


Как бы вы реализовали OrderedDict — упорядоченый словарь? Структура данных, которая бы поддерживала операции словаря (или хэш таблицы) над парами ключ-значение, но также хранила бы и поддерживала их упорядоченность?
- получить значение по ключу
- убрать из структуры по ключу
- вставка в любое место новой пары (ключ-значение)
- найти место пары по ключу
Мне начинает казаться, что такой структуры, которая бы все это поддерживала более-менее эффективно (не за линию) просто нет. Как вы думаете?






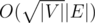 помножиное на
помножиное на 