.
An interval $$$[l, r]$$$ is just a pair of integers $$$l$$$ and $$$r$$$ such that $$$l\le r$$$. Let's make a 2D plot where the horizontal axis is $$$l$$$ and the vertical axis is $$$r$$$. Then our interval will be represented by the 2D point $$$(l, r)$$$. But an interval is more than just a pair of numbers: it describes the set of points $$$x$$$ such that $$$l\le x\le r$$$.
How can we visually tell whether a number $$$x$$$ is covered by an interval? Well, we can represent it by a point $$$(x, x)$$$ in the plane. Then we can imagine that the interval's 2D point can see down and right, and the interval covers all the points it can see.
Here's an example where we see how the interval $$$[2, 4]$$$ covers the points $$$2$$$, $$$3$$$, and $$$4$$$.

Great, we have a visualization for how an interval covers points. But we also want to talk about how intervals relate to each other. For example, intervals can be nested, or they can be disjoint, or something else.
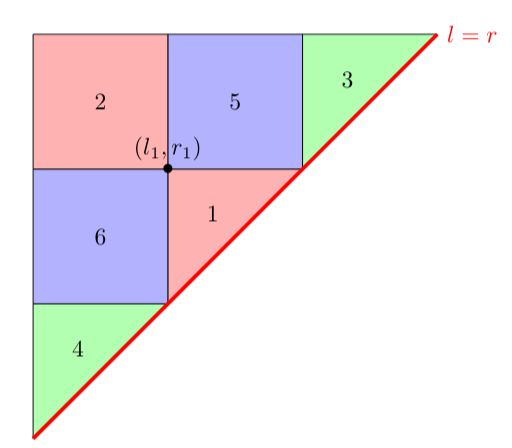
Let's classify the $$$6$$$ possible ways two intervals can relate to each other.
An interval $$$[l_1, r_1]$$$ covers an interval $$$[l_2, r_2]$$$ if $$$l_1\le l_2\le r_2\le r_1$$$.
An interval $$$[l_1, r_1]$$$ is covered by an interval $$$[l_2, r_2]$$$ if $$$l_2\le l_1\le r_1\le r_2$$$.
An interval $$$[l_1, r_1]$$$ is strictly left of an interval $$$[l_2,r_2]$$$ if $$$l_1\le r_1 < l_2\le r_2$$$.
An interval $$$[l_1, r_1]$$$ is strictly right of an interval $$$[l_2, r_2]$$$ if $$$l_2\le r_2 < l_1\le r_1$$$.
An interval $$$[l_1, r_1]$$$ intersects left of an interval $$$[l_2,r_2]$$$ if $$$l_1\le l_2\le r_1\le r_2$$$.
An interval $$$[l_1, r_1]$$$ intersects right of an interval $$$[l_2, r_2]$$$ if $$$l_2\le l_1\le r_2\le r_1$$$.
Note that there is some symmetry. For example, if one interval covers another interval, then the second interval is covered by the first interval. So, relations $$$1$$$ and $$$2$$$ are opposites, relations $$$3$$$ and $$$4$$$ are opposites, and relations $$$5$$$ and $$$6$$$ are opposites. Now, if we fix an interval $$$(l_1, r_1)$$$ we can make $$$6$$$ different regions in the plane: one for each relation. I colored opposite relations the same color.
Next, we're going to look at some example problems.
Problem 1. Nested Ranges Check
https://cses.fi/problemset/task/2168
Given $$$n$$$ ranges, your task is to determine for each range if it contains some other range and if some other range contains it.
There are two parts to this problem, so let's focus on one part for now. For each interval $$$(l, r)$$$, we want to check if it's covered by another interval. In other words, we want to check if its region $$$2$$$ is nonempty.
For an interval to be in region $$$2$$$, it must be left and up from it. Let's process all intervals in increasing order of $$$l$$$, so that the "left of" condition just becomes "previously processed". So, we just need to ask for each interval, if there exists a previously processed interval above it.
If any previously processed interval is above $$$(l, r)$$$, then definitely the one with maximum $$$r$$$ will be above it. So we don't need to check all the previous intervals by brute force: just remember the maximum $$$r$$$ value seen so far and remember it.
There's one small issue we skipped over: when we sorted all intervals by $$$l$$$, we didn't say what to do in the case of ties. In other words, if two intervals have the same $$$l$$$ value, should we process the lower or higher one first? Well, if there are two intervals with the same $$$l$$$ value, then the larger one is considered to cover the second. This means the interval with smaller $$$r$$$ should definitely be processed after the one with larger $$$r$$$. So in the case of ties for $$$l$$$ value, we should process them in decreasing order of $$$r$$$.
Now we've solved one of the two parts. For the other part, we want to check for each interval, if it covers another interval. We can actually use the exact same idea, except we will sort decreasing by $$$l$$$, break ties in increasing order of $$$r$$$, and remember the minimum $$$r$$$ value of all processed intervals.
The total complexity will be $$$O(n\log n)$$$ from sorting.
Problem 2. Nested Ranges Count
https://cses.fi/problemset/task/2169
Given $$$n$$$ ranges, your task is to count for each range how many other ranges it contains and how many other ranges contain it.
This is very similar to the previous problem, but this time we want to count ranges instead of just checking. Just like last time, let's start with only focusing on counting for each interval, how many other intervals contain it. Also like last time, let's process all intervals in increasing order of $$$l$$$, and break ties with decreasing order of $$$r$$$.
Now when we process an interval $$$(l, r)$$$, we need to count how many previously processed intervals are above it. We should maintain some kind of data structure of the processed intervals, where we can insert a value and query how many are above a certain value.
If we do coordinate compression, we can make all the intervals have values between $$$1$$$ and $$$2n$$$ without changing any of the relationships between them. Now we can store the processed $$$r$$$ values in a Fenwick tree, for example. To insert a new $$$r$$$ value, we update the Fenwick tree to increment position $$$r$$$. To answer how many values are above $$$r$$$, we query the range $$$[r, 2n]$$$.
Again, the other half of this problem is the same except for the sorting order and we want to count the number of $$$r$$$ values below instead of above.
The total complexity will be $$$O(n\log n)$$$, due to sorting and answering queries.
Problem 3. Largest Nested Interval Subset
Given $$$n$$$ intervals, find the size of the largest possible subset of intervals with the following property: for any pair of intervals, one contains the other.
First, we can describe the "nested subset" property in a nicer way: If the intervals are sorted decreasing by length $$$r-l$$$, then the first interval contains the second interval, and the second interval contains the third interval, and so on. Geometrically, this means we're looking for a path of points that moves only down and right. Now we can see that this is basically the same as the longest decreasing subsequence problem.
We can solve this problem in a similar way as before: sort all intervals in increasing order of $$$l$$$ and break ties with decreasing order of $$$r$$$. This time, we're going to use dynamic programming. For an interval $$$[l_i, r_i]$$$ we'll compute $$$dp_i$$$, which we define to be the largest nested subset of intervals such that $$$[l_i, r_i]$$$ is the smallest interval. The final answer will be the maximum $$$dp_i$$$ value.
To compute $$$dp_i$$$, we have the formula
where we assume $$$j$$$ is only allowed to be a previously processed interval. If there exist no valid $$$j$$$ then we set $$$dp_i=1$$$. Just like the Nested Ranges Count problem, we can maintain a data structure that can support point updates (to insert a new $$$dp_i$$$ value) and range max queries (to find the maximum $$$dp_j$$$ value corresponding to $$$r_j\ge r_i$$$). For example, a segment tree that supports range maximum queries will work here.
The total complexity will be $$$O(n\log n)$$$ due to sorting and segment tree queries.
Problem 4. Interesting Sections
There is an array of non-negative integers $$$a_1,a_2,\ldots, a_n$$$. Count the number of segments $$$[l, r]$$$ such that: 1. The minimum and maximum numbers are found on the segment of the array starting at l and ending at r. 2. the binary representation of the minimum and maximum numbers have the same number of bits equal to 1.
First, for each index, we want to know the largest interval on which it's the minimum element, and the largest interval on which it's the maximum element. We can precompute all these intervals in linear time with a monotonic stack idea, for example. Let's say the interval where $$$a_i$$$ the minimum element is $$$[l_1(i),r_1(i)]$$$ and the interval where it's the maximum element is $$$[l_2(i),r_2(i)]$$$. If there's a tie for the minimum (maximum) element in a range, we always pick the first occurrence to be the minimum (maximum).
Now, for each index $$$i$$$, let's consider the set of intervals $$$[l,r]$$$ on which $$$a_i$$$ is the minimum element. We simply require it to contain index $$$i$$$, and for it to be contained in $$$[l_1(i), r_1(i)]$$$. In the plane, this is just a rectangle: $$$l_1(i)\le l\le i$$$ and $$$i\le r\le r_1(i).$$$ Similarly, we have a rectangle for the maximum case.
Let's say that a rectangle is red if it came from the minimum case, and blue if it came from the maximum case. First, notice that no two rectangles of the same color intersect because a range has a unique minimum and maximum by our tie-breaking rule. Our task is to calculate how many lattice points are the intersection of a red and blue rectangle, and both of them have the same "group number", namely the popcount of their corresponding $$$a_i$$$ values.
Let's just offset rectangles according to their group number so that rectangles of different group numbers definitely don't intersect, and rectangles of the same group are offset by the same amount.
The only thing we need to compute is the area of intersection of red rectangles and blue rectangles. We can find the area of intersection of these rectangles in $$$O(n\log n)$$$ time with a sweepline and segment tree. The rectangle union problem is similar, which can be found on CSES: https://cses.fi/problemset/task/1741
For the rectangle intersection problem, we need our segment tree to maintain two things: 1. maximum value on a range, and 2. number of occurrences of the maximum element. It needs to support range increment/decrement updates and range queries. When the sweepline enters a rectangle, we increment its range, and when it exits a rectangle, we decrement its range. A value $$$2$$$ in the segment tree means there are both red and blue rectangles covering it, so the number of occurrences of $$$2$$$ describes how much intersection there is between red and blue at the sweepline's current position.






btw, this idea completely trivializes this task (massive spoiler)
An enlightening idea
Just comment -> Codeforces Catalog -> Tutorial blog
Caught red-handed :P
But I just found this visualization useful many times so I thought it was worth a blog.
Nice idea! Representing ranges as rectangles like described in the last problem can be very useful in some tricky situations.
Though while I was trying to implement the idea for the mentioned problem, I've noticed that the tie-breaking rule didn't seem to be quite right, or maybe I wasn't understanding it correctly. What worked out to me is that, if you consider a range where the element at position $$$i$$$ is minimum (for example), in order to avoid overlapping rectangles, given the range $$$[l(i), r(i)]$$$ where the condition would hold, $$$l(i) = j+1$$$ and $$$r(i) = k-1$$$ with:
If no $$$j$$$ exists, $$$j = 0$$$, and if no $$$k$$$ exists, $$$k = n+1$$$ (so it turns like $$$l(i) = 1$$$ and $$$r(i) = n$$$ respectively). You can use the same logic with the interval where $$$a_i$$$ is the maximum element, changing the conditions to $$$a_j > a_i$$$ and $$$a_k \geq a_i$$$. Also I think you can "invert" the conditions if you want, meaning it's just a matter the interval is set by the nearest lower (higher) or equal value to one side, and the nearest strictly lower (higher) value on the other side.
After reading that part a few times it's possible that, again, I was misinterpreting what it meant. But nevertheless wanted to clarify it as it maybe be useful to someone else who also didn't get it fully (or for someone else to help me get it straight, if this isn't ok either).
I also struggled (with no success) to write an implementation which would fit in the time limit. This is the best I got: 143932189, using fast I/O (with
getchar()), and optimizing the operations with the segment tree as much as I could. The idea was very easy to follow and I also liked the relation with the rectangle area union problem from CSES, but the TL makes it a bit hard to get it ACed with this alternate solution.EDIT: Fixed a mix up between 0-indexed ranges and 1-indexed.
Hello! ty so much for writing this blog, I just solved this problem with this idea. It's really cool how you can interchange one spacial dimension with time and vice versa !
This blog is really awesome.
I want to know why I'm getting downvoted here. I genuinely found the blog helpful, readable, and it helped me to solve this problem 1712E2 - LCM Sum (hard version).
I think you shouldn't make comments on old blogs,cause you are updating the "recent actions" board for nothing. Anyway I also think that downvote isn't necessary haha.
It's alright to comment on old blogs but you got downvoted here because you didn't contribute anything with your comment. You could've talked about how you solved LCM Sum with the information in this blog but just saying "this blog is really awesome" only bumped this blog up to recent actions and didn't add anything to it.
If you want to say "I enjoyed reading this blog/found it useful" only, I think that's what the upvote button is for.
I think sorting queries with the Hilbert Curve (Link) could be connected with this idea. How do you think about this?